拉格朗日函数用来求解等式约束的最优化问题;广义拉格朗日函数用来求解不等式约束的最优化问题。
无约束优化问题
关于优化问题包括无约束优化问题,等式约束优化问题,不等式约束优化问题。这里简略地介绍一下无约束优化问题。(以后再来填坑。)
考虑无约束优化问题:
min
x
f
(
x
)
\min \limits_{x} f(x)
xminf(x)
根据Fermat定理,直接找到使得
∇
x
f
(
x
)
=
0
\nabla_x f(x)=0
∇xf(x)=0的点即可。若无解析解,可以使用梯度下降或牛顿方法等使
x
x
x沿负梯度方向逐步逼近极小值点。2
等式约束优化
目标函数加上等式约束条件:
min
x
f
(
x
)
s
.
t
.
h
i
(
x
)
=
0
,
i
=
1
,
2
,
.
.
.
,
m
\begin{aligned} &\min \limits_x f(x) \\ &s.t. \quad h_i(x)=0, \quad i=1,2,...,m \end{aligned}
xminf(x)s.t.hi(x)=0,i=1,2,...,m
由于加上了等式约束条件,此时不一定能找到令
∇
x
f
(
x
)
=
0
\nabla_x f(x)=0
∇xf(x)=0的可行解,只需要在可行域内找到使得
f
(
x
)
f(x)
f(x)取最小值的点。常用的方法为拉格朗日乘子法,利用拉格朗日函数
L
(
x
,
α
)
L(x,\alpha)
L(x,α):
L
(
x
,
α
)
=
f
(
x
)
+
∑
i
=
1
m
α
i
h
i
(
x
)
L(x,\alpha)=f(x)+\sum_{i=1}^m \alpha_i h_i(x)
L(x,α)=f(x)+i=1∑mαihi(x)
其中
α
i
\alpha_i
αi为拉格朗日乘子。然后分别对
x
x
x和
α
=
(
α
1
,
.
.
.
,
α
m
)
T
\alpha=(\alpha_1,...,\alpha_m)^T
α=(α1,...,αm)T求导并令导数为0:
{
∇
x
L
(
x
,
α
)
=
0
∇
α
L
(
x
,
α
)
=
0
\left\{ \begin{aligned} \nabla_x L(x,\alpha) & = 0 \\ \nabla_\alpha L(x,\alpha) & = 0 \end{aligned} \right.
{∇xL(x,α)∇αL(x,α)=0=0
通过求解上述式子,获得极值点。
为什么拉格朗日乘子法能够得到最优值?
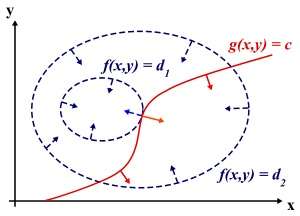
如图所示,满足条件的极值点应该是在目标函数的等高线与约束函数曲线相切的点,即等高线与约束曲线在该点的法向量必须共线,因此最优值必须满足:
∇
x
f
(
x
)
=
a
×
∇
x
g
(
x
)
\nabla_x f(x)=a × \nabla_x g(x)
∇xf(x)=a×∇xg(x)
这就是上述的
∇
x
L
(
x
,
α
)
=
0
\nabla_x L(x,\alpha)=0
∇xL(x,α)=0。再加上约束条件
h
i
(
x
)
=
0
h_i(x)=0
hi(x)=0,即
∇
α
L
(
x
,
α
)
=
0
\nabla_\alpha L(x,\alpha)=0
∇αL(x,α)=0。求解二式,可得到最优解。
不等式约束优化
给定不等式约束问题:
min
x
f
(
x
)
s
.
t
.
h
i
(
x
)
=
0
,
i
=
1
,
2
,
.
.
.
,
m
g
j
(
x
)
≤
0
,
j
=
1
,
2
,
.
.
.
,
n
\begin{aligned} &\min \limits_x f(x) \\ &s.t. \quad h_i(x)=0, \ i=1,2,...,m \\ & \qquad \ g_j(x) \leq 0, \ j=1,2,...,n \end{aligned}
xminf(x)s.t.hi(x)=0, i=1,2,...,m gj(x)≤0, j=1,2,...,n
定义广义拉格朗日函数:
L
(
x
,
α
,
β
)
=
f
(
x
)
+
∑
i
=
1
m
α
i
h
i
(
x
)
+
∑
j
=
1
n
β
i
g
i
(
x
)
L(x,\alpha,\beta)=f(x)+\sum_{i=1}^m \alpha_i h_i(x)+\sum_{j=1}^n \beta_i g_i(x)
L(x,α,β)=f(x)+i=1∑mαihi(x)+j=1∑nβigi(x)
加上不等式约束后可行解
x
x
x需满足KKT条件:
∇
x
L
(
x
,
α
,
β
)
=
0
β
j
g
j
(
x
)
=
0
,
j
=
1
,
2
,
.
.
.
,
n
h
i
(
x
)
=
0
,
i
=
1
,
2
,
.
.
.
,
m
g
j
(
x
)
≤
0
,
j
=
1
,
2
,
.
.
.
,
n
β
j
≥
0
,
j
=
1
,
2
,
.
.
.
,
n
\begin{aligned} \nabla_x L(x,\alpha,\beta) &= 0 \\ \beta_j g_j(x) &= 0, \ j=1,2,...,n \\ h_i(x) &= 0, \ i=1,2,...,m \\ g_j(x) &\leq 0, \ j=1,2,...,n \\ \beta_j &\geq 0, \ j=1,2,...,n \end{aligned}
∇xL(x,α,β)βjgj(x)hi(x)gj(x)βj=0=0, j=1,2,...,n=0, i=1,2,...,m≤0, j=1,2,...,n≥0, j=1,2,...,n
满足KKT条件后极小化广义拉格朗日函数即可得到在不等式约束条件下的可行解。
对偶问题
关于广义拉格朗日函数有一个重要的结论,即:
max
α
,
β
;
β
i
≥
0
L
(
x
,
α
,
β
)
=
{
f
(
x
)
,
x
满
足
原
始
问
题
约
束
+
∞
,
其
他
\max \limits_{\alpha,\beta; \beta_i \geq 0} L(x,\alpha, \beta) = \left\{ \begin{aligned} &f(x), \ x满足原始问题约束 \\ &+\infty, \ 其他 \end{aligned} \right.
α,β;βi≥0maxL(x,α,β)={f(x), x满足原始问题约束+∞, 其他
这很容易证明。当
h
i
(
x
)
=
0
h_i(x)=0
hi(x)=0且
g
j
(
x
)
≤
0
g_j(x) \leq 0
gj(x)≤0时,只需令
β
j
=
0
\beta_j=0
βj=0,可得
max
α
,
β
;
β
i
≥
0
L
(
x
,
α
,
β
)
=
f
(
x
)
\max \limits_{\alpha,\beta; \beta_i \geq 0} L(x,\alpha,\beta)=f(x)
α,β;βi≥0maxL(x,α,β)=f(x)。这样原始优化问题可转化无约束优化问题:
min
x
f
(
x
)
=
min
x
max
α
,
β
;
β
i
≥
0
L
(
x
,
α
,
β
)
\min \limits_x f(x)=\min \limits_x \max \limits_{\alpha,\beta; \beta_i \geq 0} L(x,\alpha,\beta)
xminf(x)=xminα,β;βi≥0maxL(x,α,β)
定义对偶函数:
D
(
α
,
β
)
=
min
x
L
(
x
,
α
,
β
)
D(\alpha,\beta)=\min \limits_x L(x,\alpha,\beta)
D(α,β)=xminL(x,α,β)
则原问题的对偶问题为:
max
α
,
β
;
β
i
≥
0
min
x
L
(
x
,
α
,
β
)
\max \limits_{\alpha,\beta;\beta_i \geq 0} \min \limits_x L(x,\alpha,\beta)
α,β;βi≥0maxxminL(x,α,β)
对偶问题的解
d
∗
d^{*}
d∗与原问题的解
p
∗
p^*
p∗满足如下关系:
d
∗
≤
p
∗
d^* \leq p^*
d∗≤p∗
即对偶问题的解是原问题解的下确界。
在KKT条件下,等式成立,因此我们可以通过求解对偶问题来求解原问题。
参考资料:
- 广义拉格朗日函数的理解
- 约束优化方法之拉格朗日乘子法与KKT条件
- 拉格朗日对偶