先上结果
优化前

优化后

工作中有一个业务场景一条命中记录会存储到一张命中记录A表,并且推送给用户,每一条推送记录存储到B表, AB是一对多的关系.现在一条sql语句是用户查看命中记录列表,按照命中的时间倒序排序.表结构如下
A表
CREATE TABLE `t_alarm_notice_all` (
`id` varchar(32) NOT NULL,
`taskId` varchar(125) ,
`alarmType` smallint(4) DEFAULT NULL ,
`objectId` varchar(125) DEFAULT NULL ,
`idCard` varchar(18) DEFAULT NULL ,
`name` varchar(125) DEFAULT NULL ,
`hitType` varchar(20) NOT NULL ,
`hitValue` varchar(200) NOT NULL,
`model` smallint(4) DEFAULT NULL ,
`sml` decimal(10,10) DEFAULT NULL,
`ceid` varchar(125) DEFAULT NULL ,
`cead` varchar(250) DEFAULT NULL ,
`lon` varchar(20) DEFAULT NULL ,
`lat` varchar(20) DEFAULT NULL ,
`latm` datetime DEFAULT NULL ,
`imtm` datetime NOT NULL COMMENT ,
`rowkey` text,
`gathers` text ,
`childId` text ,
`taskName` varchar(255) DEFAULT NULL ,
`faceImgPath` varchar(200) DEFAULT NULL,
`bgImgPath` varchar(200) DEFAULT NULL,
`engineMatchInfos` varchar(1000) DEFAULT NULL,
`groupId` varchar(255) DEFAULT NULL ,
`snapshotId` varchar(255) DEFAULT NULL ,
`engineMatchList` text,
`originHitValue` varchar(200) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_hitType` (`hitType`) USING BTREE,
KEY `idx_ceid` (`ceid`) USING BTREE,
KEY `idx_taskId` (`taskId`) USING BTREE,
KEY `idx_latm` (`latm`,`taskId`) USING BTREE,
KEY `idx_hitvalue` (`hitValue`) USING BTREE,
KEY `idx_object` (`alarmType`,`objectId`) USING BTREE,
KEY `idx_union` (`hitValue`,`objectId`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC ;
SET FOREIGN_KEY_CHECKS = 1;
B表
CREATE TABLE `t_notice_send` (
`id` int(32) NOT NULL AUTO_INCREMENT,
`userId` int(11) DEFAULT NULL ,
`noticeId` char(32) DEFAULT NULL ,
`createTime` datetime DEFAULT NULL ,
`delFlag` smallint(1) DEFAULT NULL ,
`isRead` smallint(1) DEFAULT '0' ,
`latm` datetime DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `id` (`id`) USING BTREE,
KEY `userId` (`userId`) USING BTREE,
KEY `delFlag` (`delFlag`) USING BTREE,
KEY `noticeId` (`noticeId`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=500001 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
SET FOREIGN_KEY_CHECKS = 1;
查询历史列表的sql如下
SELECT
t1.*
FROM
t_alarm_notice_all t1,
t_notice_send t2
WHERE
t1.id = t2.noticeId
AND
t2.userId = 999
ORDER BY
t1.latm DESC
LIMIT 100;
当 AB 表的数量达到了50W左右的体系时候,这条sql的查询时间达到了18s
explain 命令查询

可以看到key字段上面使用了索引, 但是为什么t2需要排序?
流程分析
- explain 相同,从上往下执行, t2为驱动表.在索引选择上,有 userid 和 noticeid,真正使用的索引是 userid.
- 遍历t2 的userid 索引树,找到userid = 999的内容,获得到主键id.
- 去主键索引上查找对应id的全部数据,找到noticeid的值
- 通过noticeid去t1表主键索引寻找对应的值,
因为还有一个order by关键字,mysql需要排序. mysql会给每个线程分配一块内存用于排序,成为 sort_buffer.
- 通过t1主键索引找到确定的一条数据后, 因为select t1.* 所以需要把t1的整行数据都放入 sort_buffer 中
- 重复2到5的操作直到userid不等于999结束
- 对sort_buffer中的数据按照latm 做快速排序
- 按照排序结果取前100条给客户端
按照latm给sort_buffer排序这个动作,可能在内存中完成,也可能需要使用外部排序, 这取决于排序所需内存和参数 sort_buffer_size
可以使用如下方法确定排序是否使用了临时文件
set optimizer_trace='enabled=on';
select variable_value into @a from performance_schema.session_status where variable_name = "Innodb_rows_read";
SELECT
t1.*
FROM
t_alarm_notice_all t1,
t_notice_send t2
WHERE
t1.id = t2.noticeId
AND
t2.userId = 999
ORDER BY
t2.createTime DESC
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SELECT variable_value into @b FROM `performance_schema`.session_status WHERE variable_name = 'Innodb_rows_read';
SELECT @b-@a;

运行结果的 trace 中寻找 filesort_summary 字段
"filesort_summary": {
"rows": 500000,
"examined_rows": 500000,
"number_of_tmp_files": 1132,
"sort_buffer_size": 8840,
"sort_mode": "<sort_key, rowid>"
}
number_of_tmp_files 表示排序过程使用的临时文件个数.mysql外部排序采用归并算法,所以产生了多个临时文件
examined_rows 表示参与排序的数量为50万行
sort_mode 表示排序过程中使用了 rowid 排序
最后一个结果 @b-@a = 1500100 表示整个过程扫描了1500100行
分析一下为什么最后的结果是 1500100行.
rowid排序
上面的排序算法是针对 非rowid排序,因为如果单行数据量太大,那么sort_buffer中存放的字段过多,sort_buffer存储的行数就太少,需要分成很多个临时文件,所以mysql认为单行太大之后会采取 rowid排序.
新的算法放入sort_buffer的字段,只有需要排序的列 latm 和主键id,但是因为缺少了其他的字段,不能直接返回,所以流程更改为
- 初始化sort_buffer 确定放入两个字段 latm 和 id
- 从索引id 找到数据,取出latm 和id字段,存入sort_buffer中
- 重复2步骤,直到索引id不在 t2表的范围之内
- 对sort_buffer中数据按照字段latm排序
- 取出前100行,再根据id的值去索引中获得最终数据返回
查询行数计算
- 通过userid = 999 获得第一条记录 +1
- 通过userid索引下面的主键id查询主键索引 +2
- 通过主键索引获得noticeid去 t1 表中查询主键id=noticeid的数据 +3
userid = 999 的数据一共有50w条,一条查询需要走3次, 50W条就是 50*3 = 150w.
最后生成的带有 id 和 latm 的临时表中排序生成前100条数据,在根据id去t1表中查询主键,需要再查100次.
所以结果是150万零100;
开始优化
通过 show profile cpu,block io for query id 详细分析情况
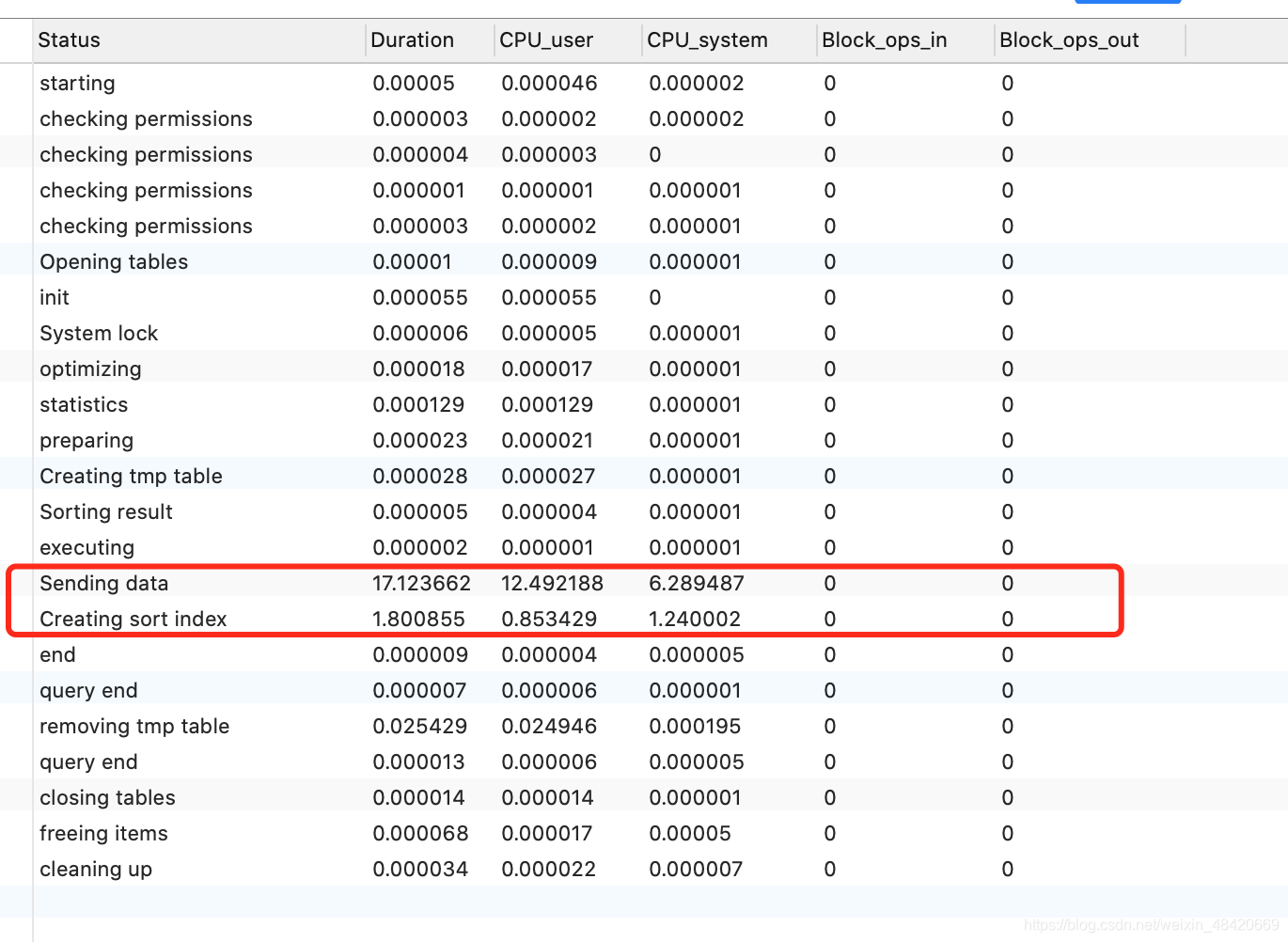
可以看到,虽然创建临时文件达到了1000多条,但是最耗时的操作并不是原来想象的 使用了临时表排序等等,而是
sending data
sending data代表mysql收集数据和发送数据的总和
也就是来回查询数据的耗时.
方案1
回头分析这段sql的业务代码本身,一条消息推送过来之后,存入消息表t1,然后给每个用户推送一条这个消息,每一条推送消息就是t2. 某一个用户查看历史消息列表的时候形成的sql.
在explain 原本sql的时候, t2可以有两个索引可以选择,我们再来回头看一下sql
SELECT
t1.*
FROM
t_alarm_notice_all t1,
t_notice_send t2
WHERE
t1.id = t2.noticeId
AND
t2.userId = 999
ORDER BY
t1.latm DESC
LIMIT 100;
这里如果是选择了userid作为索引,则表示 t2是驱动表.遍历 t2的 userid= 该用户id的数据= 50w
如果选择了 noticeid 作为索引,则表示 t1是驱动表,查询逻辑变为 先从t1的索引latm 上排序选择,则流程变为
noticeid作为索引的选择
t1表根据latm索引天生的排序功能,直接从第一条开始查询,通过索引上带有的id主键,直接去t2表上的noticeid上索引查询,查询到t2的主键id后再去t2的主键索引上查询数据,判断这条数据的userid是不是等于999,如果是的话添加到结果集中.
如果结果集总数为100了,就返回.
SELECT
t1.*
FROM
t_alarm_notice_all t1,
t_notice_send t2 force index(noticeId)
WHERE
t1.id = t2.noticeId
AND
t2.userId = 888
ORDER BY
t1.latm DESC
limit 100;
看似很完美是不?
实际生产环境中,因为是历史消息列表,所以是带有分页功能的,我们在查询语句的时候使用的是 mybatis 分页插件, 获取数据总数的时候,mybatis自动把查询语句变为
select
count(0)
from(
SELECT
t1.*
FROM
t_alarm_notice_all t1,
t_notice_send t2 force index(noticeId)
WHERE
t1.id = t2.noticeId
AND
t2.userId = 888
ORDER BY
t1.latm DESC
) temp
这条语句的执行逻辑是什么呢?
遍历整个latm 索引,取出每一条记录到t2表中查询userid是不是等于888.这样, latm 整个索引树为50W 条, 在每条都去 t2中查询一次,所以结果为 100W 次查询
set optimizer_trace='enabled=on';
select variable_value into @a from performance_schema.session_status where variable_name = "Innodb_rows_read";
SELECT
count(*)
FROM(
SELECT
t1.*
FROM
t_alarm_notice_all t1,
t_notice_send t2 force index(noticeId)
WHERE
t1.id = t2.noticeId
AND
t2.userId = 888
ORDER BY
t1.latm DESC
) temp ;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SELECT variable_value into @b FROM `performance_schema`.session_status WHERE variable_name = 'Innodb_rows_read';
SELECT @b-@a;

多出来的一次是因为这个统计的临时表查询这条数据也被算在里面,忽略不计
方案2
查询耗时的根本原因就是两张表之间来回切换判断.那么能不能判断内容都放在一个表里呢?
我们先来看看sql的判断逻辑
WHERE
t2.userId = 888
ORDER BY
t1.latm DESC
用户需要确定,并且要按照时间排序
t1表是命中记录表,对于用户来说是1对多的关系,不可能在命中表中存储所有推送的用户信息.而
从业务角度分析也可以知道,t2表的插入时间和t1表是同时的,只是t1表会插入多条t2表记录而已.于是把命中时间放在t2b表中.
增加字段
alter table t_notice_send_copy1 add column latm datetime;
因为latm是需要排序的,为了减少回表的麻烦,直接建立复合索引,userid在前latm在后,这样相同的userid下的latm还会有序排列,复合需求
alter table t_notice_send add index idx_userid_latm(userid,latm);
这样在遍历 这个复合索引表的时候,找到复合的数据,直接就可以用过该索引自带的主键id直接返回给t1表,不用再去查询t2表看userid是否符合
优化后的效果
环境: userid = 111和222 的数据各50W,相比两个sql的查询性能差距
set optimizer_trace='enabled=on';
select variable_value into @a from performance_schema.session_status where variable_name = "Innodb_rows_read";
SELECT
count(*)
FROM(
SELECT
t1.*
FROM
t_alarm_notice_all_copy1 t1,
t_notice_send_copy1 t2
WHERE
t1.id = t2.noticeId
AND
t2.userId = 111
ORDER BY
t2.latm DESC
) temp ;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SELECT variable_value into @b FROM `performance_schema`.session_status WHERE variable_name = 'Innodb_rows_read';
SELECT @b-@a;

扫描行数 100w 因为需要查询t2 的 50万条记录,然后在回到 t1表中查询数据50w+50w = 100w.

总耗时4.9秒.因为count(*) 必须全表扫描所以这是最有结果
优化前代码
set optimizer_trace='enabled=on';
select variable_value into @a from performance_schema.session_status where variable_name = "Innodb_rows_read";
SELECT
count(*)
FROM(
SELECT
t1.*
FROM
t_alarm_notice_all_copy1 t1,
t_notice_send_copy1 t2 force index(noticeId)
WHERE
t1.id = t2.noticeId
AND
t2.userId = 111
ORDER BY
t1.latm DESC
) temp ;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SELECT variable_value into @b FROM `performance_schema`.session_status WHERE variable_name = 'Innodb_rows_read';
SELECT @b-@a;

扫描200W行,因为每次t1查询之后都需要去t2确定是不是userid相同.
 耗时7.29秒
耗时7.29秒