完全理解二叉树(上)——二叉树的概念、遍历、构造以及线索化
完全理解二叉树(中)——二叉树与树、森林的转化及遍历
1. 平衡二叉树
二叉树可以用于查找元素,对于如下这颗二叉树:
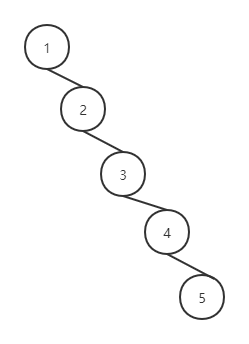
对其的遍历相当于对链表的遍历,因此找到元素5需要从头开始,查找5次,但是如果树的形状是这样:

从根结点出发只需要查找3次即可找到元素5。
1.1 定义
左右子树高度差不超过1的二叉树称为平衡二叉树(AVL树),注意是对于树中的任意结点。
例如:


都不是平衡二叉树。
结点的平衡因子 = 左子树高 - 右子树高,平衡因子的绝对值不超过1,如下图所示:

1.2 存储结构
typedef struct AVLTreeNode* avltree;
struct AVLTreeNode{
int data;
int balance;
avltree lnode,rnode;
};
1.3 左旋与右旋操作
在结点的插入过程中,无论插入的位置在哪,新结点的加入必定会影响平衡因子,可能查找路径上的所有平衡因子都会被影响,因此需要找到一种方法,在整体平衡因子改动最小的基础上,依然满足AVL树的定义。
最小失衡子树:在插入一个结点后,那么这个结点向上查找,第一个出现左右不平衡的树就是最小失衡子树,即找到平衡因子的绝对值先超过 1 的结点。
- 左旋
对于这样一颗树

插入结点 6 后,变成

显然,第一个被破坏的平衡因子就是结点 2,则需要对结点 2 进行左旋转。步骤为:
- 该结点的右孩子代替该结点的位置(结点3代替结点2成为根结点)
- 右孩子的左孩子变成该结点的右孩子(结点4变成结点2的右孩子)
- 该节点变成右孩子结点的左孩子(结点2变成结点3的左孩子)
得到的新平衡二叉树为

- 右旋
对于这样一颗树
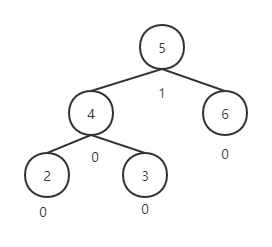
插入结点 1 后,变成

跟左旋操作类似。第一个被破坏平衡的是结点5,步骤为:
- 该结点的左孩子代替该结点的位置(结点4代替结点5成为根结点)
- 左孩子的右孩子变成该结点的左孩子(结点3变成结点5的左孩子)
- 该结点变成左孩子结点的右孩子(结点5变成结点4的右孩子)
得到的新平衡二叉树为

| 插入方式 |
结点的左孩子的左子树插入结点 |
结点的右孩子的右子树插入结点 |
结点的左孩子的右子树插入结点 |
结点的右孩子的左子树插入结点 |
| 操作 |
右旋 |
左旋 |
先左旋后右旋 |
先右旋后左旋 |
1.4 平衡调整策略
- 结点的左孩子的右子树插入结点
对于这样一颗平衡二叉树
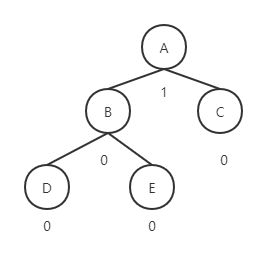
E的左子树插入结点F:
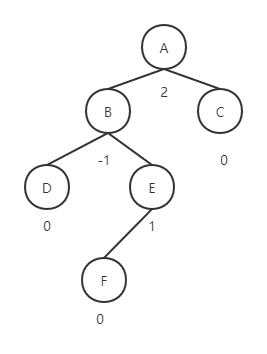
对A的左孩子进行左旋操作:

然后再对A进行右旋操作:

这样就使得二叉树再次平衡。
- 结点的右孩子的左子树插入结点
对于这样一颗平衡二叉树:

给D结点插入F:

对A的右孩子进行右旋:

再对A进行左旋:

就得到了新的平衡二叉树。
2. 二叉排序树
2.1 定义
满足:
(1) 若左子树不空,则 左子树 上所有结点的值 均小于 它的根结点的值;
(2) 若右子树不空,则 右子树 上所有结点的值 均大于 它的根结点的值;
(3) 左、右子树又分别为二叉排序树 。
的二叉树就是二叉排序树。
2.2 存储结构
二叉排序树的存储结构和普通二叉树一样:
typedef struct BsTreeNode* bstree;
struct BsTreeNode{
ElementType value;
bstree lnode;
bstree rnode;
};
2.3 二叉排序树的建立
现有如下一组数:
18 37 55 2 61 4 99 13 25 73 48
先将 18 作为根结点,接下来判断 37,37>18,则放入18的右子树,继续判断55,55>18且右子树已经有37,继续判断 55 和 37,55>37,则放入37的右子树,判断 2,2<18,放入左子树。以此类推,即保证一个数在插入过程中始终满足二叉排序树的定义,最后建立的树如下:

这颗二叉树的中序遍历结果为:2 4 13 18 25 37 48 55 61 73 99,刚好就是排序后的数列。
2.4 查找、插入、删除操作
二叉排序树的查找不需要进行中序遍历,根据树的结构,直接从根结点进入,然后比较结点的值,以此决定进入左子树还是右子树,代码如下:
bstree BsSearch(bstree root, int key)
{
if (root == NULL || root->data == key)
return root;
if (root->key < key)
return BsSearch(root->rnode, key);
return BsSearch(root->lnode, key);
}
插入算法也不难理解,同样使用递归解决:
bstree BsInsert(bstree node, int key)
{
if (node == NULL)
return NewCreate(key);
if (key < node->data)
node->lnode = BsInsert(node->lnode, key);
else if (key > node->data)
node->rnode = BsInsert(node->rnode, key);
return node;
}
删除操作稍微复杂一点,分为以下情况:
- 被删除的结点是叶子结点:不会影响树的结构,直接删除。
- 被删除的结点仅有一个孩子:无论是左孩子还是右孩子,都只需要把孩子结点连接到要删除结点的父结点上即可。
- 被删除的结点左右孩子都存在:假设要删除的是根结点,根据中序遍历顺序的不变性,以及二叉排序树的结构,可以得出左子树的最右下结点就是直接前驱,根据递归,可以推出任何结点的左子树的最右下结点都是这个结点的直接前驱,故只要找到直接前驱,替换它和待删除结点的值,然后删除该前驱结点,并把它的剩余部分连接回它的父结点,就可以完成删除。当然也可以找到后继结点,这里不作赘述。
bstree BsDelete(bstree root, int key)
{
// 如为空,直接返回
if (root == NULL)
return root;
// 如果删除的值小于 root 的值,则递归遍历左子树
if (key < root->data)
root->lnode = BsDelete(root->lnode, key);
// 如果删除的值大于 root 的值,则递归的遍历右子树
else if (key > root->data)
root->rnode = BsDelete(root->rnode, key);
// 如果值相等,则删除结点
else
{
if (root->lnode == NULL) //删除结点没有左孩子,拼接右孩子
{
bstree temp = root;
root = root->rnode;
free(temp);
}
else if (root->rnode == NULL) //删除结点没有右孩子,拼接左孩子
{
bstree temp = root;
root = root->lnode;
free(temp);
}
// 左右孩子均不为空,获取删除结点中序遍历的直接前驱结点
bstree q = root;
bstree s = root->lnode;
while(s->rnode) // 转左,然后向右走到尽头,找到最右下结点
{
q = s;
s = s->rnode;
}
root->data = s->data;
if( q != root ) // 判断是否执行上述while循环
q->rnode = s->lnode; // 说明到了最右下结点,s可能有左子树,因此s的父结点重接右子树
else
q->lnode = s->lnode; // 说明s没有右子树,但可能有左子树,因此root重接左子树
free(s);
}
return root;
}
3. 哈夫曼树
3.1 背景
考虑这个问题,把某个班同学百分制的成绩转换成5分制,规则如下,
90~100 5
80~90 4
70~80 3
60~70 2
<60 1
用条件语句实现:
if (score < 60)
grade = 1;
else if(score < 70)
grade = 2;
else if(score < 80)
grade = 3;
else if(score < 90)
grade = 4;
else
grade = 5;
但是如果这个班的同学大多数都取得了90分以上的好成绩,那么前面4步的判断在面对大量数据的时候是比较浪费时间的。现在做如下优化,假定我们目前已经知道了这个班成绩的分布律
成绩:
<60
60~70
70~80
80~90
90~100
比例:
0.05
0.15
0.33
0.27
0.20
用比例乘上判断的次数,算法的效率是(最后一档不用比较,因此也是4次):0.05 * 1 + 0.15 * 2 + 0.33 * 3 + 0.27 * 4 + 0.20 * 4 = 3.22
稍微修改一下算法,先判断比例最大的:
if(score < 80)
{
if(score < 70)
{
if(score < 60)
grade = 1;
else
grade = 2;
}
else
grade = 3;
}
else if(score < 90)
grade = 4;
else
grade = 5;
改良后的算法效率:0.05 * 3 + 0.15 * 3 + 0.33 * 2 +0.27 * 2 + 0.2 * 2 = 2.2
很明显,改良后的算法效率增加了很多。
这样的条件语句可以画出如下的树:

哈夫曼树就是为了优化这类数据查找效率的算法。
3.2 定义
给定n权值作为n个叶子节点,构造一棵二叉树,若这棵二叉树的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称为Huffman树。
3.3 构建
对于 3.1 节给出的数据,定义权值为不同分值出现的频率,则对于 1~5 的5分制,这里用 ABCDE 代表结点的值,用 1~5 代表结点的权,权值 1 2 3 4 5 对应了 3.1 中的频率:0.05、0.15、0.20、0.27、0.33,对应的结点为 ABEDC,其构建过程为:
- 选择最小的两个,即 1 和 2,合并,权值之和为 3
- 从刚才合并好的 3 和剩下的 3,4,5 里选择两个最小的,即 3 和 3,合并,权值之和为 6
- 从 6,4,5 里选择两个最小的,即 4 和 5,合并,6 在往上一层,因此选择了 4 和 5 并不会和 6 处在一层,而是和 3 在同一层,权值之和为 9
- 将 6 和 9 合并,权值之和为 15
构建的树如下:

其实以上过程就是在不断重复找出字符中权值最小的两个,小的在左边,大的在右边,组成二叉树。在频率表中删除此次找到的两个数,并加入此次最小两个数的频率和 这个过程。
3.4 性质
由上面构建出的哈夫曼树,可以得到带权路径长度为:(1+2) * 3 + (3+4+5) * 2 = 9+24 = 33,实际上,一种带权路径长度最短的二叉树,也称为最优二叉树。
给树的路径上,向左标 0,向右标 1,则会得到:

对于每个结点,都能得到唯一的哈夫曼编码:
A:000
B:001
C:11
D:10
E:01
可见,编码越短,离根结点越近,出现的频率越高。
哈夫曼树(最优二叉树)在构造的时候保证长编码的不与短编码的字母冲突,因为哈夫曼树的它的字母都在叶子节点上,因此不会出现一个字母的编码为另一个字母编码左起子串的情况。意思就是说读到当前位置已经能确定是什么字母时不能因为再读取一位或几位让这个编码能表示另外的字母。