
 一波四折
——记一次K8S集群应用故障排查
一波四折
——记一次K8S集群应用故障排查
 Part1 初露端倪
Part1 初露端倪


一个周四的下午,客户的报障打破了微信群的平静。
“我们部署在自建K8S集群上的应用突然无法正常访问了,现在业务受到了影响!”
收到客户的报障,我们立刻响应,向客户了解了问题现象和具体报错信息。
客户反馈K8S集群部署在云主机上,K8S的应用pod example-app通过访问外部域名example-api.com调用接口,同时访问云数据库做数据查询后将结果返回客户端。客户排查应用pod日志,日志中有如下报错:

可以看到最关键的信息是Name or service not known。该报错一般为域名无法解析导致的。
由于客户的应用pod只访问example-api.com这一个外部域名,因此判断应该是pod解析该域名时出现异常。为了进一步验证,我们执行kubectl exec -it example-app /bin/sh命令进入pod内执行ping example-api.com命令,果然出现了相同的报错。

因此可以确认应用日志中的报错是域名解析失败导致的。
执行kubectl get pod example-app -o yaml|grep dnsPolicy查看pod的dns策略,是ClusterFirst模式,也就是pod使用K8S集群的kube-dns服务做域名解析。
执行命令kubectl get svc kube-dns -n kube-system,确认kube-dns服务的clusterIP是192.168.0.10 查看pod内的/etc/resolv.conf文件,nameserver设置的正是该IP。再执行kubectl describe svc kube-dns -n kube-system|grep Endpoints,可以看到dns服务关联了一个coredns pod作为后端。
执行kubectl get pods -n kube-system|grep coredns看到kube-dns关联的coredns pod处于running状态。
再执行kubectl logs coredns –n kube-system,看到pod日志中有大量和客户配置的外部dns服务器IP地址通讯超时的报错。
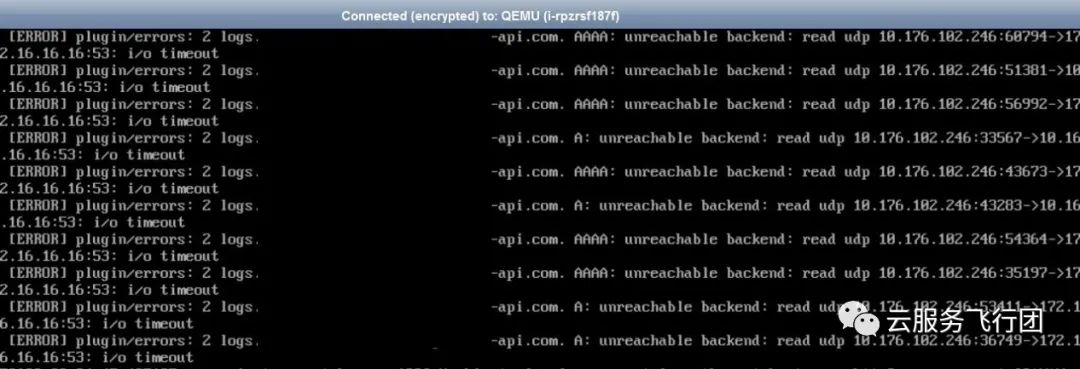
10.16.16.16和172.16.16.16为客户自建DNS服务器的IP地址
。为了确认是否是DNS服务器有问题,我们在example-app pod中分别执行nslookup example-api.com 10.16.16.16和nslookup example-api.com 172.16.16.16,均能解析出正确的IP地址。
因此判断问题应该出在coredns pod上。此时我们发现,coredns pod的状态变成了crashloobbackoff,稍后又变成了running。
观察一段时间后发现pod在这两个状态之间反复切换。鉴于整个集群只有一个coredns pod,我们修改了coredns的deploy,将pod副本数调至2,新扩的pod一直处于running状态,pod日志中也没有出现和10.16.16.16、172.16.16.16的通信超时的报错。而此时example-app pod也可以正常解析域名了!可以确认之前是集群唯一的coredns pod状态异常导致集群DNS服务不可用。
那么coredns pod为什么会出现异常呢?
再次查看异常的pod日志,发现除了和外部DNS服务器有通讯超时的记录,还有和集群api-server通讯超时的记录。因此有必要怀疑是pod所处的网络有问题。在客户的K8S集群网络规划中,pod使用和集群node不同的子网通讯。通过在K8S节点云主机上绑定pod子网的弹性网卡,在网卡上给节点的pod在pod子网中分配IP,实现pod的网络可达。
由于example-app pod是可以与外部通讯的,因此pod子网层面是没有问题的。我们将焦点移至coredns pod使用的弹性网卡上。弹性网卡在节点云主机操作系统中的设备名是eth1,pod子网网关是10.176.96.1在节点上执行ping -I eth1 10.176.96.1,结果如图:

可见云主机无法通过eth1 ping通子网网关,而且找不到eth1设备。执行ifconfig命令发现eth1设备没有被系统识别到。而弹性网卡底层是被正常挂载到云主机上的。
手动执行echo 1 > /sys/bus/pci/rescan命令重新扫描弹性网卡,发现eth1出现了,此时执行ping -I eth1 10.176.96.1也可以ping通了!而异常的coredns pod也恢复了正常。判断之前应该是系统异常导致的网卡没有被识别到导致。
通过这一问题也提醒我们如果集群需要使用kube-dns服务,coredns的pod一定要配置多副本,以免单个pod异常导致集群DNS不可用。
Part2 一波刚平一波又起
域名解析的问题解决,本以为已经结案,谁知新的问题接踵而来。客户调用应用,不再报错域名解析失败。但是仍然不能正常返回结果。排查应用日志,报错如下:

通过报错判断是应用pod连接云数据库超时导致。排查云数据库所在子网的路由、ACL和白名单设置,均无异常。连接pod后可以ping通数据库域名,判断pod与数据库的网络链路是正常的。但是pod内无法telnet通数据库域名的3306端口,判断这就是导致连接数据库超时的原因了!
排查pod内的防火墙,没有开启。pod所在的子网ACL,没有限制。表面的分析没有任何线索,于是只能祭出网络问题排查的经典手段——tcpdump抓包!
由于pod内的容器一般CPU、内存、网络资源和存储空间有限,在pod内抓包会占用大量资源和存储空间,抓包结束后数据包取出也比较繁琐。而且有的容器镜像是无法安装tcpdump工具的。所以通常我们不会在容器内抓包。
基于K8S集群的网络架构,pod的网络通讯是通过所在节点云主机的辅助弹性网卡收发数据的。因此我们只要在pod所在节点云主机上对相应的网卡进行抓包即可。
在客户的场景下,应用pod使用所在节点的eth1网卡,所以pod telnet云数据库的3306端口时,我们直接在节点上抓取eth1网卡上与云数据库IP交互的数据包即可。
pod的IP是10.176.98.29,云数据库的IP是10.176.46.4。在pod的容器内执行telnet 10.176.46.4 3306,同时在节点上执行tcpdump -i eth1 host 10.176.46.4 -w /tmp/mysql.cap。pod内telnet超时后,我们结束抓包,将cap文件取出后发现居然一片空白,一个包都没有抓到!
这不科学!
之前pod内可以ping通云数据库,说明一定有数据包从pod所在云主机发出并收到了回包。为了验证pod telnet请求的包是否正常发出,我们干脆不把抓包范围局限在eth1网卡,而是使用tcpdump -i any host 10.176.46.4 -w /tmp/mysql.cap对云主机所有网络接口抓包。这次终于抓到了数据包,发现telnet发出后,没有收到数据库的任何回包。
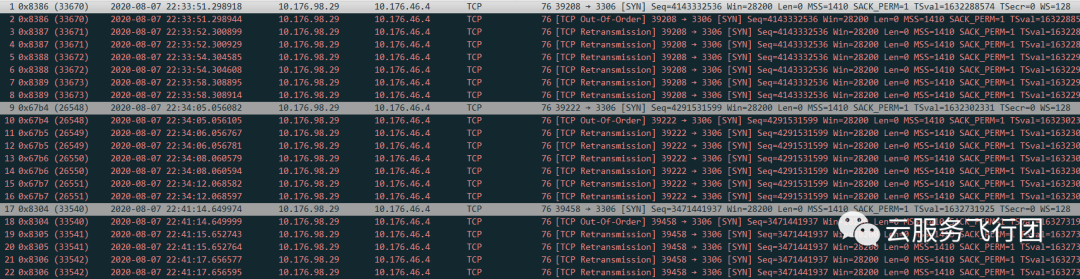
在telnet的同时,集群中有其他pod可以正常连接云数据库,所以因为云数据库侧异常导致没有回包的可能性不大。云主机可以和外界通讯的网卡只有eth0和eth1,莫非……为了验证我们的猜想,在telnet时,节点上执行tcpdump -i eth0 host 10.176.46.4,果然看到了pod发出的到云数据库的数据包!
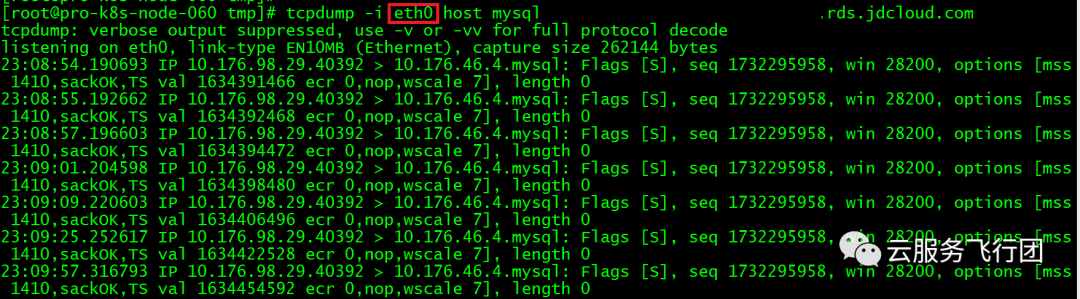
所以pod 容器telnet不通云数据库3306端口的原因也真相大白了。因为pod telnet云数据库的数据包没有走eth1,而是走了eth0,数据包发送至云数据库后,云数据库的回包发给了pod的子网网关。
SDN网络OVS判断来包是从node子网网关发出(eth0),而回包却是发往pod子网(eth1)源和目的地址不一致,因此将数据包丢弃。pod也就无法收到数据库的回包了。之前可以ping通是因为ICMP协议是代答的,即使源和目的地址不一致,也可以正常收到回包。
那么,pod的所有网络请求正常是应该通过云主机上的辅助网卡收发的,为什么走了云主机主网卡了呢?正常的K8S集群节点上配置了table 2路由规则,定义了pod的网络请求默认路由的下一跳是pod子网网关,并且走辅助网卡,如下图所示:

而在客户的应用pod所在节点执行ip r show table 2,我们看到的结果和第一次抓包一样,空空如也。。。
路由是由K8S集群的网络插件维护,路由缺失问题在网络插件日志中没有发现任何线索,具体原因不得而知。当务之急是修复问题。
可以通过重启ipamd容器恢复table 2路由。
执行docker ps | grep ipamd | grep sh找到ipamd的容器ID。
然后执行docker restart 容器ID重启容器。
再次执行ip r show table 2,终于看到了路由规则!
Finally,此时在应用pod内测试可以telnet通云数据库的3306端口。客户的应用调用也终于可以成功返回结果。
然鹅,如果各位看官觉得这个case到这里就结束了,那就和当时排障的攻城狮一样图样图森破了。
Part3
慢=不可用
就在攻城狮以为一切都恢复正常时,客户的追加反馈表明这个问题只是进入了下一个阶段。
客户反馈应用虽然可以正常调用,但是一次调用要超过一分钟才能有返回结果,之前正常的速度是仅需几秒就可以返回结果。现在这样的速度完全不能满足业务要求,相当于还是不可用的。
问题尚未解决,攻城狮仍需努力!
分析应用调用返回慢的问题,一是着眼于应用流程的各个环节,如客户端,服务端对业务请求的处理时间,另外一个就是排查数据传输链路是否有延迟。在客户的场景下,就是确认pod和云数据库在处理请求上是否有瓶颈,还有就是pod到云数据库之间的网络传输是否有延迟。在pod内ping云数据库IP,没有超时丢包,延迟很低。
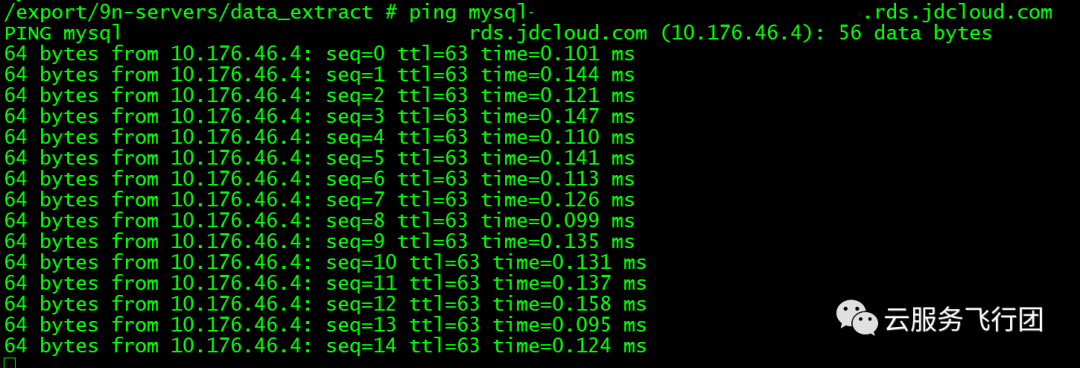
要想确认pod和云数据库在处理请求时的时长,还是要依靠tcpdump工具抓包分析。于是我们在pod对数据库发起一次完整的请求过程中,依然使用tcpdump -i eth1 host 10.176.46.4 -w /tmp/mysql.cap命令在pod所在节点抓包。将数据包取出后分析发现,一次完整的业务请求,pod会对数据库做13次查询。对比第一次查询和最后一次查询的时间,如图所示:

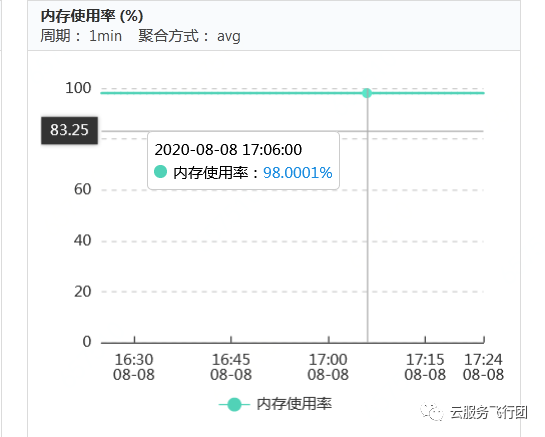
可以发现13次请求用了1分钟左右,与业务调用耗时吻合。排查云数据库监控,发现内存
使用接近100%
同时实例慢查询日志中有大量慢sql记录,可以看到几乎每次查询都耗时较长
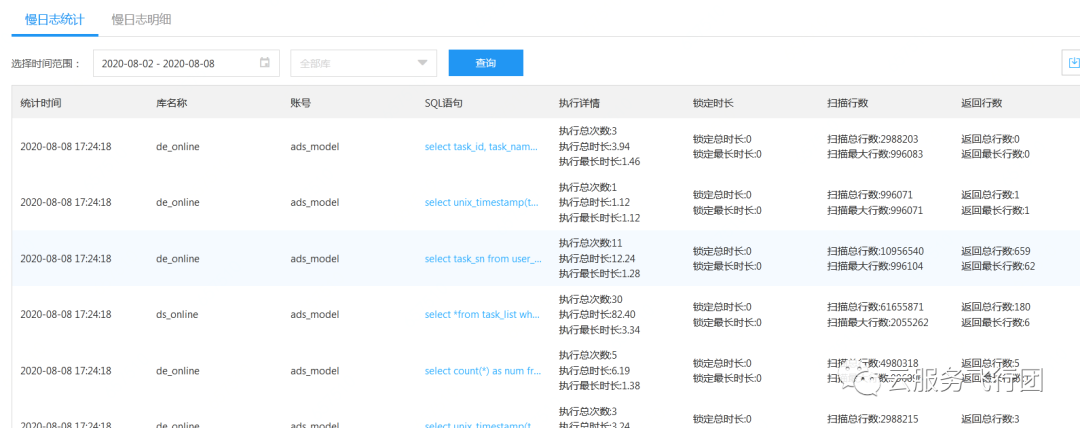
可见如果业务调用的13次请求,每次都是慢查询,耗时4秒左右,就会导致我们看到的完整请求耗时一分钟左右。
因此判断瓶颈应该主要在云数据库上,建议客户对数据库慢查询进行优化,降低内存负载。然后观察应用调用时长是否恢复正常。
part4 问题的真相只有一个!
当我们天真地以为优化完数据库慢查询后,一切就都尘埃落定时。客户的反馈几乎让人崩溃——优化慢查询后,数据库内存使用已降至30%,慢日志中也几乎没有慢sql记录。而应用的调用时长仍然没有缩短!
一定还有哪个环节有疏漏。
为了完整了解应用pod在应用调用过程中都产生了哪些数据交互,我们决定再次抓包分析,但焦点不再集中在云数据库上,而是以pod维度进行抓包。使用tcpdump -i eth1 host -w /tmp/app.cap命令在pod所在节点抓取所有和pod相关的包,分析数据包后果然有了新的发现:pod与100.64.249.132这个地址有文件传输交互。
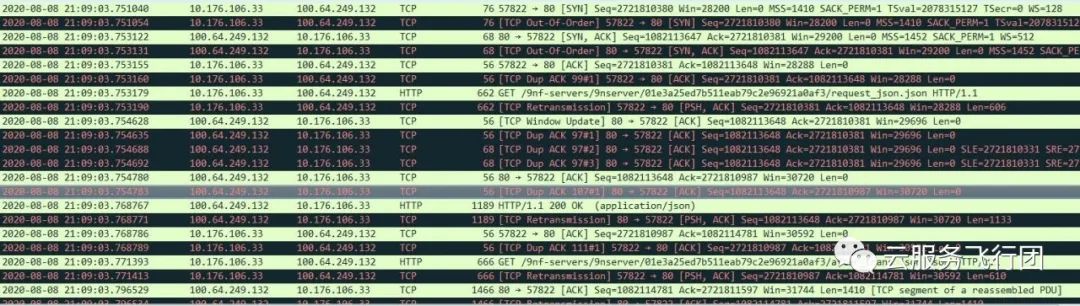
查看数据包详细数据发现这个地址是OSS对象存储解析到的域名!pod还会与oss传输文件这个重要环节在此前是不知道的,客户也没有主动告知。
这也提醒我们在分析应用问题时,务必要搞清完整的业务调用流程,应用架构和涉及到的产品环节,否则挤牙膏似的信息输出和被问题现象牵着鼻子走,会浪费大量时间,甚至严重阻碍问题排查。
我们在pod内测试ping 100.64.249.132,延时非常感人。
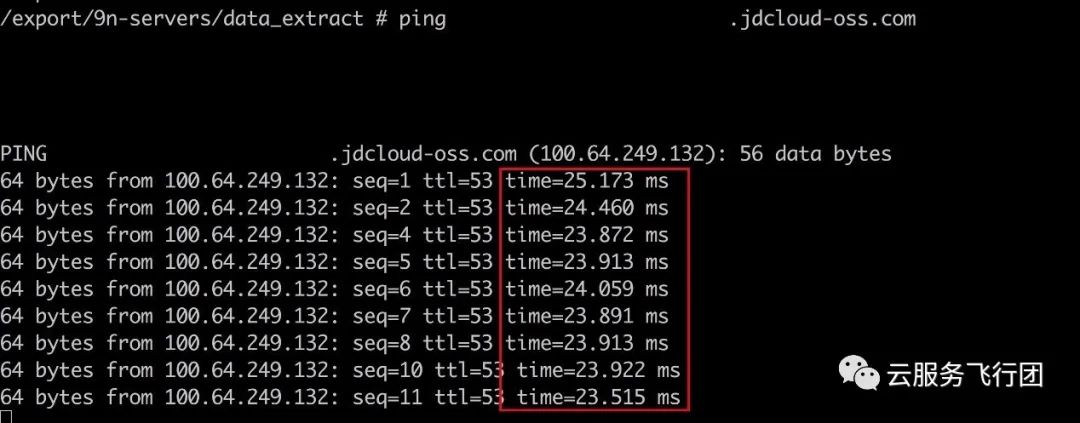
与客户确认,客户反馈OSS域名解析的IP貌似不对。在业务架构规划时,为了保证客户pod与oss的网络性能,配置了通过专线连接oss。当前解析的IP没有走专线网段,而是走了普通的网段,无法满足性能要求。正常走专线的域名解析IP应该是10.219.226.2。
但是域名解析为什么会出现问题呢?
各位童鞋是否还记得part1中我们提到客户的pod使用的是kube-dns提供的dns解析,而kube-dns配置的上游服务器是客户自建的dns服务器?经过客户测试发现,自建dns服务器对oss域名的解析就是100.64.249.132。应该是近期客户侧维护dns服务器的时候误操作修改了解析导致的。。。将自建dns服务器的域名解析地址修改回正确地址后。再次在pod内测试,结果如下:
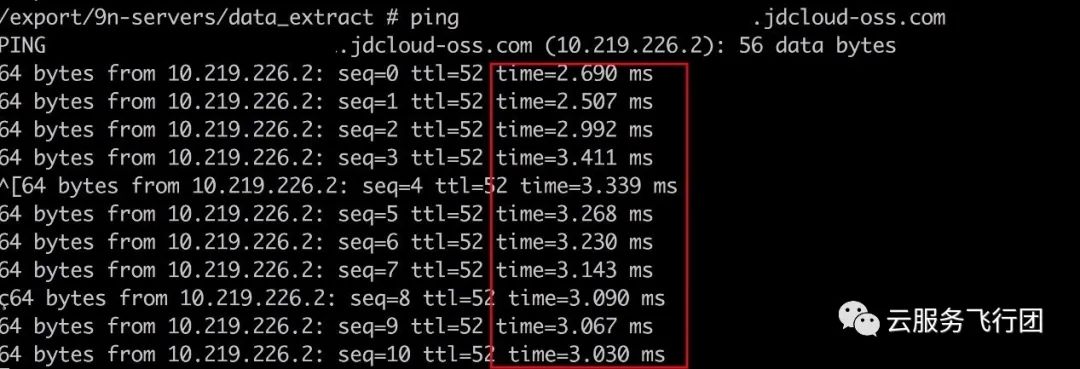
再次测试应用调用,终于恢复到了正常的时长!可喜可贺!

至此客户的问题卍解,总结问题排查过程,有几点值得分享:
1、 k8s集群如果使用kube-dns服务,coredns pod务必配置多副本,避免单点故障导致集群dns服务不可用。
2、 排查K8S集群pod网络问题时,可以在pod所在节点抓取pod使用的辅助网卡的相应网络数据包,避免直接在pod内抓包。
3、 应用系统性能排查涉及到各个节点设备和网络传输,务必了解清楚完整的系统架构,调用流程,再针对涉及的每个环节逐一分析。
以上就是一次“波折”的K8S应用问题排查过程,感谢各位童鞋阅读,如果能够对大家有所帮助,欢迎点赞转发评论。关注我们的公众号,更多精彩内容会持续放送!
