JJava自定义线程池详解及代码实现【非直接调用ThreadPoolExecutor】
- JDK中的线程池函数ThreadPoolExecutor
- JDK中的线程池执行任务时的流程
- 自定义线程池业务分析
- 自定义线程池的代码实现-注释详尽
- 1.定义阻塞队列
- 2.定义线程池以及线程对象内部类
- 3.定义拒绝策略,只定义接口,之后策略由调用者传入。
- 自定义线程池代码测试
要实现自定义的线程池,首先得了解线程池的工作流程。
我们可以参考JDK中自定的线程池工作流程去理解,并实现其简化版本。
JDK中的线程池函数ThreadPoolExecutor
JDK中实现线程池的函数如下,其中包含了7个参数。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
这7个参数的含义如下:

corePoolSize表示线程池中的核心线程数,核心线程为常驻线程池中的线程的个数。maximumPoolSize表示最大线程数,其中救急线程个数等于maximumPoolSize - corePoolSize,救急线程为线程池核心线程已满,并且阻塞队列已满时使用的线程,救急线程并不会常驻线程池,其有空闲存活时间,可以通过之后的参数设定。keepAliveTime表示救急线程空闲存活时间,当救急线程没有任务时,等待keepAliveTime之后还没有任务,则消亡。unit 的时间单位。workQueue阻塞队列,当线程池中的核心线程都在工作时,之后来的任务会让在队列中等待执行。threadFactory 创建线程的工厂,一般用来为线程设定可辨识的名字。handler拒绝策略,当线程池无法执行之后来的任务的处理策略。一般包括 1)AbortPolicy 让调用者抛出RejectedExecutionException异常,这是默认策略 2)CallerRunsPolicy 让调用者运行任务 3)DiscardPolicy 放弃本次任务 4)DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之。我们也可以实现自己拒绝策略: 1) 死等 2) 带超时等待 3) 让调用者放弃任务执行 4) 让调用者抛出异常 5) 让调用者自己执行任务等。
JDK中的线程池执行任务时的流程
当我们调用JDK中的线程池执行任务时,其流程一般如下:
- 当我们想向线程池提交任务时,如果线程池的线程数中小于核心线程数时,线程池新建核心线程,任务交给核心线程执行。
- 如果线程池中线程数等于核心线程数,则将后来的任务放入到阻塞队列中,等待核心线程执行完任务之后,从队列中取任务执行。
- 当核心线程都在工作,并且阻塞队列已满时,则创建救急线程,可创建的救急线程数为
maximumPoolSize - corePoolSize,将任务交给救急线程执行。 - 当核心线程已满、阻塞队列已满,救急线程已满时,则执行根据所提供的拒绝策略对后来的任务进行处理。
自定义线程池业务分析
我们可以对上述流程进行分析,简化处理去除掉救急线程,来完成自定义的线程池。
- 定义阻塞队列。通过对线程池的业务分析,我们可以发现,当线程池中的线程都在工作时,后续的任务需要放置到阻塞队列中。之后线程池中的线程都是从阻塞队列中获取任务执行,新来的任务也是被放置到阻塞队列中。此处的工作方式,为生产者消费者模式。因为阻塞队列为多线程中的共享资源,所以需要加锁以确保共享资源的安全性。
- 阻塞队列的实现分析。首先需要定义队列容量,定义双端队列来存储任务,此处任务类型可定义为泛型。之后需要定义两种方法,分别是任务存入队列的方法和从队列中获取任务的方法。在存和取得过程中使用可重入锁进行加锁判断。在取任务的过程中,加锁,如果过队列为空,则阻塞等待,也可以设置为带超时的阻塞等待,后续会附上代码,否则直接从队列中返回任务对象。在存任务的过程中,加锁,如果队列为满,则阻塞等待,也可以设置为带超时的阻塞等待,如果不为空,则存入。具体见之后的代码实现。
- 定义线程池。首先需要设定核心线程数的大小,定义集合对象存储已经创建的线程,方便之后根据集合对象获取已创建的线程的个数。当新来任务时,如果集合的大小小于核心线程数则新建线程,执行任务。否则当核心线程已经全部工作时,需要将新来的任务放入阻塞队列中,等待线程执行完毕从阻塞队列中获取任务,相当于生产者与消费者模式中的消费者。
- 定义线程对象。该线程对象继承自
Thread类,并重写其run()方法。该线程对象即为线程池中的线程。我们在其run()方法中,编写线程执行任务的过程,任务我们定义为Runnable对象,通过调用在线程对象中run()方法中调用Runnable对象的run方法,执行任务,当执行完毕时候,该线程对象继续尝试从阻塞队列中获取任务,可以阻塞获取(即一直等待,有任务就执行,没任务就等待),或者超时等待(当超时之后,直接放弃获取)。 - 定义拒绝策略。拒绝策略通过使用策略模型实现,我们只定义拒绝策略的接口,具体逻辑通过调用者实现。拒绝策略的使用情况。当阻塞队列已满时,如果还有新来的任务,则使用拒绝策略进行处理。当队列未满则直接添加。
以上就是自定义线程池所需要的对象方法,接下来我们使用Java代码一一实现。
自定义线程池的代码实现-注释详尽
我们将任务定义为Runnable对象,线程池中的线程对象为Thread的子类,这样就可以将Runnable对象,传给Thread进行处理。当然其他实现也可以,可以自行尝试。
1.定义阻塞队列
class BlockingQueue<T>{
private Deque<T> queue = new ArrayDeque<>();
private ReentrantLock lock = new ReentrantLock();
private Condition fullWaitSet = lock.newCondition();
private Condition emptyWaitSet = lock.newCondition();
private int capacity;
public BlockingQueue(int capacity) {
this.capacity = capacity;
}
public T pull(long timeout, TimeUnit unit){
lock.lock();
try{
long nanos = unit.toNanos(timeout);
while(queue.isEmpty()){
if(nanos <= 0){
return null;
}
nanos = emptyWaitSet.awaitNanos(nanos);
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public T take(){
lock.lock();
try{
while(queue.isEmpty()){
emptyWaitSet.await();
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public boolean offer(T task, long timeout, TimeUnit timeUnit){
lock.lock();
try{
long nanos = timeUnit.toNanos(timeout);
while(queue.size()==capacity ){
System.out.println(task.toString() + " 等待加入任务队列" );
if(nanos<=0){
return false;
}
nanos = fullWaitSet.awaitNanos(nanos);
}
queue.addLast(task);
System.out.println("任务【" + task.toString() + "】加入队列 " );
emptyWaitSet.signal();
return true;
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public void put(T task){
lock.lock();
try{
while(queue.size()==capacity){
System.out.println(task.toString() + " 等待加入任务队列" );
fullWaitSet.await();
}
queue.addLast(task);
System.out.println("任务【" + task.toString() + "】加入队列 " );
emptyWaitSet.signal();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public int size(){
lock.lock();
try{
return queue.size();
}finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try{
if(queue.size()==capacity){
rejectPolicy.reject(this,task);
}else{
queue.addLast(task);
System.out.println("任务【" + task.toString() + "】加入队列 " );
emptyWaitSet.signal();
}
}finally {
lock.unlock();
}
}
}
2.定义线程池以及线程对象内部类
class ThreadPool{
private BlockingQueue<Runnable> taskQueue;
private HashSet<Worker> workers = new HashSet<>();
private int coreSize;
private long timeout;
private TimeUnit timeUnit;
private RejectPolicy<Runnable> rejectPolicy;
public void execute(Runnable task){
synchronized (workers){
if(workers.size() < coreSize){
Worker worker = new Worker(task);
System.out.println("新增worker " + worker.toString() + " 任务 " + task.toString());
workers.add(worker);
worker.start();
}else{
taskQueue.tryPut(rejectPolicy, task);
}
}
}
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapacity, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapacity);
this.rejectPolicy = rejectPolicy;
}
class Worker extends Thread{
private Runnable task;
private Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
while(task !=null || (task = taskQueue.pull(timeout, timeUnit)) !=null ){
try{
System.out.println("正在执行: " + task.toString());
task.run();
}catch (Exception e){
e.printStackTrace();
}finally {
task = null;
}
}
synchronized (workers){
System.out.println("worker 移除:" + this.toString());
workers.remove(this);
}
}
}
}
3.定义拒绝策略,只定义接口,之后策略由调用者传入。
interface RejectPolicy<T>{
void reject(BlockingQueue<T> queue, T task);
}
自定义线程池代码测试
public class MyThreadPoolTest {
public static void main(String[] args) {
ThreadPool pool = new ThreadPool(1, 1000,
TimeUnit.MICROSECONDS, 1,(queue,task)->{
throw new RuntimeException("任务执行失败,队列已满" + task);
});
for (int i = 0; i < 3; i++) {
int id = i+1;
pool.execute(()->{
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().toString()+ " " + id);
});
}
}
}
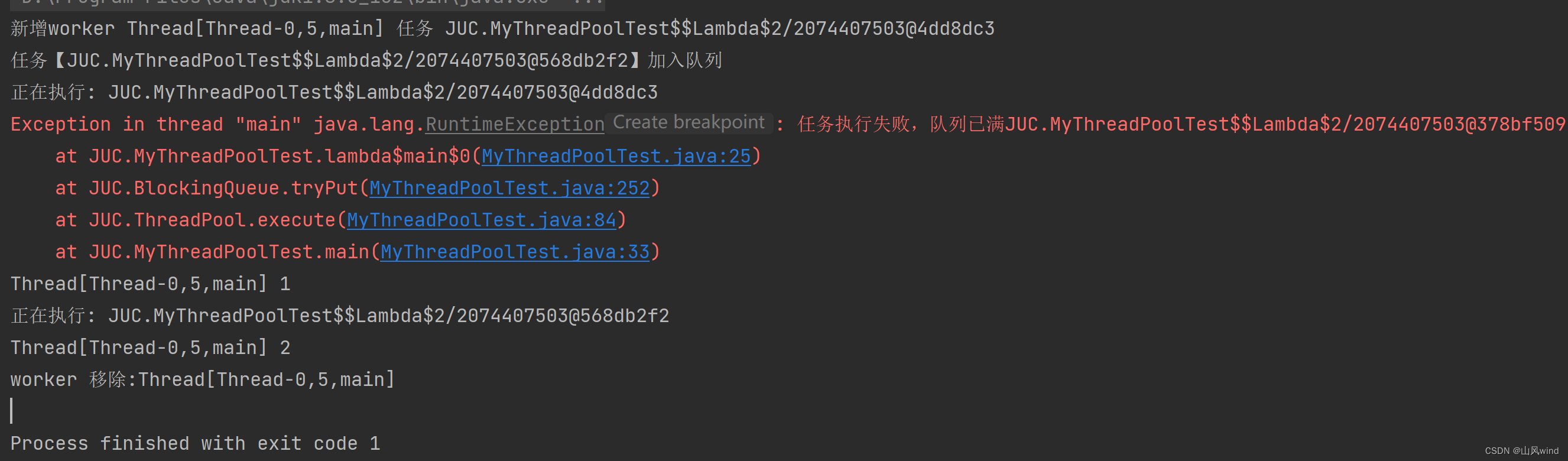
测试结果;
结果分析;
我们创建了线程个数为1的线程池,并且阻塞队列也为1,拒绝策略为直接抛出异常。当有三个任务时,我们可以看到刚开始第一个任务JUC.MyThreadPoolTest$$Lambda$2/2074407503@4dd8dc3到来,线程池创建了线程对象,第二个任务JUC.MyThreadPoolTest$$Lambda$2/2074407503@568db2f2加入的阻塞队列,第一个任务执行。当第三个任务来时,因为线程池中线程正忙,阻塞队列已满,所以根据拒绝策略直接抛出了异常。当两个任务执行完毕之后,线程池中的线程尝试从阻塞队列中继续超时获取,但是超时之后未获取到,所以直接结束,并删除了线程池中的线程,任务结束。
其他的情况,可以自行尝试。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)