启动etcd服务
启动etcd时最主要的是需要准备两个没有使用过的端口,这两个端口一个用于etcd之间同步信息,一个用于etcd向客户端提供服务的端口。
因此启动单个etcd节点,只需按照如下命令行输入即可
server -name myetcd1 -listen-client-urls http://0.0.0.0:12379 \
-advertise-client-urls http://0.0.0.0:12379 \
-listen-peer-urls http://0.0.0.0:12380 \
-initial-advertise-peer-urls http://0.0.0.0:12380 \
-initial-cluster myetcd1=http://0.0.0.0:12380
其中listen-client-urls的端口是客户端连接的端口,listen-peer-urls指定的端口是etcd之间同步数据使用的,并且在注册集群的时候,集群指定的端口也是etcd之间同步数据使用的端口
-initial-cluster myetcd1=http://0.0.0.0:12380
如何启动一个etcd集群
对etcd的操作
官方提供了etcdctl来连接etcd,使用etcdctl连接etcd很简单,只需要提供指定的endpoints,然后输入要操作的命令即可
etcdctl --endpoints=$ENDPOINTS get foo
etcdctl --endpoints=$ENDPOINTS --write-out="json" get foo
对etcd数据的增删改查
etcdctl --endpoints=$ENDPOINTS put web1 value1
etcdctl --endpoints=$ENDPOINTS put web2 value2
etcdctl --endpoints=$ENDPOINTS put web3 value3
etcdctl --endpoints=$ENDPOINTS get web --prefix
etcdctl --endpoints=$ENDPOINTS put key myvalue
etcdctl --endpoints=$ENDPOINTS del key
etcdctl --endpoints=$ENDPOINTS put k1 value1
etcdctl --endpoints=$ENDPOINTS put k2 value2
etcdctl --endpoints=$ENDPOINTS del k --prefix
事务型操作
etcdctl --endpoints=$ENDPOINTS put user1 bad
etcdctl --endpoints=$ENDPOINTS txn --interactive
compares:
value("user1") = "bad"
success requests (get, put, delete):
del user1
failure requests (get, put, delete):
put user1 good
对数据进行监听
// 在一个控制端上监听指定数据
etcdctl --endpoints=$ENDPOINTS watch stock1
// 在另外一个控制端上操作数据
etcdctl --endpoints=$ENDPOINTS put stock1 1000
// 在一个控制端上监听所有stock 开头的数据
etcdctl --endpoints=$ENDPOINTS watch stock --prefix
// 在另外一个控制端上操作数据
etcdctl --endpoints=$ENDPOINTS put stock1 10
etcdctl --endpoints=$ENDPOINTS put stock2 20
创建lease并将创建的数据绑定租约上
etcdctl --endpoints=$ENDPOINTS lease grant 300# lease 2be7547fbc6a5afa granted with TTL(300s)
etcdctl --endpoints=$ENDPOINTS put sample value --lease=2be7547fbc6a5afa
etcdctl --endpoints=$ENDPOINTS get sample
etcdctl --endpoints=$ENDPOINTS lease keep-alive 2be7547fbc6a5afa
etcdctl --endpoints=$ENDPOINTS lease revoke 2be7547fbc6a5afa
# or after 300 seconds
etcdctl --endpoints=$ENDPOINTS get sample
etcd提供的分布式锁
// 在一个控制端上创建lock一个Key值
etcdctl --endpoints=$ENDPOINTS lock mutex1
// 另外一个控制端如果想拿到锁,会卡住直到第一个拿到锁的释放锁为止
# another client with the same name blocks
etcdctl --endpoints=$ENDPOINTS lock mutex1
https://etcd.io/docs/v3.5/tutorials/how-to-create-locks/
查看集群状态
etcdctl --write-out=table --endpoints=$ENDPOINTS endpoint status
+------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| 10.240.0.17:2379 | 4917a7ab173fabe7 | 3.5.0 | 45 kB | true | false | 4 | 16726 | 16726 | || 10.240.0.18:2379 | 59796ba9cd1bcd72 | 3.5.0 | 45 kB | false | false | 4 | 16726 | 16726 | || 10.240.0.19:2379 | 94df724b66343e6c | 3.5.0 | 45 kB | false | false | 4 | 16726 | 16726 | |
+------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------|
etcdctl --endpoints=$ENDPOINTS endpoint health
10.240.0.17:2379 is healthy: successfully committed proposal: took = 3.345431ms
10.240.0.19:2379 is healthy: successfully committed proposal: took = 3.767967ms
10.240.0.18:2379 is healthy: successfully committed proposal: took = 4.025451ms
保存etcd快照
etcdctl --write-out=table --endpoints=$ENDPOINTS snapshot status my.db
+---------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+---------+----------+------------+------------+
| c55e8b8 | 9 | 13 | 25 kB |
+---------+----------+------------+------------+
etcdv2升级到etcdv3
# write key in etcd version 2 storeexport ETCDCTL_API=2
etcdctl --endpoints=http://$ENDPOINT set foo bar
# read key in etcd v2
etcdctl --endpoints=$ENDPOINTS --output="json" get foo
# stop etcd node to migrate, one by one# migrate v2 dataexport ETCDCTL_API=3
etcdctl --endpoints=$ENDPOINT migrate --data-dir="default.etcd" --wal-dir="default.etcd/member/wal"# restart etcd node after migrate, one by one# confirm that the key got migrated
etcdctl --endpoints=$ENDPOINTS get /foo
Etcd特性
客户端必须向leader发送请求吗?
raft算法是以Leader为准-强领导权,领导处理所有客户端的请求,但是客户端不需要知道谁是领导,任何的需要一致性的请求就算发发送给follower也会被转发给leader,非一致性请求任何集群成员都能进行处理
listen-<client,peer>-urls, advertise-client-urls or initial-advertise-peer-urls的区别
listen-client-urls and listen-peer-urls是用来etcd服务端绑定用的,是集群之间连接使用的
advertise-client-urls and initial-advertise-peer-urls是etcd客户端连接服务端用的端口,advertise的地址必须是远程机器可访问的,
etcd的个数
原则上来说etcd是没有个数硬性限制的,然而一个etcd集群个数最好不要超过7个节点,根据google的经验来说节点个数最好保持为5个
当出现request ignored (cluster ID mismatch)” 意味着什么?
每个集群都会根据集群初始化配置和用户提供的initial-cluster-token值来生成一个唯一的cluster ID,根据cluster ID etcd能够防止不同集群之间的交叉访问。
当拆除一些旧集群,然后新集群重新使用同样的地址时会出现这些警告。如果旧集群中任何的etcd成员尝试连接新集群,新集群会忽略请求并发出警告,通常通过确保不同集群之间地址不相交可以避免这些警告。
如何解决mvcc: database space exceeded问题
默认情况下,etcd会保存kv值的所有历史信息而不是周期的进行压缩(可通过设置–auto-comaction来实现自动压缩),当存储空间耗尽时etcd会发出空间配额预警警告以防止进一步的写入集群中信息,只要警告持续,etcd就会对请求返回mvcc: database space exceeded
自动压缩空间
# keep one hour of history
$ etcd --auto-compaction-retention=1
碎片整理
在压缩之后数据库会出现碎片,这些碎片会占用一定的内存空间,这些内存空间etcd数据库可以使用,但是在主机上表现还是占用着内存空间,要想这些内存空间再次归还系统,需要对内存碎片空间进行整理并进行内存释放。
碎片整理可以将这些存储空间归还给文件系统,碎片整理是针对单个集群成员发出的,可以避免集群范围内的延迟峰值。
$ etcdctl defrag
Finished defragmenting etcd member[127.0.0.1:2379]
需要注意的是对一个活动节点进行碎片整理会阻塞读写(一个节点在碎片整理重构状态时)
需要注意的是碎片整理的请求并不会在集群上进行复制,因此请求只是应用到了本地的节点,如果需要对整个集群的成员进行碎片整理需要在–endpoints上或–cluster上指定所有成员来对整个集群中成员进行碎片整理
$ etcdctl defrag --cluster
Finished defragmenting etcd member[http://127.0.0.1:2379]
Finished defragmenting etcd member[http://127.0.0.1:22379]
Finished defragmenting etcd member[http://127.0.0.1:32379]
当etcd集群没有运行时可以通过指定文件夹来对指定文件夹进行碎片整理
etcdctl defrag --data-dir <path-to-etcd-data-dir>
etcd配额
默认情况下etcd的配额是2G,但是有些使用特殊的情况下,比如在虚拟机或者其他嵌入式小型设备中本身的磁盘都没有那么大,那么这个时候就需要对etcd的默认配额进行修改来满足特定的场景了
# set a very small 16MB quota
$ etcd --quota-backend-bytes=$((16*1024*1024))
可以用脚本来测试etcd配额不足的情况
# fill keyspace
$ while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL_API=3 etcdctl put key || break; done
...
Error: rpc error: code = 8 desc = etcdserver: mvcc: database space exceeded
# confirm quota space is exceeded
$ ETCDCTL_API=3 etcdctl --write-out=table endpoint status
+----------------+------------------+-----------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+----------------+------------------+-----------+---------+-----------+-----------+------------+
| 127.0.0.1:2379 | bf9071f4639c75cc | 2.3.0+git | 18 MB | true | 2 | 3332 |
+----------------+------------------+-----------+---------+-----------+-----------+------------+
# confirm alarm is raised
$ ETCDCTL_API=3 etcdctl alarm list
memberID:13803658152347727308 alarm:NOSPACE
当出现配额不足时通过压缩和碎片整理来恢复当前etcd
# get current revision
$ rev=$(ETCDCTL_API=3 etcdctl --endpoints=:2379 endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')# compact away all old revisions
$ ETCDCTL_API=3 etcdctl compact $rev
compacted revision 1516# defragment away excessive space
$ ETCDCTL_API=3 etcdctl defrag
Finished defragmenting etcd member[127.0.0.1:2379]# disarm alarm
$ ETCDCTL_API=3 etcdctl alarm disarm
memberID:13803658152347727308 alarm:NOSPACE
# test puts are allowed again
$ ETCDCTL_API=3 etcdctl put newkey 123
OK
etcd的使用场景
服务注册与发现
服务注册发现时分布式系统常见的问题之一,即在同一个分布式系统中找到我们需要的目标服务,建立连接,然后完成整个链路的调度。
用通俗的话来说服务发现就是要知道当前集群中的进程监听的udp或tcp端口,并且通过名字就可以进行查找和连接。etcd主要实现以下三种机制来完成服务发现:
-
强一致性、高可用的服务存储目录。基于Raft算法的etcd天生就是这样一个强一致性高可用的服务存储目录
-
提供注册服务和监控服务健康状态的机制,通过注册key-value值,并且定时保持服务的心跳以达到监控健康状态的效果
-
查找和连接服务的机制,通过在etcd指定的主题下注册服务,也能在对应的主题下查找到
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LBLqDyWx-1679296449075)(https://ny5odfilnr.feishu.cn/space/api/box/stream/download/asynccode/?code=OTdiMTI3YTcwOTZhMjYwMDVkYTA3ZWJlM2M1N2RmMTVfSDRyVFNUVXRra21LSHZQNmtJRnZrcVJXUzJ4WmxzNFdfVG9rZW46Ym94Y25nOXd4QzJjZlVDZk9kUE45S0Q4REJmXzE2NzkyOTU5NzU6MTY3OTI5OTU3NV9WNA)]](https://img-blog.csdnimg.cn/422ccb8cd7ed41e8960f93a4f4562ffe.png)
一个用户的API请求可能会调用多个微服务的资源,这些服务我们可以使用etcd进行注册和服务发现
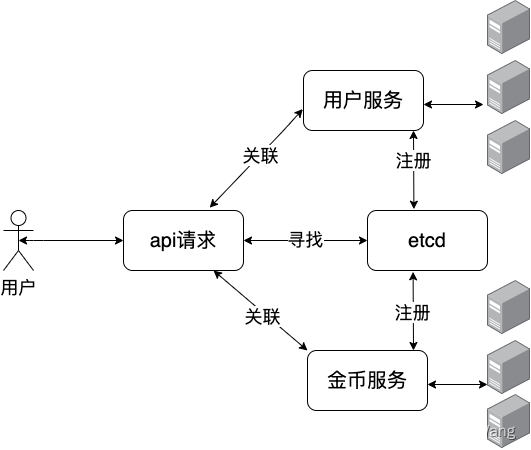
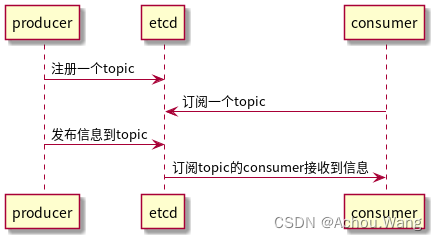
消息发布和订阅
在 分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅,即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者,通过这种方式可以做到分布式系统配置的集中管理与动态更新。
-
应用中用到的一些配置信息放到etcd上进行集中管理。启动时获取一次配置信息,同时注册一个watcher并等待,后期有配置更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的
-
分布式搜索服务,索引元信息和服务器机器的节点状态存放到etcd中
-
分布式日志收集系统
-
系统中的信息需要动态自动获取与人工干预修改信息请求内容的情况
负载均衡
负载均衡通常来说有两种:
etcd上实现是软件上实现的负载均衡,在分布式场景下
ETCD
关注公众号:码上有话了解更多