最近在读《Introduction to Data Mining 》这本书,发现课后答案只有英文版,于是打算结合自己的理解将答案翻译一下,其中难免有错误,欢迎大家指正和讨论。侵删。
第二章

字段3 × 3 ≈ 字段2。字段2和字段3很有可能包含相同的信息,尽管从一个很小的样本中得出结论是非常不可靠的行为。


(a)二元的,定性的,序数的
(b)连续的,定量的,比率的
(c)离散的,定性的,序数的
(d)连续的,定量的,比率的(比如描述走了半圈就是一个角度中比例的概念)
(e)离散的,定性的,序数的
(f)连续的,定量的,比率的/区间的(取决于海平面的概念定义)
(g)离散的,定量的,比率的
(h)离散的,定性的,标称的
(i)离散的,定性的,序数的
(j)离散的,定性的,序数的
(k)连续的,定量的,比率的/区间的
(l)离散的,定量的,比率的(这个离散我也很疑惑,难道不可以有实数的密度吗)
(m)离散的,定性的,标称的

(a)当然是老板对了。销售主管错的很离谱,就好比说一部几亿票房电影差评数比一部几百万票房电影差评多,但是评论数根本不是一个量级的,因此应该用差评率=差评数 / 评论数这个概念来评估满意度,各大电影网站也是这么做的。
(b)毫无意义。理由同上。

(a)是的。假如出现1>2,2>3,3>1的情况那不就傻了。
(b)当1>2,2>3这种已经能建立序数的情况下,就不做第三次比较了;当1>2,2<3这种情况才做第三次比较。这种创建序数度量的方法通常来说不太准确,因为比较的维度可能不太一样,比如1>2是因为1价格比2便宜,而2>3是因为2质量比3好。
通过学生的学号来预测学生哪一年毕业。

(a)
Q1=A : 00
Q1=B : 01
Q1=C : 10
Q1=D : 11
…………
Q100=A : 00
Q100=B : 01
Q100=C : 10
Q100=D : 11
(b)400个非对称的二进制属性。
日气温。
文档-词矩阵第i行第j列的元素表示单词j在文档i中出现的次数。大部分文档都只包含了一小部分非零元素,因此,无论是在描述一个文档还是比较文档的不同时,零元素都是无意义的。所以说文档-词矩阵有非对称离散的特征。如果以TF-IDF算法(以词频和逆文档频率相乘得到的值当作矩阵元素,某个词越重要则TF-IDF值越大,可见第16题)应用到单词上,并且规范化文档的L2范数=1,这样的文档-词矩阵就是连续的,但这样的转换并不影响之前就为0的元素,因此它还是非对称的,0元素仍无意义。
观测科学并不能控制观察到的数据的质量。举个例子,比如已经可以使用现在的地球轨道卫星技术了,但是测量海洋表面温度仍然还是依靠船舶,类似的,测量天气的数据也依靠地面上的基站。因此,可用的数据是必不可少的。在这层意义上,观测科学的数据分析工作与数据挖掘十分类似。

浮点数精度是最高的精度。更直接地说,精度通常用来表示有效数字的数量,单精度只能表示有效数字低于32位的值,约等于十进制的九位数字。通常使用32位(64位)的时候实际表示精度是低于32位(64位)的。
(1)文本文件我们可以直接通过文本编辑器查看,但二进制文件我们无法看懂(计算机专家除外)
(2)跨系统或项目时文本文件更加便携。
(3)文本文件更容易修改。

(a)根据定义,噪声并不令人感兴趣。但离群点有研究的意义。
(b)可能。随机数据的失真通常归咎于离群点。
(c)并不。
(d)不,离群点只代表一类和正常点不同的点。
(e)可以。

(a)第一,在最近邻列表中,重复元素的顺序取决于算法细节和集合中元素顺序。
第二,如果有很多的重复元素,返回的列表中可能只有重复元素。
第三,一个元素可能不是它自己的最近邻。
(b)去重复。

这些属性都是数值型的,但是都有广泛的取值范围,这取决于测量的刻度。此外,这些属性都是对称的。将欧几里得距离标准化会更合适。

第一种抽奖是分层抽样,可以保证从每组抽出的元素相等。第二组是简单随机抽样,但从平均意义上来说,从每组中抽出的元素和第一种方案一样。

(a)如果一个词仅出现在一个文档中,会赋予它最大的权重;如果出现在每个文档中,则权重为0。
(b)每个文档中都出现的词不能区分文档,因此,这样的变换可以更好地区分文档。

(a)(a2,b2)
(b)y=x2

(a)L1 = 3 Jaccard = 2 / 5
(b)汉明距离更类似于简单匹配系数,实际上,SMC = 1 - 汉明距离 / 位数。Jaccard相似度更类似于余弦度量,因为两者都忽略了0-0匹配。
(c)Jaccard度量更合适,因为两者都没有的基因(即0-0匹配)并不能用来比较有机体的相似性,我们更加关注1-1匹配。
(d)汉明距离更合适。因为我们关注两者不同的基因(即1-0和0-1匹配)。

(a) cos(x,y) = 1 ; corr(x,y) = 0/0 ; Euclidean(x,y) = 2
(b) cos(x,y) = 0 ; corr(x,y) = -1 ; Euclidean(x,y) = 2 ; Jaccard = 0
© cos(x,y) = 0 ; corr(x,y) = 0 ; Euclidean(x,y) = 2
(d) cos(x,y) = 0.75 ; corr(x,y) = 0.25 ; Jaccard = 0.6
(e) cos(x,y) = 0 ; corr(x,y) = 0

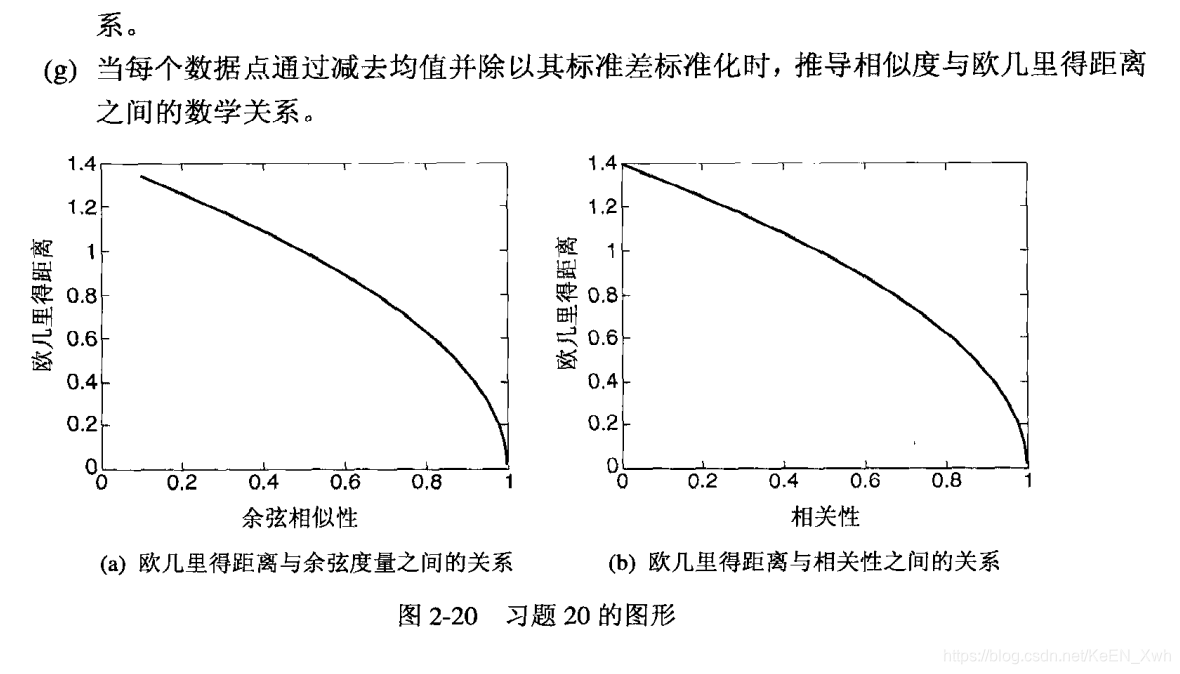
(a)[-1,1]。在很多情况下只有非负的属性值,这时的范围是[0,1]。
(b)不一定。例如x = ( 1 , 0 ) , y = ( 2 , 0 )
(c)当x与y的均值为0时,cos(x,y)与corr(x,y)相等。
(d)基于这100000点,两者有相反的关系。如果余弦相似度=1,则欧几里得距离=0;如果欧几里得距离比较大,则余弦相似度接近于0。注意所有的数据点都来自正的象限,因此所有的余弦值都为非负的。
(e)同上。
(f)
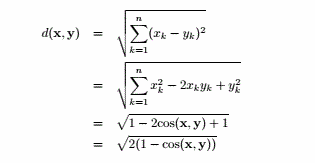
(g)
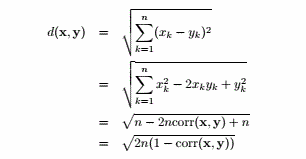

(a)显然,d ( A , B ) ≥ 0。当A = B时,d ( A , B ) = 0。
(b)d ( A , B ) = d ( B , A )也很显然。
(c)首先,d( A , B) = size(A) + size(B) - 2size(A ∩ B)
则d(A , B) + d(B , C) = size(A) + size© + 2size(B) - 2size(A ∩ B) - 2size(B ∩ C)
又size(A ∩ B) ≤ size(B) , size(B ∩ C) ≤ size(B)
所以d(A , B) + d(B , C) ≥ size(A) + size© + 2size(B) - 2size(B) = size(A) + size© ≥ size(A) + size© - 2size(A ∩ C) = d(A , C)
三角不等式证毕。

对于第一个应用对时间序列聚类,具有高的正相关性的时间序列应该放在一起,因此
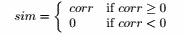 比较合适。
比较合适。
对于第二个应用,需要考虑强的负相关关系,因此取绝对值更加合适,即sim=| corr | 。

假设s是在区间[0,1]取值的相似性度量,d = ( 1 - s ) / s,d = - log s 。

(a)两两比较,取最大的邻近度或者最小的邻近度;基于所有的点算出一个欧几里得空间里的质心,取所有点到质心的距离之和或取平均值。
(b)分别算出两个点集的质心,定义两个质心的距离就是两个点集的距离。
(c)一个方法是计算每个点到另一个对象集中所有点的距离取平均值,另一个方法是取最大值或最小值。

(a)可以参考第四章的Hint算法。d( y , z ) ≤ d( y , x ) + d( x , z )
如果d( x , y ) ≤ ε / 2,d( x , z ) ≤ ε / 2,那么d( y , z )无需计算。
d( y , z ) ≥ d( y , x ) - d( x , z )
如果d( y , x ) - d( x , z ) ≥ ε ,那么d( y , z )无需计算。
(b)如果x,y之间距离为0那么就无需其他计算了,如果x与y距离较大的话,就需要更多的计算。
(c)设x,y是S‘里的点,x*和y*是S’里距离x,y最近的点。
如果d( x* , y* ) + 2ε ≤ β,那么d( x , y ) ≤ β.
如果d( x* , y* ) - 2ε ≤ β,那么d( x , y ) ≥ β.
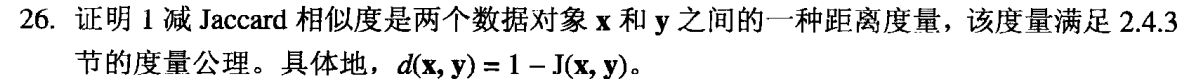
(a)由J( x , y ) ≤ 1,立即得d( x , y ) ≥ 0 ; J( x , x ) = 1时有d( x , y ) = 0.
(b)由J( x , y ) = J( y , x ) ,立即得d( x , y ) = d( y , x ).
(c)证明根据Jeffrey Ullman定理

注意到x与y之间夹角角度∈[0,180°)。
(a)arccos的取值范围为[0,π],因此d( x , y ) ≥ 0;d( x , x ) = arccos 1 = 0.
(b)由cos( y , x ) = cos( x , y )立即得d( y , x ) = d( x , y ).
(c)显然x,z之间的角度必然小于等于x,y与y,z之间的角度之和。