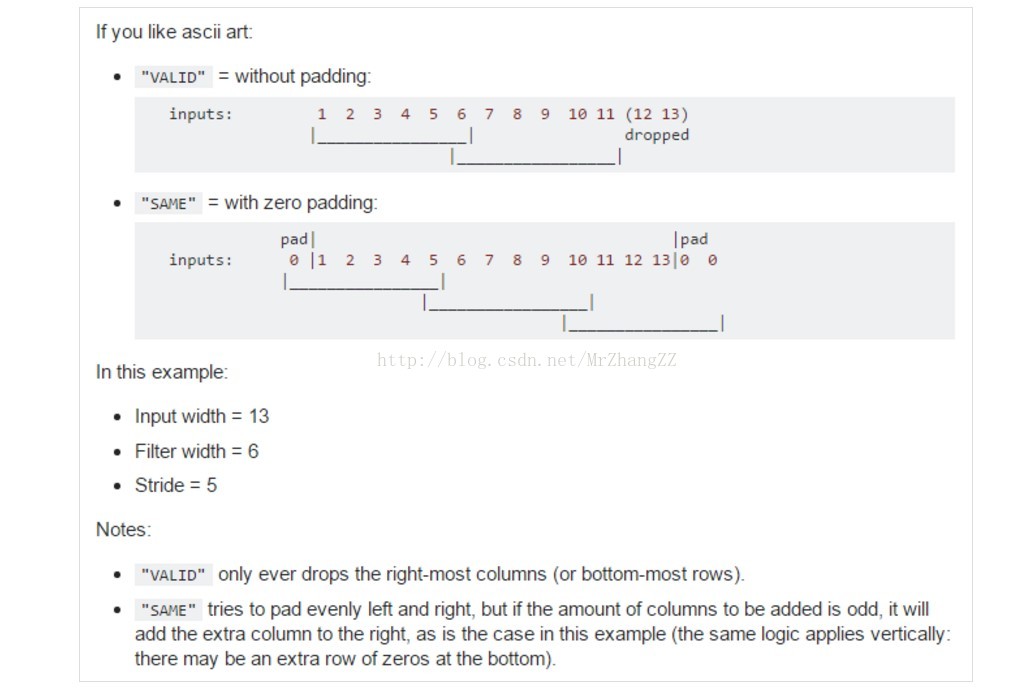
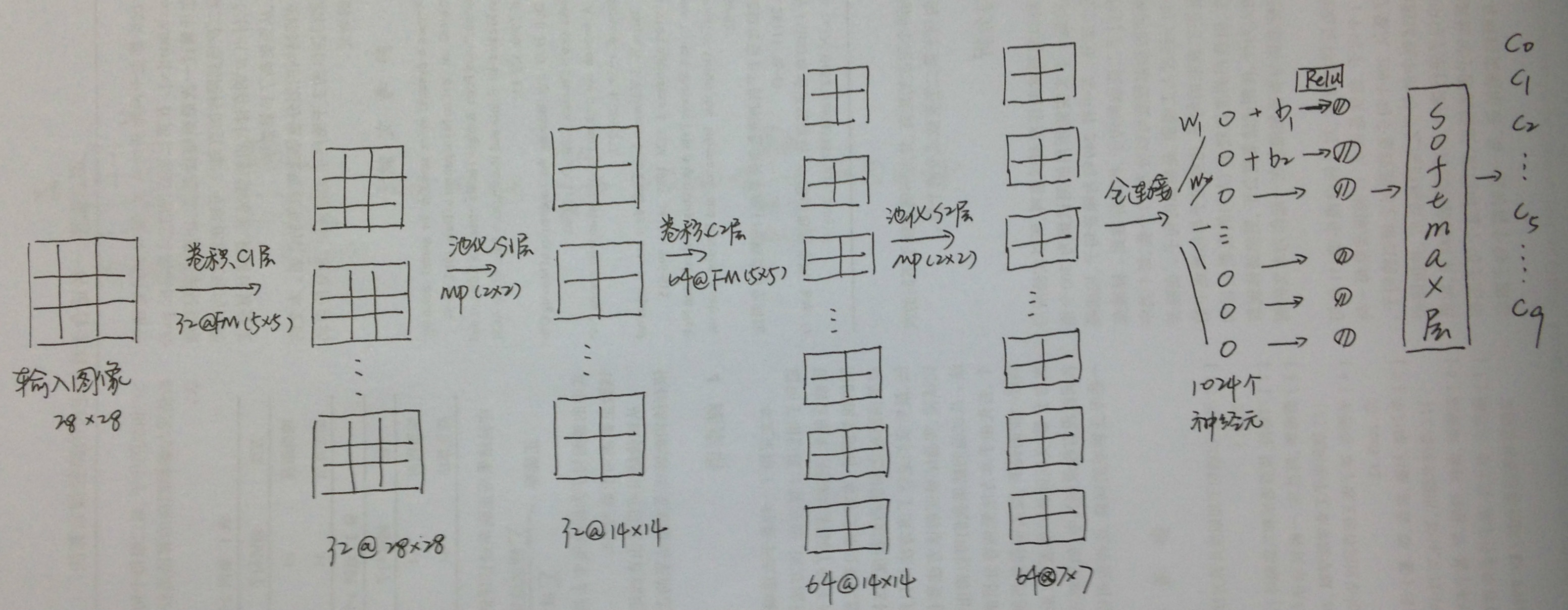
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data# 60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)# (每一行包含28*28=784个像素点)# Import datamnist = input_data.read_data_sets("MNIST_data/", one_hot=True)# init weightdef weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.01) return tf.Variable(initial)# init biasdef bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial)# create CNN layerdef conv2d(x, W): # stride [1,x_movement,y_movement,1],stride[0] and stride[3] must be 1 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') ### ???# create pooling ,in order to reduce the loss of info when cutting the imagedef max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')# def compute_accuracydef comput_accuracy(v_xs, v_ys): global prediction y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1}) correct_pre = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pre, tf.float32)) result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1}) return result# define placeholder for inputs to networkxs = tf.placeholder(tf.float32, [None, 784]) # 28x28ys = tf.placeholder(tf.float32, [None, 10])keep_prob = tf.placeholder(tf.float32)x_image = tf.reshape(xs, [-1, 28, 28, 1])# print(x_image.shape) #[n_sample.28,28,1]# conv1 layerW_conv1 = weight_variable([5, 5, 1, 32]) # patch 5x5,in size 1,out size 32b_conv1 = bias_variable([32])hide_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)# relu: let data nonlinear , output size 28x28x32hide_pool1 = max_pool_2x2(hide_conv1) # output size 14x14x32# conv2 layerW_conv2 = weight_variable([5, 5, 32, 64]) # patch 5x5,in size 32,out size 64b_conv2 = bias_variable([64])hide_conv2 = tf.nn.relu(conv2d(hide_pool1, W_conv2) + b_conv2) # relu: let data nonlinear , output size 14x14x64hide_pool2 = max_pool_2x2(hide_conv2) # output size 7x7x64# func1 layerW_fc1 = weight_variable([7*7*64, 1024]) # 全连接b_fc1 = bias_variable([1024])# [n_samples,7,7,64] ->> [n_samples,7*7*64]h_pool2_flat = tf.reshape(hide_pool2, [-1, 7*7*64]) # 转化为1维h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # 点积h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)# func2 layerW_fc2 = weight_variable([1024, 10])b_fc2 = bias_variable([10])prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)# the error between the prediction and real datacross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction), reduction_indices=[1]))train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)# create sessionwith tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5}) if i % 40 == 0: print(comput_accuracy(mnist.test.images, mnist.test.labels))-