B站评论采集
打开目标网址
哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
找到爬取得剧的评论,打开浏览器抓包工具进行抓包分析:
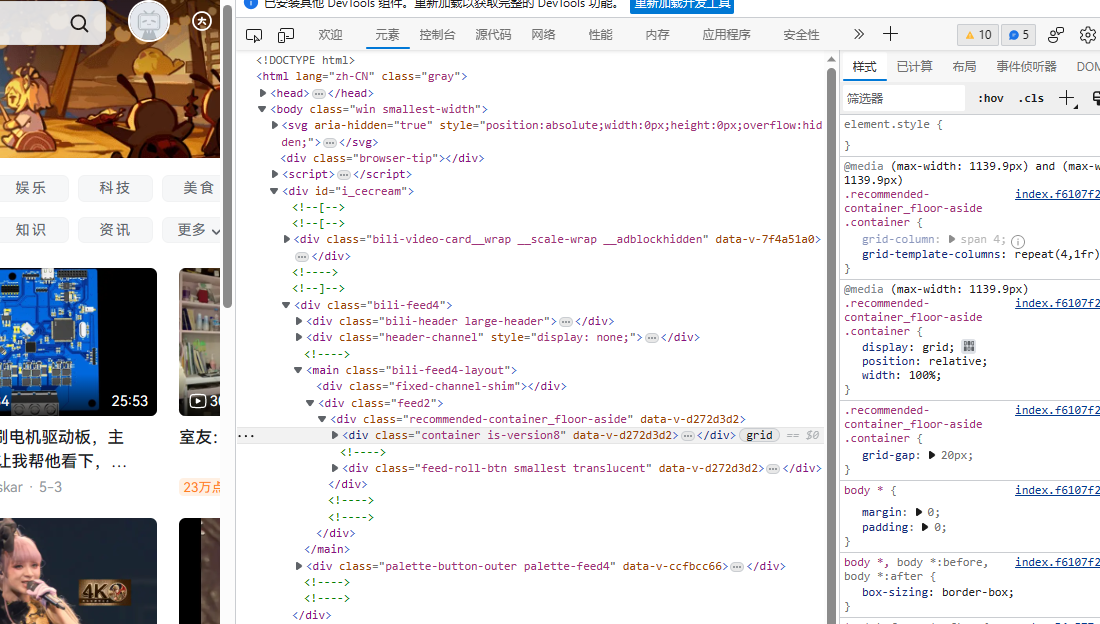
这里爬取鬼灭之刃第一季的评论数据,
分析网页
打开评论页面,可以看到分为短评(128702)和长评(639)条。常规操作直接F12打开网络观察发送的请求数据。
在评论页面往下翻几下就可以看到有个url是“list?“开头的,点开预览果然就是哔哩哔哩评论的api了。找到了api就很好办了,直接分析一下api的组成和需要传递的参数。
分析b站api
复制代码 隐藏代码
https://api.bilibili.com/pgc/review/short/list?media_id=22718131&ps=20&sort=0&cursor=83215035767195
观察一下链接,有个short字段,这个就是对应的短评,如果换成long就是长评。
”ps=20“就是一页的数据。”media_id=22718131“就是番剧的id。
”cursor“字段就是数据的地址,每次请求数据返回的json数据都会有下一页的cursor。
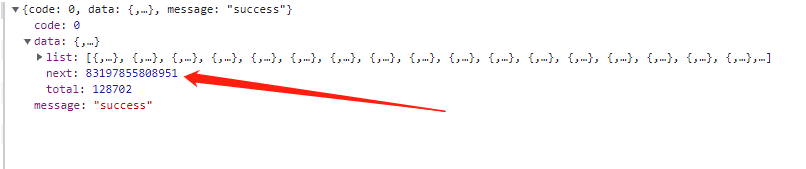
下面就是用requests进行请求写代码
先导入库:
import requests
import json
import time
import csv
爬取代码:
def levels_get(mid, proxies):
url = f'https://api.bilibili.com/x/space/wbi/acc/info?mid={str(mid)}'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'cookie': "_uuid=B31794AC-389B-5ABE-431A-4A457532710F563197infoc; buvid3=90E810B6-24C7-0FD9-FCEB-FFAAD82CE42266124infoc; b_nut=1666688064; buvid4=C5894024-2549-4CC5-B6CC-4CE4F3C6025F66124-022102516-ueloTil9hhszmIQpPi1hPg==; buvid_fp_plain=undefined; i-wanna-go-back=-1; nostalgia_conf=-1; rpdid=|(u))umkR)l|0J'uYY)Y~lkkl; bsource=search_google; LIVE_BUVID=AUTO2616698028069789; is-2022-channel=1; CURRENT_BLACKGAP=0; CURRENT_FNVAL=4048; CURRENT_QUALITY=120; fingerprint=5fdc996e8cc80fd6b9c56ffc54ce7181; sid=8dtevv76; bp_video_offset_83512806=744605732851155000; buvid_fp=5fdc996e8cc80fd6b9c56ffc54ce7181; b_lsid=F72104910B_18557CE9216; b_ut=7; innersign=1; PVID=8",
}
try:
rs = requests.get(url, headers=header,proxies=proxies)
except:
proxies = gengxin()
rs = requests.get(url, headers=header, proxies=proxies, timeout=10)
datad = json.loads(rs.text)
try:
return datad['data']['level']
except:
return 'Nah'
cursor = 78670930957092
while cursor != '老6':
url = f'https://api.bilibili.com/pgc/review/long/list?media_id=22718131&ps=20&sort=0&cursor={cursor}'
print(url)
while True:
try:
r = requests.get(url, timeout=5)
data = json.loads(r.text)
break
except:
print('请求超时')
time.sleep(1)
for i in data['data']['list']:
uname = i['author']['uname']#用户昵称
userid = i['author']['mid']#用户id
score = i['score']#用户评分
content = i['content']#用户评论内容
time_unix = int(i['mtime'])
times = timefun(time_unix)
# middd = levels_get(userid, proxies)
middd = 'Nah'
print(times, uname, userid, middd, score, content)
with open("test.csv", "a", newline='',encoding='UTF8') as csvfile:
writer = csv.writer(csvfile)
# 写入多行用writerows
writer.writerow([times, uname, userid, middd, score, content])
cursor = data['data']['next']
print(f'下一个页面{cursor}')
完整代码:
import requests
import json
import time
import csv
'''包括评分用户id及会员等级、具体评分星级、长评以及短评的评论内容、评分时间,'''
def timefun(time1):
time1 = int(time1)
timeArray = time.localtime(time1)
times = time.strftime("%Y-%m-%d %H:%M:%S", timeArray) # 时间
return times
def levels_get(mid, proxies):
url = f'https://api.bilibili.com/x/space/wbi/acc/info?mid={str(mid)}'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'cookie': "_uuid=B31794AC-389B-5ABE-431A-4A457532710F563197infoc; buvid3=90E810B6-24C7-0FD9-FCEB-FFAAD82CE42266124infoc; b_nut=1666688064; buvid4=C5894024-2549-4CC5-B6CC-4CE4F3C6025F66124-022102516-ueloTil9hhszmIQpPi1hPg==; buvid_fp_plain=undefined; i-wanna-go-back=-1; nostalgia_conf=-1; rpdid=|(u))umkR)l|0J'uYY)Y~lkkl; bsource=search_google; LIVE_BUVID=AUTO2616698028069789; is-2022-channel=1; CURRENT_BLACKGAP=0; CURRENT_FNVAL=4048; CURRENT_QUALITY=120; fingerprint=5fdc996e8cc80fd6b9c56ffc54ce7181; sid=8dtevv76; bp_video_offset_83512806=744605732851155000; buvid_fp=5fdc996e8cc80fd6b9c56ffc54ce7181; b_lsid=F72104910B_18557CE9216; b_ut=7; innersign=1; PVID=8",
}
try:
rs = requests.get(url, headers=header,proxies=proxies)
except:
proxies = gengxin()
rs = requests.get(url, headers=header, proxies=proxies, timeout=10)
datad = json.loads(rs.text)
try:
return datad['data']['level']
except:
return 'Nah'
cursor = 78670930957092
while cursor != '老6':
url = f'https://api.bilibili.com/pgc/review/long/list?media_id=22718131&ps=20&sort=0&cursor={cursor}'
print(url)
while True:
try:
r = requests.get(url, timeout=5)
data = json.loads(r.text)
break
except:
print('请求超时')
time.sleep(1)
for i in data['data']['list']:
uname = i['author']['uname']#用户昵称
userid = i['author']['mid']#用户id
score = i['score']#用户评分
content = i['content']#用户评论内容
time_unix = int(i['mtime'])
times = timefun(time_unix)
# middd = levels_get(userid, proxies)
middd = 'Nah'
print(times, uname, userid, middd, score, content)
with open("test.csv", "a", newline='',encoding='UTF8') as csvfile:
writer = csv.writer(csvfile)
# 写入多行用writerows
writer.writerow([times, uname, userid, middd, score, content])
cursor = data['data']['next']
print(f'下一个页面{cursor}')