Supervisor分析
1.运行原理概述:
Supervisor生成主进程并将主进程变成守护进程,supervisor依次生成配置文件中的工作进程,然后依次监控工作进程的工作状态,并且主进程负责与supervisorctl客户端通信,实现主进程对子进程的控制。
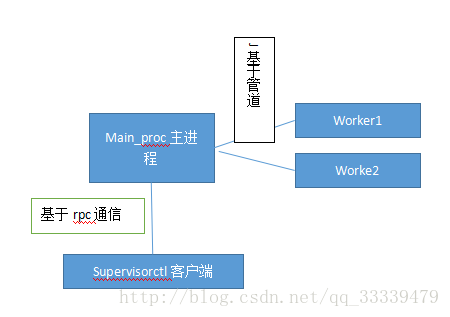
2.本次分析只分析supervisor的最小实现原理部分
1).supervisor生成主进程并成为守护进程,根据配置依次生成子进程
2).supervisor与supervisorctl基于rpc通信
3).子进程与主进程的管道通信
3.源码分析
本次源码基于supervisor-2.0b1
命令行启动
[wuzi:] supervisord
此时supervisord已经启动,我们就从这个命令中开始supervisord的分析
Supervisord文件中
#!/usr/bin/python
from supervisor.supervisord import main
main()
运行的开始函数开始于main, main中主要运行代码为:
while 1:
# if we hup, restart by making a new Supervisor()
# the test argument just makes it possible to unit test this code
options = ServerOptions()
d = Supervisor(options)
d.main(None, test, first)
1).ServerOptions类主要进行了配置文件的优化,提供服务器的初始化和主进程变成守护进程,子进程的创建和管理等工作。
2).Supervisor类主要实现了基于异步IO的服务器运行,接受子进程、rpc客户端的通信处理等工作。
3).d.main(None, test, first),主要执行了运行时的参数日志等初始化工作,并生成子进程,打开http服务器等工作。
d.main(None, test, first)代码为:
def main(self, args=None, test=False, first=False):
.......(省略部分初始化代码)
self.run(test)
def run(self, test=False):
self.processes = {}
for program in self.options.programs:
name = program.name
# 根据初始化后的配置文件生成相应的子进程实例
self.processes[name] = self.options.make_process(program)
try:
# 生成pid文件
self.options.write_pidfile()
# 打开http服务器
self.options.openhttpserver(self)
# 设置注册的信号量
self.options.setsignals()
# 主进程是否成为守护进程
if not self.options.nodaemon:
self.options.daemonize()
# 运行异步io服务器
self.runforever(test)
finally:
self.options.cleanup()
def runforever(self, test=False):
timeout = 1
# 获取已经注册的句柄
socket_map = self.options.get_socket_map()
while 1:
# mood表示主进程状态1为运行
if self.mood > 0:
self.start_necessary()
r, w, x = [], [], []
process_map = {}
# process output fds
# 子进程管道数据操作
for proc in self.processes.values():
proc.log_output()
drains = proc.get_pipe_drains()
for fd, drain in drains:
r.append(fd)
process_map[fd] = drain
# medusa i/o fds
# 网络socket io操作
for fd, dispatcher in socket_map.items():
if dispatcher.readable():
r.append(fd)
if dispatcher.writable():
w.append(fd)
# mood为主程序为停止状态
if self.mood < 1:
if not self.stopping:
self.stop_all()
self.stopping = True
# if there are no delayed processes (we're done killing
# everything), it's OK to stop or reload
delayprocs = self.get_delay_processes()
if delayprocs:
names = [ p.config.name for p in delayprocs]
namestr = ', '.join(names)
self.options.logger.info('waiting for %s to die' % namestr)
else:
break
try:
# 依次遍历注册的文件句柄
r, w, x = select.select(r, w, x, timeout)
except select.error, err:
if err[0] == errno.EINTR:
self.options.logger.log(self.options.TRACE,
'EINTR encountered in select')
else:
raise
r = w = x = []
for fd in r:
# 如果是子进程的管道事件
if process_map.has_key(fd):
drain = process_map[fd]
# drain the file descriptor
drain(fd)
# 如果是客户端的rpc读事件
if socket_map.has_key(fd):
try:
socket_map[fd].handle_read_event()
except asyncore.ExitNow:
raise
except:
socket_map[fd].handle_error()
for fd in w:
# 如果是客户端rpc写事件
if socket_map.has_key(fd):
try:
socket_map[fd].handle_write_event()
except asyncore.ExitNow:
raise
except:
socket_map[fd].handle_error()
# 判断配置子进程的状态,来决定该子进程是否运行(这其中是由于有些进程可以配置延迟执行),通过调用子进程实例的spwn()方法来运行子进程
self.give_up()
# 杀死没有要杀死但还没杀死的进程
self.kill_undead()
# 获取已经死亡的子进程信息
self.reap()
# 处理信号
self.handle_signal()
if test:
break
其中以上比较重要的步骤为:
1).明白子进程如果将数据发送给主进程
2).明白如何处理客户端发过来的rpc请求
Supervisor将http的句柄和管道的句柄放在了同一个select中进行了处理,
一.管道数据的发送
Linux中管道是单向传输数据的,如果创建管道后,如果要读就必须关闭管道的写操作。
首先我们先找到run()函数,其中有
for program in self.options.programs:
name = program.name
# 根据初始化后的配置文件生成相应的子进程实例
self.processes[name] = self.options.make_process(program)
找到options.py中,1029行,
def make_process(self, config):
from supervisord import Subprocess
return Subprocess(self, config)
其中Subprocess类的主要方法:
def spawn(self):
"""Start the subprocess. It must not be running already.
Return the process id. If the fork() call fails, return 0.
"""
pname = self.config.name
# 如果该实例已经有pid文件则该实例已经运行
if self.pid:
msg = 'process %r already running' % pname
self.options.logger.critical(msg)
return
# 相应状态的初始化
self.killing = 0
self.spawnerr = None
self.exitstatus = None
self.system_stop = 0
self.administrative_stop = 0
# 最后一次启动时间
self.laststart = time.time()
# 获取配置子进程的执行命令
filename, argv, st = self.get_execv_args()
# 检查该配置文件是否可以运行这些执行命令
fail_msg = self.options.check_execv_args(filename, argv, st)
if fail_msg is not None:
self.record_spawnerr(fail_msg)
return
try:
# 生成管道,生成与主进程通信的管道
self.pipes = self.options.make_pipes()
except OSError, why:
code = why[0]
if code == errno.EMFILE:
# too many file descriptors open
msg = 'too many open files to spawn %r' % pname
else:
msg = 'unknown error: %s' % errno.errorcode.get(code, code)
self.record_spawnerr(msg)
return
try:
# 生成子进程
pid = self.options.fork()
except OSError, why:
code = why[0]
if code == errno.EAGAIN:
# process table full
msg = 'Too many processes in process table to spawn %r' % pname
else:
msg = 'unknown error: %s' % errno.errorcode.get(code, code)
self.record_spawnerr(msg)
self.options.close_pipes(self.pipes)
return
if pid != 0:
# Parent
self.pid = pid
# 关闭父进程中管道的写
for fdname in ('child_stdin', 'child_stdout', 'child_stderr'):
self.options.close_fd(self.pipes[fdname])
self.options.logger.info('spawned: %r with pid %s' % (pname, pid))
self.spawnerr = None
self.delay = time.time() + self.config.startsecs
self.options.pidhistory[pid] = self
return pid
else:
# Child
try:
# prevent child from receiving signals sent to the
# parent by calling os.setpgrp to create a new process
# group for the child; this prevents, for instance,
# the case of child processes being sent a SIGINT when
# running supervisor in foreground mode and Ctrl-C in
# the terminal window running supervisord is pressed.
# Presumably it also prevents HUP, etc received by
# supervisord from being sent to children.
self.options.setpgrp()
# 0 将子进程的标准输入重定向到管道
self.options.dup2(self.pipes['child_stdin'], 0)
# 1 将子进程的标准输出重定向到管道
self.options.dup2(self.pipes['child_stdout'], 1)
# 2 将子进程的标准错误重定向到管道
self.options.dup2(self.pipes['child_stderr'], 2)
# 关闭子进程管道的读
for i in range(3, self.options.minfds):
self.options.close_fd(i)
# sending to fd 1 will put this output in the log(s)
msg = self.set_uid()
if msg:
self.options.write(
1, "%s: error trying to setuid to %s!\n" %
(pname, self.config.uid)
)
self.options.write(1, "%s: %s\n" % (pname, msg))
try:
# 子进程开始执行
self.options.execv(filename, argv)
except OSError, why:
code = why[0]
self.options.write(1, "couldn't exec %s: %s\n" % (
argv[0], errno.errorcode.get(code, code)))
except:
(file, fun, line), t,v,tbinfo = asyncore.compact_traceback()
error = '%s, %s: file: %s line: %s' % (t, v, file, line)
self.options.write(1, "couldn't exec %s: %s\n" % (filename,
error))
finally:
# 子进程执行完毕后,退出
self.options._exit(127)
其中,make_pipes()方法位于options.py中1033行,
def make_pipes(self):
""" Create pipes for parent to child stdin/stdout/stderr
communications. Open fd in nonblocking mode so we can read them
in the mainloop without blocking """
pipes = {}
try:
# 生成一个子进程标准输入管道的读和写句柄
pipes['child_stdin'], pipes['stdin'] = os.pipe()
# 生成一个子进程标准输出管道的读和写句柄
pipes['stdout'], pipes['child_stdout'] = os.pipe()
# 生成一个子进程标准错误管道的读和写句柄
pipes['stderr'], pipes['child_stderr'] = os.pipe()
# 将主进程中要读的管道设置成非阻塞,使之在异步io中不阻塞整个循环
for fd in (pipes['stdout'], pipes['stderr'], pipes['stdin']):
fcntl(fd, F_SETFL, fcntl(fd, F_GETFL) | os.O_NDELAY)
return pipes
except OSError:
self.close_pipes(pipes)
raise
此时,在上述代码中runforever()函数中:
for proc in self.processes.values():
proc.log_output()
drains = proc.get_pipe_drains()
for fd, drain in drains:
r.append(fd)
process_map[fd] = drain
Proc为进程实例,get_pipe_drains()返回管道的标准输出和标准错误输出
def get_pipe_drains(self):
if not self.pipes:
return []
drains = ( [ self.pipes['stdout'], self.drain_stdout],
[ self.pipes['stderr'], self.drain_stderr] )
return drains
其中,self.drain_stdout为
def drain_stdout(self, *ignored):
#将管道中的内容读出并保存
output = self.options.readfd(self.pipes['stdout'])
if self.config.log_stdout:
self.logbuffer += output
for fd in r:
if process_map.has_key(fd):
drain = process_map[fd]
# drain the file descriptor
# 其中drain就是self.drain_stdout或者self.drain_stderr
drain(fd)
至此管道的数据处理方式已经完成,管道数据的传递的基本原理已经分析完成
二.Rpc事件的处理
由于rpc的处理方式,使用了python中的asyncore, asynchat这两个包作为基础进行扩展。
这里对这两个包做个简要的分析,因为后面在rpc的处理中,会用到这两个包的基础知识。
由于在服务端异步编程中,
服务器端
ser=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
ser.bind(('127.0.0.1',8000))
ser.listen(5)
while 1:
client,addr=ser.accept()
print 'accept %s connect'%(addr,)
data=client.recv(1024)
print data
client.send('get')
client.close()
会初始化一个socket,如上例中的ser,这个ser只负责接收创建新的请求,client,addr=ser.accept(),当新接收的请求client再接收数据后然后再通过该请求client将该数据发送出去。
此时我们就有两个需求一个是专门的ser只负责接收新的请求,一个是专门处理新请求的实例,将新的请求并处理该请求的类对应到asyncore.py中dispatcher类为专门接收新请求的类和asynchat.py中就是async_chat专门处理新接收的请求。
asyncore.py简要分析
socket_map 为包全局的描述符的字典
poll()对应select模式
poll2()对应epoll模式
loop()函数根据当前的运行环境选择哪种异步IO模式
dispatcher()类
init(self, sock=None, map=None) 如果传入的sock为None则实例化为ser实例,如果sock不为None则是处理请求实例,并将该sock设置为非阻塞,加入socket_map中
add_channel(self, map=None) 添加socket_map中为自己的实例
del_channel(self, map=None) 删除socket_map中为自己的实例
create_socket(self, family=socket.AF_INET, type=socket.SOCK_STREAM) 创建ser实例,并将该实例设置为非阻塞,并加入socket_map中
set_socket(self, sock, map=None) 添加sock到socket_map中
set_reuse_addr(self) 设置ser监听的端口能够在断开监听后立马重新被监听
readable(self) 该sock是否可读
writable(self) 该sock是否可写
listen(self, num) 设置ser监听的数量
bind(self, addr) 设置ser监听的端口
connect(self, address) 设置连接地址
accept(self) 接收新的连接请求
send(self, data) 发送数据
recv(self, buffer_size) 接收数据
close(self) 关闭连接
handle_read_event(self) 处理读事件,如果是新请求则接收,如果是连接发送数据则接收
handle_connect_event(self) 处理新连接进来的请求
handle_write_event(self) 处理连接的写请求
以上为dispatcher主要的方法,
在asynchat.py中async_chat继承自dispatcher.该类的详细分析
class async_chat(asyncore.dispatcher):
"""This is an abstract class. You must derive from this class, and add
the two methods collect_incoming_data() and found_terminator()"""
# these are overridable defaults
# 接收缓存区大小
ac_in_buffer_size = 65536
# 发送数据缓冲区大小
ac_out_buffer_size = 65536
# we don't want to enable the use of encoding by default, because that is a
# sign of an application bug that we don't want to pass silently
use_encoding = 0
encoding = 'latin-1'
def __init__(self, sock=None, map=None):
# for string terminator matching
# 初始化接收缓冲区
self.ac_in_buffer = b''
# we use a list here rather than io.BytesIO for a few reasons...
# del lst[:] is faster than bio.truncate(0)
# lst = [] is faster than bio.truncate(0)
# 分段接收数据的列表
self.incoming = []
# we toss the use of the "simple producer" and replace it with
# a pure deque, which the original fifo was a wrapping of
# 发送数据时使用的队列数据结构
self.producer_fifo = deque()
# 调用dispatcher的构造方法,将sock设置成非阻塞,将sock添加到socket_map
asyncore.dispatcher.__init__(self, sock, map)
# 获取接收到的数据
def collect_incoming_data(self, data):
raise NotImplementedError("must be implemented in subclass")
def _collect_incoming_data(self, data):
self.incoming.append(data)
# 将所有接收到的数据
def _get_data(self):
d = b''.join(self.incoming)
del self.incoming[:]
return d
# 查找接收数据中的分隔符
def found_terminator(self):
raise NotImplementedError("must be implemented in subclass")
# 设置接收数据中的分隔符
def set_terminator(self, term):
"""Set the input delimiter.
Can be a fixed string of any length, an integer, or None.
"""
if isinstance(term, str) and self.use_encoding:
term = bytes(term, self.encoding)
elif isinstance(term, int) and term < 0:
raise ValueError('the number of received bytes must be positive')
self.terminator = term
# 获取已经设置的分隔符
def get_terminator(self):
return self.terminator
# grab some more data from the socket,
# throw it to the collector method,
# check for the terminator,
# if found, transition to the next state.
# 处理读事件
def handle_read(self):
try:
data = self.recv(self.ac_in_buffer_size)
except BlockingIOError:
return
except OSError as why:
self.handle_error()
return
if isinstance(data, str) and self.use_encoding:
data = bytes(str, self.encoding)
# 将读出的数据存入到接收缓冲区
self.ac_in_buffer = self.ac_in_buffer + data
# Continue to search for self.terminator in self.ac_in_buffer,
# while calling self.collect_incoming_data. The while loop
# is necessary because we might read several data+terminator
# combos with a single recv(4096).
while self.ac_in_buffer:
# 获取接收的数据长度
lb = len(self.ac_in_buffer)
# 获取设置的分隔符
terminator = self.get_terminator()
if not terminator:
# no terminator, collect it all
# 将已经接收的数据处理
self.collect_incoming_data(self.ac_in_buffer)
# 将接收缓冲区设置为空
self.ac_in_buffer = b''
# 如果设置分隔符是数字则接收相应长度的数据
elif isinstance(terminator, int):
# numeric terminator
n = terminator
if lb < n:
self.collect_incoming_data(self.ac_in_buffer)
self.ac_in_buffer = b''
# 将设置的分隔符长度减去已经接收的数据长度
self.terminator = self.terminator - lb
else:
# 清楚已经接收的数据
self.collect_incoming_data(self.ac_in_buffer[:n])
# 留下超出长度的部分
self.ac_in_buffer = self.ac_in_buffer[n:]
# 重置
self.terminator = 0
self.found_terminator()
else:
# 3 cases:
# 1) end of buffer matches terminator exactly:
# collect data, transition
# 2) end of buffer matches some prefix:
# collect data to the prefix
# 3) end of buffer does not match any prefix:
# collect data
terminator_len = len(terminator)
# 在接收缓冲区中查找分隔符
index = self.ac_in_buffer.find(terminator)
if index != -1:
# we found the terminator
if index > 0:
# don't bother reporting the empty string
# (source of subtle bugs)
self.collect_incoming_data(self.ac_in_buffer[:index])
# 将剩下的数据保留到接收数据缓冲区
self.ac_in_buffer = self.ac_in_buffer[index+terminator_len:]
# This does the Right Thing if the terminator
# is changed here.
self.found_terminator()
else:
# check for a prefix of the terminator
# 检查接收缓冲区是否已分隔符结尾
index = find_prefix_at_end(self.ac_in_buffer, terminator)
if index:
if index != lb:
# we found a prefix, collect up to the prefix
# 如果是分隔符结尾则结束本次处理
self.collect_incoming_data(self.ac_in_buffer[:-index])
self.ac_in_buffer = self.ac_in_buffer[-index:]
break
else:
# no prefix, collect it all
# 将接收缓冲区数据处理并重置
self.collect_incoming_data(self.ac_in_buffer)
self.ac_in_buffer = b''
def handle_write(self):
# 将处理的数据全部发送出去
self.initiate_send()
def handle_close(self):
# 关闭连接
self.close()
def push(self, data):
# 将连接处理后的数据全部加入发送缓冲区
if not isinstance(data, (bytes, bytearray, memoryview)):
raise TypeError('data argument must be byte-ish (%r)',
type(data))
sabs = self.ac_out_buffer_size
# 如果要发送出去的数据大于发送缓冲区大小,就使用生产者模式发送
if len(data) > sabs:
for i in range(0, len(data), sabs):
self.producer_fifo.append(data[i:i+sabs])
else:
self.producer_fifo.append(data)
self.initiate_send()
def push_with_producer(self, producer):
self.producer_fifo.append(producer)
self.initiate_send()
def readable(self):
"predicate for inclusion in the readable for select()"
# cannot use the old predicate, it violates the claim of the
# set_terminator method.
# return (len(self.ac_in_buffer) <= self.ac_in_buffer_size)
return 1
def writable(self):
"predicate for inclusion in the writable for select()"
return self.producer_fifo or (not self.connected)
def close_when_done(self):
"automatically close this channel once the outgoing queue is empty"
self.producer_fifo.append(None)
def initiate_send(self):
# 如果当前生产者队列不为空,连接未关闭就发送数据
while self.producer_fifo and self.connected:
first = self.producer_fifo[0]
# handle empty string/buffer or None entry
if not first:
# 如果数据生产者没有数据则删除该生产者,如果为None则所有数据已经发送完成,并关闭连接
del self.producer_fifo[0]
if first is None:
self.handle_close()
return
# handle classic producer behavior
obs = self.ac_out_buffer_size
try:
data = first[:obs]
except TypeError:
data = first.more()
if data:
self.producer_fifo.appendleft(data)
else:
del self.producer_fifo[0]
continue
if isinstance(data, str) and self.use_encoding:
# 将发送数据改为字节类型
data = bytes(data, self.encoding)
# send the data
try:
# 发送数据
num_sent = self.send(data)
except OSError:
self.handle_error()
return
if num_sent:
if num_sent < len(data) or obs < len(first):
# 如果发送的数据还没有完成则继续发送
self.producer_fifo[0] = first[num_sent:]
else:
del self.producer_fifo[0]
return
def discard_buffers(self):
# Emergencies only!
self.ac_in_buffer = b''
del self.incoming[:]
self.producer_fifo.clear()
对这两个包有大概了解后,我们开始分析run()方法中
self.options.openhttpserver(self)
该方法调用http中的make_http_server方法
def openhttpserver(self, supervisord):
from http import make_http_server
try:
self.httpserver = make_http_server(self, supervisord)
except socket.error, why:
if why[0] == errno.EADDRINUSE:
port = str(self.http_port.address)
self.usage('Another program is already listening on '
'the port that our HTTP server is '
'configured to use (%s). Shut this program '
'down first before starting supervisord. ' %
port)
except ValueError, why:
self.usage(why[0])
在http.py文件中,
def make_http_server(options, supervisord):
if not options.http_port:
return
# 配置的用户名和密码
username = options.http_username
password = options.http_password
class LogWrapper:
def log(self, msg):
if msg.endswith('\n'):
msg = msg[:-1]
options.logger.info(msg)
wrapper = LogWrapper()
family = options.http_port.family
# 如果是socket监听
if family == socket.AF_INET:
# 主要分析socket连接
host, port = options.http_port.address
# 生成http_server
hs = supervisor_af_inet_http_server(host, port, logger_object=wrapper)
# 如果是原始套接字
elif family == socket.AF_UNIX:
socketname = options.http_port.address
sockchmod = options.sockchmod
sockchown = options.sockchown
hs = supervisor_af_unix_http_server(socketname, sockchmod, sockchown,
logger_object=wrapper)
else:
raise ValueError('Cannot determine socket type %r' % family)
from xmlrpc import supervisor_xmlrpc_handler
from web import supervisor_ui_handler
# 本次分析的rpchandler
xmlrpchandler = supervisor_xmlrpc_handler(supervisord)
tailhandler = logtail_handler(supervisord)
here = os.path.abspath(os.path.dirname(__file__))
templatedir = os.path.join(here, 'ui')
filesystem = filesys.os_filesystem(templatedir)
uihandler = supervisor_ui_handler(filesystem, supervisord)
if username:
# wrap the xmlrpc handler and tailhandler in an authentication handler
users = {username:password}
from medusa.auth_handler import auth_handler
xmlrpchandler = auth_handler(users, xmlrpchandler)
tailhandler = auth_handler(users, tailhandler)
uihandler = auth_handler(users, uihandler)
else:
options.logger.critical('Running without any HTTP authentication '
'checking')
# 将handler注册到服务器类中
hs.install_handler(uihandler)
hs.install_handler(tailhandler)
hs.install_handler(xmlrpchandler)
return hs
这里分析supervisor_af_inet_http_server类,该类继承自supervisor_http_server,supervisor_http_server继承自http_server.http_server,http_server.http_server继承自asyncore.dispatcher,所以hs就是上例中的接收新请求的类,因为该实例的主要作用就是在新请求进来时处理
class http_server (asyncore.dispatcher):
SERVER_IDENT = 'HTTP Server (V%s)' % VERSION_STRING
channel_class = http_channel
def handle_accept (self):
self.total_clients.increment()
try:
# 接收新请求
conn, addr = self.accept()
except socket.error:
# linux: on rare occasions we get a bogus socket back from
# accept. socketmodule.c:makesockaddr complains that the
# address family is unknown. We don't want the whole server
# to shut down because of this.
self.log_info ('warning: server accept() threw an exception', 'warning')
return
except TypeError:
# unpack non-sequence. this can happen when a read event
# fires on a listening socket, but when we call accept()
# we get EWOULDBLOCK, so dispatcher.accept() returns None.
# Seen on FreeBSD3.
self.log_info ('warning: server accept() threw EWOULDBLOCK', 'warning')
return
# 将新请求用该类实例化处理
self.channel_class (self, conn, addr)
supervisor_http_server类的定义
channel_class = deferring_http_channel
所以通过deferring_http_channel处理该请求
deferring_http_channel继承自http_server.http_channel
http_server.http_channel继承自asynchat.async_chat
由于当该链接有可读数据时,就出触发handle_read函数,而该函数在接收数据放入接收缓冲区后,就会调用 found_terminator函数,
我们分析一下deferring_http_channel函数
def found_terminator (self):
""" We only override this to use 'deferring_http_request' class
instead of the normal http_request class; it sucks to need to override
this """
# 如果当前请求实例存在则继续处理接收数据
if self.current_request:
self.current_request.found_terminator()
# 如果不存在当前初始化实例
else:
# 第一次接收的数据
header = self.in_buffer
# 将接收缓冲区清空
self.in_buffer = ''
# 将头部信息分离出来
lines = string.split (header, '\r\n')
# --------------------------------------------------
# crack the request header
# --------------------------------------------------
while lines and not lines[0]:
# as per the suggestion of http-1.1 section 4.1, (and
# Eric Parker <eparker@zyvex.com>), ignore a leading
# blank lines (buggy browsers tack it onto the end of
# POST requests)
lines = lines[1:]
if not lines:
self.close_when_done()
return
# 第一行头部数据
request = lines[0]
# 第一行数据的命令,uri,版本
command, uri, version = http_server.crack_request (request)
# 处理剩下的头部信息
header = http_server.join_headers (lines[1:])
# unquote path if necessary (thanks to Skip Montanaro for pointing
# out that we must unquote in piecemeal fashion).
rpath, rquery = http_server.splitquery(uri)
if '%' in rpath:
if rquery:
uri = http_server.unquote (rpath) + '?' + rquery
else:
uri = http_server.unquote (rpath)
# 实例化一个http_request实例
r = deferring_http_request (self, request, command, uri, version,
header)
self.request_counter.increment()
self.server.total_requests.increment()
if command is None:
self.log_info ('Bad HTTP request: %s' % repr(request), 'error')
r.error (400)
return
# --------------------------------------------------
# handler selection and dispatch
# --------------------------------------------------
# 通过第一行信息来匹配注册的handlers
for h in self.server.handlers:
# 调用handler中的match方法,如果匹配rpc方法就返回rpchandler
if h.match (r):
try:
# 将该处理实例保存
self.current_request = r
# This isn't used anywhere.
# r.handler = h # CYCLE
# handler处理该请求
h.handle_request (r)
except:
self.server.exceptions.increment()
(file, fun, line), t, v, tbinfo = \
asyncore.compact_traceback()
self.log_info(
'Server Error: %s, %s: file: %s line: %s' %
(t,v,file,line),
'error')
try:
r.error (500)
except:
pass
return
# no handlers, so complain
r.error (404)
由于此次只分析rpchandler,supervisor_xmlrpc_handler继承自xmlrpc_handler分析xmlrpc_handler,通过协议来匹配该handler
def match (self, request):
# Note: /RPC2 is not required by the spec, so you may override this method.
if request.uri[:5] == '/RPC2':
return 1
else:
return 0
class supervisor_xmlrpc_handler(xmlrpc_handler):
def __init__(self, supervisord):
# rpc调用类方发接口,通过该类实现rpc客户端的对主进程的操作
self.rpcinterface = RPCInterface(supervisord)
# supervisord实例
self.supervisord = supervisord
def continue_request (self, data, request):
logger = self.supervisord.options.logger
try:
# 解析出上传的内容,并通过xmlrpclib解析成方法
params, method = xmlrpclib.loads(data)
try:
logger.debug('XML-RPC method called: %s()' % method)
# 调用方法执行
value = self.call(method, params)
logger.debug('XML-RPC method %s() returned successfully' %
method)
except RPCError, err:
# turn RPCError reported by method into a Fault instance
value = xmlrpclib.Fault(err.code, err.text)
logger.warn('XML-RPC method %s() returned fault: [%d] %s' % (
method,
err.code, err.text))
if isinstance(value, types.FunctionType):
# returning a function from an RPC method implies that
# this needs to be a deferred response (it needs to block).
pushproducer = request.channel.push_with_producer
pushproducer(DeferredXMLRPCResponse(request, value))
else:
# if we get anything but a function, it implies that this
# response doesn't need to be deferred, we can service it
# right away.
# 将方法执行的结果返回
body = xmlrpc_marshal(value)
request['Content-Type'] = 'text/xml'
request['Content-Length'] = len(body)
# 调用request.push方法,将body信息压入该内容自行阅读源码
request.push(body)
# 执行完后将数据发送出去,该内容自行阅读源码
request.done()
except:
io = StringIO.StringIO()
traceback.print_exc(file=io)
val = io.getvalue()
logger.critical(val)
# internal error, report as HTTP server error
request.error(500)
def call(self, method, params):
# 调用rpcinterface的方法
return traverse(self.rpcinterface, method, params)
该方法就是调用一个实例的方法
def traverse(ob, method, params):
path = method.split('.')
for name in path:
if name.startswith('_'):
# security (don't allow things that start with an underscore to
# be called remotely)
raise RPCError(Faults.UNKNOWN_METHOD)
ob = getattr(ob, name, None)
if ob is None:
raise RPCError(Faults.UNKNOWN_METHOD)
try:
return ob(*params)
except TypeError:
raise RPCError(Faults.INCORRECT_PARAMETERS)
至此一个rpchandle的处理就完成了
总结
[supervisor_demo](https://github.com/xiaowuzidaxia/sp_demo)
本文只是简要介绍了supervisor运行时的基本原理,由于水平有限,不能详细介绍其他更多功能,但是supervisor的基本原理已经介绍了,此时附一个基于python实现的简单的supervisor的demo希望对大家理解有帮助。[简单supervisor模型](https://github.com/xiaowuzidaxia/sp_demo)