一、基本配置(所有节点)
(一)配置静态网络
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcgf-ens192

开启网卡服务
[root@localhost ~]# service network start
(二)修改主机名和修改host文件
[root@localhost ~]# hostnamectl --static set-hostname master
[root@localhost ~]# hostnamectl

[root@localhost ~]# vi /etc/hosts
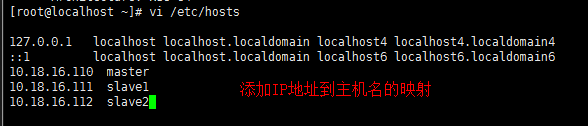
在master直接将hosts文件发送给其他两个节点
[root@localhost ~]# scp -r /etc/hosts slave1:/etc/hosts
[root@localhost ~]# scp -r /etc/hosts slave2:/etc/hosts
(三)禁用SELINUX
[root@localhost ~]# vi /etc/sysconfig/selinux

同样将文件发给其他两个节点
[root@localhost ~]# scp -r /etc/sysconfig/selinux slave1:/etc/sysconfig/
[root@localhost ~]# scp -r /etc/sysconfig/selinux slave2:/etc/sysconfig/
(四)关闭防火墙、并取消开机自启动
[root@localhost ~]# systemctl stop firewalld.service
[root@localhost ~]# systemctl disable firewalld.service

(五)配置NTP时间同步(集群所有节点)
[root@localhost ~]# yum install chrony -y
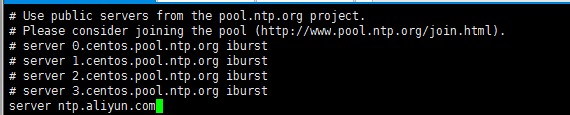
下载完成后 修改chrony.conf配置文件
[root@localhost ~]# vi /etc/chrony.conf
master 节点
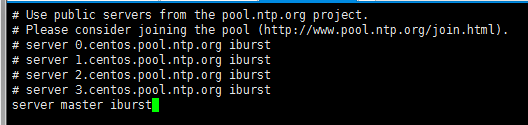
slave1和slave2 节点
启动服务并设置开机自启动
[root@localhost ~]# systemctl start chronyd.service
[root@localhost ~]# systemctl enable chronyd.service
删除本地时间分区: rm /etc/localtime
创建时间分区链接文件: ln -s /usr/share/zoneinfo/Universal /etc/localtime
查看时间: timedatectl status
[root@localhost ~]# rm /etc/localtime
rm:是否删除符号链接 "/etc/localtime"?y
[root@localhost ~]# ln -s /usr/share/zoneinfo/Universal /etc/localtime
[root@localhost ~]# timedatectl status

(六)下载一下vim编辑器
[root@localhost ~]# yum install vim
(七)安装JDK1.8
[root@localhost ~]# yum install java-1.8.0-openjdk* -y
查看java安装目录
之后环境变量JAVA_HOME时会用到这个路径
[root@localhost ~]# ll /etc/alternatives/java
(八)创建hadoop用户(所有节点)
(1)创建用户:useradd hdfs
(2)修改密码:passwd hdfs
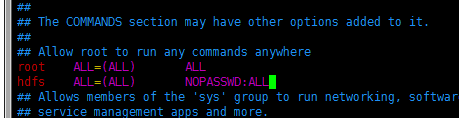
(3)配置sudo 免密权限:
在root 用户下,编辑文件/etc/sudoers
增加以下一行
[root@localhost ~]#useradd hdfs
[root@localhost ~]#passwd hdfs
[root@localhost ~]#vi /etc/sudoers
二、开始安装hadoop
(一)hdfs用户下的ssh免密登录(所有节点)
[hdfs@master root]$ ssh-keygen -t rsa
一直默认回车

将密钥发送到其它主机:
[hdfs@master root]$ ssh-copy-id -i ~/.ssh/id_rsa.pub master
[hdfs@master root]$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
[hdfs@master root]$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave2

(二)下载hadoop(主节点)
1.wget没有下载的话可以用 yum install wget
如果权限不够的话可以用sudo
[hdfs@master root]$sudo wget http://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
2.解压到/home/hdfs/bigdata/opt/目录下
[hdfs@master root]$ sudo tar -zxvf hadoop-2.6.0.tar.gz -C /home/hdfs/bigdata/opt/
(三)配置jdk1.8和hadoop2.6的环境变量
[hdfs@master root]$ sudo vim /etc/profile
export JAVA_HOME='/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64'
export HADOOP_HOME='/home/hdfs/bigdata/opt/hadoop-2.6.0'
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使环境变量生效并且查验
[hdfs@master root]$ source /etc/profile #使环境变量生效
[hdfs@master root]$ echo $HADOOP_HOME
/home/hdfs/bigdata/opt/hadoop-2.6.0
[hdfs@master root]$ echo $JAVA_HOME
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
(四)创建一些hadoop 数据存放的目录
(1)临时数据存放目录:
[hdfs@master root]$ mkdir -p /home/hdfs/bigdata/hadoopData/tmp
(2)namenode 上存储hdfs 名字空间元数据
[hdfs@master root]$ mkdir -p /home/hdfs/bigdata/hadoopData/hdfs/namenode
(3)datanode 上数据块的物理存储位置
[hdfs@master root]$ mkdir -p /home/hdfs/bigdata/hadoopData/hdfs/datanode
(五)修改hadoop 配置文件
关于配置文件以及参数说明
进入到hadoop的配置文件夹中
[hdfs@master root]$ cd $HADOOP_HOME/etc/hadoop
(1)修改配置文件hadoop-env.sh
[hdfs@master hadoop]$ ll /etc/alternatives/java
[hdfs@master hadoop]$ sudo vim hadoop-env.sh

(2)修改配置文件core-site.xml
[hdfs@master hadoop]$ sudo vim core-site.xml
fs.defaultFS 参数配置的是HDFS 的地址,hdfs://主机名:端口号
hadoop.tmp.dir 参数配置的是hadoop 临时数据存放的目录
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/bigdata/hadoopData/tmp</value>
</property>

(3)修改配置文件hdfs-site.xml
[hdfs@master hadoop]$ sudo vim hdfs-site.xml
dfs.replication 参数配置的是备份副本的数量,这个数量不能大于datanode 的数量。系统默
认是3 份
dfs.name.dir 参数配置的是namenode 上存储hdfs 名字空间元数据
dfs.data.dir 参数配置的是datanode 上数据块的物理存储位置
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.dir</name>
<value>/home/hdfs/bigdata/hadoopData/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.dir</name>
<value>/home/hdfs/bigdata/hadoopData/hdfs/datanode</value>
</property>

(4)修改配置文件mapred-site.xml
因为配置文件mapred-site.xml 是不存在的,但有一个mapred-site.xml.temple 文件,所以我
们可以复制一个mapred-site.xml 出来
[hdfs@master hadoop]$ sudo cp mapred-site.xml.template mapred-site.xml
[hdfs@master hadoop]$ sudo vim mapred-site.xml
mapreduce.framework.name 参数配置的是mapreduce 的运行框架,这里使用的yarn 框架
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

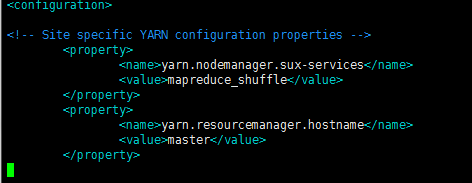
(5)修改配置文件yarn-site.xml
[hdfs@master hadoop]$ sudo vim yarn-site.xml
yarn.nodemanager.sux-services 参数配置的是yarn 的默认混洗方式,这里配置的是mapreduce
的默认混洗算法
<property>
<name>yarn.nodemanager.sux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
(6)配置文件slaves
[hdfs@master hadoop]$ sudo vim slaves
在里面写上所有datanode 节点的主机名

(六)将hadoop 文件发送到其它节点
(1)将bigdata整个文件夹给slave节点(包含创建一些hadoop 数据存放的目录)
[hdfs@master bigdata]$ scp -r /home/hdfs/bigdata/ slave1:/home/hdfs/
[hdfs@master bigdata]$ scp -r /home/hdfs/bigdata/ slave2:/home/hdfs/
(2)slave节点的环境变量记得配
三、启动服务
(一)格式化HDFS(主节点)
[hdfs@master bigdata]$ hdfs namenode -format
只需要格式化一次就行,出现successfully 就代表格式化成功

(二)启动HDFS(所有节点)
(1)启动NameNode
(2)启动Datanode
(3)启动SecondaryNamenode
[hdfs@master bigdata]$ hadoop-daemon.sh start namenode
[hdfs@master bigdata]$ hadoop-daemon.sh start datanode
[hdfs@master bigdata]$ hadoop-daemon.sh start secondarynamenode
(三)启动YARN(所有节点)
(1)启动Resourcemanager
(2)启动nodemanager
[hdfs@master bigdata]$ yarn-daemon.sh start resourcemanager
[hdfs@master bigdata]$ yarn-daemon.sh start nodemanager
也可以使用start-all.sh 一起启动所有的服务
(四)访问HDFS和YARN
在浏览器输入:http://10.18.16.110:50070,hadoop2.x hdfs 的默认访问端口是50070,
hadoop3.x hdfs 的默认访问端口是9870

在浏览器输入http://10.18.16.110:8088,8088 是YARN 的默认访问端口
