在业界的数据湖方案中有 Hudi、Iceberg 和 Delta 三个关键组件可供选择。
一、Iceberg 是什么?
Iceberg 官网中是这样定义的:
Apache Iceberg is an open table format for huge analytic datasets
即 Iceberg 是大型分析型数据集上的一个开放式表格式。通过该表格式,将下层的存储介质(HDFS、S3、OSS等)、文件格式(Parquet、Avro、ORC等)与上层计算引擎(Flink、Spark、Presto、Hive等)进行解耦,如下图所示。
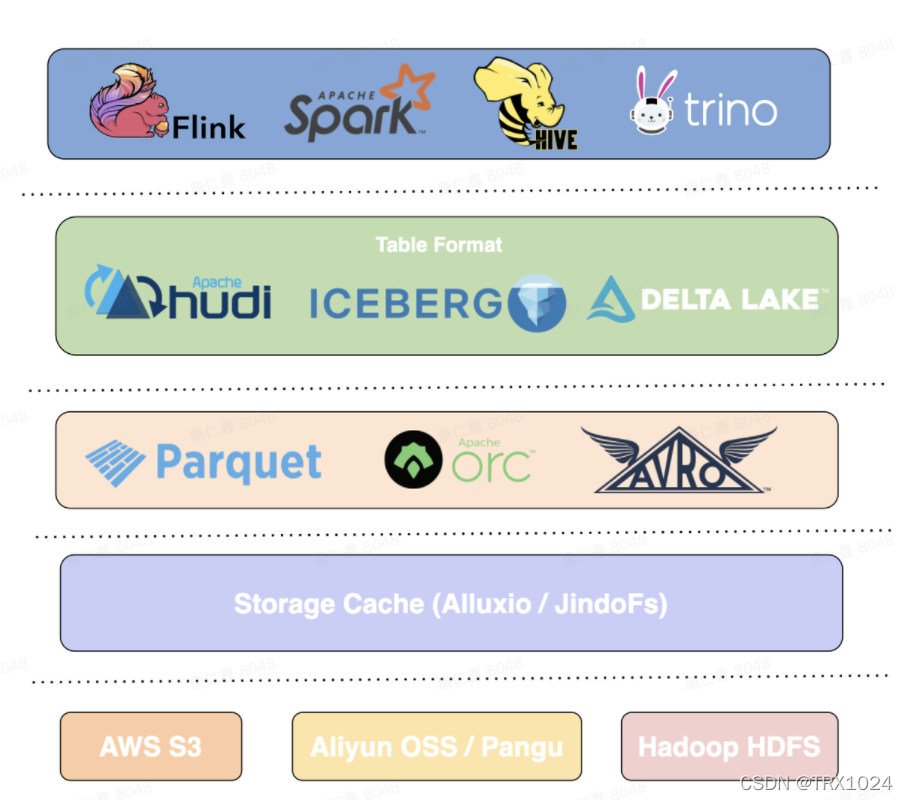
计算与存储的解耦给我们带来了更多的灵活性,在计算引擎上有了更多的选择,可以根据实际的需求选择不同的计算引擎。通过表格式屏蔽了下层的存储细节,对上层引擎呈现的都只是一张 Iceberg 表。
二、Iceberg 的文件组织形式
为了便于理解 Iceberg 的几个重要的特性,我们先简单介绍下 Iceberg 的文件的组织形式。
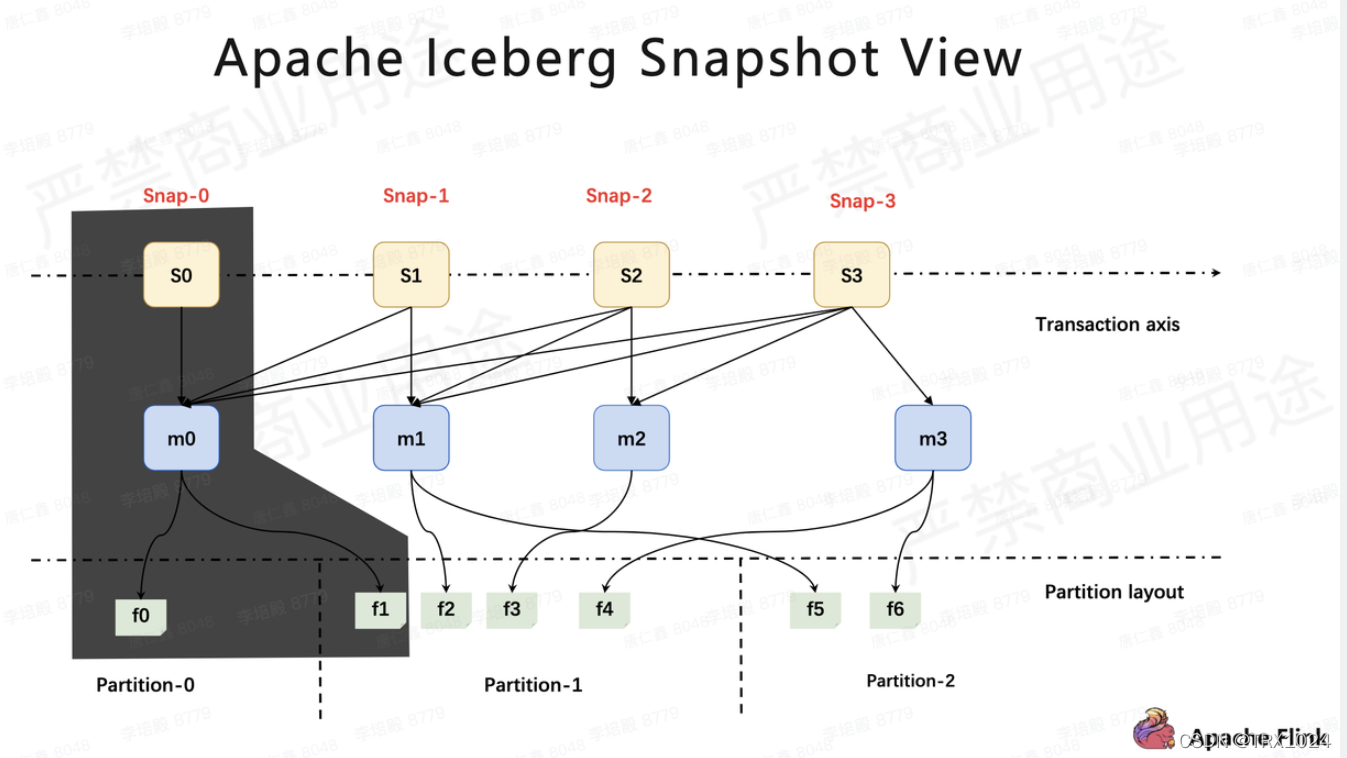
如下图所示,Iceberg 文件组织分为四层,分别为Metadata、Snapshot、Manifest、File。
- Metadata 文件:该文件记录了最新的快照信息和历史的快照记录。并且记录了最新的 Schema 信息。
- Snapshot 文件(图中Snap-x):由于 Iceberg 基于 MVCC(多版本并发控制) 的设计理念,每次 Commit 都会生成一个 Snapshot, 该 Snapshot 是当时表的全局快照,即选定某个快照读取时,读到的是全量数据。Snapshot 文件记录了历史的 Manifest 文件和本次 Commit 新增的 Manifest,当我们增量读取时,只需要读取指定快照的新增的 Manifest 就可以实现读取新增的数据。
- Manifest 文件(图中mx):该文件记录了本次事务中写入的文件和分区的对应关系,并且记录了文件中字段的一些统计信息(如最大值、最小值)以便于快速查找。
- File:实际写入的数据文件,如 Parquet、Avro 等格式文件。
三、事务性
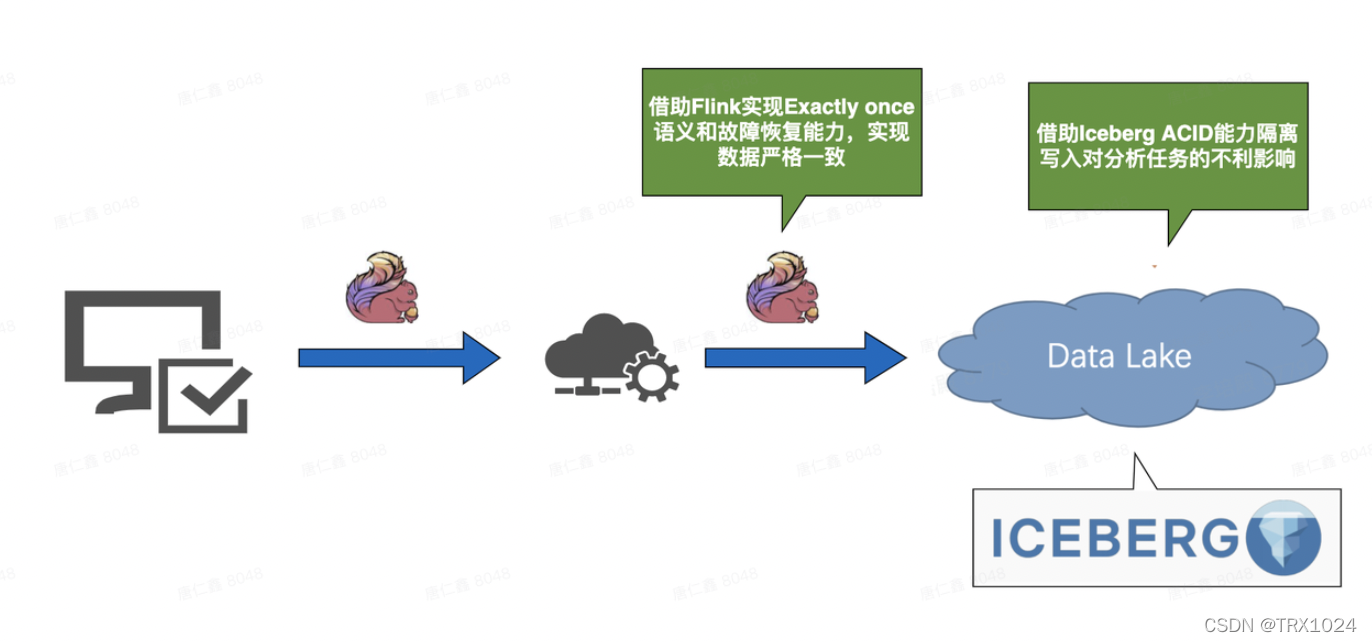
Iceberg 的一个亮点是提供了 ACID 的语义支持,通过 Snapshot 进行读写分离,提供了 Serializable isolation,且所有的操作都可以保证原子性。
相比 Hive 而言,Iceberg 提供的事务性可以隔离写入任务队分析任务的不利影响,且写入失败不会出现脏数据。

更加吸引人的是 Iceberg 和 Flink 的结合,通过 Flink 的 Checkpoint 机制和 Iceberg 的事务性,可以做到端到端的 Exactly once 语义。
四、Schema 约束与 Schema evolution
Schema约束
提起一张表(table format),我想最先强调的是表是具有 Schema的。 Iceberg 表是有 Schema 强制约束的。与 Hive 表不同,写入 Iceberg 表的数据必须经过 Schema 的校验,这样就解决了 Hive 表文件内容和 Schema 不匹配导致的下游消费异常的问题。
Schema evolution
此外,Iceberg 在Metadata 文件中记录最新的 Scehma 结构,并通过 id 与实际的数据文件中的 Schema 进行映射。因此对 Iceberg 表可以进行更加灵活的 Schema 变更操作,你可以像 MySQL 那样对 Iceberg 表进行增加列、删除列、更新列等操作,并且这些操作不会有任何的副作用,而在使用 Hive 表进行 Schema 变更时,在某些情况下则需要将历史的分区数据全部重写才可以完成。
五、Hidden Partition 与 Partition evolution
Hidden Partition
与 Hive 表类似,Iceberg 也可以进行分区来获取更快的查询。但与 Hive 不同的地方时 Iceberg 支持隐式分区。
在 Hive 中,分区需要显示指定为表中的一个字段,并且要求在写入和读取时需要明确的指定写入和读取的分区,如下示例中,以 event_date 作为分区分别展示读写 Hive 表和 Iceberg 表。

在上述例子中,Hive 表并不知道event_date 和event_time的对应关系,需要用户来跟踪。
而在 Iceberg 中将分区进行隐藏,由 Iceberg 来跟踪分区与列的对应关系。在建表时用户可以指定date(event_time) 作为分区, Iceberg 会保证正确的数据总是写入正确的分区,而且在查询时不需要手动指定分区列,Iceberg 会自动根据查询条件来进行分区裁剪。
Partition evolution
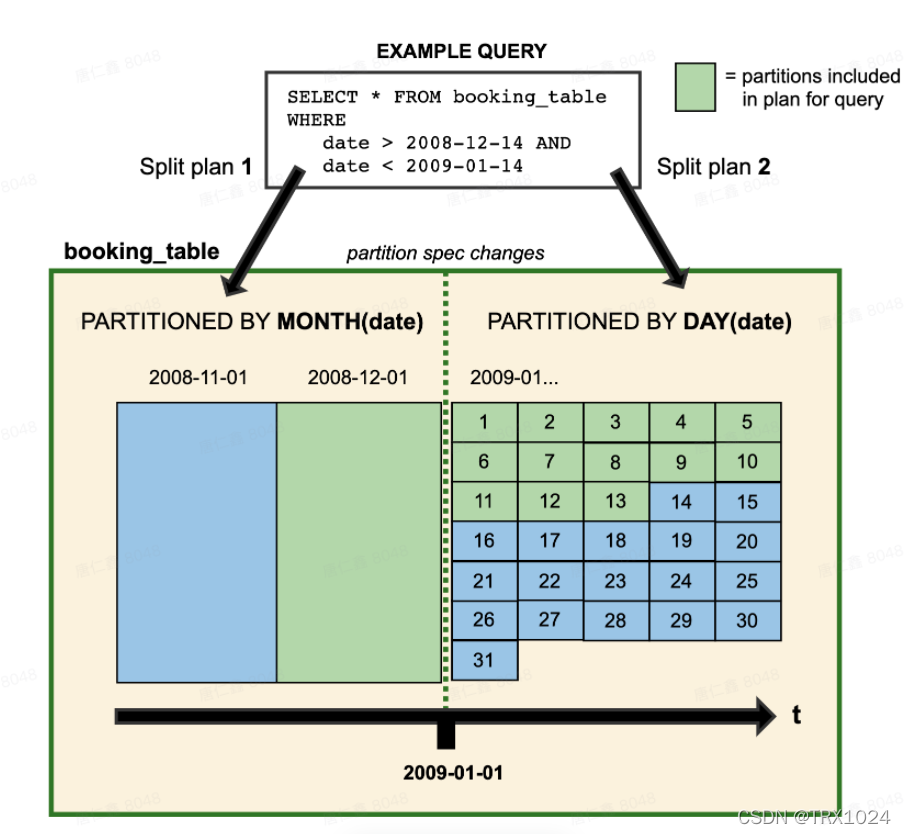
通过 Iceberg 隐式分区,我们将表分区从物理的目录结构和逻辑上分区进行分离,因此 Iceberg 可以更好的进行分区的变更。如下图所示,当我们将分区由按月分区调整为按天分区后,旧分区的目录结构保持不变,新数据将会使用新的目录结构写入。当进行查询时,会根据分区的不同分别执行不同的查询计划。
六、行级更新
Iceberg 表的一大亮点是提供了 OLAP 场景下列式存储数据集的更新和删除的能力。由于 Iceberg 表支持更新和删除,因此你可以将 Changelog (如 Binlog 数据) 导入到 Iceberg 表中进行分析,同时也可以操作 Iceberg 表以更新或删除某一行或者一批数据。而在 Hive 中,由于 Hive 不支持更新,因此每次只能全量写入,浪费了计算资源,且存在较多的冗余数据。
Iceberg 表的更新是采用 MOR (Merge on Read) 模式来实现的,任何的更新和删除操作并不会对原数据文件进行操作,而是采用追加的形式写入到另一个文件中(Delete File),在读取时进行 Merge 操作以获取正确的结果。
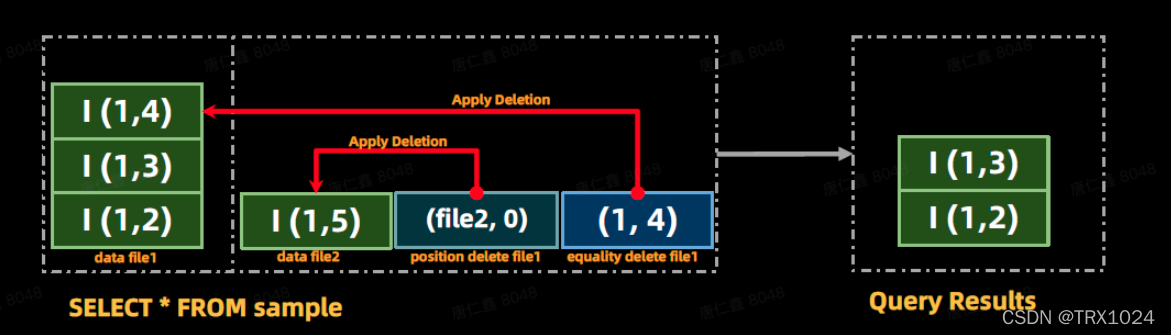
七、Snapshots 与Time travel
由于 Iceberg 多版本的设计,允许用户在多个快照之间进行切换。通过 Time travel 用户可以实现如下操作:
-
历史数据查询:指定某一个 Snapshot 来查询某一时刻的快照数据
-
增量消费:指定起始和终止的 Snapshot,查询某时间内新增的数据
-
回滚:当出现脏数据时可以回滚到某一个快照
-
回溯:指定某一个快照开始消费以进行回溯数据
此外 Snapshots 记录了本次 Commit 的变更,可以通过查询、监控 Snapshots 的信息以监控数据的并更情况,及时发现数据的质量问题。
SELECT * FROM prod.db.table.snapshots
八、总结
最后我们做一个总结:Iceberg 作为一种表格式,将上层计算引擎和下层存储进行了解耦,使对数据的管理和操作更加灵活;通过 Schema 的强约束和事务性保证了写入数据的一致性问题;得益于良好的文件组织形式,使表分区在逻辑上和物理目录进行了分离,且可以达到文件级别的索引,不需要遍历目录下所有的文件,这大大提升了查询的性能和使用的便捷性。