公式
L1
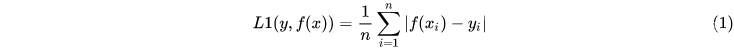
L2
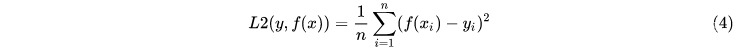
L1
令 x = fx - y
有Lx = |x|
求导数:
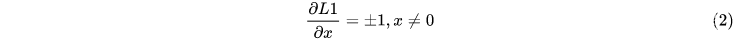
我们知道梯度更新方法为:

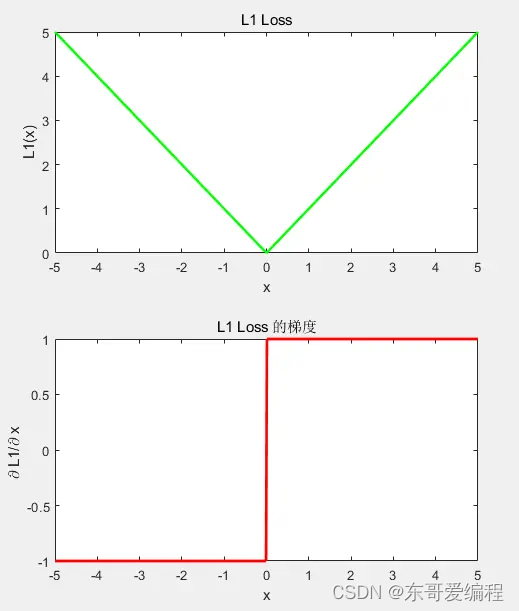
这样会有一个问题就是 为0 的时候不可导,另外当梯度很小时,很难收敛到极小值
优点: 前期收敛快,梯度不变,不容易收脏数据的影响,
缺点: 后期无法收敛,只能调学习率的方式,更新太快可能无法取到极小值
L2
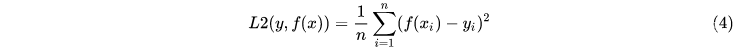
令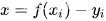 ,忽略求和及系数,则有L1(x)=x^2,其导数为
,忽略求和及系数,则有L1(x)=x^2,其导数为
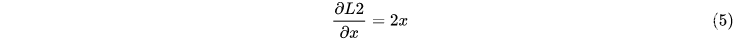
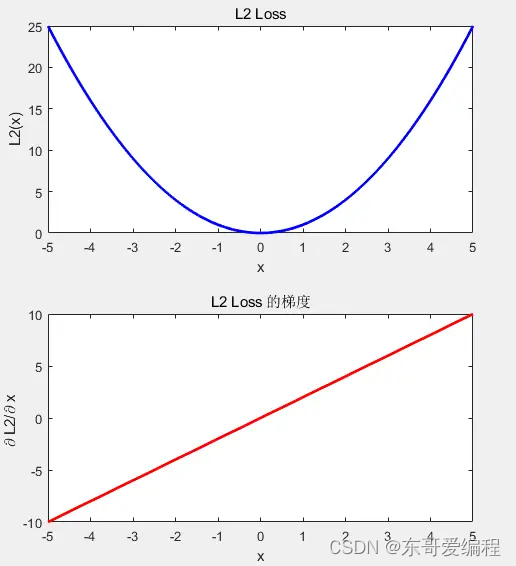
所以, l2 中, 预测和真实值的差值越大, 损失越大。
优点: 差值越大, 导数越大,反之, 容易收敛到极小值
缺点: 容易受到离群点,脏数据的影响,一开始梯度太大,容易出现训练不稳定, 梯度爆炸
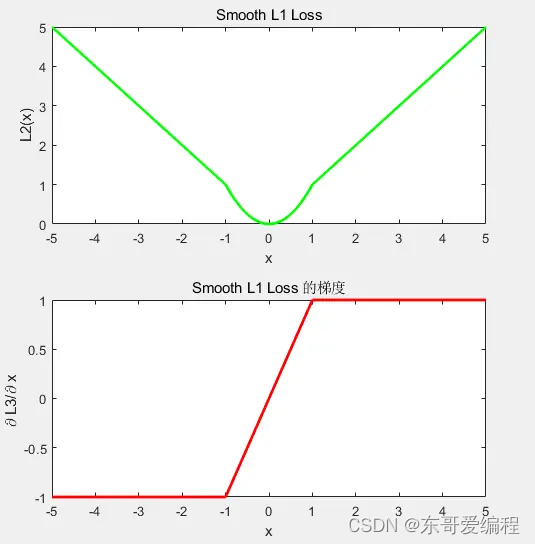
Smooth l1
这是一个分段函数
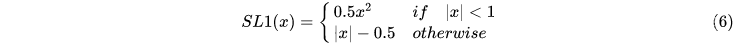
是l2 和l1 的结合体, 在梯度较小时,采用l2 较为平滑的方式, 较大时采用稳定的梯度下降。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)