一、DBSCAN(Density-Baseed Spatial Clustering of Applications with Noise)聚类算法
- 核心对象:若某个点的密度达到算法设定的阈值则其为核心。(即r邻域内点的数量不小于minPts)
- 邻域的距离阈值:设定的半径r
- 直接密度可达:若某点p在点q的r邻域内,且q是核心点则p-q直接密度可达.
解释如图:
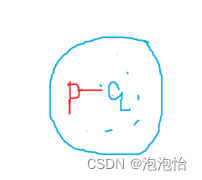
4. 密度可达:若有一点的序列Q0,Q1,…,QK,对任意Qi-Qi-1是直接密度可达的,则称从Q0到Q是密度可达,这实际上是直接密度可达的传播。
解释如图:
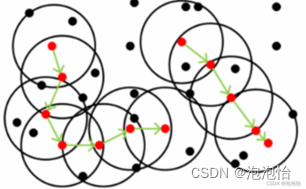
二、Python代码实现
1.产生数据集,代码如下:
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=1000,noise=0.05,random_state=42)
补充说明:X代表二维,y代表labels
2.dbscan代码:
from sklearn.cluster import DBSCAN
dbscan=DBSCAN(eps=0.2,min_samples=5)#eps是半径
dbscan.fit(X)
3.性质:
(1)labels_
dbscan.labels_#出现-1代表离群点
结果如图:

(2)核心对象的索引
dbscan.core_sample_indices_[:10]
结果如图:
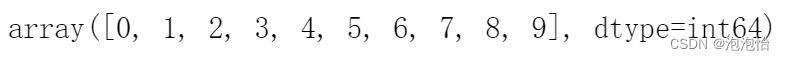
(3) #观察返回几个簇
np.unique(dbscan.labels_)#7个
4.效果展示
plt.figure(figsize=(12,6))
plt.subplot(121)
plt.scatter(X[:,0],X[:,1],c='b')
plt.title("picture_1")
plt.subplot(122)
plt.scatter(X[labels!=-1,0],X[labels!=-1,1],c=labels[labels!=-1]) #显示聚类了的点
plt.scatter(X[labels==-1,0],X[labels==-1,1],marker='+') #奇异点标注为+
plt.title("picture_2")
plt.show()
结果如图: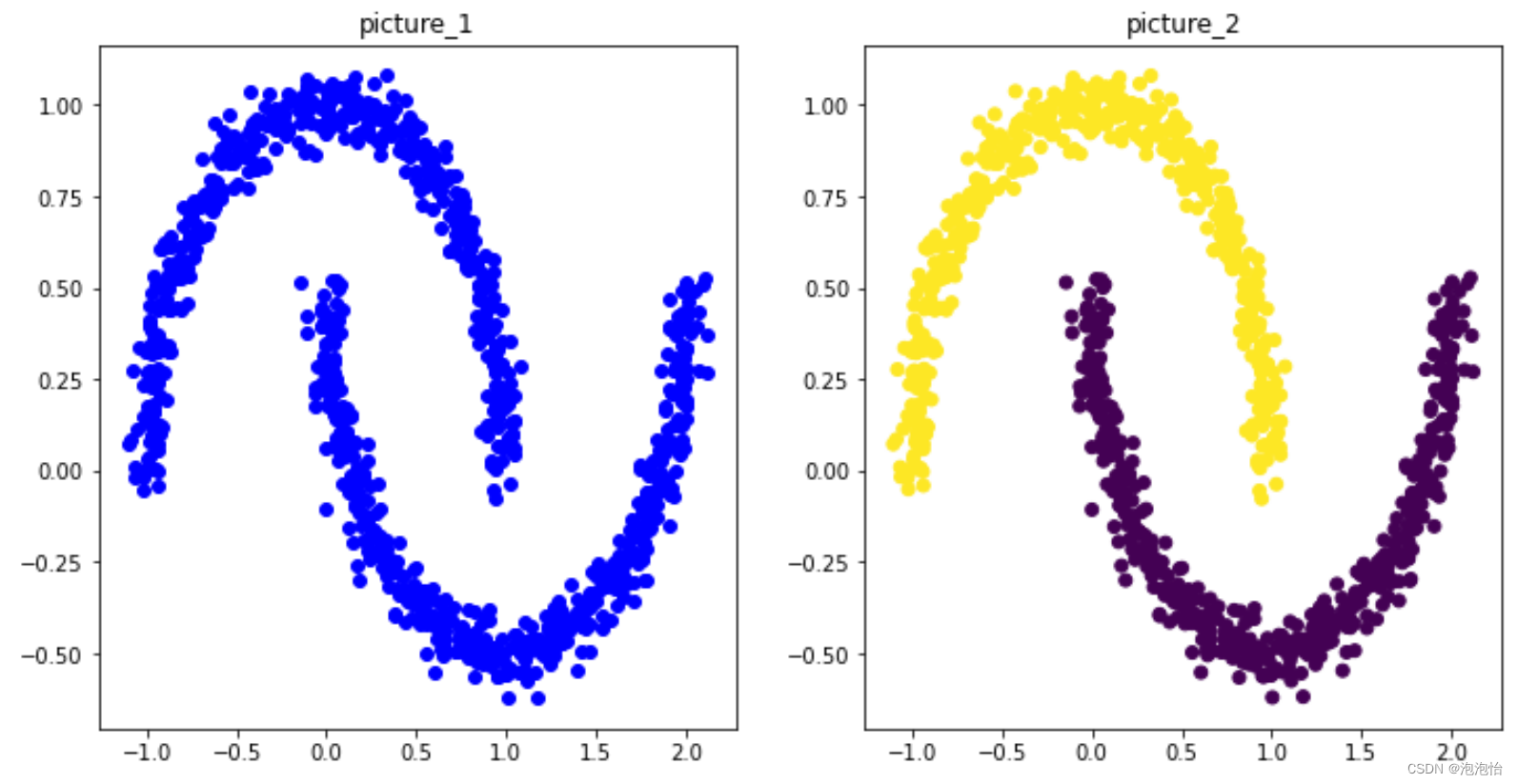
三、优缺点
- 优点:
- (1)与K-means方法相比,DBSCAN不需要事先知道要形成的簇类的数量。
- (2)对噪声敏感。这是因为该算法能够较好地判断离群点。
- (3)能发现任意形状的簇。这是因为DBSCAN 是靠不断连接邻域呢高密度点来发现簇的,只需要定义邻域大小和密度阈值,因此可以发现不同形状,不同大小的簇
- 缺点:
- (1)对两个参数的设置敏感,即圈的半径 eps 、阈值 MinPts。
- (2)DBSCAN 使用固定的参数识别聚类。显然,当聚类的稀疏程度不同,聚类效果也有很大不同。即数据密度不均匀时,很难使用该算法
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)