While you should make use of the flexibility afforded by scatterplot( ) and relplot( ), always try to keep in mind that several simple plots are usually more effective than one complex plot.
当你利用 scatterplot( )和 relplot( )所提供的灵活性的同时,应当尽可能地记住一些简单图形,这往往比只记住一个复杂的图形会更加有效。 ——Seaborn文档
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
用散点图关联变量 Relating variables with scatter plots
简单的散点图
tips = pd.read_csv('tips.csv') # 读取数据
sns.relplot(x='total_bill', y='tip', data=tips) # 默认参数kind='scatter'
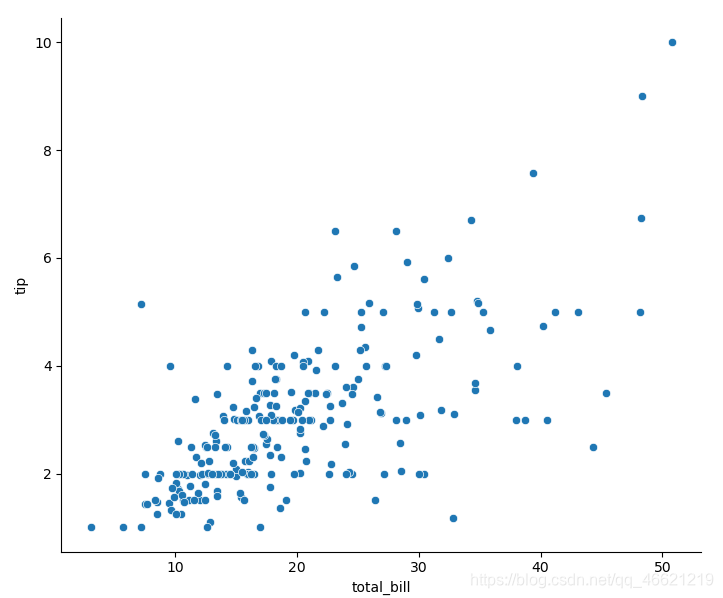
使用语义的散点图
- 我想,Seaborn最为人称道的便是可以通过在代码中设置参数来使用不同的语义(semantic),即让点发生改变,从而简单地在二维图像中增加更多的维度。需要指出的是,这种方法的使用逻辑同样是向语义参数传入的列名即所谓的变量,并且该列名对应的数据应为表示分类含义的数据——这是很重要的。色调语义即改变点的颜色,对应 参数hue :
sns.relplot(data=tips, x='total_bill', y='tip', hue='smoker', data=tips)
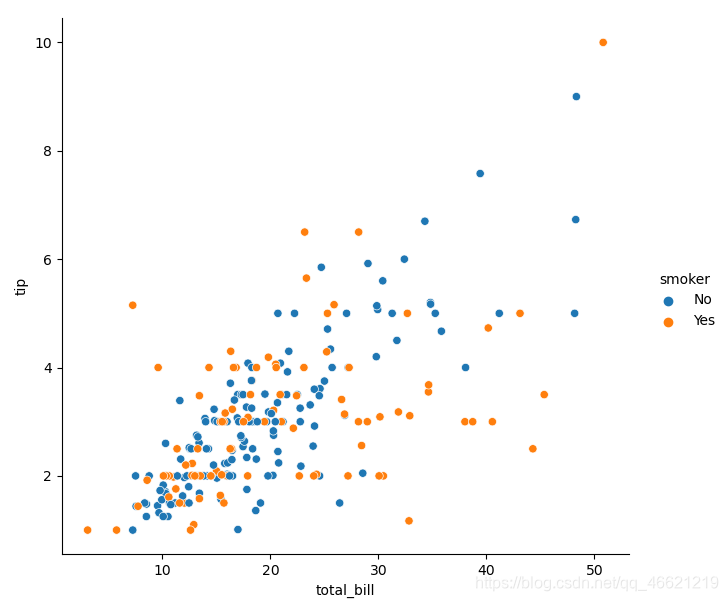
- 当向参数hue所传入的分类数据为数值时,点的着色将会呈现一种渐进的变化:
sns.relplot(data=tips, x='total_bill', y='tip', hue='size')
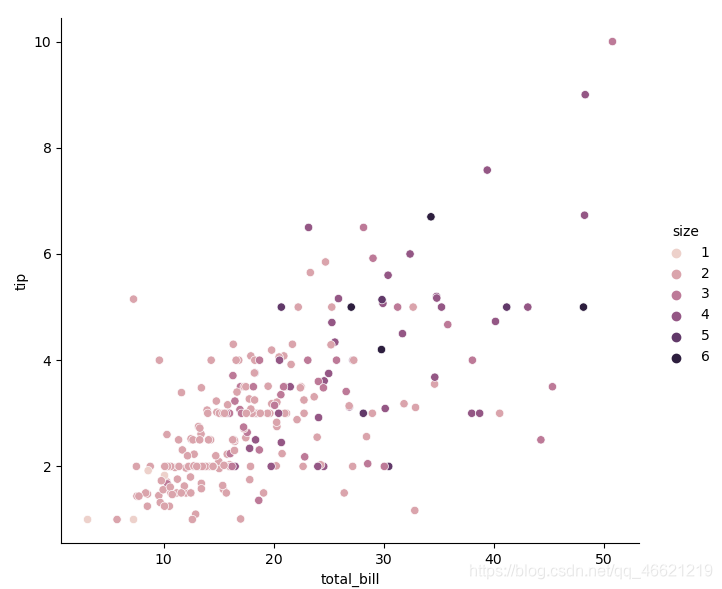
-
样式语义 即改变点的样式(形状),对应 参数style :
sns.relplot(data=tips, x='total_bill', y='tip', style='smoker')
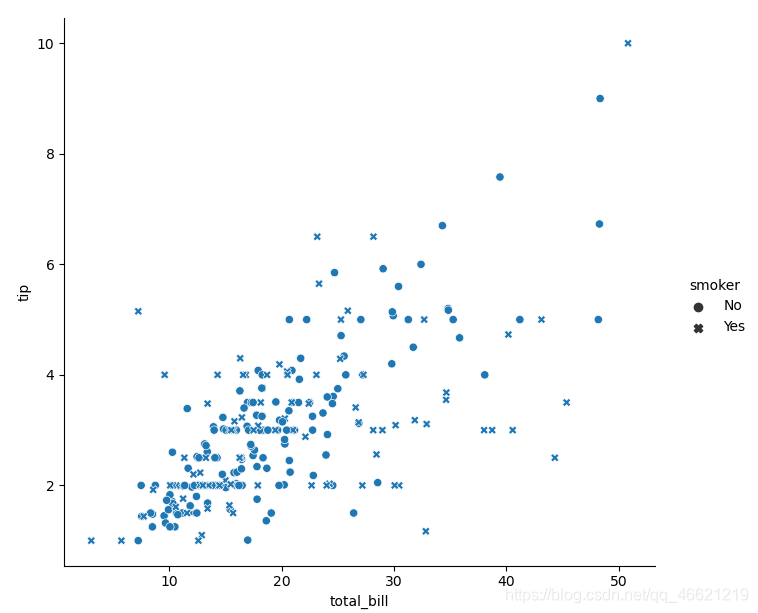
-
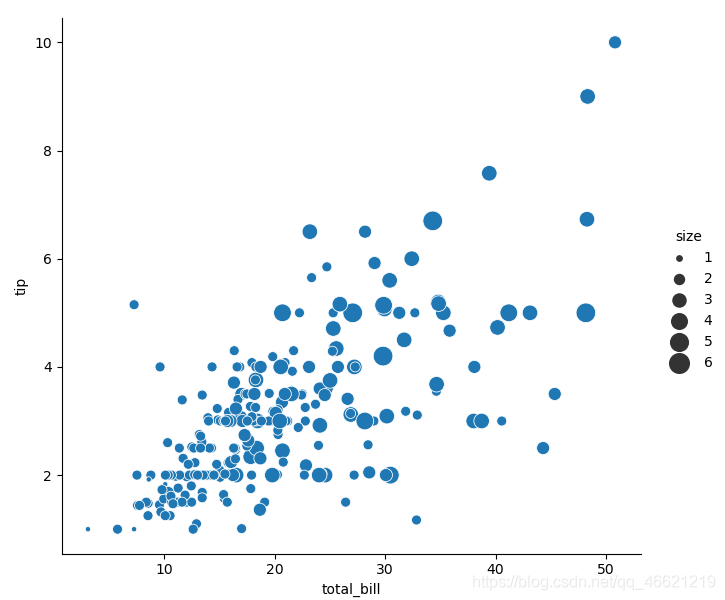
尺寸语义 即改变点的大小(面积),对应 参数size。不同于matplotlib中绘制散点图的函数scatter ( ),点与点之间的相对大小可以由向 参数sizes 传入的范围来控制,而不用取决于数值本身的大小。
sns.relplot(data=tips, x='total_bill', y='tip', hue='size', size='size', sizes=(15, 200))
# 向参数size传入数据集tips的列名size
两个语义对应一个变量
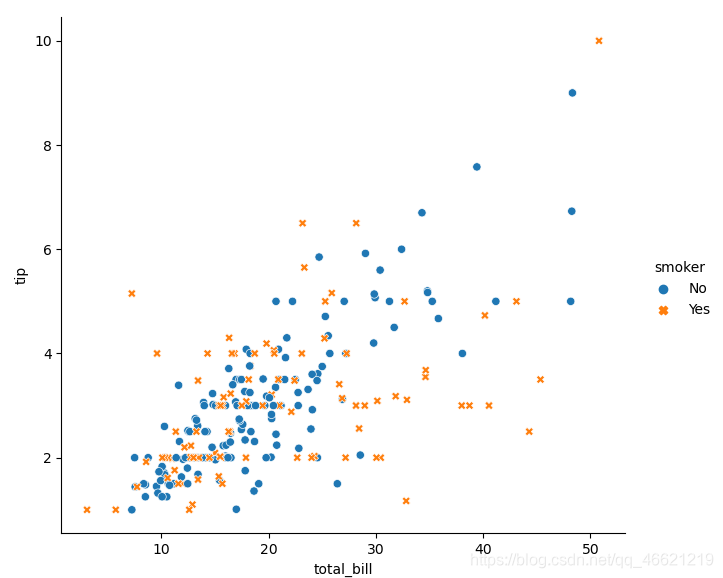
- 如果同时使用色调语义和样式语义,且传入不同的变量,这时生成的二维图像相当于包含了四个变量:
sns.relplot(data=tips, x='total_bill', y='tip', hue='smoker', style='time')

- 显而易见的是,由于我们的眼睛对于形状的敏感度远低于对于颜色的敏感度,圆点与叉点不容易从蓝点与橙点中区分出来。所以,我建议应当对一个变量使用两种语义 ,进而达到更直观的效果:
sns.relplot(data=tips, x='total_bill', y='tip', hue='smoker', style='smoker') # 改变点的颜色和样式
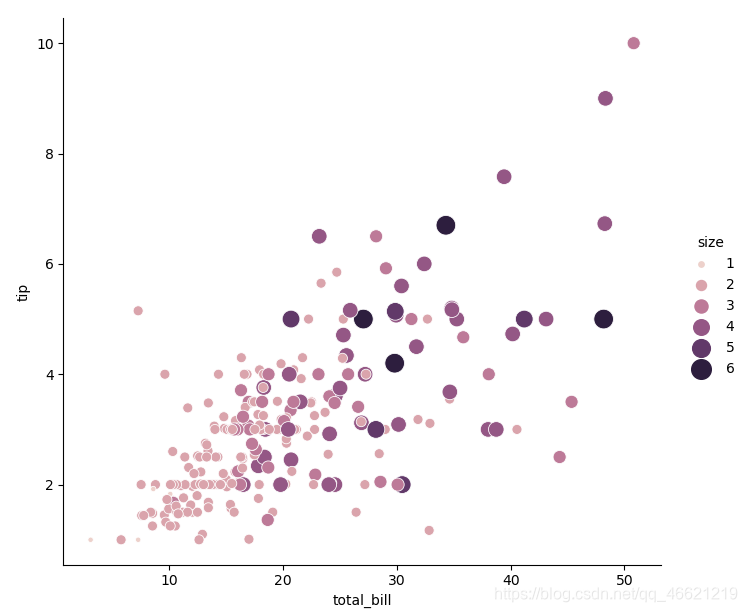
sns.relplot(data=tips, x='total_bill', y='tip', hue='size', size='size', sizes=(15, 200))# 改变点的颜色与大小
用折线图强调连续性 Emphasizing continuity with line plots
简单的折线图
np.random.seed(2021) # 有了这一句便可将生成的随机数组固定下来
df = pd.DataFrame(dict(time=np.arange(500), value=np.random.randn(500).cumsum()))
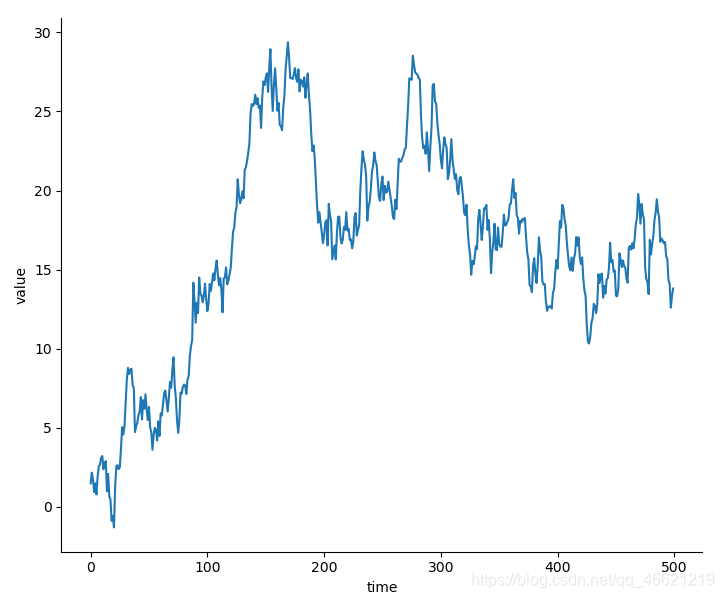
- 在Seaborn中,可以绘制折线图可以直接使用函数lineplot( )或者将函数relplot( )中的 参数kind 设置为’line’,并且其使用逻辑和散点图的绘制没有什么不同。
sns.relplot(x='time', y='value', data=df, kind='line')
- 在默认情况下,函数 relplot( ) 会对横轴变量所对应的数据进行排序后再使用,也就是希望该变量是连续的。当然可以取消这步操作,但是这样绘制出来的图一般是找不出两变量之间所具有的关系的:
df = pd.DataFrame(np.random.randn(500, 2).cumsum(axis=0), columns=['x', 'y']) # axis=0时, 二维数组纵向累加
sns.relplot(data=df, x='x', y='y', kind='line', sort=False) # 将参数sort设置为False
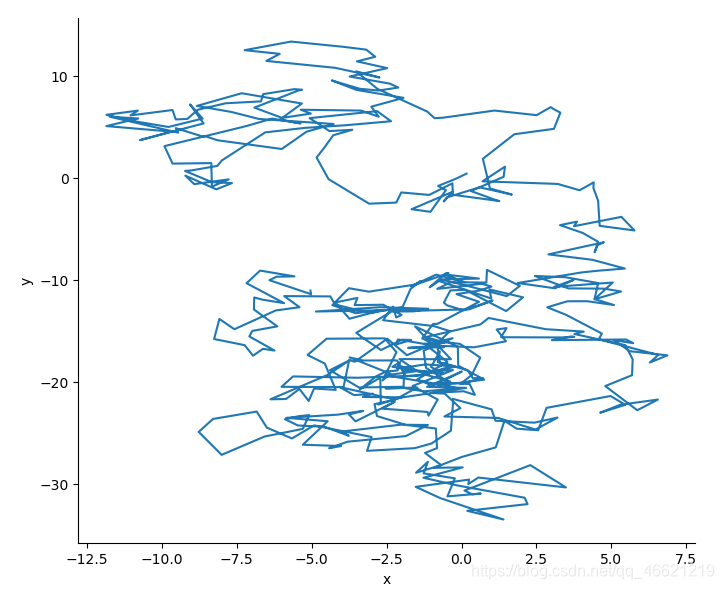
由聚合来表示不确定性
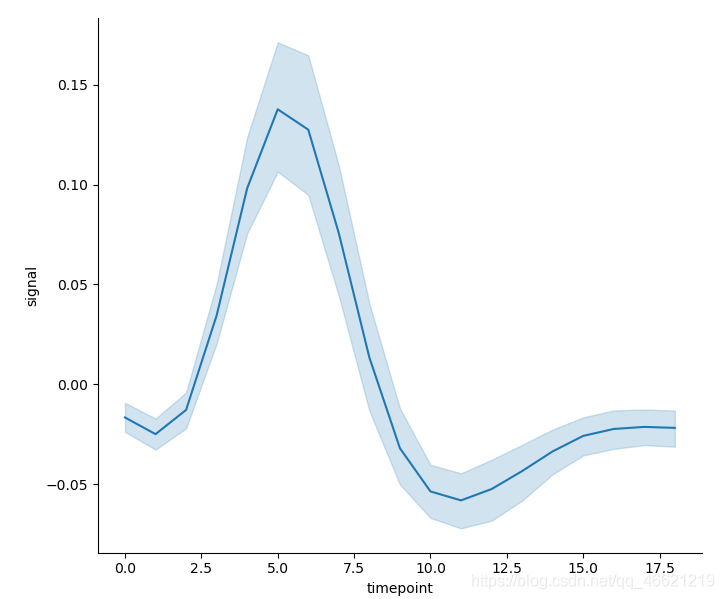
- 对于较为复杂的数据来说,可能会出现横轴变量的同一个取值对应纵轴变量的多个不同的取值(横轴变量取值重复)这种情况。此时,Seaborn的绘图函数relplot( )会计算对应纵轴变量的均值(mean)和置信水平为0.95的置信区间(confidence interval)来实现一种聚合(aggregation)——在matplotlib中画出来的什么都不是(难道是我不会用?)。使用数据集fmri4。
fmri = pd.read_csv('fmri.csv')
sns.relplot(x='timepoint', y='signal', kind='line', data=fmri)
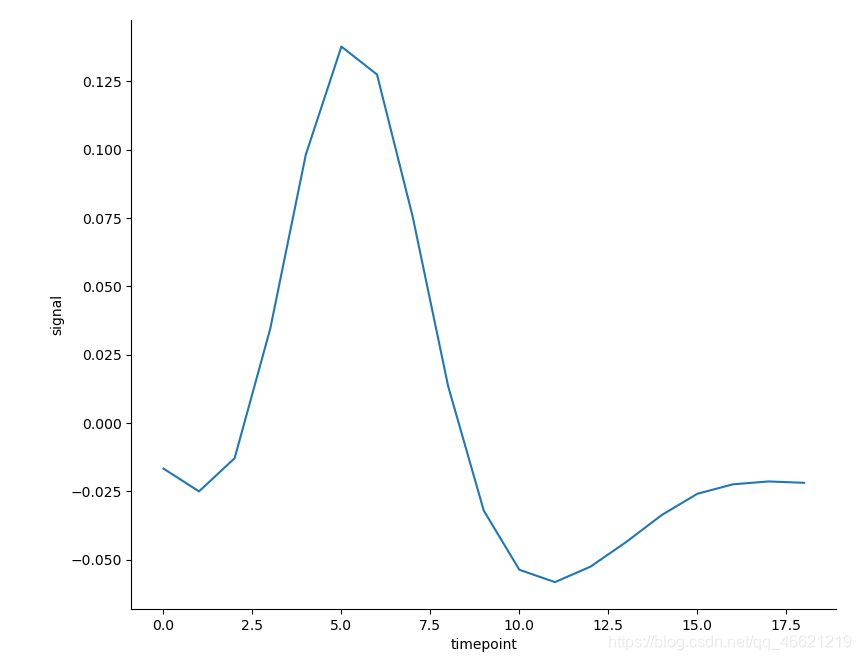
- 当数据集很大的时候,计算置信区间可能需要很长的时间。有两种方法可以进行代替——都会用到 参数ci,即直接选择不计算置信区间而仅计算均值:
sns.relplot(x='timepoint', y='signal', kind='line', data=fmri, ci=None) # 将参数ci设置为None
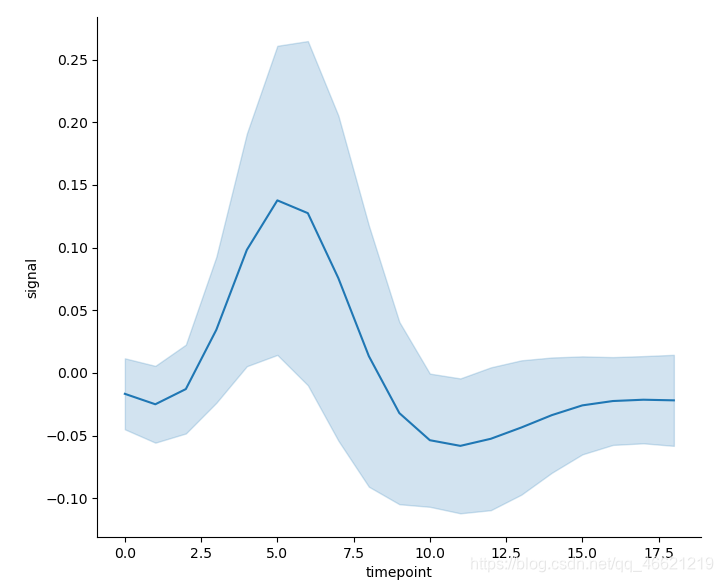
- 或者计算数据的标准差(standard deviation)来代替置信区间;而从逻辑上讲,如果其区间长度小于置信区间的长度,那么计算标准差也就不会成为备选方案了:
sns.relplot(x='timepoint', y='signal', kind='line', ci='sd', data=fmri) # 将参数ci设置为sd
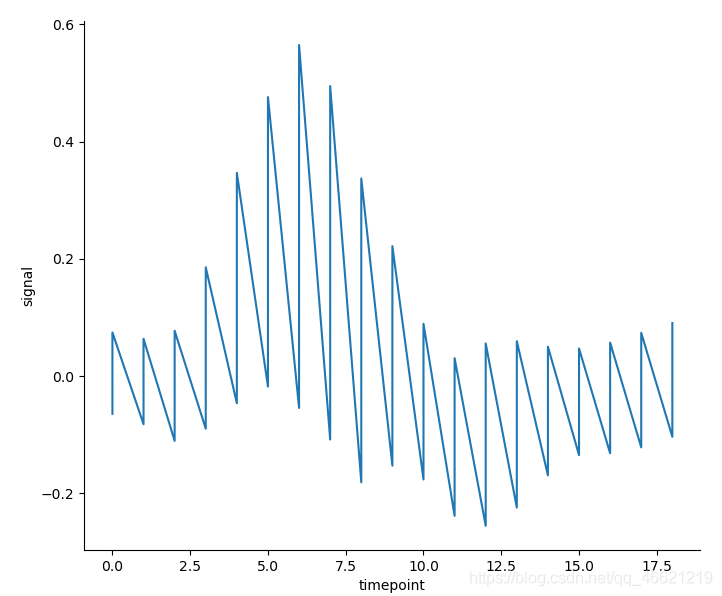
- 如果不进行聚合的话,这样绘制的折线图,意义是不大的。但是我们也确实可以通过其以及对应的散点图来理解聚合到底在干什么:
sns.relplot(x='timepoint', y='signal', estimator=None, kind='line', data=fmri)
# 需要设置参数estimator=None来关闭聚合
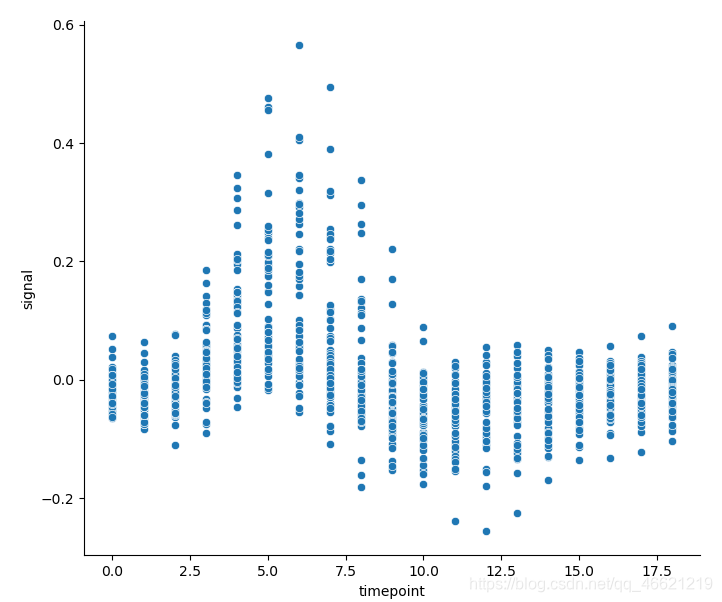
sns.relplot(x='timepoint', y='signal', kind='scatter', data=fmri)
用语义映射绘制数据子集
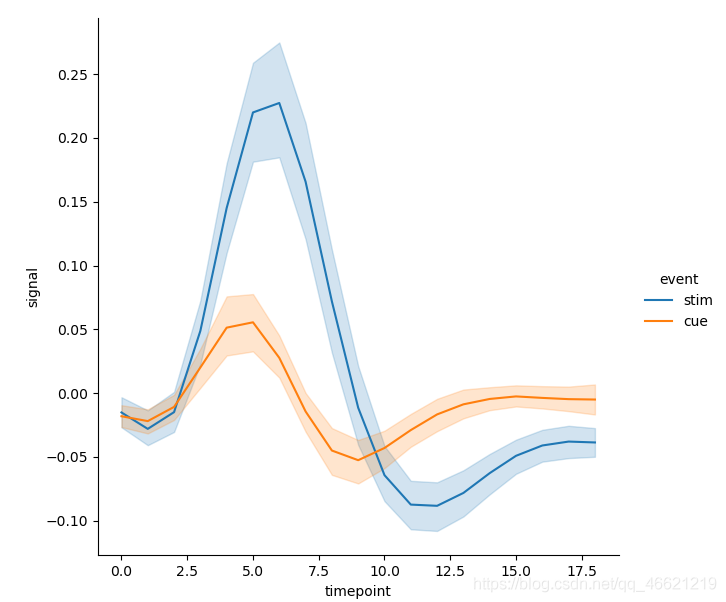
- 在折线图绘制中,同样可以在绘图函数*relplot( )和lineplot( )*中设置语义参数来增加更多的变量,从而扩大图像的维度。色调语义会改变线和错误带(error band)的颜色:
sns.relplot(x='timepoint', y='signal', hue='event', kind='line', data=fmri)
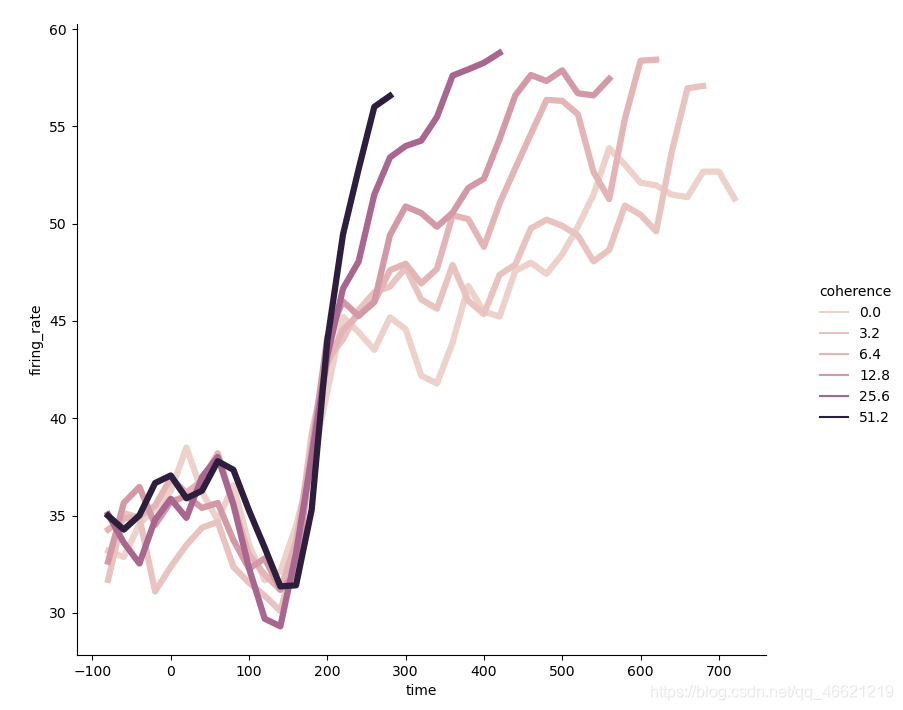
dots = pd.read_csv('dots.csv').query('align == "dots"')
sns.relplot(x='time', y='firing_rate', hue='coherence', linewidth=4.5, # 设置所有线的宽度
ci=None, kind='line', data=dots.query('choice == "T1"')) # 不计算置信区间
- 使用样式语义时,会有更多的选择——由线本身的样式进行区分:
sns.relplot(x='timepoint', y='signal', style='event', kind='line', data=fmri) # 默认情况下
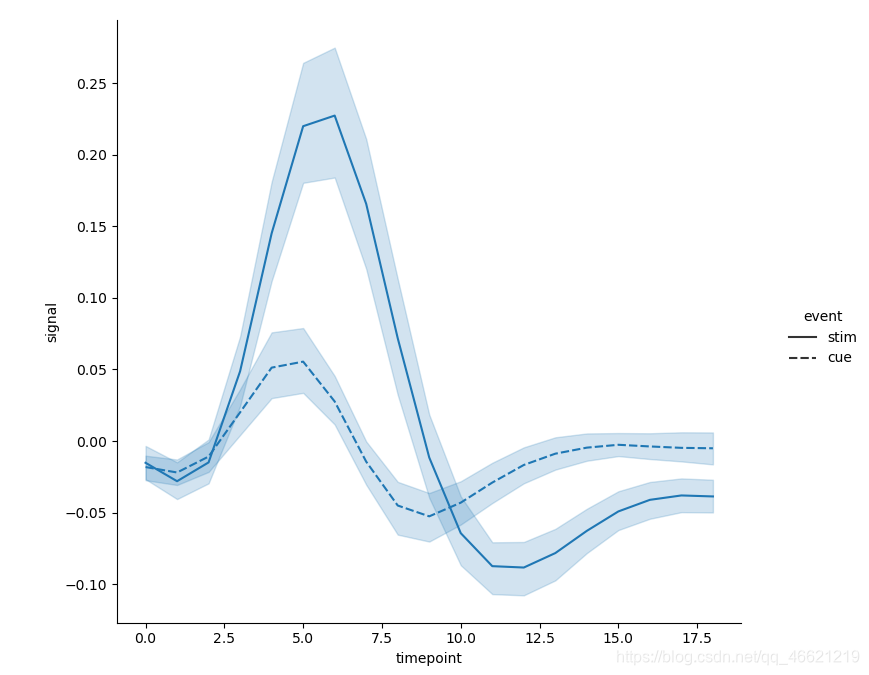
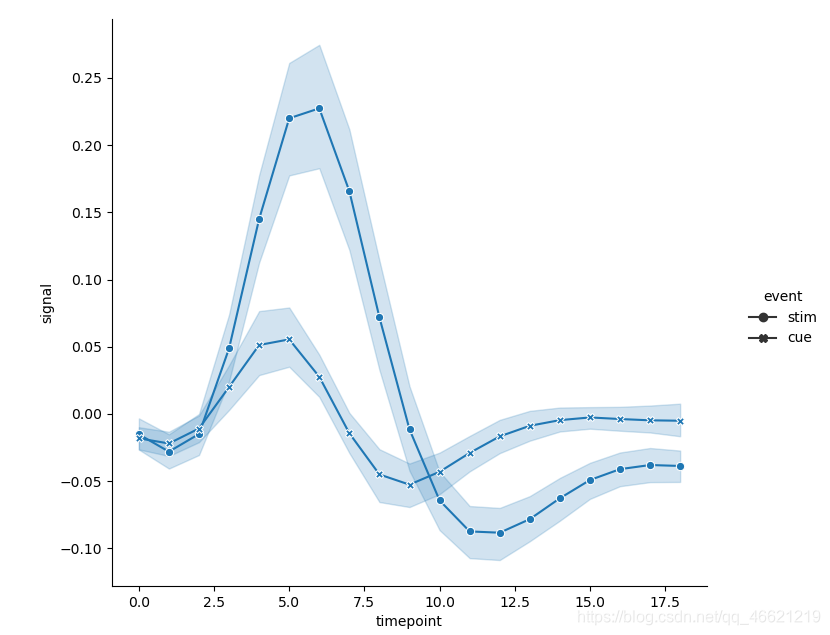
- 或者再额外设置 参数dashes 和 参数markers,即在数据节点, 改变点的形状:
sns.relplot(x='timepoint', y='signal', style='event',
dashes=False, markers=True, kind='line', data=fmri) # 可以认为是关闭虚线,打开标记点
- 使用尺寸语义实际上是在改变线的宽度(粗细),即不同类的线,其宽度是不同的,从而增加图像的维度:
sns.relplot(x='timepoint', y='signal', size='event', kind='line', data=fmri)

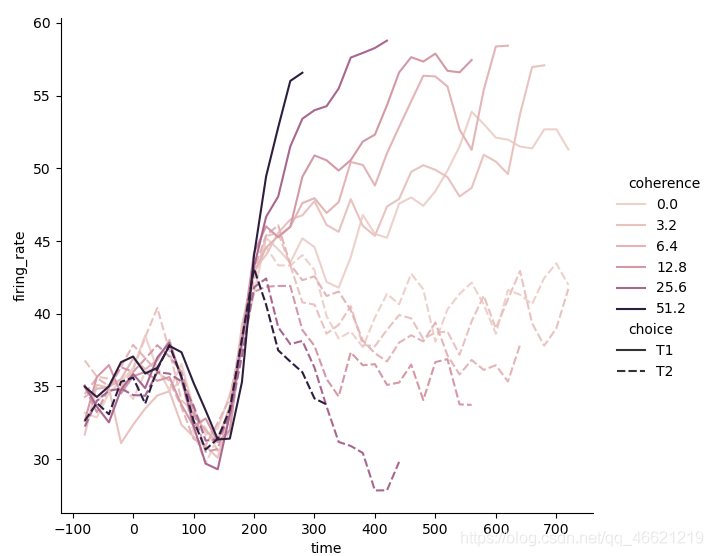
- 在上面的例子中,我都有意避免了同时使用两个语义,更不要说什么包含四个变量。一方面,我认为还是要从最基本的内容来进行参考,即使这些几乎没有任何难度,另一方面,我仍然建议要对一个变量使用两种语义,从而增加图像在视觉上的直观性,这在后面还会提到。出于练习以及对比,我们不妨在使用两个语义且增加两个变量的同时,体会Seaborn中的绘图函数为我们所带来的便捷性和灵活性。使用色调语义和样式语义:
sns.relplot(x='time', y='firing_rate', hue='coherence', style='choice', kind='line', data=dots)
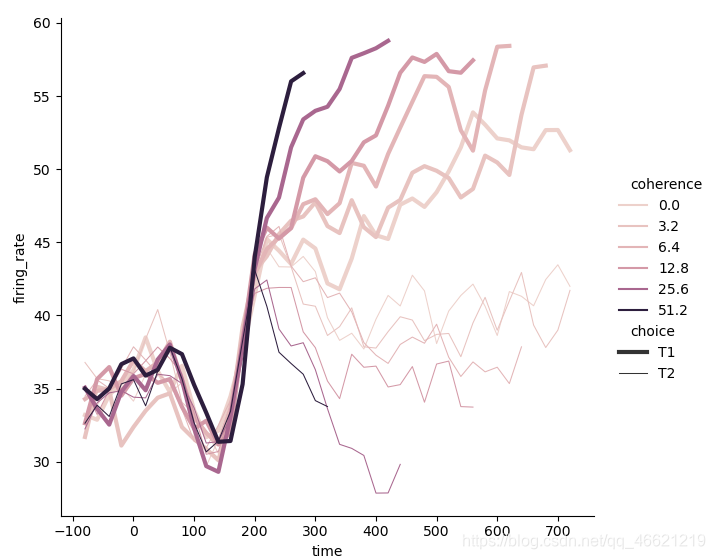
- 在同时使用色调语义和尺寸语义时,似乎线的粗细要比线的实虚要更突出一些:
sns.relplot(x='time', y='firing_rate', hue='coherence', size='choice', kind='line', data=dots)
通过分面来表示多个关系Showing multiple relationships with facets
为什么要进行分面
- 在介绍绘制重复数据的折线图时,使用到了数据集fmri,这里我们不妨进一步来看看每一列的内容究竟是什么:
| 列名 |
数据 |
| subject |
s0、s2、s3、s4、s5、s6、s7、s8、s9、s10、s11、s12、s13 |
| timepoint |
0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18 |
| event |
cue、stim |
| region |
parietal、frontal |
| signal |
-0.25549 ~ 0.564985 |
| subject |
timepoint |
event |
region |
signal |
| s0 |
1 |
cue |
parietal |
0.0003 |
| s0 |
2 |
cue |
frontal |
0.024296 |
| s0 |
2 |
stim |
parietal |
0.009642 |
| s0 |
17 |
stim |
frontal |
-0.03932 |
| s7 |
2 |
cue |
parietal |
-0.07661 |
| s8 |
7 |
stim |
parietal |
0.312811 |
| s13 |
9 |
stim |
frontal |
-0.06805 |
-
尝试着对这个数据集进行解释:由列 ’subject‘ 可知共有14个采样单位(sampling unit),每个单位由列 ‘event’ 分为 ‘cue’ 和 ’stim’ 两类、由列 ‘region’ 分为 ‘parietal’ 和 ’frontal’ 两类,在19个时间单位(0, 1, … , 18)上,测得其 ’signal‘ 值;并且重复值的出现是因为每个时间单位上有十四个采样单位,每个单位又分成4类(2 × 2),即重复56个观测值——这是通过观察不难得出分析结果。
那么在对数据集有一定了解的情况下,处理起重复值绘图问题就又多了一种选择,即向 参数units 传入列名 ’subject’,绘制出该列的每一个采样单位。接下来选择4类中的一类来进行绘制:
sns.relplot(x='timepoint', y='signal',
units='subject', estimator=None, # 对参数estimator的设置似乎是不能缺少的
kind='line', data=fmri.query('event == "stim" & region == "parietal"')) # 使用pd.query()函数来选择一类
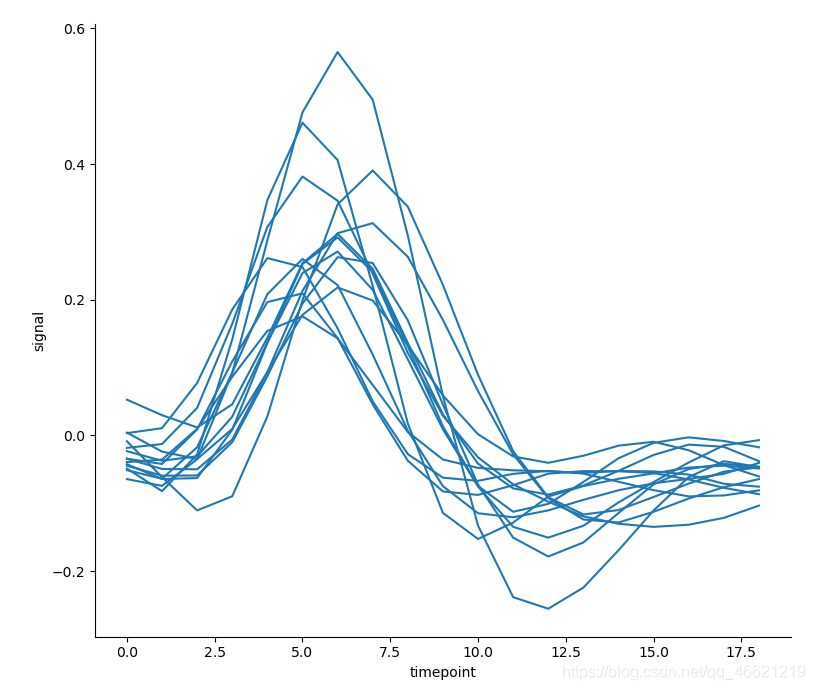
- 上面的这幅图中共有14条线,如果这时使用色调语义来考虑变量 ‘region’ 对横轴变量 ‘timepoint’ 与纵轴变量 *‘signal’*之间的关系所带来的影响,得到的将是28条线密集地出现在一张图这不太让人容易观察出什么的结果:
sns.relplot(x='timepoint', y='signal', hue='region', # 设置语义参数hue
units='subject', estimator=None,
kind='line', data=fmri.query('event == "stim"'))

给出解决方案
-
对上面的问题,可以概括成:如何理解两个变量之间的关系是如何依赖于至少一个的其他变量呢?(But what about when you do want to understand how a relationship between two variables depends on more than one other variable?)
在Seaborn中,最好的办法就是绘制多张图。对于 参数 col 和 参数 row 来说,和语义参数一样,都是传入类别数据的列名,便会在行和列上生成对应的子图,每个子图表示在该类别下,横轴变量和纵轴变量之间的关系。如果将每个采样单位的四个类别绘制成四张子图,绘制出来的效果可能会有所改善:
sns.relplot(x='timepoint', y='signal', hue='subject',
col='region', row='event', estimator=None,
height=2.5, kind='line', data=fmri) # 参数height设置每个子图的高度

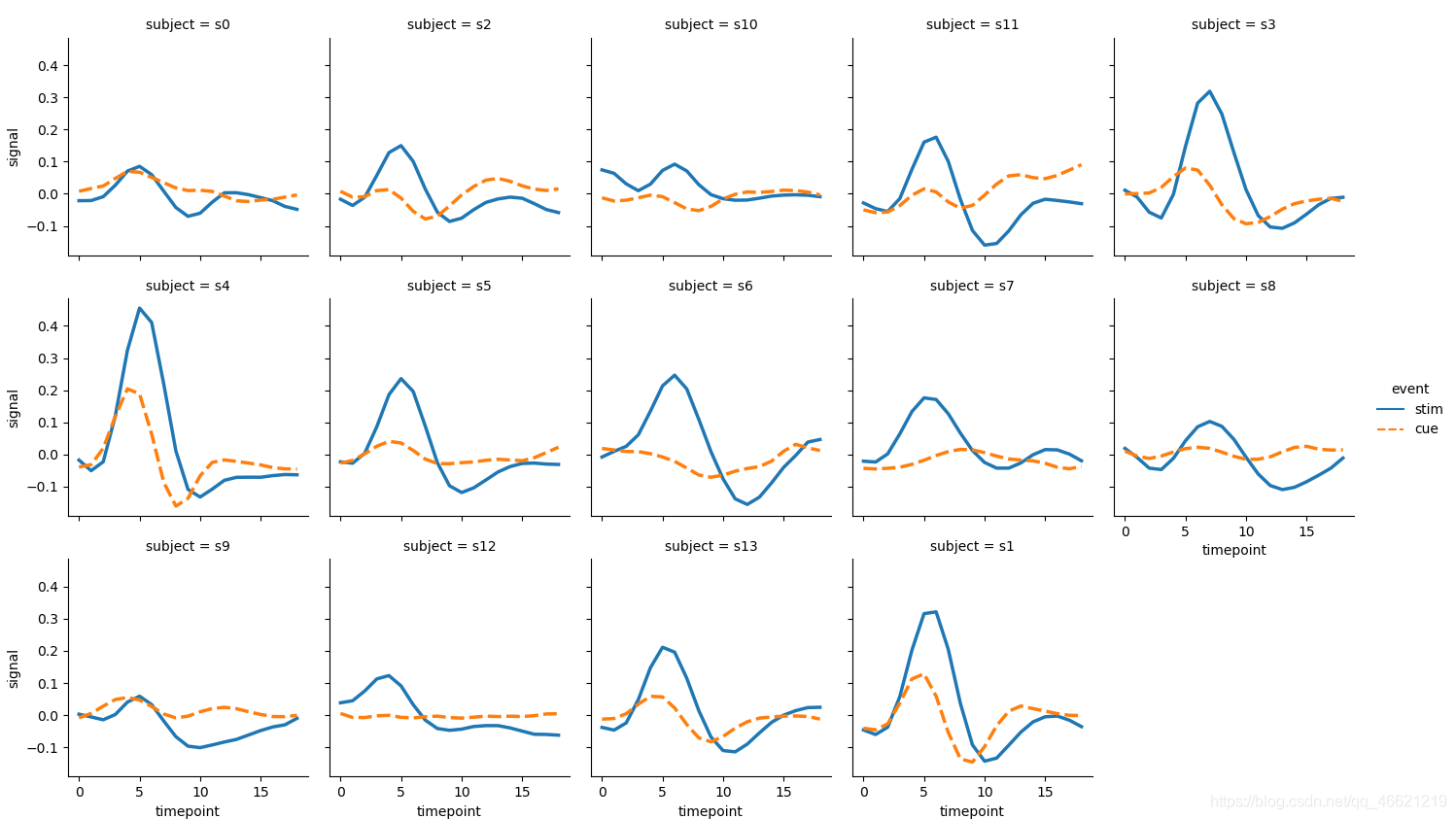
- 如果将14个采样单位独立地绘制出来,并且是在只考虑两个类别的情况下,这样得到的图像会因为其小而多变得非常有效:
sns.relplot(x='timepoint', y='signal', kind='line',
hue='event', style='event', # 一个变量, 两种语义
col='subject', col_wrap=5, linewidth=2.5, # 参数col_wrap表示一行子图的个数
height=2.5, aspect=1.0, # 参数aspect表示子图的高度与宽度之比
data=fmri.query('region == "frontal"'))
-
数据集tips的列名为:Index([‘total_bill’, ‘tip’, ‘sex’, ‘smoker’, ‘day’, ‘time’, ‘size’], dtype = ‘object’) ,对应的数据类型分别为:float64、float64、object、object、object、object、int64.
-
生成的随机数服从标准正态分布,传入生成数据的形状;这里是大小为500的一维数组。可以参考这篇有关生成随机数的文章。
-
简单的操作: 对于数组arr_1 = [1, 1, 1, 1, 1], arr_1.cumsum( ) = [1, 2, 3, 4, 5]; 对于数组arr_2 = [1, 2, 3, 4], arr_2.cumsum( ) = [1, 3, 6, 10].
-
数据集fmri的列名为:Index([‘subject’, ‘timepoint’, ‘event’, ‘region’, ‘signal’], dtype = ‘object’), 对应的数据类型分别为: object、 int64、object、object、float64。更详细的可以参考第三大部分:通过分面来表示多个关系的开头。
-
数据集dots的列名为:Index([‘align’, ‘choice’, ‘time’, ‘coherence’, ‘firing_rate’], dtype = ‘object’) ,对应的数据类型分别为:object、object、object、int64、float64、float64.
-
可以说,该函数是用来在数据框(数据集)中挑选行(样本)的;这里就是在数据集dots中,挑选出列 ‘align’(变量)为"dots"的行(样本),之后又挑选出列 ‘choice’(变量)为"T1"的行(样本)。