新闻分类系统概述
新闻分类系统,顾名思义,就是对于一片新闻或者是一片文章,进行自动的分类,例如政治,财经,娱乐等等
从技术角度讲,其实属于自然语言处理中比较经典的文本分类问题。当然在一个工业级别的分类系统当中,会遇到各种各样的问题,例如语料优化,文本预处理,特征抽取,模型选择及融合,硬规则等一系列问题。本人有幸在国内某一线互联网公司做过相关的工作,故做一些总结。
分类系统架构设计
对于传统的分类系统来讲,就是如下这几个模块,包括文本预处理,特征抽取,特征选择,模型训练等。但是对于一个工业级的分类系统来说,这是远远不够的。
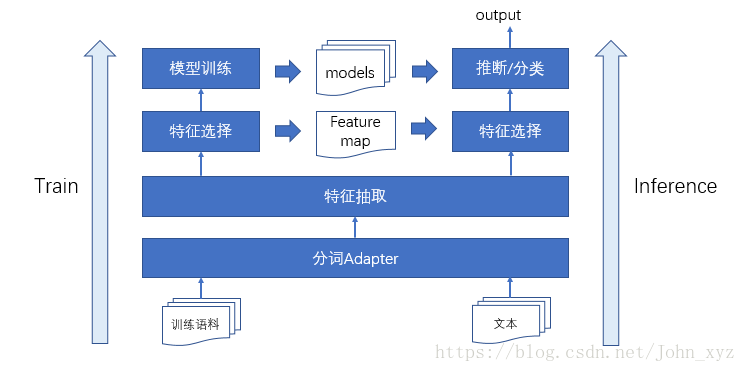
更加详细的分类模及每个模块的组件如下所示,将每个模块的结果都存入DataFlow用于定位问题。规则干预系统可以短期处理模型解决不了的case。
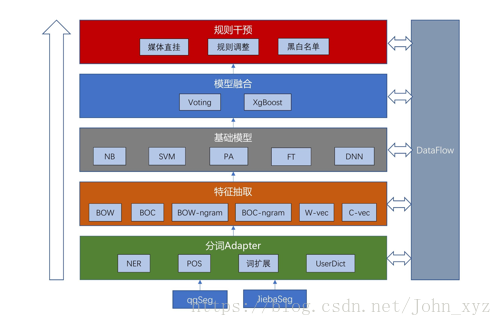
基本流程
-
文本预处理
文本预处理主要是指分词(涉及到分词粒度的选取),停留词,高频词和低频词的过滤。值得注意的是,训练时的处理流程和预测时的处理流程要保持一致,否则很有可能出现训练和测试分词不一致的情况,从而影响整个分类系统的性能。
-
特征抽取
特征抽取主要是从新闻的标题,正文中提取出特征,把新闻转换成固定维度的向量。
对于深度模型而言,可能不需要做特征抽取的工作,端到端直接训练即可。例如,fasttext,textcnn;
对于传统的机器学习模型来说,特征工程的质量会直接影响模型的分类性能;
在我的分类系统中,特征抽取主要包含三个方面:
n-gram特征,即如果是uni-gram,文本里面每个单词就是一个特征,如果是bi-gram,那么文本里面连续的两个单词也是一个特征。通常来讲,一般是uni-gram+bi-gram。n如果很大的话,特征会非常稀疏,导致特征向量维度过大
实体归一化特征是指,对于某些实体,可以将其映射到一个实体桶中,从而增加特征的泛化性能。例如"花千骨" ->“娱乐_电视剧”,“反恐精英” ->"游戏_射击游戏"等等。但有两个问题是,很多实体有歧义,对于这种实体可以不将其归一化,也可以根据上下文进行实体消歧(不在本文讨论范围内);第二个问题是实体归一化依赖于人工运营,且需要不断的更新,需要比较多的人力成本,但是对整个分类系统的改进也是非常明显的。
人工特征其实就是认为的设计一些规则,如果命中规则,那么就补充特征。相比于硬规则(命中规则就分到某个类别),更加平滑。
实际得到的特征是以上三类特征的级联
-
特征过滤及特征选择
特征过滤:
卡方检验进行特征选择:
-
基分类器的选取及训练
选用了四个模型fasttext, svm, pa, nb
-
nb训练速度快,对于大规模训练语料,几分钟就能训练完,而且解释性比较好。但缺点就是模型分类性能比较弱,因为特征独立的假设在新闻分类任务中应该是不成立的。
-
svm分类效果是最好的,但是训练时间比较长。
-
fasttext是端到端的训练,不依赖特征工程,训练效果也非常不错,但是可解释性比较差。
-
pa
上述的nb,svm,pa在sklearn中都有统一的接口可以直接调用,fasttext也有封装好的api,因此训练起来非常的方便。实际在做模型训练的时候,可以写一个统一的离线训练脚本。
-
模型融合策略
对于四个子模型,如果四个子模型或三个子模型预测的结果一致,则直接投票处理;
如果是其他情况,则可以考虑使用xgboost进行模型融合,具体的融合方法就是,对于每个样本来说,经过模型输出一个结果(可能是概率向量,即每个类别都对应的一个概率,实际去概率最大的那个类别),也可以经过各种平滑转换成概率向量。对于xgboost来说,输入就是每个子模型的输入的向量,输出就是类别。
-
规则系统
规则系统简单来说就是,当某个样本满足规则的时候,就将这个样本分到某个类别,而忽略模型的分类结果。比较硬,一般用于最新的新闻,比如最近"延禧攻略"等等。这种新闻因为语料库中没有相似的样本,所以分类很可能出错,使用规则可以短期处理这个问题,但是长期来看,可以将这批最新的数据加到语料中,重新训练模型。
需要注意的是:
- 规则上线之前都要做评估
- 尽可能减少对规则的依赖,可能会发生异常的后果
- 模型打包上线,对外提供服务
提升分类性能的小技巧
1. 新闻时效性问题
新闻的时效性问题很普遍,在一个工业级的产品中,有专门的算法去过滤过期的新闻。我们关心的是对于一些新的新闻,而且在训练语料中没有出现的特征,该怎么处理。短期可以用规则系统去解决。长期来讲,就要构造新的训练数据,和老训练数据做一定的融合,再进行特征抽取和特征选择,最后用总的数据重新训练再上线即可。
实际操作的时候可以写一个总的离线训练脚本,输入文件的路径,输出模型。脚本中包含特征抽取,模型训练,模型融合,模型评估等步骤,这样处理起来比较高效
2. 媒体直挂
对于一个feed流产品而言,很多的内容都是自媒体创造的,所以可以根据媒体的类型进行直挂。比如某个媒体是讲NBA的,那么这个媒体的内容大概率都是体育类。
3. 训练语料的分布及优化
训练语料中往往包含大量的噪声,如何对训练语料去噪也是一个比较头疼的问题。训练语料的优化主要包含三个个方面,一方面是某个类别的准确率很高,但是召回率不足;另一方面是准确率不足,召回率很高;还有就是准确召回都很低.
去噪手段:交叉验证,二分类器(置信度阈值),降采样,关键词
- 对于准确率很高,召回率不足的类:查看哪些类别和该类混淆的比较多,训练一个二分类器从该类别中去去除噪声;或者说如果两个类别相互混淆,可以使用十折交叉验证(9份数据训练,对1份数据去噪,循环操作)的方法去噪。
- 对于准确率很低,但召回率很高的类:这种情况可以看看召回错误样本的分布,然后利用降采样或者关键词的手段去噪
- 对于准确和召回都比较低的类:这就很难了,先处理上面两种情况吧。所有的去噪手段都可以试试…
4. Debug信息管理
一个工业级别的分类系统当中,往往都需要分析badcase,如果系统只给出分类结果的话,很难去查错。正确的姿势应该是在系统的每个节点,都给出相关的信息。比如每个子模型的每个结果,融合后模型的分类结果,是否命中媒体直挂系统,是否命中规则系统等等,对于朴素贝叶斯模型,可以给出每个单词的权重。通过这种方式去分析badcase,可以直接找到错误的原因,提高效率.
分类系统服务化中的架构设计问题
这个不在本文讨论范围内,有兴趣的同学可以自己去了解
开源项目