协同过滤(collaborative filtering)是一种在推荐系统中广泛使用的技术。该技术通过分析用户或者事物之间的相似性,来预测用户可能感兴趣的内容并将此内容推荐给用户。
这里的相似性可以是人口特征的相似性,也可以是历史浏览内容的相似性,还可以是个人通过一定机制给与某个事物的回应。比如,A和B是无话不谈的好朋友,并且都喜欢看电影,那么协同过滤会认为A和B的相似度很高,会将A喜欢但是B没有关注的电影推荐给B,反之亦然。
协同过滤推荐分为3种类型:
- 基于用户(user-based)的协同过滤(UserCF)
- 基于物品(item-based)的协同过滤(ItemCF算法)
- 基于模型(model-based)的协同过滤 (ModelCF算法)
技术提升
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
文章中的完整源码、资料、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自 获取推荐资料
方式②、微信搜索公众号:机器学习社区,后台回复:推荐资料
算法原理
ItemCF算法是目前业界使用最广泛的算法之一,亚马逊、Netflix、YouTube的推荐算法的基础都是基于ItemCF。
不知道大家平时在网上购物的时候有没有这样的体验,比如你在网上商城下单了一个手机,在订单完成的界面,网页会给你推荐同款手机的手机壳,你此时很可能就会点进去浏览一下,顺便买一个手机壳。
其实这就是ItemCF算法在背后默默工作。ItemCF算法给用户推荐那些和他们之前喜欢的物品相似的物品。因为你之前买了手机,ItemCF算法计算出来手机壳与手机之间的相似度较大,所以给你推荐了一个手机壳,这就是它的工作原理。
看起来是不是跟UserCF算法很相似是不是?只不过这次不再是计算用户之间的相似度,而是换成了计算物品之间的相似度。
由上述描述可以知道ItemCF算法的主要步骤如下:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
那么摆在我们面前的第一个问题就是如何计算物品之间的相似度,这里尤其要特别注意一下:
ItemCF算法并不是直接根据物品本身的属性来计算相似度,而是通过分析用户的行为来计算物品之间的相似度。
什么意思呢?比如手机和手机壳,除了形状相似之外没有什么其它的相似点,直接计算相似度似乎也无从下手。但是换个角度来考虑这个问题,如果有很多个用户在买了手机的同时,又买了手机壳,那是不是可以认为手机和手机壳比较相似呢?
由此引出物品相似度的计算公式:



最后将筛选出来的物品按照用户对其感兴趣程度逆序排序,取全体列表或者列表前K个物品推荐给用户,至此ItemCF算法完成。
算法工作流程
接下来我们用一个简单例子演示一下ItemCF的具体工作流程。
下表是一个简易的原始数据集,也称之为User-Item表,即用户-物品列表,记录了每个用户喜爱的物品,数据表格如下:
| 用户 |
喜爱的物品 |
| A |
{a,b,d} |
| B |
{b,c,e} |
| C |
{c,d} |
| D |
{b,c,d} |
| E |
{a,d} |


用户A的共现矩阵
上图是用户A的共现矩阵C,C[i][j]代表的含义是同时喜欢物品i和物品j的用户数量。举个例子,C[a][b]=1代表的含义就是同时喜欢物品a和物品b的用户有一个,就是用户A。
由于同时喜欢物品i和物品j的人与同时喜欢物品j和物品i的人数是一样的,所以这是一个对称矩阵。
同样的道理,其他用户也都有一张类似的表格。因为不同的用户的喜爱物品列表不一致,会导致每个用户形成的共现矩阵大小不一,这里为了统一起见,将矩阵大小扩充到nxn,其中n是所有用户喜欢物品列表的并集的大小。
下面用一张图来描述如何构建完整的共现矩阵:

通过对不同用户的喜爱物品集合构成的共现矩阵进行累加,最终得到了上图中的矩阵C,这其实就是相似度公式中的分子部分。
这里只是为了演示如何计算物品整体共现矩阵,实际在代码中我们并不会采用分别为每个用户建立一个共现矩阵再累加的方式。为了加快效率和节省空间,可以使用python的dict来实现,具体可以参考代码实现章节。
接下来我们计算最终的物品相似度矩阵,以物品a和物品b的相似度计算为例,通过上面计算的计算可知C[a][b]=1,即同时喜欢物品a和物品b的用户有一位。根据User-Item表可以统计出N(a)=2,N(b)=3,那么物品a和物品b的相似度计算如下:

有了物品相似度矩阵W之后,我们对用户进行物品推荐了,下面以给用户C推荐物品为例,展示一下计算过程:
可以看到用户C喜欢的物品列表为{c,d},通过查物品相似度矩阵可知,与物品c相似的有{b,d,e},同理与物品d相似的物品有{a,b,c},故最终给用户C推荐的物品列表为{a,b,e}(注意这里并不是{a,b,c,d,e},因为要去掉用户C喜欢的物品,防止重复推荐)。接下来分别计算用户C对这些物品的感兴趣程度。
P(C,a) = W[d][a] = 0.71
P(C,b) = W[c][b] + W[d][b]= 0.67 + 0.58 = 1.25
P(C,e) = W[c][e] = 0.58
故给用户C的推荐列表是{b,a,e}。
相似度算法改进
从前面的讨论可以看到,在协同过滤中两个物品产生相似度是因为它们共同出现在很多用户的兴趣列表中。换句话说,每个用户的兴趣列表都对物品的相似度产生贡献。那么是不是每个用户的贡献都相同呢?
假设有这么一个用户,他是开书店的,并且买了当当网上80%的书准备用来自己卖。那么他的购物车里包含当当网80%的书。假设当当网有100万本书,也就是说他买了80万本。从前面对ItemCF的讨论可以看到,这意味着因为存在这么一个用户,有80万本书两两之间就产生了相似 度,也就是说,内存里即将诞生一个80万乘80万的稠密矩阵。
John S. Breese在论文1中提出了一个称为IUF(Inverse User Frequence),即用户活跃度对数的 倒数的参数,他也认为活跃用户对物品相似度的贡献应该小于不活跃的用户,他提出应该增加IUF 参数来修正物品相似度的计算公式:

上述公式对活跃用户做了一种软性的惩罚,但是对于很多过于活跃的用户,比如上面那位买了当当网80%图书的用户,为了避免相似度矩阵过于稠密,我们在实际计算中一般直接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中。
相似度矩阵归一化处理
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w’:
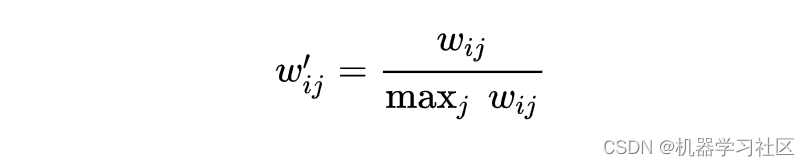
实验表明,归一化的好处不仅仅在于增强推荐的准确度,还可以提高推荐的覆盖率和多样性。
代码实践
根据之前的介绍,可知整个算法流程分为两个阶段:
对于训练阶段,可分为以下几步:
- 数据预处理,建立User-Item表
- 建立物品整体共现矩阵
- 建立物品相似度矩阵
对于推荐阶段,可分为以下几步:
- 寻找与被推荐用户喜爱物品集最相似的N个物品
- 计算用户对这N个物品的感兴趣程序列表并逆序排列
训练阶段
数据预处理,建立User-Item表
我们采用MovieLens数据集中的ratings.dat文件,因为这里面包含了用户对电影的评分数据,注意我们忽略掉评分那一栏,将其简化成用户喜欢或者不喜欢。只要用户有参与过评分的电影,无论分值如何,我们都认为这部电影是用户喜欢的。
注意,ratings.dat里面包含了100多万条评价数据,为了减少训练时间,可以只读取部分数据,本文读取了前29415条数据,即前200个用户的评价数据。ratings.dat原始数据每行包含了4列,本文中只取了’UserID‘、’MovieID‘这两列。
接下来使用以下代码来读取数据并建立User-Item表:
import random
import pandas as pd
def LoadMovieLensData(filepath, train_rate):
ratings = pd.read_table(filepath, sep="::", header=None, names=["UserID", "MovieID", "Rating", "TimeStamp"],\
engine='python')
ratings = ratings[['UserID','MovieID']]
train = []
test = []
random.seed(3)
for idx, row in ratings.iterrows():
user = int(row['UserID'])
item = int(row['MovieID'])
if random.random() < train_rate:
train.append([user, item])
else:
test.append([user, item])
return PreProcessData(train), PreProcessData(test)
def PreProcessData(originData):
"""
建立User-Item表,结构如下:
{"User1": {MovieID1, MoveID2, MoveID3,...}
"User2": {MovieID12, MoveID5, MoveID8,...}
...
}
"""
trainData = dict()
for user, item in originData:
trainData.setdefault(user, set())
trainData[user].add(item)
return trainData
建立物品整体共现矩阵
这里并没有采用对每个用户都建立共现矩阵再累加的方式,而是直接采用了两重dict来实现一个Matrix,然后在此基础上直接建立共现矩阵。
def ItemMatrix(trainData, similarity):
"""
建立物品共现矩阵
:param trainData: User-Item表
:param similarity: 相似度计算函数选择
:return:
"""
N = defaultdict(int) # 记录每个物品的喜爱人数
itemSimMatrix = defaultdict(int) # 共现矩阵
for user, items in trainData.items():
for i in items:
itemSimMatrix.setdefault(i, dict())
N[i] += 1
for j in items:
if i == j:
continue
itemSimMatrix[i].setdefault(j, 0)
if similarity == "cosine":
itemSimMatrix[i][j] += 1
elif similarity == "iuf":
itemSimMatrix[i][j] += 1. / math.log1p(len(items) * 1.)
return itemSimMatrix
建立物品相似度矩阵
这一步是是直接在物品共现矩阵的基础上除以两个物品各自喜爱人数的乘积,并且包含了数据归一化的处理。
def ItemSimilarityMatrix(ItemMatrix, N, isNorm):
"""
计算物品相似度矩阵
:param ItemMatrix:
:param N:
:param isNorm:
:return:
"""
itemSimMatrix = dict()
for i, related_items in ItemMatrix.items():
for j, cij in related_items.items():
# 计算相似度
itemSimMatrix[i][j] = cij / math.sqrt(N[i] * N[j])
# 是否要标准化物品相似度矩阵
if isNorm:
for i, relations in itemSimMatrix.items():
max_num = relations[max(relations, key=relations.get)]
# 对字典进行归一化操作之后返回新的字典
itemSimMatrix[i] = {k: v / max_num for k, v in relations.items()}
return itemSimMatrix
推荐阶段
def recommend(trainData, itemSimMatrix, user, N, K):
"""
:param trainData: User-Item表
:param itemSimMatrix: 物品相似度矩阵
:param user: 被推荐的用户user
:param N: 推荐的商品个数
:param K: 查找的最相似的用户个数
:return: 按照user对推荐物品的感兴趣程度排序的N个商品
"""
recommends = dict()
# 先获取user的喜爱物品列表
items = trainData[user]
for item in items:
# 对每个用户喜爱物品在物品相似矩阵中找到与其最相似的K个
for i, sim in sorted(itemSimMatrix[item].items(), key=itemgetter(1), reverse=True)[:K]:
if i in items:
continue # 如果与user喜爱的物品重复了,则直接跳过
recommends.setdefault(i, 0.)
recommends[i] += sim
# 根据被推荐物品的相似度逆序排列,然后推荐前N个物品给到用户
return dict(sorted(recommends.items(), key=itemgetter(1), reverse=True)[:N])
核心代码
下面的代码实现了完整的功能,修改“ratings.dat"文件的路径之后,可以直接运行。
import math
import random
import pandas as pd
from collections import defaultdict
from operator import itemgetter
def LoadMovieLensData(filepath, train_rate):
ratings = pd.read_table(filepath, sep="::", header=None, names=["UserID", "MovieID", "Rating", "TimeStamp"],\
engine='python')
ratings = ratings[['UserID','MovieID']]
train = []
test = []
random.seed(3)
for idx, row in ratings.iterrows():
user = int(row['UserID'])
item = int(row['MovieID'])
if random.random() < train_rate:
train.append([user, item])
else:
test.append([user, item])
return PreProcessData(train), PreProcessData(test)
def PreProcessData(originData):
"""
建立User-Item表,结构如下:
{"User1": {MovieID1, MoveID2, MoveID3,...}
"User2": {MovieID12, MoveID5, MoveID8,...}
...
}
"""
trainData = dict()
for user, item in originData:
trainData.setdefault(user, set())
trainData[user].add(item)
return trainData
class ItemCF(object):
""" Item based Collaborative Filtering Algorithm Implementation"""
def __init__(self, trainData, similarity="cosine", norm=True):
self._trainData = trainData
def similarity(self):
N = defaultdict(int) #记录每个物品的喜爱人数
for user, items in self._trainData.items():
for i in items:
self._itemSimMatrix.setdefault(i, dict())
N[i] += 1
for j in items:
if i == j:
continue
self._itemSimMatrix[i].setdefault(j, 0)
if self._similarity == "cosine":
self._itemSimMatrix[i][j] += 1
elif self._similarity == "iuf":
self._itemSimMatrix[i][j] += 1. / math.log1p(len(items) * 1.)
for i, related_items in self._itemSimMatrix.items():
for j, cij in related_items.items():
self._itemSimMatrix[i][j] = cij / math.sqrt(N[i]*N[j])
# 是否要标准化物品相似度矩阵
if self._isNorm:
for i, relations in self._itemSimMatrix.items():
max_num = relations[max(relations, key=relations.get)]
# 对字典进行归一化操作之后返回新的字典
self._itemSimMatrix[i] = {k : v/max_num for k, v in relations.items()}
def recommend(self, user, N, K):
"""
:param user: 被推荐的用户user
:param N: 推荐的商品个数
:param K: 查找的最相似的用户个数
:return: 按照user对推荐物品的感兴趣程度排序的N个商品
"""
recommends = dict()
# 先获取user的喜爱物品列表
items = self._trainData[user]
for item in items:
# 对每个用户喜爱物品在物品相似矩阵中找到与其最相似的K个
for i, sim in sorted(self._itemSimMatrix[item].items(), key=itemgetter(1), reverse=True)[:K]:
if i in items:
continue # 如果与user喜爱的物品重复了,则直接跳过
recommends.setdefault(i, 0.)
recommends[i] += sim
# 根据被推荐物品的相似度逆序排列,然后推荐前N个物品给到用户
return dict(sorted(recommends.items(), key=itemgetter(1), reverse=True)[:N])
if __name__ == "__main__":
train, test = LoadMovieLensData("../Data/ml-1m/ratings.dat", 0.8)
print("train data size: %d, test data size: %d" % (len(train), len(test)))
ItemCF = ItemCF(train, similarity='iuf', norm=True)
ItemCF.train()
# 分别对以下4个用户进行物品推荐
print(ItemCF.recommend(1, 5, 80))
上述代码对测试集中前4个用户进行了电影推荐,对每个用户而言,从与他们喜爱电影相似的80部电影中挑选出5部推荐。
输出结果是一个dict,里面包含了给用户推荐的电影以及用户对每部电影的感兴趣程度,按照逆序排列。
结果如下:
