前言
我们通过前面几节的学习已经了解到bs4模块对于我们抓取网页的方便之处,也通过一个实例实践了抓取某网站菜价。本节我们以某图片网为例(链接放评论区),实现抓取唯美壁纸栏目的内容并保存到本地文件夹。
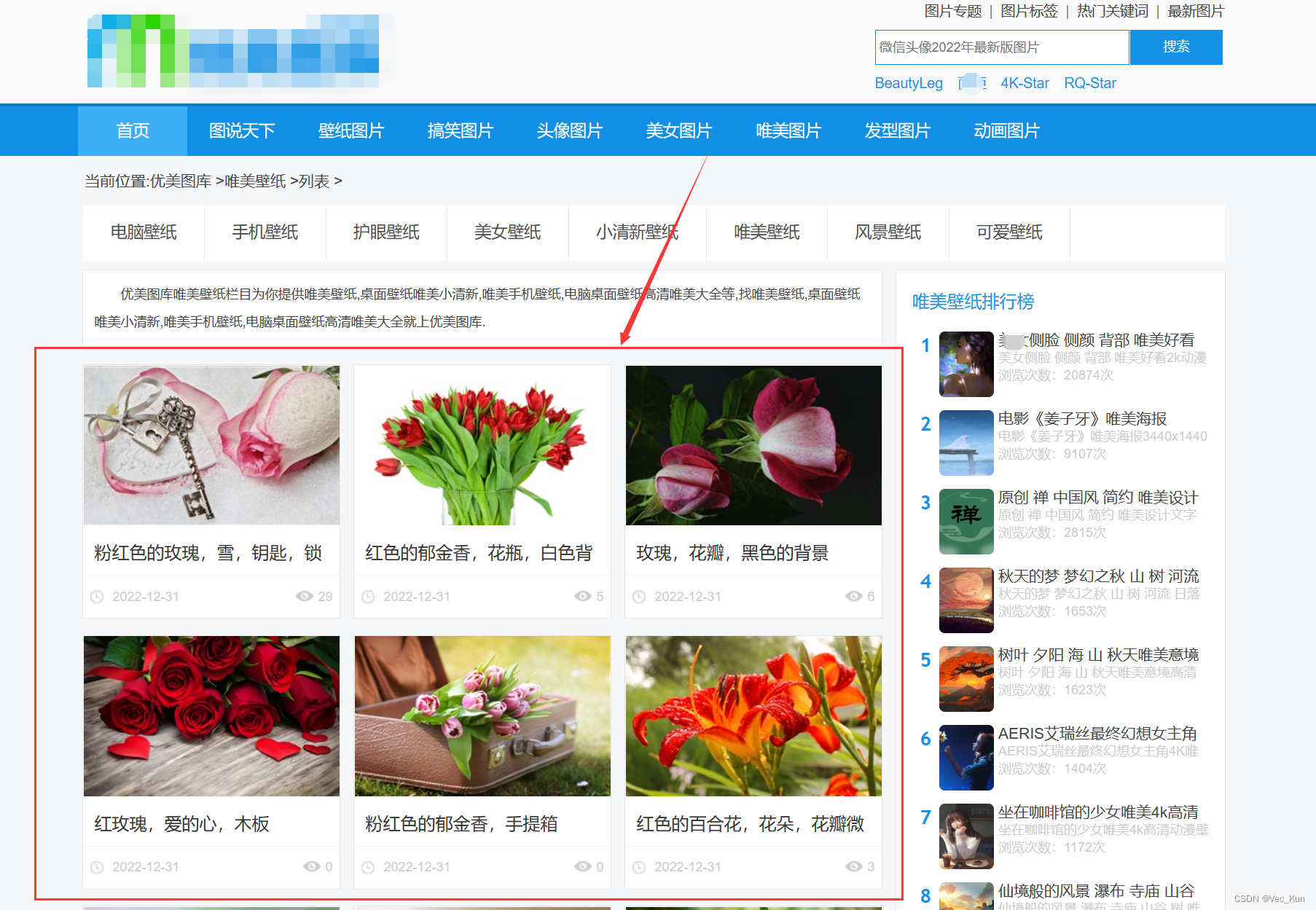 目标
目标
思路
1. 获取所有子页面链接地址
2. 获取子页面中图片资源地址
3. 下载图片
代码实现
第一步,老规矩,先获取页面源代码
import requests
from bs4 import BeautifulSoup
import time
url = "在评论区"
resp = requests.get(url)
resp.encoding = 'utf-8' # 处理乱码
第二步,把源代码扔给BeautifulSoup处理,找到子链接
# 把源代码交给bs
main_page = BeautifulSoup(resp.text, "html.parser")
item_list = main_page.find_all("div", class_="item masonry_brick")
alist = []
for item in item_list:
find = item.find("a")
alist.append(find)
# print(alist)
第三步,遍历访问子链接,获取子页面源代码并拿到图片下载路径
for a in alist:
href = 'https://www.umei.cc/' + a.get('href').strip("/") # 直接通过get就可以拿到属性的值
# 拿到子页面的源代码
child_page_resp = requests.get(href)
child_page_resp.encoding = 'utf-8'
child_page_text = child_page_resp.text
# 从子页面中拿到图片的下载路径
child_page = BeautifulSoup(child_page_text, "html.parser")
div = child_page.find("div", class_="big-pic")
img = div.find("img")
src = img.get("src")
第四步,下载图片
# 下载图片
img_resp = requests.get(src)
# img_resp.content # 这里拿到的是字节
img_name = src.split("/")[-1] # 拿到url中的最后一个/以后的内容
with open("img8/" + img_name, mode="wb") as f:
f.write(img_resp.content) # 图片内容写入文件
print("over!!!", img_name)
time.sleep(1)
print("all over!!!")
下载图片的思路很简单,只需要拿到图片的字节形式,并用二进制方式写入本地文件夹(wb为二进制写,很明显是write byte的缩写嘛)
完整代码
# 1.拿到主页面的源代码. 然后提取到子页面的链接地址, href
# 2.通过href拿到子页面的内容. 从子页面中找到图片的下载地址 img -> src
# 3.下载图片
import requests
from bs4 import BeautifulSoup
import time
url = "见评论区"
resp = requests.get(url)
resp.encoding = 'utf-8' # 处理乱码
# print(resp.text)
# 把源代码交给bs
main_page = BeautifulSoup(resp.text, "html.parser")
item_list = main_page.find_all("div", class_="item masonry_brick")
alist = []
for item in item_list:
find = item.find("a")
alist.append(find)
# print(alist)
for a in alist:
href = 'https://www.umei.cc/' + a.get('href').strip("/") # 直接通过get就可以拿到属性的值
# 拿到子页面的源代码
child_page_resp = requests.get(href)
child_page_resp.encoding = 'utf-8'
child_page_text = child_page_resp.text
# 从子页面中拿到图片的下载路径
child_page = BeautifulSoup(child_page_text, "html.parser")
div = child_page.find("div", class_="big-pic")
img = div.find("img")
src = img.get("src")
# 下载图片
img_resp = requests.get(src)
# img_resp.content # 这里拿到的是字节
img_name = src.split("/")[-1] # 拿到url中的最后一个/以后的内容
with open("img8/" + img_name, mode="wb") as f:
f.write(img_resp.content) # 图片写入文件
print("over!!!", img_name)
time.sleep(1)
print("all over!!!")
运行效果
我爬取了一部分就停了,咱还是悠着点,练练手就好了。

Tips:由于PyCharm每次在项目文件夹有更新时,都会遍历一次文件夹,更新文件索引。我们爬取图片太多的时候,很有可能会在这一步让我们的编译软件越来越卡,所以可以右击创建的img文件夹,选择Mark Directory as...,再选择Excluded,这样就是告诉PyCharm,我们这个文件夹不属于项目调用的范畴,它也就不会每次都花力气对它索引了。

总结
今天我们操作了bs4的一个实战例子,运用bs4模块对某网站的唯美壁纸进行批量下载到本地文件夹的操作,提升了爬虫技术。下一节我们将开始xpath的教学。