爬虫流程
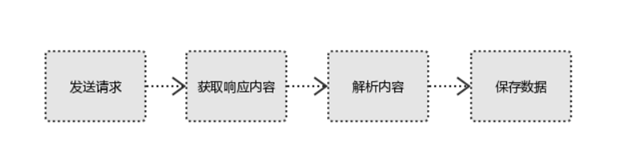
- 发起请求,通过使用HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,并等待服务器响应。
- 获取响应内容如果服务器能正常响应,则会得到一个Response,Response的内容就是所要获取的页面内容,其中会包含:html,json,图片,视频等。
- 解析内容得到的内容可能是html数据,可以使用正则表达式、第三方解析库如Beautifulsoup,etree等,要解析json数据可以使用json模块,二进制数据,可以保存或者进一步的处理。
- 保存数据保存的方式比较多元,可以存入数据库也可以使用文件的方式进行保存。
正则表达式
正则表达式(regular expression),又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一些过滤逻辑。在Python中正则表达式通过re模块来实现。
正则表达式匹配规则
| 符号 |
说明 |
| . |
用于匹配任意一个字符,如 a.c 可以匹配 abc 、aac 、akc 等 |
| ^ |
用于匹配以...开头的字符,如 ^abc 可以匹配 abcde 、abcc 、abcak 等 |
| $ |
用于匹配以...结尾的字符,如 abc$ 可以匹配 xxxabc 、123abc 等 |
| * |
匹配前一个字符零次或多次,如 abc* 可以匹配 ab 、abc 、abcccc 等 |
| + |
匹配前一个字符一次或多次,如 abc+ 可以匹配 abc 、abcc 、abcccc 等 |
| ? |
匹配前一个字符零次或一次,如 abc? 只能匹配到 ab 和 abc |
| \ |
转义字符,比如我想匹配 a.c ,应该写成 a\.c ,否则 . 会被当成匹配字符 |
| | |
表示左右表达式任意匹配一个,如 aaa|bbb 可以匹配 aaa 也可以匹配 bbb |
| [ ] |
匹配中括号中的任意一个字符,如 a[bc]d 可以匹配 abd 和 acd,也可以写一个范围,如 [0-9] 、[a-z] 等 |
| ( ) |
被括起来的表达式将作为一个分组,如 (abc){2} 可以匹配 abcabc ,a(123|456)b 可以匹配 a123b 或 a456b |
| {m} |
表示匹配前一个字符m次,如 ab{2}c 可以匹配 abbc |
| {m,n} |
表示匹配前一个字符 m 至 n 次,如 ab{1,2}c 可以匹配 abc 或 abbc |
| \d |
匹配数字,如 a\dc 可以匹配 a1c 、a2c 、a3c 等 |
| \D |
匹配非数字,也就是除了数字之外的任意字符或符号,如 a\Dc 可以匹配 abc 、aac 、a.c 等 |
| \s |
匹配空白字符,也就是匹配空格、换行符、制表符等等,如 a\sc 可以匹配 'a c' 、a\nc 、a\tc 等 |
| \S |
匹配非空白字符,也就是匹配空格、换行符、制表符等之外的其他任意字符或符号,如 a\Sc 表示除了 'a c' 之外都能匹配,abc 、a3c 、a.c 等 |
| \w |
匹配大小写字母和数字,也就是匹配 [a-zA-Z0-9] 中的字符,如 a\wc 可以匹配 abc 、aBc 、a2c 等 |
| \W |
匹配非大小写字母和数字,也就是匹配大小写字母和数字之外的其他任意字符或符号,如 a\Wc 可以匹配 a.c 、a#c 、a+c 等 |
实战1:爬取ppt网页一级页面图片
import re,requests
#参数设置
page_num=2#页面数
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}#请求头信息,模拟浏览器进行请求
#开始爬取
for n in range(page_num):
url='http://www.1ppt.com/beijing/ppt_beijing_{}.html'.format(n+1)
response=requests.get(url,headers=headers)#发送请求
if response.status_code==200:
response.encoding=response.apparent_encoding#字符编码设置为网页本来所属编码
html=response.text#获取网页代码
pattern= re.compile(r'img src="(.*?jpg)" alt')#编译正则表达式
image_url= pattern.findall(html)#解析图片链接
for i,link in enumerate(image_url):
print('第{}页第{}张图片下载中......'.format(n+1,i+1))
resp=requests.get(link,headers=headers)#请求图片链接
content=resp.content#获取二进制内容
with open('./图片/{}-{}.jpg'.format(n+1,i+1),'wb') as f:
f.write(content)#下载图片
else:
print('请求失败!')
实战2:爬取ppt网页二级页面图片
import requests,re
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}#请求头,模拟浏览器进行请求
page_num=2
for i in range(page_num):
url='http://www.1ppt.com/beijing/ppt_beijing_{}.html'.format(i+1)
print('第{}页爬取中......'.format(i+1))
response=requests.get(url,headers=headers)#向一级网页发送请求
if response.status_code==200:
response.encoding=response.apparent_encoding#字符编码设置为网页本来所属编码
html=response.text#获取网页代码
pattern=re.compile(r'<li> <a href="(.*?)" target="_blank">')#编译正则表达式
url_sub=pattern.findall(html)#解析二级页面链接
url_sub=['http://www.1ppt.com'+x for x in url_sub]#拼接成完整链接
for j,link in enumerate(url_sub):
print('第{}页第{}个ppt爬取中......'.format(i+1,j+1))
resp=requests.get(link,headers=headers)#向二级网页发送请求
if resp.status_code==200:
resp.encoding=resp.apparent_encoding#字符编码设置为网页本来所属编码
html_sub=resp.text#获取网页代码
pattern=re.compile(r'img src="(.*?)" width="700"')#编译正则表达式
image_link=pattern.findall(html_sub)#解析图片链接
for k,li in enumerate(image_link):
response_image=requests.get(li,headers=headers)#请求图片链接
content=response_image.content#获取图片二进制内容
with open('./图片/{}-{}-{}.jpg'.format(i+1,j+1,k+1),'wb') as f:
f.write(content)#下载图片
else:
print('第{}页第{}个ppt链接请求失败!'.format(i+1,j+1))
else:
print('第{}页一级页面请求失败!'.format(i+1))
如果对你有帮助,请点下赞,予人玫瑰手有余香!
时时仰望天空,理想就会离现实越来越近!