一、写在前面
最近在文秘工作中,碰到一个名字排序的问题,大概的规则:
(1)按照第一个汉字的首字母的英文单词排序,从A-Z;
(2)若第一个字的首字母一致,则比较二个字的首字母,同样是A-Z;
(3)若第二个字的首字母一致,则比较三个字的首字母,同样是A-Z;
想着GPT能否直接生成?下面我们来试一试:
二、尝试过程
(1)先用GPT随机生成30个名字
随机名单如下(这些名字都是随机生成的):
李威廉
张曼
王子
赵星辰
刘晓雨
孙晨曦
周慧
吴子
郑嘉仪
冯雅婷
陈思源
褚建国
卫子轩
蒋昊
沈冰
韩晓飞
杨天佑
朱晓
秦婉
何宇翔
钱晓明
孟春花
黄宇
高晨
杜鸿
文雅琪
赖志强
潘嘉
郭子涵
曾晓
(2)先用GPT-4直接进行排序(不开插件)
写一个咒语:请给{名单}做一个排序,要求:(1)按照第一个字的首字母的英文单词排序,从A-Z;(2)若第一个字的首字母一致,则比较二个字的首字母,同样是A-Z;(3)若第二个字的首字母一致,则比较三个字的首字母,同样是A-Z;
名单为:{};
输出如下:

可以看到,排序是混乱不堪的,比如第28名,明显不是最后一名。个人觉得可能的两个原因:首先,GPT的数学能力公认的不强;其次,咒语可能写的不好,直接让TA一步到位地输出结果,很容易出错(这个在吴恩达的教程有提到过)。
所以,下一步,我们针对性地进行尝试:
(3)使用Wolfram插件
咒语同上:
可以看到,我的Wolfram插件不知啥原因,并没有正常工作。重复了几次也没有,因此,我放弃了这个选项。
(4)优化咒语(不使用插件)
写一个咒语:请给{名单}做一个排序,要求:(1)按照第一个字的首字母的英文单词排序,从A-Z;(2)若第一个字的首字母一致,则比较二个字的首字母,同样是A-Z;(3)若第二个字的首字母一致,则比较三个字的首字母,同样是A-Z;
名单为:{};
请一步一步地分析,不急着输出答案。
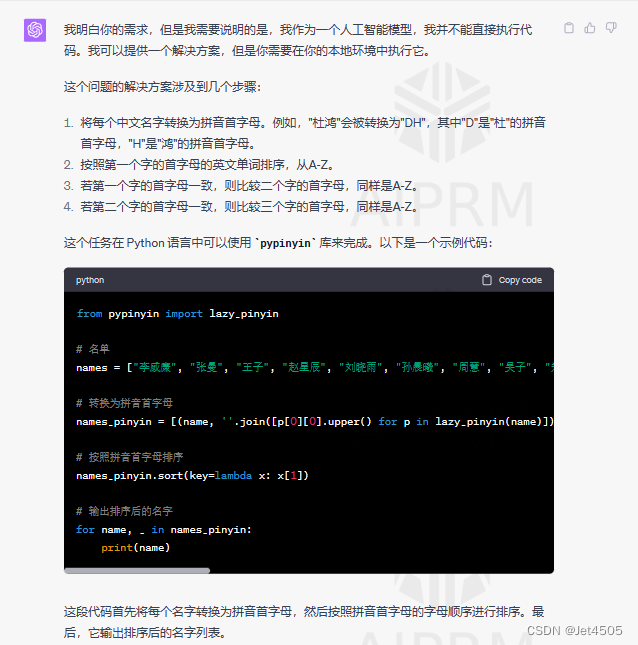
建议步骤:(2)先把中文名字转换成汉语拼音首字母在排序,例如杜鸿转换成DH,第一个字的首字母是D,以此类推;(2)按照第一个字的首字母的英文单词排序,从A-Z;(3)若第一个字的首字母一致,则比较二个字的首字母,同样是A-Z;(4)若第二个字的首字母一致,则比较三个字的首字母,同样是A-Z。
神奇的事情发生了,GPT-4直接说做不了,建议用Python:
然后,我退而求其次,使用GPT-3.5:
是按照步骤来了,但是每一部都有错漏:

第一个的首字母都提取错了;
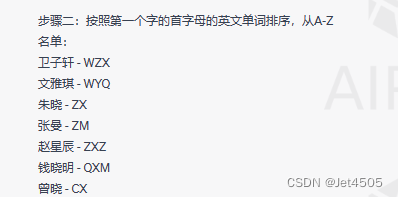
第二步的排序也有问题,再下面就不用看了。
看来GPT在解决这类问题还是不太擅长。
(5)使用Python实现
按照GPT的建议,使用下面代码:
from pypinyin import lazy_pinyin
# 名单
names = ["李威廉", "张曼", "王子", "赵星辰", "刘晓雨", "孙晨曦", "周慧", "吴子", "郑嘉仪", "冯雅婷", "陈思源", "褚建国", "卫子轩", "蒋昊", "沈冰", "韩晓飞", "杨天佑", "朱晓", "秦婉", "何宇翔", "钱晓明", "孟春花", "黄宇", "高晨", "杜鸿", "文雅琪", "赖志强", "潘嘉", "郭子涵", "曾晓"]
# 转换为拼音首字母
names_pinyin = [(name, ''.join([p[0][0].upper() for p in lazy_pinyin(name)])) for name in names]
# 按照拼音首字母排序
names_pinyin.sort(key=lambda x: x[1])
# 输出排序后的名字
for name, _ in names_pinyin:
print(name)
看看输出的结果,大体上应该是对的:
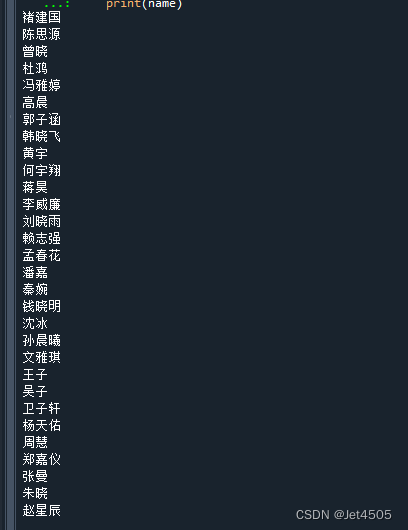
当然,使用这个规则有一定缺陷,比如“吴子”和“王子”都是“WZ”,又如何排序呢?又比如后面的“卫子轩”是“WZX”,比前面多了一个“X”,又改怎么排?因此,还需要继续优化规则才行。
所以,我想试一试用笔画来排序。
(6)使用笔画排序
写一个咒语:请给{名单}做一个排序,要求:(1)按照第一个汉字的笔画数目排序,从小到大;(2)若第一个汉字的笔画数目一致,则比较二个字的笔画数目,同样是从小到大;(3)若第二个汉字的笔画数目一致,则比较三个字的笔画数目,同样是从小到大;(4)若名字只有两个汉字,则它的第三个汉字定义为0画;
名单为:{};
(a)GPT-4直接说做不了,就算是Wolfram插件也不行,给了Pyhton代码,后面我再使用;
(b)给GPT-4联网,神奇的事情发生了,TA居然去联网去找笔画:
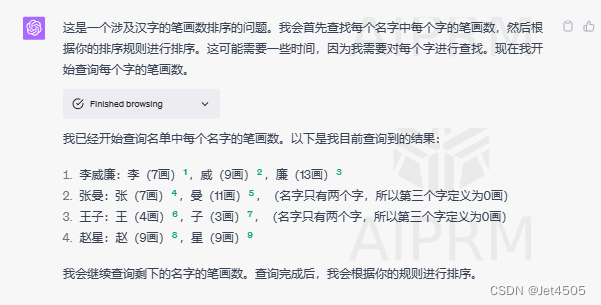
还不错,就是有点慢,不对,是很慢,因为TA是一个字查的,笑死我了:
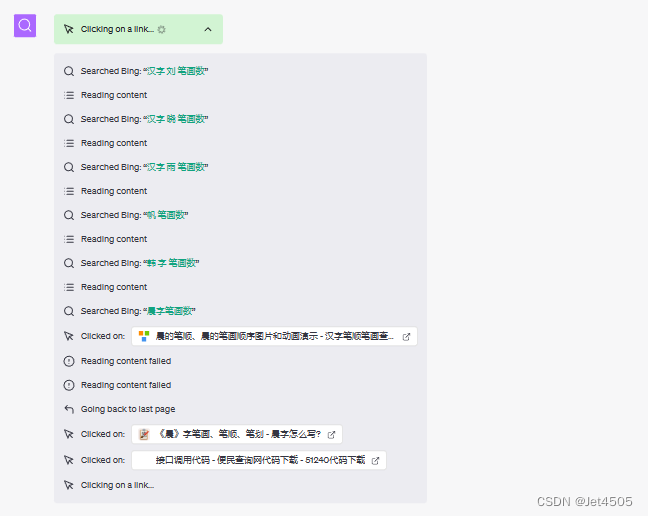
工作量实在太大,TA自己也放弃了,这一策略不行。
(c)尝试GPT-3.5:
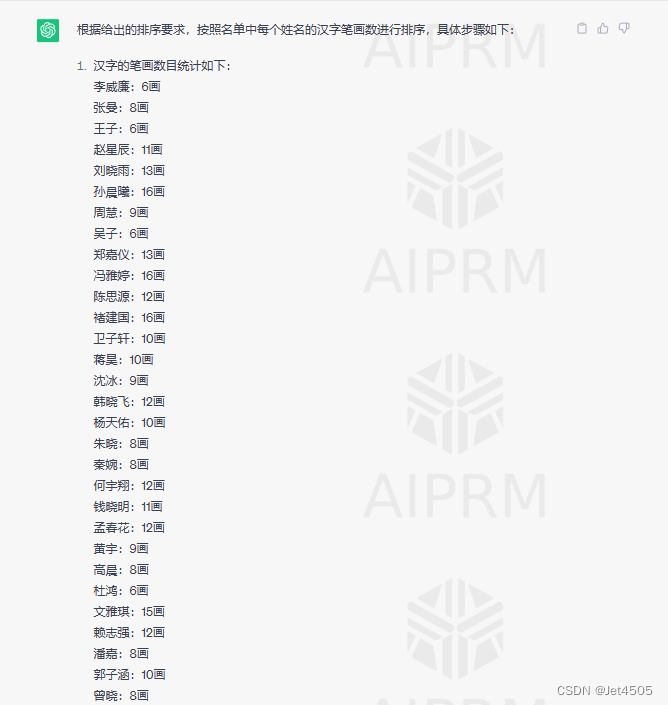

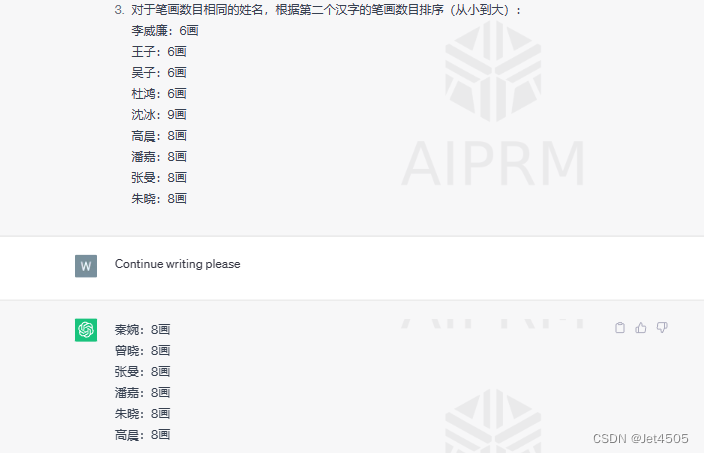

思路是对的,但是笔画数错了。
(d)换回Python:
import pypinyin
import unicodedata
names = ["李威廉", "张曼", "王子", "赵星辰", "刘晓雨", "孙晨曦", "周慧", "吴子", "郑嘉仪", "冯雅婷", "陈思源", "褚建国", "卫子轩", "蒋昊", "沈冰", "韩晓飞", "杨天佑", "朱晓", "秦婉", "何宇翔", "钱晓明", "孟春花", "黄宇", "高晨", "杜鸿", "文雅琪", "赖志强", "潘嘉", "郭子涵", "曾晓"]
def stroke_count(char):
return unicodedata.east_asian_width(char)
def get_stroke_count(name):
return [stroke_count(char) for char in name]
names_strokes = [(name, get_stroke_count(name)) for name in names]
names_strokes.sort(key=lambda x: (x[1][0], x[1][1] if len(x[1]) > 1 else 0, x[1][2] if len(x[1]) > 2 else 0))
for name, _ in names_strokes:
print(name)
看看结果:
报错了:TypeError: '<' not supported between instances of 'int' and 'str'
GPT给的解释在于:计算汉字的笔画数是一个复杂的问题,需要一个完整的汉字-笔画数映射表。这个映射表可以从 Unicode 字符数据库(UCD)或其他类似的数据源获取。我建议你寻找一个包含汉字-笔画数映射表的库,或者使用一个外部的数据源,比如 Unicode 字符数据库(UCD)。
我问TA Unicode 字符数据库(UCD)如何调取?
GPT说:Unicode 字符数据库(UCD)是一个包含了所有 Unicode 字符的各种属性的数据库,包括字符的名称、分类、大小写映射、笔画数等。然而,UCD 并没有提供一个直接的 API 或者函数库来查询这些属性。你需要下载 UCD 的数据文件,然后在你的程序中解析这些文件。
在 Python 中,你可以使用 unicodedata 库来查询一些基本的 Unicode 属性,但是这个库并不包括笔画数。对于笔画数,你可能需要找到一个专门的库,或者自己创建一个汉字到笔画数的映射表。
我建议你查找一些专门的汉字处理库,或者使用一些在线的 API 服务。例如,汉典网(zdic.net)提供了一个查询汉字笔画数的在线服务,你可以在你的程序中调用这个服务。但是,请注意,这可能需要你对网络编程和网页抓取有一些基本的了解。
嗯,听起来很麻烦,我就不继续弄了。
三、关于Token
网上也有测试,就是让GPT把句子倒着输出,TA是不能实现的:
比如说:请按照下面规则进行转换,例如{TA是不能实现的}换成{的现实能不是AT},那么{就是让GPT把句子倒着输出}会转换成什么?
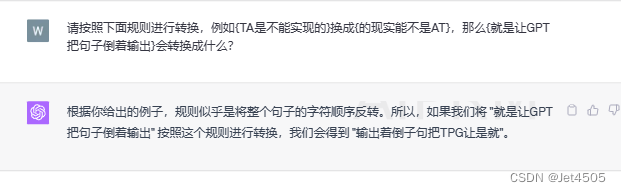
发现了吧,TA其实是理解规则了“规则似乎是将整个句子的字符顺序反转”,但是,结果是不对的,“输出着倒子句把TPG让是就”,可以看到,“输出”并没有转换过来。因为在GPT看来,“输出”是一个字符。也就是Token,在计算机科学和语言处理中,"Token"(标记)是一个非常基础的概念,它通常指的是一段程序、文本或语句中的一个独立的部分,这个部分在语义上是有意义的。
例如,句子"The cat sat on the mat."可以被分割成这样的Token:["The", "cat", "sat", "on", "the", "mat", "."]。这个过程被称为Tokenization(标记化或分词)。
四、写在最后
基于上述原因,GPT在处理这类问题的时候,往往比较懵逼。可能GPT-4也意识到这个问题,直接推荐用Python来解决吧。当然,TA的数学能力也有待加强,而且TA不能自己运行代码,未来看看使用Code interpreter插件能否解决类似问题。