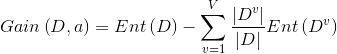接下来是三种经典的决策树算法的学习过程:
Step1:信息熵与信息增益 信息熵(information_entropy):是度量样本集合纯度最常用的一种指标,假定当前样本集合D中第k类样本所占的比例为pk(k=1,2,…,|y|),则D的信息熵定义为: Ent(D)的值越小,则D的纯度越高。 假定离散属性a有V个可能的取值{ },若使用a来对样本集D进行划分,会产生V个分支结点,其中第v个分支节点包含了D中所有在属性a上取值为的样本,记为。通过信息熵公式可以计算出的信息熵,再考虑到不同的分支节点所包含的样本数不同,给分支节点赋予权重||/|D|,即样本数越多的分支节点的影响越大。于是,计算出用属性a样本集D进行划分所获得的“信息增益”(information_gain): 一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可以用信息增益来进行决策树的划分属性选择。ID3决策树学习算法就是以信息增益为准则来选择划分属性。
Step2:ID3算法的弊端以及改进 由信息熵以及信息增益的计算公式,不难知道,信息增益准则对可取值数目较多的属性有所偏好。当每个分支结点包含非常少甚至只有一个样本,这些分支节点的纯度达到最大。然而,这样的决策树不具有泛化能力,无法对新样本进行有效预测。比如,数据的“编号”的信息增益是最大的,但没实际意义。于是,著名的C4.5决策树算法出现了。
Step3:C4.5算法以及信息增益率 信息增益率的公式:
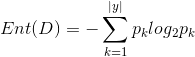
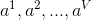 },若使用a来对样本集D进行划分,会产生V个分支结点,其中第v个分支节点包含了D中所有在属性a上取值为
},若使用a来对样本集D进行划分,会产生V个分支结点,其中第v个分支节点包含了D中所有在属性a上取值为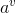 的样本,记为
的样本,记为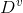 。通过信息熵公式可以计算出
。通过信息熵公式可以计算出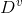 的信息熵,再考虑到不同的分支节点所包含的样本数不同,给分支节点赋予权重|
的信息熵,再考虑到不同的分支节点所包含的样本数不同,给分支节点赋予权重|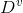 |/|D|,即样本数越多的分支节点的影响越大。于是,计算出用属性a样本集D进行划分所获得的“信息增益”(information_gain):
|/|D|,即样本数越多的分支节点的影响越大。于是,计算出用属性a样本集D进行划分所获得的“信息增益”(information_gain):