参考的两篇博文
(1) 优化算法总结-深度学习 https://blog.csdn.net/fengzhongluoleidehua/article/details/81104051
(2) 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam) https://www.cnblogs.com/guoyaohua/p/8542554.html (看这篇就好)
https://www.jianshu.com/p/aebcaf8af76e (Adam)
1.Batch Gradient Descent (BGD)
梯度更新规则:
BGD 采用整个训练集的数据来计算 cost function 对参数的梯度:
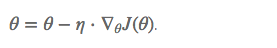
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
我们会事先定义一个迭代次数 epoch,首先计算梯度向量 params_grad,然后沿着梯度的方向更新参数 params,learning rate 决定了我们每一步迈多大。
缺点:
由于这种方法是在一次更新中,就对整个数据集计算梯度,所以计算起来非常慢,遇到很大量的数据集也会非常棘手,而且不能投入新数据实时更新模型。
优点:
Batch gradient descent 对于凸函数可以收敛到全局极小值,对于非凸函数可以收敛到局部极小值。
2.Stochastic Gradient Descent (SGD)
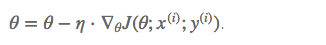
fo