几个基本概念
Topic
消息主题。
每一条消息都必须要指定主题。kafka集群可以同时进行多个topic的分发。
Broker
消息处理的节点。
可以立即为每个broker是一个单独的kafka进程, 一般部署在不同的机器上, 多个broker共同组成一个集群。
Partition
分区。是topic在物理上的分组。每个partition实际上就是一个目录。
对于同一个topic下的多条消息, 按照一定的规则存储在多个partition上。 对于每个partition而言,消息的存储是有序的,但是对于整个topic而言, 消息的存储是无序的。
Segment
partition在物理上是有多个segment组成。
文件存储方式
topic中partition存储分布
假设当前环境kafka集群只有一个broker, 配置的数据存储根目录是 /data/, 假设现在创建了两个topic, 分别为event_log和alarm_log, partition数量设置的都为4, 则在/data目录下的结构如下:
/data
event_log-0/
event_log_1/
event_log_2/
evnet_log_3/
alarm_log_0/
alarm_log_1/
alarm_log_2/
alarm_log_3/
我们可以看到每个topic按名称分别占据了4个目录,且第一个partition的序号从0开始, 依次递增。
partition中文件存储分布
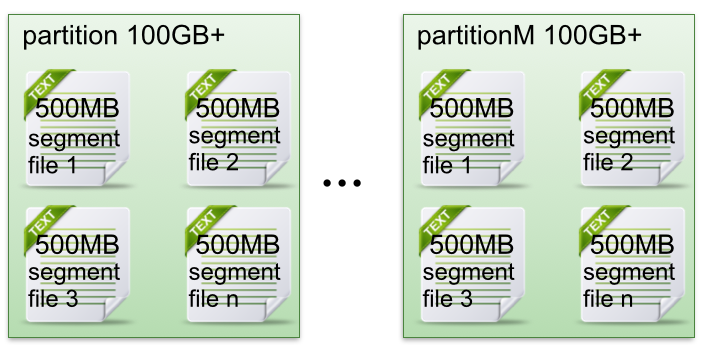
- 每个partition目录下平均分配到多个大小相等segment(段)数据文件。 但每个segment段文件的消息数量不一定相等。
- 每个partition只允许顺序读写。这也是为什么说单个partition存储的消息是有序的。
对于segment文件, 由两部分组成, 且一一对应,成对出现, 分别为:
- index file 索引文件,后缀为index。 存储元数据, 索引文件中的元数据指向对应数据文件中meaage的物理偏移地址。
- data file 数据文件, 后缀为log。 存储message数据
下面是某个partition目录下的存储的segment文件
event_log-0/
0000000000000000000.index
0000000000000000000.log
0000000000000246789.index
0000000000000246789.log
......
其中segment文件的命名规则如下:
- partition全局的第一个segment从0开始
- 后续每个sengment文件名为上一个全局partiitonde的最大offset(偏移message数)
- 19位数字字符长度, 没有用0填充
可以看到data file是由meassage组成的, message的物理结构如下图所示:

| 关键字 |
解释说明 |
| 8 byte offset |
在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size |
message大小 |
| 4 byte CRC32 |
用crc32校验message |
| 1 byte “magic" |
表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes" |
表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length |
表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key |
可选 |
| value bytes payload |
表示实际消息数据。 |
在 partition 中通过 offset 查找 message过程
- 根据 offset 的值,查找 segment 段中的 index 索引文件。由于索引文件命名是以上一个文件的最后一个offset 进行命名的,所以,使用二分查找算法能够根据offset 快速定位到指定的索引文件
- 找到索引文件后,根据 offset 进行定位,找到索引文件中的匹配范围的偏移量position。(kafka 采用稀疏索引的方式来提高查找性能)
- 得到 position 以后,再到对应的 log 文件中,从 position处开始查找 offset 对应的消息,将每条消息的 offset 与目标 offset 进行比较,直到找到消息
比如说,我们要查找 offset=2490 这条消息,那么先找到00000000000000000000.index, 然后找到[2487,49111]这个索引,再到 log 文件中,根据 49111 这个 position 开始查找,比较每条消息的 offset 是否大于等于 2490。最后查找到对应的消息以后返回
kafka特性
顺序写
如果把消息以随机的方式写入到磁盘,那么磁盘首先要做的就是寻址,也就是定位到数据所在的物理地址,在磁盘上就要找到对应的柱面、磁头以及对应的扇区;这个过程相对内存来说会消耗大量时间,为了规避随机读写带来的时间消耗,kafka 采用顺序写的方式存储数据。
零拷贝
一般的拷贝过程如下:
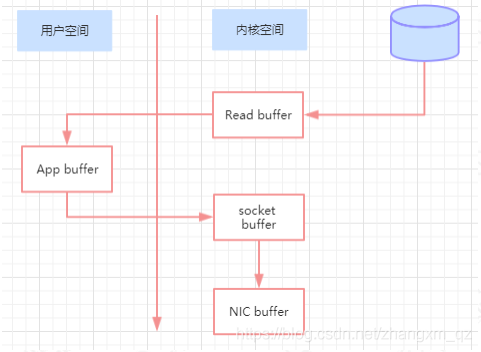
- 操作系统将数据从磁盘读入到内核空间的页缓存
- 应用程序将数据从内核空间读入到用户空间缓存
- 应用程序将数据写回到内核空间到 socket 缓存中
- 操作系统将数据从 socket 缓冲区复制到网卡缓冲区,以便将数据经网络发出
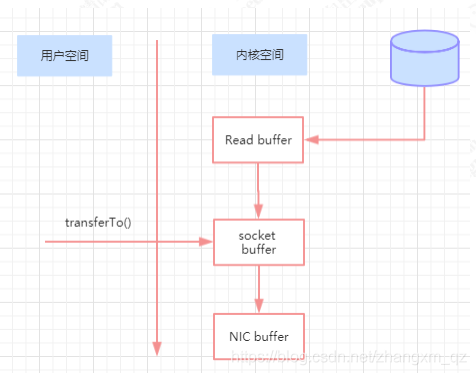
而零拷贝则直接将数据从页缓存传输到 socket, 不需要经过用户空间。
在 Linux 中,是通过 sendfile系统调用来完成的。Java 提供了访问这个系统调用的方法FileChannel.transferTo
参考文章:
https://blog.csdn.net/zhangxm_qz/article/details/87636094