Celery是一个简单、灵活、可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具。是一个专注于实时处理的任务队列,同时还支持任务调度。
目录
应用场景
问题
解决
celery架构图
安装
配置celery
Settings.py配置
创建celery
修改__init__
开启celery
异步执行
创建任务文件
视图
路由
演示
启动django
重启celery
浏览器访问
获取执行结果
AsyncResult属性和方法
演示
视图
路由
浏览器访问
Celery报错
kombu.async.timer
cannot import name 'current_app'
AttributeError
定时执行
增加配置
多个任务执行
创建执行方法
启动celery
绑定任务
实现绑定
实现错误重试
celery管理和监控
安装
运行命令
运行flower
浏览器访问
总结
参考文章
应用场景
问题
1.用户发起请求,需要等待响应返回;但是在视图中如果有一些耗时操作,可能导致用户会等待很长时间,这样用户体验非常不好。
2.网站隔一段时间要同步一次数据,但是http请求是需要触发的。
解决
使用celery来解决:耗时的操作方法在celery中异步执行;还可以使用celery定时执行。
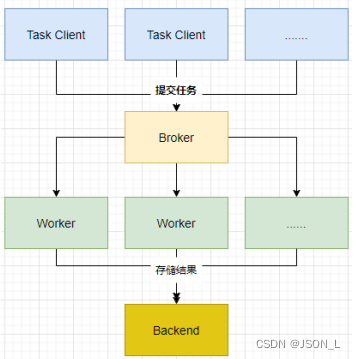
celery架构图
celery由以下四部分构成:
任务(Task)、代理(Broker)、任务执行(Worker)、结果存储(Backend)。
安装
命令如下:
pip install celery
pip install redis
# window下安装,linux下不需要
pip install eventlet
配置celery
Settings.py配置
Settings.py中在最下面配置
# celery配置
# Broker配置,使用Redis作为消息中间件
BROKER_URL = 'redis://127.0.0.1:6379/1'
# 若有密码这样配置
# BROKER_URL = 'redis://:pwd@127.0.0.1:6379/1'
# BACKEND配置,这里使用redis
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/1'
# 若有密码这样配置
# CELERY_RESULT_BACKEND = 'redis://:pwd@127.0.0.1:6379/1'
# 结果序列化方案
CELERY_RESULT_SERIALIZER = 'json'
# 任务结果过期时间,秒
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24
# 时区配置
CELERY_TIMEZONE = 'Asia/Shanghai'
# 指定导入的任务模块,可以指定多个
# CELERY_IMPORTS = (
# 'other_dir.tasks',
# )
创建celery
在工程目录下的project目录下创建celery.py文件。

内容如下:
import os
from celery import Celery
from django.conf import settings
# 设置系统环境变量,安装django,必须设置,否则在启动celery时会报错
# project 是当前工程目录名
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'project.settings')
celery_app = Celery('project')
celery_app.config_from_object('django.conf:settings')
celery_app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
修改__init__
在工程目录下project的__init__文件中添加
from .celery import celery_app
__all__ = ['celery_app']
开启celery
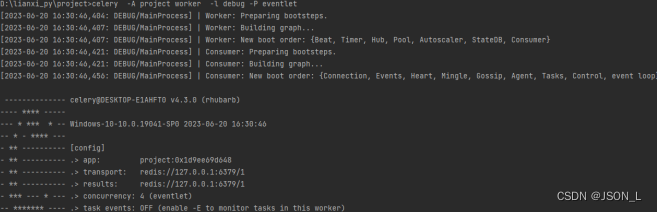
Window命令如下:
celery -A project worker -l debug -P eventlet
pip 安装eventlet,在启动celery的参数加上eventlet,
原理是windows不支持celery的进程执行。
Linux 命令如下:
celery -A project worker -l
成功截图如下:
Redis数据库

异步执行
创建任务文件
在子应用目录下创建tasks.py来执行任务(写耗时异步执行)
内容如下:
from celery import shared_task
import time
@shared_task
def add(x, y):
print('添加一个事件')
time.sleep(10)
print(x, y)
print('事件执行完成')
视图
应用视图views.py中增加引入和视图方法
from .tasks import *
def task_add(request):
add.delay(100, 200)
return HttpResponse(f'调用函数结果')
路由
urlpatterns = [
# celery
path(r'task_add', views.task_add, name='task_add'),
]
演示
启动django
python manage.py runserver
重启celery
celery -A project worker -l debug -P eventlet
浏览器访问
然后浏览器访问task路由。

通过worker的控制台,可以看到任务被worker处理。

获取执行结果
可通过AsyncResult对象通过返回的事件id来获取事件信息。
AsyncResult属性和方法
state: 返回任务状态,等同status;
task_id: 返回任务id;
result: 返回任务结果,同get()方法;
ready(): 判断任务是否执行以及有结果,有结果为True,否则False;
info(): 获取任务信息,默认为结果;
wait(t): 等待t秒后获取结果,若任务执行完毕,则不等待直接获取结果,若任务在执行中,则wait期间一直阻塞,直到超时报错;
successful(): 判断任务是否成功,成功为True,否则为False;
演示
视图
from celery import result
from django.http import JsonResponse
def task_info(request):
task_id = request.GET.get('task_id')
res = result.AsyncResult(task_id)
if res.ready():
return JsonResponse({'status': res.state, 'result': res.get()})
else:
return JsonResponse({'status': res.state, 'result': ''})
路由
path(r'task_info/<str:id>', views.task_info, name='task_info'),
浏览器访问
地址栏传入新增事件时,返回的事件id

Celery报错
kombu.async.timer
开启celery,提示错误Kombu.async.timer import Entry......

解决方法:
卸载celery,重装固定版本
命令如下:
pip install celery==4.3
cannot import name 'current_app'
cannot import name 'current_app' from 'celery'

解决方法:
打开D:\python3.7\lib\site-packages\celery\local.py"
原方法
def getappattr(path):
"""Get attribute from current_app recursively.
Example: ``getappattr('amqp.get_task_consumer')``.
"""
from celery import current_app
return current_app._rgetattr(path)
修改为:
def getappattr(path):
"""Get attribute from current_app recursively.
Example: ``getappattr('amqp.get_task_consumer')``.
"""
# from celery import current_app
from celery._state import current_app
return current_app._rgetattr(path)
AttributeError
AttributeError: 'EntryPoints' object has no attribute 'get'

解决方法:
安装固定版本的importlib-metadata
命令如下:
pip install importlib-metadata==4.13.0
定时执行
增加配置
工程目录下/settings.py
CELERYBEAT_SCHEDULE = {
'every_5_seconds': {
# 任务路径 应用目录/任务文件/方法
'task': 'myapp.tasks.schedule_execute',
# 每5秒执行一次
'schedule': 5,
# 设置参数
'args': (14, 6, 5)
}
}
多个任务执行
可在原来基础上继续增加
CELERYBEAT_SCHEDULE = {
'every_5_seconds': {
# 任务路径 应用目录/任务文件/方法
'task': 'myapp.tasks.schedule_execute',
# 每5秒执行一次
'schedule': 5,
# 设置参数
'args': (14, 6, 5)
},
'every_10_seconds': {
# 任务路径 应用目录/任务文件/方法
'task': 'myapp.tasks.schedule_execute',
# 每10秒执行一次
'schedule': 10,
# 设置参数
'args': (18, 10, 10)
},
}
创建执行方法
在task.py中设置执行方法并记录日志
from celery import shared_task
import logging
logger = logging.getLogger(__name__)
@shared_task
def schedule_execute(x, y, s):
logger.info('_____' * 20)
logger.info('每%d秒执行一次' % s)
logger.info('%d + %d = %d' % (x, y, (x+y)))
logger.info('执行结束')
logger.info('_____' * 20)
启动celery
(两个cmd)分别启动worker和beat
celery -A project worker -l debug -P eventlet
celery beat -A project -l debug
可通过控制台查看执行结果。
绑定任务
Celery可通过task绑定到实例获取到task的上下文,这样我们可以在task运行时候获取到task的状态,记录相关日志等
实现绑定
修改应用任务文件内容:在装饰器中加入参数 bind=True,在add函数中的第一个参数设置为self。
内容如下:
@shared_task(bind=True)
def add(self, x, y):
print('添加一个事件')
time.sleep(2)
print(x, y)
logger.info(self.name)
logger.info(dir(self))
print('事件执行完成')
实现错误重试
self对象是myapp.tasks.add实例,可用于实现重试。
@shared_task(bind=True)
def add(self, x, y):
try:
print('添加一个事件')
time.sleep(2)
print(x, y)
logger.info(self.name)
# 没有state属性 只是为了验证重试
logger.info(self.state)
logger.info(dir(self))
print('事件执行完成')
except Exception as e:
# 出错每5秒尝试一次,尝试3次
self.retry(exc=e, countdown=5, max_retries=3)
celery管理和监控
celery通过flower组件实现管理和监控功能。
Flower官网
Getting started — Flower 2.0.0 documentation
安装
pip install flower
运行命令
celery -A project flower
Or
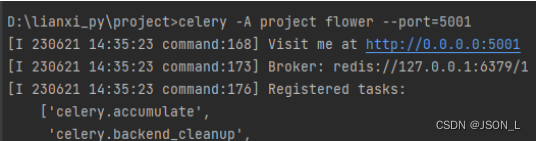
celery -A project flower --port=5001
参数说明
-A 项目名称
--port 端口号,默认5555
运行flower
运行命令,显示如下:
浏览器访问
http://127.0.0.1:port

总结
本文主要介绍了celery的应用场景;
如何安装及安装哪些类库;
异步和定时执行实现以及任务可视化管理。
参考文章
https://www.cnblogs.com/chunyouqudongwuyuan/p/16892475.html
Django 中celery的使用_django celery_宠乖仪的博客-CSDN博客
在django中使用celery_哔哩哔哩_bilibili
一文读懂 Python 分布式任务队列 celery