txt标签文件的说明
获取到的数据集是这样的,需要转换为VOC格式,其实就是将txt转换为xml文件:
打开txt文件可以看到以下内容:
1 0.4635416666666667 0.3016666666666667 0.39375 0.48333333333333334
id为1:目标为 mask,
该图片大小:w * h = 480 * 600
0.4635416666666667:【中心点X的比例标注】,480 * 0.4635416666666667 = 222.5 pixel
0.3016666666666667 :【中心点Y的比例标注】 600*0.3016666666666667 = 181.0 pixel
0.39375: 【BOX宽比例标注】0.39375 * 480 = 189 pixel
0.48333333333333334: 【BOX高比例标注】0.48333333333333334 * 600 = 290 pixel
181 / 2 = 90.5
290 / 2 =145
xmin:222.5 - 90.5 = 132
xmax:222.5 + 90.5 = 313
ymin:189 - 145 = 44
ymax:189 + 145 = 334
将jpg与txt文件分开
先将txt和jpg分别分开到txt和picture文件夹下:
相关代码如下:
修改文件后缀,如果是分出txt,则将后缀改为.txt
# -*- coding:utf-8 -*-
import os
import shutil
import sys
import glob
file_type = ".jpg" #文件后缀
from_path = '.\\mask\\' #源文件路径
to_path = '.\\picture\\' #要复制的目标路径
from_path_list = glob.glob(from_path + '*' + file_type)
total = len(from_path_list) # 要复制的文件总数,视情况改
print('复制文件数:',total)
i = 0
interval = 5 # 打算每隔5%变化一次,视需求改
interval_num = int(total / (100 / interval))
# 遍历路径内的文件
for root , dirs, files in os.walk(from_path):
for name in files:
if name.endswith(file_type): # 只复制特定类型文件
# print (os.path.join(root, name))
source = os.path.join(root, name)
target = os.path.join(to_path, name)
try:
shutil.copy(source, target)
except:
print("Copy %s failed!" % name)
# 每隔5%刷新一次屏幕显示的进度百分比
i += 1
if (i % interval_num == 0):
sys.stdout.write("Copy progress: %d%% \r" % (i / interval_num * interval))
sys.stdout.flush()
分开之后的效果
txt生成xml标签文件
读取txt文件,并生成xml文件,代码如下:
from xml.dom.minidom import Document
import os
import cv2
import sys
def makexml(txtPath,xmlPath,picPath): #读取txt路径,xml保存路径,数据集图片所在路径
files_len = get_files_list_len(txtPath)
dict = {'0': "unmask",#字典对类型进行转换,分的种类越多,这里的字典越多
'1': "mask",
'2': "slot_l",
'3': "sink_l",
'4': "chap_l",
'5': "block_l",
'6': "track_l",
'7': "plash",
'8': "block_h"}
files = os.listdir(txtPath)
x = 0
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile=open(txtPath+name)
txtList = txtFile.readlines()
img = cv2.imread(picPath+name[0:-4]+".jpg")
Pheight,Pwidth,Pdepth=img.shape
for i in txtList:
oneline = i.strip().split(" ")
folder = xmlBuilder.createElement("folder")#folder标签
folderContent = xmlBuilder.createTextNode("VOC2007")
folder.appendChild(folderContent)
annotation.appendChild(folder)
filename = xmlBuilder.createElement("filename")#filename标签
filenameContent = xmlBuilder.createTextNode(name[0:-4]+".jpg")
filename.appendChild(filenameContent)
annotation.appendChild(filename)
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthContent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthContent)
size.appendChild(width)
height = xmlBuilder.createElement("height") # size子标签height
heightContent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightContent)
size.appendChild(height)
depth = xmlBuilder.createElement("depth") # size子标签depth
depthContent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthContent)
size.appendChild(depth)
annotation.appendChild(size)
object = xmlBuilder.createElement("object")
picname = xmlBuilder.createElement("name")
nameContent = xmlBuilder.createTextNode(dict[oneline[0]])
picname.appendChild(nameContent)
object.appendChild(picname)
pose = xmlBuilder.createElement("pose")
poseContent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(poseContent)
object.appendChild(pose)
truncated = xmlBuilder.createElement("truncated")
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
difficult = xmlBuilder.createElement("difficult")
difficultContent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultContent)
object.appendChild(difficult)
bndbox = xmlBuilder.createElement("bndbox")
xmin = xmlBuilder.createElement("xmin")
mathData=int(((float(oneline[1]))*Pwidth+1)-(float(oneline[3]))*0.5*Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
ymin = xmlBuilder.createElement("ymin")
mathData = int(((float(oneline[2]))*Pheight+1)-(float(oneline[4]))*0.5*Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
xmax = xmlBuilder.createElement("xmax")
mathData = int(((float(oneline[1]))*Pwidth+1)+(float(oneline[3]))*0.5*Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
ymax = xmlBuilder.createElement("ymax")
mathData = int(((float(oneline[2]))*Pheight+1)+(float(oneline[4]))*0.5*Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
f = open(xmlPath+name[0:-4]+".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
show(files_len,x)
x = x+1
#获取文件总数
def get_files_list_len(txtPath):
from_path_list = os.listdir(txtPath)
total = len(from_path_list) # 文件总数
print('复制文件数:',total)
return total
#转换为xml时的进度显示
def show(files_len,x):
interval = 5 # 打算每隔5%变化一次,视需求改
interval_num = int(files_len / (100 / interval))
if (x % interval_num == 0):
sys.stdout.write("Copy progress: %d%% \r" % (x / interval_num * interval))
sys.stdout.flush()
if __name__ == '__main__':
#makexml("txt所在文件夹","xml保存地址","图片所在地址")
makexml(".\\txt\\",".\\xml\\",".\\picture\\")
生成后的效果;
xml标签详解
获取后得到的xml标签详解:
<annotation>
<folder>VOC2007</folder> #文件夹
<filename>test_00000002.jpg</filename> #图片名称
<size> #图片大小
<width>480</width>
<height>600</height>
<depth>3</depth> #图片维度
</size>
<object>
<name>mask</name> #类别名称
<pose>Unspecified</pose> #拍摄角度
<truncated>0</truncated> #是否被裁减,0表示完整,1表示不完整
<difficult>0</difficult> #是否容易识别,0表示容易,1表示困难
<bndbox> #先验框的位置
<xmin>129</xmin>
<ymin>37</ymin>
<xmax>318</xmax>
<ymax>327</ymax>
</bndbox>
</object>
</annotation>
xml标签生成txt
#!/usr/bin/evn python
#coding:utf-8
import os
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
import sys
#获取文件总数
def get_files_list_len(txtPath):
from_path_list = os.listdir(txtPath)
total = len(from_path_list) # 文件总数
print('复制文件数:',total)
return total, from_path_list
#处理进度显示
def show(files_len,x):
interval = 5 # 打算每隔5%变化一次,视需求改
interval_num = int(files_len / (100 / interval))
if (x % interval_num == 0):
sys.stdout.write("Copy progress: %d%% \r" % (x / interval_num * interval))
sys.stdout.flush()
#读取xml标签,处理为txt文件
def xml_to_txt(xml_path,txt_path):
files_len,from_path_list = get_files_list_len(xml_path)
for i in range(files_len):
#file_srx = open() #其中包含所有待计算的文件名
#print(from_path_list[i])
#print(line)
#f = line[:-1] # 除去末尾的换行符
tree = ET.parse('.\\xml\\' + from_path_list[i]) #打开xml文档
root = tree.getroot() #获得root节点
#print ("*"*10)
filename = root.find('filename').text
filename = filename[:-4]
#print (filename)
file_object = open(txt_path + filename + ".txt", 'w') #写文件
file_object_log = open(txt_path + filename + ".log", 'w') #写文件
flag = False
########################################
for size in root.findall('size'): #找到root节点下的size节点
width = size.find('width').text #子节点下节点width的值
height = size.find('height').text #子节点下节点height的值
#print (width, height)
########################################
for object in root.findall('object'): #找到root节点下的所有object节点
name = object.find('name').text #子节点下节点name的值
#print (name)
bndbox = object.find('bndbox') #子节点下属性bndbox的值
xmin = bndbox.find('xmin').text
ymin = bndbox.find('ymin').text
xmax = bndbox.find('xmax').text
ymax = bndbox.find('ymax').text
#print (xmin, ymin, xmax, ymax)
file_object.write(name+' '+ xmin +' ' + ymin + ' ' + xmax + ' ' + ymax)
# if name == ("bicycle" or "motorbike"):
#file_object.write("Cyclist" + " 0 0 0 " + xmin + ".00 " + ymin + ".00 " + xmax + ".00 " + ymax + ".00 " + "0 0 0 0 0 0 0" + "\n")
# file_object_log.write(str(float(int(xmax) - int(xmin)) * 1920.0 / float(width)) + " " + str(float(int(ymax) - int(ymin)) * 1080.0 / float(height)) + "\n")
# flag = True
# if name == ("car"):
#file_object.write("Car" + " 0 0 0 " + xmin + ".00 " + ymin + ".00 " + xmax + ".00 " + ymax + ".00 " + "0 0 0 0 0 0 0" + "\n")
# file_object_log.write(str(float(int(xmax) - int(xmin)) * 1920.0 / float(width)) + " " + str(float(int(ymax) - int(ymin)) * 1080.0 / float(height)) + "\n")
# flag = True
# if name == ("person"):
#file_object.write("Pedestrian" + " 0 0 0 " + xmin + ".00 " + ymin + ".00 " + xmax + ".00 " + ymax + ".00 " + "0 0 0 0 0 0 0" + "\n")
# file_object_log.write(str(float(int(xmax) - int(xmin)) * 1920.0 / float(width)) + " " + str(float(int(ymax) - int(ymin)) * 1080.0 / float(height)) + "\n")
# flag = True
#file_object.close( )
file_object_log.close()
if flag == False: #如果没有符合条件的信息,则删掉相应的txt文件以及jpg文件
#os.remove(filename + ".txt")
#os.remove(filename + ".jpg")
os.remove(txt_path + filename + ".log")
#line = file_srx.readline()
show(files_len,i)
if __name__ == '__main__':
xml_path = '.\\xml' #读取xml路径
txt_path = '.\\to_txt\\' #保存txt路径
xml_to_txt(xml_path,txt_path)
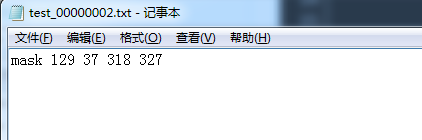
运行后效果如图
参考文献:
https://www.jianshu.com/p/c5b98b2cb7ff
https://zhuanlan.zhihu.com/p/58392978
https://blog.csdn.net/weixin_39875161/article/details/92846873
https://blog.csdn.net/xiao_lxl/article/details/85342707
https://www.cnblogs.com/rainsoul/p/6283231.html