延迟队列的实现方案
一、应用场景
什么是延时队列?顾名思义:首先它要具有队列的特性,再给它附加一个延迟消费队列消息的功能,也就是说可以指定队列中的消息在哪个时间点被消费。
延时队列在项目中的应用场景是比较多的,尤其像电商类平台:
1、订单成功后,在30分钟内没有支付,自动取消订单
2、外卖平台发送订餐通知,下单成功后60s给用户推送短信。
3、如果订单一直处于某一个未完结状态时,及时处理关单,并退还库存
4、淘宝新建商户一个月内还没上传商品信息,将冻结商铺等
5、公司的会议预定系统,在会议预定成功后,会在会议开始前半小时通知所有预定该会议的用户。
6、工单超过24小时未处理,则自动提醒相关责任人。
为了解决以上问题,最简单直接的办法就是定时去扫表。每个业务都要维护一个自己的扫表逻辑。 当业务越来越多时,我们会发现扫表部分的逻辑会非常类似。我们可以考虑将这部分逻辑从具体的业务逻辑里面抽出来,变成一个公共的部分。
这种场景下,就需要使用到我们今天的主角 —— 延迟队列了。延迟队列为我们提供了一种高效的处理大量需要延迟消费消息的解决方案。那么话不多说,下面我们就来看一下几种常见的延迟队列的解决方案以及他们各自的优缺点。
二、实现方案
1、轮询数据库
对于数据量比较少并且时效性要求不那么高的场景,一种比较简单的方式是轮询数据库,比如每秒轮询一下数据库中所有数据,处理所有到期的数据,比如如果我是公司内部的会议预定系统的开发者,我可能就会采用这种方案,因为整个系统的数据量必然不会很大并且会议开始前提前30分钟提醒与提前29分钟提醒的差别并不大。但是如果需要处理的数据量比较大实时性要求比较高,比如淘宝每天的所有新建订单15分钟内未支付的自动超时,数量级高达百万甚至千万,这时候如果你还敢轮询数据库怕是要被你老板打死,不被老板打死估计也要被运维同学打死。
最简单的方式,定时扫表;例如每分钟扫表一次十分钟之后未支付的订单进行主动支付 ;
优点: 简单
缺点: 每分钟全局扫表,浪费资源,有一分钟延迟,如果数据量大的话轮询数据库方式不能采用, 如果遇到表数据订单量即将过期的订单量很大,会造成关单延迟。
我们可以使用 zset这个命令,用设置好的时间戳作为score进行排序,使用 zadd score1 value1 …命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务,通过循环执行队列任务即可。也可以通过 zrangebyscore key min max withscores limit 0 1 查询最早的一条任务,来进行消费.通过以下这几个操作使用 Redis 的 ZSet 来实现一个延迟队列:
- 入队操作:
ZADD KEY timestamp task, 我们将需要处理的任务,按其需要延迟处理时间作为 Score 加入到 ZSet 中。Redis 的 ZAdd 的时间复杂度是O(logN),N是 ZSet 中元素个数,因此我们能相对比较高效的进行入队操作。
- 起一个进程定时(比如每隔一秒)通过
ZREANGEBYSCORE方法查询 ZSet 中 Score 最小的元素,具体操作为:ZRANGEBYSCORE KEY -inf +inf limit 0 1 WITHSCORES。查询结果有两种情况:
a. 查询出的分数小于等于当前时间戳,说明到这个任务需要执行的时间了,则去异步处理该任务;
b. 查询出的分数大于当前时间戳,由于刚刚的查询操作取出来的是分数最小的元素,所以说明 ZSet 中所有的任务都还没有到需要执行的时间,则休眠一秒后继续查询;
同样的,ZRANGEBYSCORE操作的时间复杂度为O(logN + M),其中N为 ZSet 中元素个数,M为查询的元素个数,因此我们定时查询操作也是比较高效的。
这里从网上搬运了一套 Redis 实现延迟队列的后端架构,其在原来 Redis 的 ZSet 实现上进行了一系列的优化,使得整个系统更稳定、更健壮,能够应对高并发场景,并且具有更好的可扩展性,是一个挺不错的架构设计,其整体架构图如下:

其核心设计思路:
- 将延迟的消息任务通过 hash 算法路由至不同的 Redis Key 上,这样做有两大好处:
a. 避免了当一个 KEY 在存储了较多的延时消息后,入队操作以及查询操作速度变慢的问题(两个操作的时间复杂度均为O(logN))。
b. 系统具有了更好的横向可扩展性,当数据量激增时,我们可以通过增加 Redis Key 的数量来快速的扩展整个系统,来抗住数据量的增长。
- 每个 Redis Key 都对应建立一个处理进程,称为 Event 进程,通过上述步骤 2 中所述的 ZRANGEBYSCORE 方法轮询 Key,查询是否有待处理的延迟消息。
- 所有的 Event 进程只负责分发消息,具体的业务逻辑通过一个额外的消息队列异步处理,这么做的好处也是显而易见的:
a. 一方面,Event 进程只负责分发消息,那么其处理消息的速度就会非常快,就不太会出现因为业务逻辑复杂而导致消息堆积的情况。
b. 另一方面,采用一个额外的消息队列后,消息处理的可扩展性也会更好,我们可以通过增加消费者进程数量来扩展整个系统的消息处理能力。
- Event 进程采用 Zookeeper 选主单进程部署的方式,避免 Event 进程宕机后,Redis Key 中消息堆积的情况。一旦 Zookeeper 的 leader 主机宕机,Zookeeper 会自动选择新的 leader 主机来处理 Redis Key 中的消息。
从上述的讨论中我们可以看到,通过 Redis Zset 实现延迟队列是一种理解起来较为直观,可以快速落地的方案。并且我们可以依赖 Redis 自身的持久化来实现持久化,使用 Redis 集群来支持高并发和高可用,是一种不错的延迟队列的实现方案。
3、rabbit mq
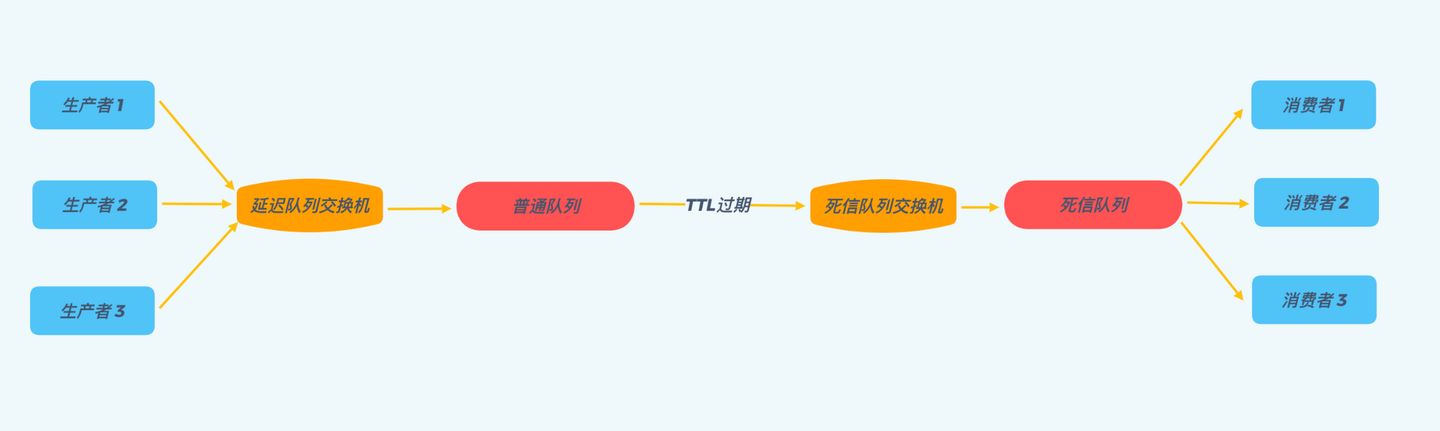
RabbitMQ 本身并不直接提供对延迟队列的支持,我们依靠 RabbitMQ 的TTL以及死信队列功能,来实现延迟队列的效果。那就让我们首先来了解一下,RabbitMQ 的死信队列以及 TTL 功能。
死信队列
死信队列实际上是一种 RabbitMQ 的消息处理机制,当 RabbmitMQ 在生产和消费消息的时候,消息遇到如下的情况,就会变成“死信”:
- 消息被拒绝
basic.reject/ basic.nack 并且不再重新投递 requeue=false
- 消息超时未消费,也就是 TTL 过期了
- 消息队列到达最大长度
消息一旦变成一条死信,便会被重新投递到死信交换机(Dead-Letter-Exchange),然后死信交换机根据绑定规则转发到对应的死信队列上,监听该队列就可以让消息被重新消费。
TTL
TTL(Time-To-Live)是 RabbitMQ 的一种高级特性,表示了一条消息的最大生存时间,单位为毫秒。如果一条消息在 TTL 设置的时间内没有被消费,那么它就会变成一条死信,进入我们上面所说的死信队列。
有两种不同的方式可以设置消息的 TTL 属性:
- 一种方式是直接在创建队列的时候设置整个队列的 TTL 过期时间,所有进入队列的消息,都被设置成了统一的过期时间,一旦消息过期,马上就会被丢弃,进入死信队列.
- 另一种方式是针对单条消息设置, 需要不同的消息设置不同的延迟时间,上面针对队列的 TTL 设置便无法满足我们的需求,需要使用这种针对单个消息的 TTL 设置。
RabbitMQ可以针对Queue设置x-expires 或者 针对Message设置 x-message-ttl,来控制消息的生存时间,如果超时(两者同时设置以最先到期的时间为准),则消息变为dead letter(死信)。RabbitMQ针对队列中的消息过期时间有两种方法可以设置。
A: 通过队列属性设置,队列中所有消息都有相同的过期时间。
B: 对消息进行单独设置,每条消息TTL可以不同。
如果同时使用,则消息的过期时间以两者之间TTL较小的那个数值为准。消息在队列的生存时间一旦超过设置的TTL值,就成为dead letter。
TTL 不就是延迟队列中消息要延迟的时间么?如果我们把需要延迟的消息,将 TTL 设置为其延迟时间,投递到 RabbitMQ 的普通队列中,一直不去消费它,那么经过 TTL 的时间后,消息就会自动被投递到死信队列,这时候我们使用消费者进程实时地去消费死信队列中的消息,不就实现了延迟队列的效果。使用 RabbitMQ 来实现延迟队列,我们可以很好的利用一些 RabbitMQ 的特性,比如消息可靠发送、消息可靠投递、死信队列来保障消息至少被消费一次以及未被正确处理的消息不会被丢弃。另外,通过 RabbitMQ 集群的特性,可以很好的解决单点故障问题,不会因为单个节点挂掉导致延迟队列不可用或者消息丢失。
从下图可以直观的看出使用 RabbitMQ 实现延迟队列的整体流程:
4、kafka 时间轮
Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList 是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务 TimerTask。在 Kafka 源码中对这个 TimeTaskList 是用一个名称为 buckets 的数组表示的。Kafka中一个时间轮TimingWheel是由20个时间格组成,wheelSize = 20;每格的时间跨度是1ms,tickMs = 1ms。
Kafka的时间轮还有一个表盘指针 currentTime,表示时间轮当前所处的时间。随着时间推移, 这个指针也会不断前进; 随着时间的推移,指针 currentTime 不断向前推进,过了 n ms 之后,当 currentTime 指向时间格 2时,就需要将对应的 TimerTaskList 中的任务进行到期操作。

Kafka 为此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中。

kafka的定时器只是持有第一层时间轮的引用,并不会直接持有其他高层时间轮的引用,但是每个时间轮都会有一个指向更高一层时间轮的引用,随着时间的推移,高层时间轮内的定时任务也会重新插入到底层时间轮内,直到插入到第一层时间轮内等待被最终的执行。现在,每个任务除了要维护在当前轮盘的 round,还要计算在所有下级轮盘的 round。当本层的 round为0时,任务按下级 round 值被下放到下级轮子,最终在最底层的轮盘得到执行。
多层次时间轮还会有降级的操作,假设一个任务延迟500秒执行,那么刚开始加进来肯定是放在第三层的,当时间过了 436 秒后,此时还需要 64 秒就会触发任务的执行,而此时相对而言它就是个延迟64秒后的任务,因此它会被降低放在第二层中,第一层还放不下它。再过个 56 秒,相对而言它就是个延迟8秒后执行的任务,因此它会再被降级放在第一层中,等待执行。
优势:
- 时间精度可控;
- 并且增删任务的时间复杂度都是O(1);
缺点:
- 时间轮的推进是根据时间精度TickDuration来固定推进的,如果槽位中无任务,也需要移动指针,会造成无效的时间轮推进,比如TickDuration为1秒,此时就一个延迟500秒的任务,那就是有499次无用的推进。
- 任务的执行都是同一个工作线程处理的,并且工作线程的除了处理执行到时的任务还做了其他操作,因此任务不一定会被精准的执行,而且任务的执行如果不是新起一个线程执行,那么耗时的任务会阻塞下个任务的执行。
一种直观的想法是,像现实中的钟表一样,“一格一格”地走,这样就需要有一个线程一直不停的执行,而大多数情况下,时间轮中的bucket大部分是空的,指针的“推进”就没有实质作用。
空推进与DelayQueue
为了减少这种“空推进”,kafka的设计者就使用了DelayQueue+时间轮的方式,来保证kafka的高性能定时任务的执行,Delayqueue负责时间轮的推进工作,时间轮则负责将每个定时任务TimerTaskEntry按照时间顺序插入以及删除,然后又使用专门的一个线程来从DelayQueue中获取到期的任务列表,然后执行对应的操作,这样就利用空间换时间的思想解决了空推进的问题,保证了kafka的高性能运行。Kakfa是将每个使用到的TimerTaskList加入到DelayQueue当中,DelayQueue会根据TimerTaskList对应的超时时间来排序。此时,我们只需要查看一下DelayQueue中队列头的超时时间,等待时间到就去执行任务即可,而不用使时间轮"空转"。
- Kafka用DelayQueue保存每个bucket,以bucket为单位入队,通过每个bucket的过期时间排序(堆排序),这样拥有最早需要执行任务的槽会被优先获取。如果时候未到,那么delayQueue.poll就会阻塞着。
- 每当有bucket到期,即queue.poll能拿到结果时,才进行时间的“推进”,减少了 ExpiredOperationReaper 线程空转的开销。这样就不会有空推进的情况发生,同时呢,任务组织结构仍由时间轮组织,也兼顾了任务插入、删除操作的高性能。
Kafka中的定时器真可谓是“知人善用”,用TimingWheel做最擅长的任务添加和删除操作,而用DelayQueue做最擅长的时间推进工作,相辅相成。
参考链接1
参考链接2
5、kafka 多topic
创建多个topic 用于处理不同的延迟消息,例如延迟一分钟的任务消息,让 topic为 delay-minutes-1 进行处理。
- 发送延迟消息时不直接发到目标topic,而是发到一个用于处理延迟消息的topic,例如 delay-minutes-1
- 写一段代码定时拉取 delay-minutes-1 中的消息,将满足的消息发到真正的目标主题里。
缺点:超时时间需要提前预知,并且固定有限制和topic数量相关。
如何让延迟消息等待一段时间才发送到真正的topic里面?
KafkaConsumer 提供了暂停和恢复的API函数,调用消费者的暂停方法后就无法再拉取到新的消息,同时长时间不消费kafka也不会认为这个消费者已经挂掉了。另外为了能够更加优雅,我们会启动一个定时器来替换sleep。当消费者发现消息不满足条件时,我们就暂停消费者,并把偏移量seek到上一次消费的位置以便等待下一个周期再次消费这条消息。
缺点:kafka内部改造复杂度较高,由于要使 consumer 进行 pause,还需要额外的做一些健康检查操作,在状态不对时可以报警或者重启。另外,不支持灵活设置延时时间。