主题模型(Topic Model)是以非监督学习的方式对文档的隐含语义结构(latent semantic structure)进行聚类(clustering)的统计模型。
主题模型认为在词(word)与文档(document)之间没有直接的联系,它们应当还有一个维度将它们串联起来,主题模型将这个维度称为主题(topic)。每个文档都应该对应着一个或多个的主题,而每个主题都会有对应的词分布,通过主题,就可以得到每个文档的词分布。依据这一原理,就可以得到主题模型的一个核心公式:
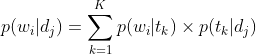
在一个已知的数据集中,每个词和文档对应的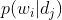 都是已知的。而主题模型就是根据这个已知的信息,通过计算
都是已知的。而主题模型就是根据这个已知的信息,通过计算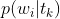 和
和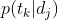 的值,从而得到主题的词分布和文档的主题分布信息。而要得到这个分布信息,现在常用的方法就是LSA(LSI)和LDA。其中LSA主要是采用SVD的方法进行暴力破解,而LDA则是通过贝叶斯学派的方法对分布信息进行拟合。
的值,从而得到主题的词分布和文档的主题分布信息。而要得到这个分布信息,现在常用的方法就是LSA(LSI)和LDA。其中LSA主要是采用SVD的方法进行暴力破解,而LDA则是通过贝叶斯学派的方法对分布信息进行拟合。
隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)是由David Blei等人在2003年提出的,该方法的理论基础是贝叶斯理论。LDA根据词的共现信息的分析,拟合出词-文档-主题的分布,进而将词、文本都映射到一个语义空间中。
LDA算法假设文档中主题的先验分布和主题中词的先验分布都服从狄利克雷分布。在贝叶斯学派看来,先验分布+数据(似然)=后验分布。我们通过对已有数据集的统计,就可以得到每篇文档中主题的多项式分布和每个主题对应词的多项式分布。然后就可以根据贝叶斯学派的方法,通过先验的狄利克雷分布和观测数据得到的多项式分布,得到一组Dirichlet-multi共轭,并据此来推断文档中主题的后验分布,也就是我们最后需要的结果。那么具体的LDA模型应当如何进行求解,其中一种主流的方法就是吉布斯采样。结合吉布斯采样的LDA模型训练过程一般如下:
- 随机初始化,对语料中每篇文档中的每个词w,随机地赋予一个topic编号z。
- 重新扫描语料库,对每个词w按照吉布斯采样公式重新采样它的topic,在语料中进行更新。
- 重复以上语料库的重新采样过程直到吉布斯采样收敛。
- 统计语料库的topic-word共现频率矩阵,该矩阵就是LDA的模型。
经过以上的步骤,就得到一个训练好的LDA模型,接下来就可以按照一定的方式针对新文档的topic进行预估,具体步骤如下:
- 随机初始化,对当前文档中的每个词w,随机地赋予一个topic编号z。
- 重新扫描当前文档,按照吉布斯采样公式,重新采样它的topic。
- 重复以上过程直到吉布斯采样收敛。
- 统计文档中的topic分布即为预估结果。
具体的LDA理论可以参考rickjin写的LDA数学八卦:http://www.52nlp.cn/lda-math-%E6%B1%87%E6%80%BB-lda%E6%95%B0%E5%AD%A6%E5%85%AB%E5%8D%A6
通过上面的LSI或LDA算法,我们得到了文档对主题的分布和主题对词的分布,接下来就是要利用这些信息来对关键词进行抽取。在我们得到主题对词的分布后,也据此得到词对主题的分布。接下来,就可以通过这个分布信息计算文档与词的相似性,继而得到文档最相似的词列表,最后就可以得到文档的关键词。
在TF-IDF实现文本关键词提取的基础上,实现一个完整的主题模型,分别实现LSI、LDA算法,根据传入参数model进行选择。几个参数如下:
- doc_list:是前面数据集加载方法的返回结果。
- keyword_num:同上,为关键词数量。
- model:本主题模型的具体算法,分别可以传入LSI、LDA,默认为LSI。
- num_topics为主题模型的主题数量。
LSI和LDA的训练是根据现有的数据集生成文档-主题分布矩阵和主题-词分布矩阵,Gensim中有实现好的训练方法,直接调用即可。
from gensim import corpora, models
# 主题模型
class TopicModel(object):
# 三个传入参数:处理后的数据集,关键词数量,具体模型(LSI、LDA),主题数量
def __init__(self, doc_list, keyword_num, model='LSI', num_topics=4):
# 使用gensim的接口,将文本转为向量化表示
# 先构建词空间
self.dictionary = corpora.Dictionary(doc_list)
# 使用BOW模型向量化
corpus = [self.dictionary.doc2bow(doc) for doc in doc_list]
# 对每个词,根据tf-idf进行加权,得到加权后的向量表示
self.tfidf_model = models.TfidfModel(corpus)
self.corpus_tfidf = self.tfidf_model[corpus]
self.keyword_num = keyword_num
self.num_topics = num_topics
# 选择加载的模型
if model == 'LSI':
self.model = self.train_lsi()
else:
self.model = self.train_lda()
# 得到数据集的主题-词分布
word_dic = self.word_dictionary(doc_list)
self.wordtopic_dic = self.get_wordtopic(word_dic)
def train_lsi(self):
lsi = models.LsiModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)
return lsi
def train_lda(self):
lda = models.LdaModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)
return lda
def get_wordtopic(self, word_dic):
wordtopic_dic = {}
for word in word_dic:
single_list = [word]
wordcorpus = self.tfidf_model[self.dictionary.doc2bow(single_list)]
wordtopic = self.model[wordcorpus]
wordtopic_dic[word] = wordtopic
return wordtopic_dic
# 计算词的分布和文档的分布的相似度,取相似度最高的keyword_num个词作为关键词
def get_simword(self, word_list):
sentcorpus = self.tfidf_model[self.dictionary.doc2bow(word_list)]
senttopic = self.model[sentcorpus]
# 余弦相似度计算
def calsim(l1, l2):
a, b, c = 0.0, 0.0, 0.0
for t1, t2 in zip(l1, l2):
x1 = t1[1]
x2 = t2[1]
a += x1 * x1
b += x1 * x1
c += x2 * x2
sim = a / math.sqrt(b * c) if not (b * c) == 0.0 else 0.0
return sim
# 计算输入文本和每个词的主题分布相似度
sim_dic = {}
for k, v in self.wordtopic_dic.items():
if k not in word_list:
continue
sim = calsim(v, senttopic)
sim_dic[k] = sim
for k, v in sorted(sim_dic.items(), key=functools.cmp_to_key(cmp), reverse=True)[:self.keyword_num]:
print(k + "/ ", end='')
print()
@staticmethod
# 词空间构建方法和向量化方法,在没有gensim接口时的一般处理方法
def word_dictionary(doc_list):
dictionary = []
for doc in doc_list:
dictionary.extend(doc)
dictionary = list(set(dictionary))
return dictionary
def doc2bowvec(self, word_list):
vec_list = [1 if word in word_list else 0 for word in self.dictionary]
return vec_list
统一算法调用接口:
def topic_extract(word_list, model, pos=False, keyword_num=10):
doc_list = load_data(pos)
topic_model = TopicModel(doc_list, keyword_num, model=model)
topic_model.get_simword(word_list)
对目标文本进行关键词提取:
if __name__ == '__main__':
text = '费尔南多·托雷斯(Fernando Jose Torres Sanz),1984年3月20日出生于西班牙马德里,' + \
'西班牙足球运动员,司职前锋,效力于日本职业足球甲级联赛鸟栖砂岩足球俱乐部。' + \
'托雷斯2001出道于马德里竞技,2007年加盟英超利物浦,2011年转会切尔西,' + \
'期间帮助球队夺得了2012年欧洲冠军联赛冠军,其后以租借的形式加盟AC米兰,' + \
'2014年12月,托雷斯宣布回归马德里竞技。2018年7月,托雷斯宣布加盟日本鸟栖砂岩足球俱乐部。' + \
'2004年欧洲杯,托雷斯首次代表国家队参加国际大赛,2008年和2012年跟随西班牙队两度夺得欧洲杯冠军,' + \
'2010年随队夺得世界杯冠军,其个人在2008年荣膺欧洲杯决赛MVP,2012获得欧洲杯金靴奖、2013年获得联合会杯金靴奖。'
pos = True
seg_list = seg_to_list(text, pos)
filter_list = word_filter(seg_list, pos)
print('LSI模型结果:')
topic_extract(filter_list, 'LSI', pos)
print('LDA模型结果:')
topic_extract(filter_list, 'LDA', pos)
执行结果如下:
LSI模型结果:
大赛/ 代表/ 个人/ 形式/ 职业/ 国际/ 日本/ 加盟/ 运动员/ 冠军/
LDA模型结果:
大赛/ 职业/ 运动员/ 冠军/ 日本/ 形式/ 个人/ 代表/ 国际/ 国家队/
参考:https://book.douban.com/subject/30247776/