
硬盘属于外存储器(19年第3题)
机械硬盘的性能指标:(18年第4题)
磁盘转速、平均寻道时间、容量
计算机操作的最小时间单位:时钟周期
1. CPU的功能
2. CPU的组成
1) 运算器
\qquad
功能:
\qquad
(1) 执行所有的算术运算。
\qquad
如加、减、乘、除等基本运算及附加运算。
\qquad
(2) 执行所有的逻辑运算并进行逻辑测试。
\qquad
如与、非、或、零值测试或两个值得比较等。
\qquad
组成:(20年第1题)
\qquad
(1) 算术逻辑单元 (Arithmetic and Logic Unit,ALU)
\qquad
处理数据,实现对数据的算术运算和逻辑运算
\qquad
(2) 累加寄存器 (Accumulator Register,AC)(14年第1题/17年第1题)
\qquad
为算术逻辑单元提供一个工作区,暂存源操作数和计算结果
\qquad
(3) 数据缓冲寄存器 (Data buffer Register,DR)
\qquad
暂存由内存储器读写的一条指令或一个数据字,将不同时间段内读写的数据隔离开来
\qquad
作用:作为CPU和内存、外设之间在操作速度上的缓冲,以及数据传送的中转站
\qquad
(4) 状态条件寄存器 (Program Status Word,PSW)
\qquad
保存根据算术指令和逻辑指令运行或测试的结构建立的各种条件码内容,主要分为状态标志和控制标志。
\qquad
如运算结果进位标志( C )、运算结果溢出标志(V)、运算结果为0标志(Z)、运算结果为负标志(N)、中断标志(I)、方向标志(D)等。
2)控制器
\qquad
功能:
\qquad
决定了计算机过程的自动化。它不仅要保证程序的正确执行,而且要能够处理异常事件。
\qquad
部件:
\qquad
(1) 指令寄存器 (Instruction Register,IR)(10年第5题)
\qquad
暂存从内存读取的指令(操作码+地址码)
\qquad
(2) 程序计数器 (Program Counter,PC) (10年第1题/11年第1题/19年第1题/21年第1题)
\qquad
存放将要执行的下一条指令在内存中的地址
\qquad
程序计数器的内容即是从内存提取的第一条指令的地址。当执行指令时,CPU 将自动修改PC 的内容,即每执行一条指令PC 增加一个量,这个量等于指令所含的字节数,以便使其保持的总是将要执行的下一条指令的地址。由于大多数质量都是按顺序来执行的,所以修改的过程通常只是简单的对PC 加1
\qquad
(3) 地址寄存器 (Address Register,AR)
\qquad
保存当前CPU 所访问的内存单元的地址
\qquad
(4) 指令译码器 (Instruction decoder,ID)
\qquad
对指令中的操作码字段进行分析解释,识别该指令规定的操作,然后向操作控制器发出具体的控制信号
指令:是对机器进行程序控制的最小单位。
一条指令通常包括两个部份:操作码和操作数

操作码指出是什么操作,由指令译码器(ID)来识别。
操作数直接指出操作数本身或者指出操作数所在的地址。
3)寄存器组
(1)专用寄存器
运算器和控制器中的寄存器是专用寄存器,其作用是固定的。
(2)通用寄存器
用途广泛并可由程序员规定其用途,其数目因处理器不同而不同。
3. 多核CPU
补充:
CPU 与其他部件交换数据时,用数据总线传输数据。数据总线宽度指同时传送的二进制位数,内存容量、指令系统中的指令数量和寄存器的位数与数据总线的宽度无关。数据总线宽度越大,单位时间内能进出CPU的数据就越多,系统的运算速度越快。
串行总线将数据一位一位传输,数据线只需要一根(如果支持双向需要2根),并行总线是将数据的多位同时传输(4位,8位,甚至64位,128位),显然,并行总线的传输速度快,在长距离情况下成本高,串行传输的速度慢,但是远距离传输比串行成本低。
单总线结构在一个总线上适应不同种类的设备,通用性强,但是无法达到高的性能要求,而专用总线则可以与连接设备实现最佳匹配。(16年第6题)
在计算机系统中采用总线结构,便于实现系统的积木化构造,便于增减外设,同时可以有效减少信息传输线的数量。
单总线结构
在单总线结构中,CPU与主存之间、CPU与 I/O 设备之间、I/O 设备与主存之间、各种设备之间都通过系统总线交换信息。
优点:控制简单方便、扩充方便。
缺点:由于所有设备部件均挂在单一总线上,使这种结构只能分时工作,即同一时刻只能在两个设备之间传送数据,这就使系统总体数据传输的效率和速度受到限制
2. 常见总线
补充知识点:时钟周期、机器周期、指令周期、总线周期、存储周期的区别
(1)时钟周期:计算机中最小的时间单位,等于CPU 主频的倒数。一个时钟周期内,CPU 仅完成一个最基本的动作。
(2)机器周期(CPU 周期):计算机中为了方便管理,常把一条指令 的执行过程划分为若干个阶段(如取指、间址、执行、中断等)
每一阶段完成一个基本操作。注意:每一个基本操作都是由若干CPU最基本的动作组成。这个基本操作所需要的时间称为机器周期,则机器周期由若干个时钟周期组成。
(3)指令周期:从取指开始到执行完成该指令所需要的全部时间。指令周期包含若干机器周期。
(4)总线周期:存储器和I/O端口是挂接在总线上的,CPU对存储器和I/O接口的访问通过总线实现。把CPU通过总线对微处理器外部(存储器或I/O接口)进行一次访问所需时间称为一个总线周期。
(5)存储周期:存储周期包含存取时间和恢复时间。指两次独立访问存储器操作之间的最小间隔。
存取时间指从启动一次存储器操作到完成该操作所经历的时间。恢复时间指读写操作之后,用来恢复内部状态的时间。
总结:
指令周期>机器周期>时钟周期
存储周期>总线周期
(21年上第2题)
(1) CISC (Complex Instrunction Set Computer,复杂指令集计算机)
进一步增强原有指令的功能,用更为复杂的新指令取代由原先子程序完成的功能,实现软件功能的硬化,导致机器的指令系统越来越庞大而复杂。普遍使用微程序控制器。
(微处理器x86 属于CISC)
(2) RISC (Reduced Instrunction Set Computer,精简指令集计算机)
通过减少指令总数和简化指令功能,降低硬件设计的复杂度,使指令能单周执行,并通过优化编译,提高指令的执行速度,通用寄存器数量相当多,采用硬线控制逻辑,不用或少用微码控制,优化编译程序,导致机器的指令系统进一步精炼而简单。采用流水线技术。
(ARM 处理器属于RISC)
关键技术:
① 重叠寄存器窗口技术
② 优化编译技术
③ 将流水及超标量技术
④ 硬布线逻辑与微程序相结合在微程序技术中
RISC采用的流水技术:
① 超流水线(Super Pipeline)
② 超标量(Super Scalar)
③ 超长指令字(Very Long Instruction Word,VLIW)(16年第1题)
一种非常长的指令组合,它把许多条指令连在一起,增加了运算的速度。
(1)指令控制方式
① 顺序方式
优点:控制简单
缺点:速度慢,各部件利用率低
② 重叠方式
优点:速度有所提高,控制也不太复杂
缺点:会出现冲突、转移和相关等问题
③ 流水方式
一次重叠只是把一条指令解释分解为两个子过程,而流水则是分解为更多的子过程
(2)流水线的种类
① 级别角度:部件级、处理机级以及系统级的流水线
② 功能角度:单功能和多功能流水线
③ 联接方式:静态流水线和动态流水线
(3)流水的相关处理
(4)吞吐率和流水建立时间 (09年第6题/12年第5-6题/14年第5题)
流水线周期
各子任务中执行时间最长的(最慢的)子任务的执行时间。
流水线执行完 n 条指令所需要的时间
Tn = 执行一条指令所需时间 + (n-1) * 流水线周期
吞吐率(18年第3题)
是指单位时间里流水线处理机流出的结果数。对指令而言,就是单位时间里执行的指令数。如果各段流水的操作时间不同,则流水线的吞吐率是最长流水段操作时间。
吞吐率:p=1/max(∆t1,∆t2,…∆tm),即最长子过程所用时间的倒数。
| 例题1:一条指令的执行过程可以分解为取指、分析和执行三步,在取指时间 t 取指=3△t,分析时间 t 分析=2△t,执行时间 t 执行=4△t 的情况下,若按串行方式执行,则10条指令全部执行完需要( )△t。若按照流水方式执行,则执行完10条指令需要( )△t。 串行:(3+2+4)* 10 = 90 流水:(3+2+4)+(10-1)*4= 45 |
| 例题2:某指令流水线由5段组成,第1、3、5段所需时间为△t, 第2、4段所需时间分别为3△t、2△t,那么连续输入n条指令时的吞吐率(单位时间内执行的指令个数)TP为()。 解: ① 流水线周期 = 3 ② 流水线执行完 n 条指令所需要的时间 = (3+3+2)+(n-1)*3 ③ 吞吐率 = n/((3+3+2)+(n-1)*3) |
补充知识点:
异步流动是指任务从流水线流出的次序同流入流水线的次序不一样,也称为乱序流动或错序流动。性能会下降。
流水线的
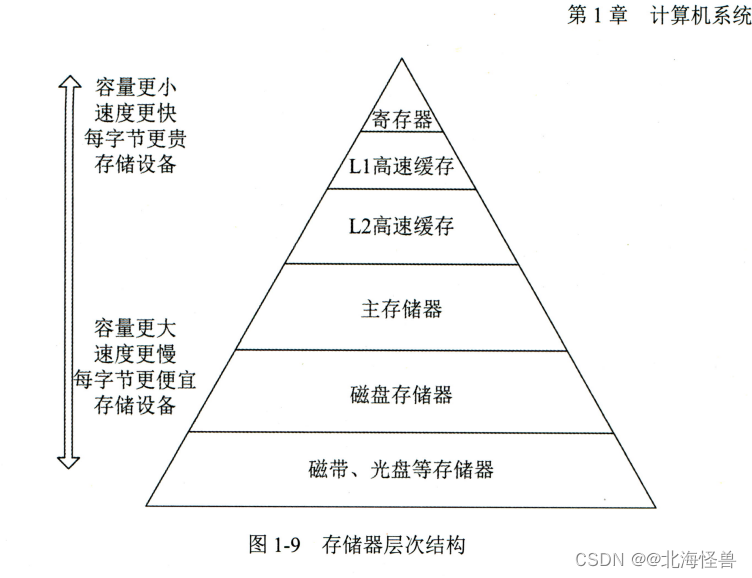
计算机系统中的CPU内部对通用寄存器的存取操作是最快的,其次是Cache,内存的存取速度再次。 (15年第2题)
(17年第6题)
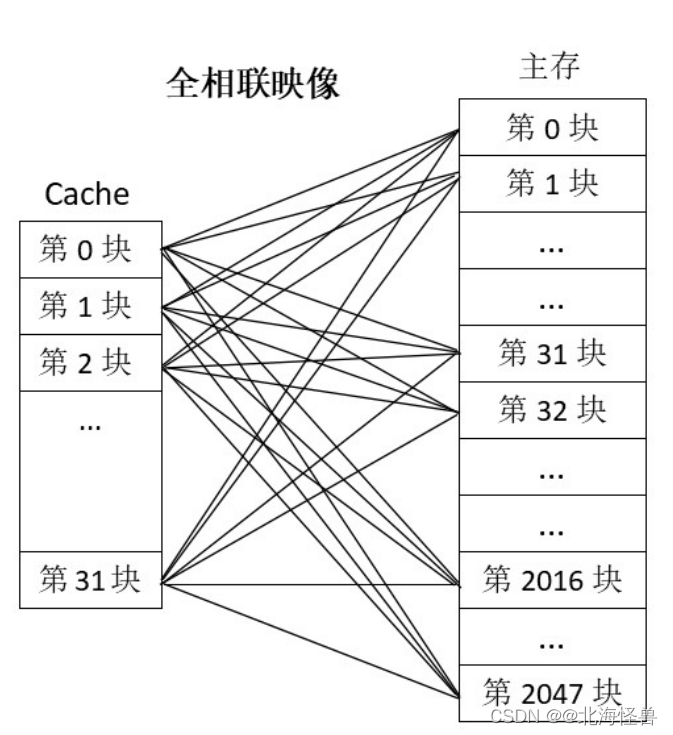
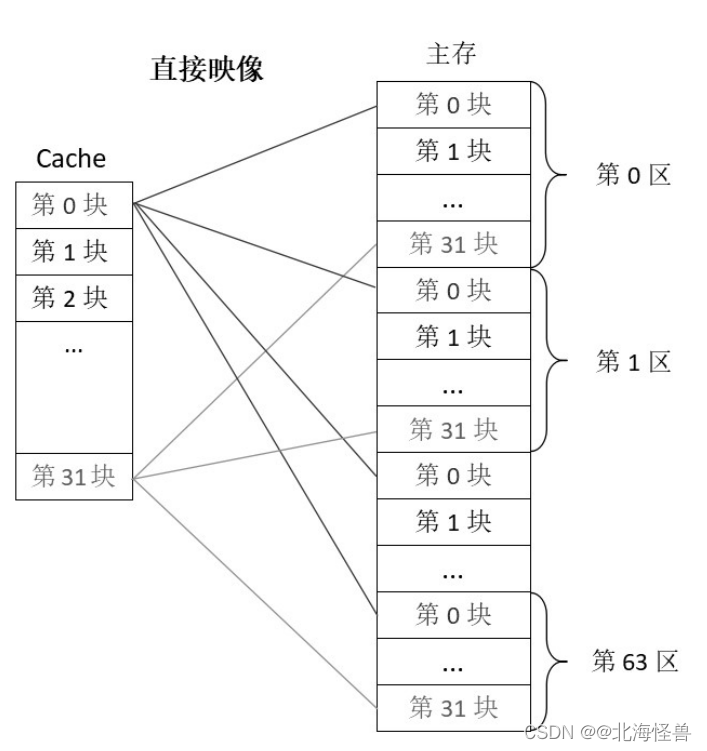
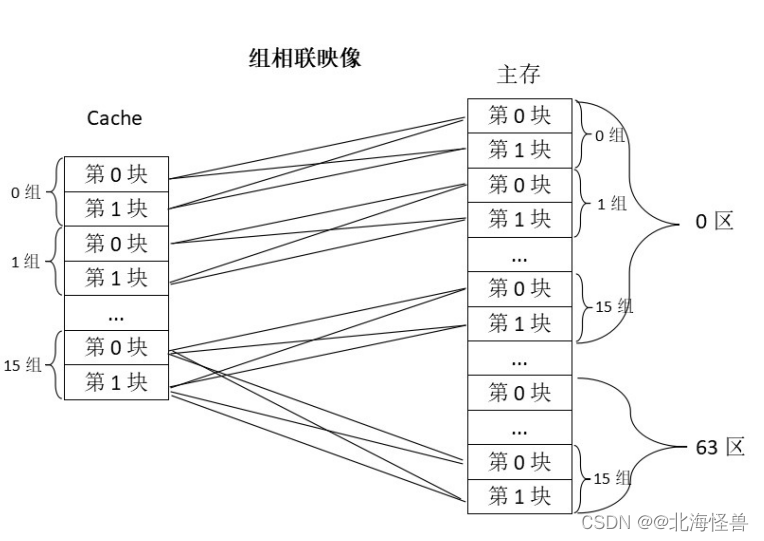
2. 高速缓存的替换算法
(1)随机替换算法
(2)先进先出替换算法
(3)近期最少使用替换算法
(4)优化替换算法
3. 高速缓存的性能分析
设Hc 为Cache 的命中率,tc 为Cache 的存取时间,tm 为主存的访问时间,则Cache 存储器的等效加权平均访问时间ta为:
ta=Hctc+(1-Hc)tm
虚拟存储器实际上是一种逻辑存储器。
常用的虚拟存储器由主存-辅存两级存储器组成。(13年第1题)
相联存储器是一种按内容访问的存储器。(12年第3题)
转换检测缓冲区/相联存储器/快表 能够不访问页表,实现快速将虚拟地址映射到物理地址的硬件机制
磁盘存取时间包括寻道时间,定位扇区的时间(也就是旋转延迟的时间)以及读取数据的时间(也就是传输时间),如果磁盘转速提高了一倍,则旋转延迟时间减少一倍。(21年上第4题)
在Windows系统中,磁盘碎片整理程序可以分析本地卷,以及合并卷上的可用空间使其成为连续的空闲区域,从而使系统可以更有效地访问文件或文件夹。(19年第17题)
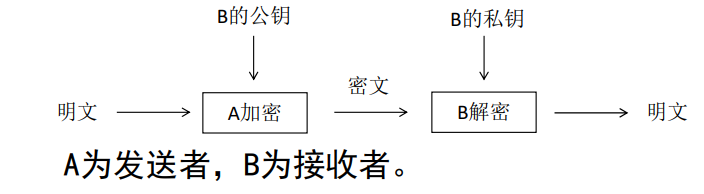
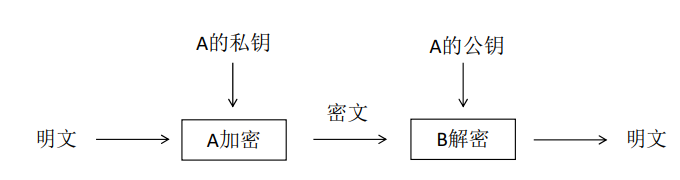
♥ 特点
保密性比较好,消除了最终用户交换密钥的需要,但加密和解密花费时间长、速度慢,不适合于对文件加密,而只适用于对少量数据进行加密。
♥ 代表算法
RSA (Rivest, Shamir and Adleman)算法
由于密钥对中的私钥只有持有者才拥有,所以私钥是不可能进行交换的。(17年第9题)
2)数字签名(12年第7题/18年第12、13题)
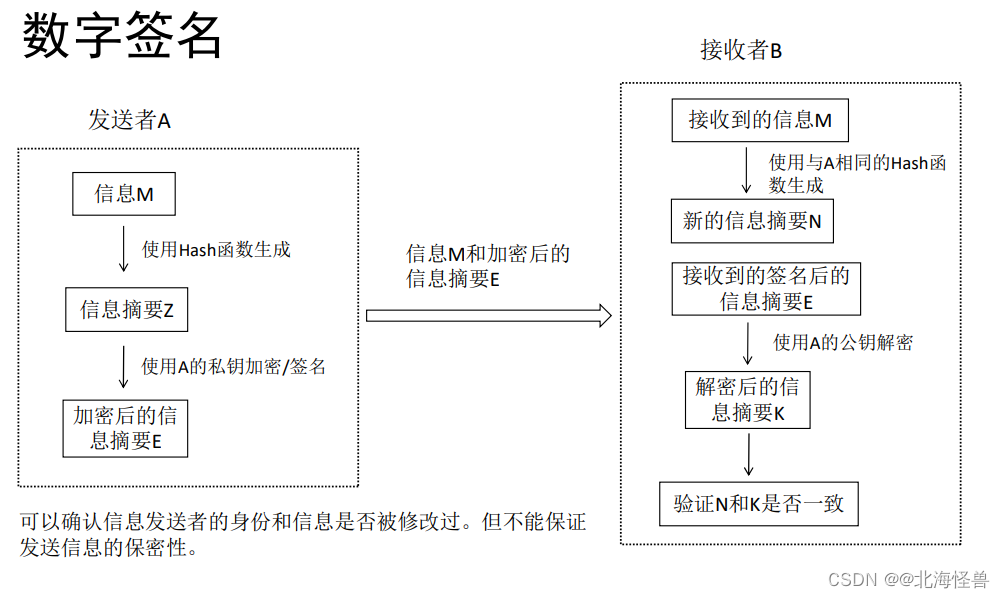
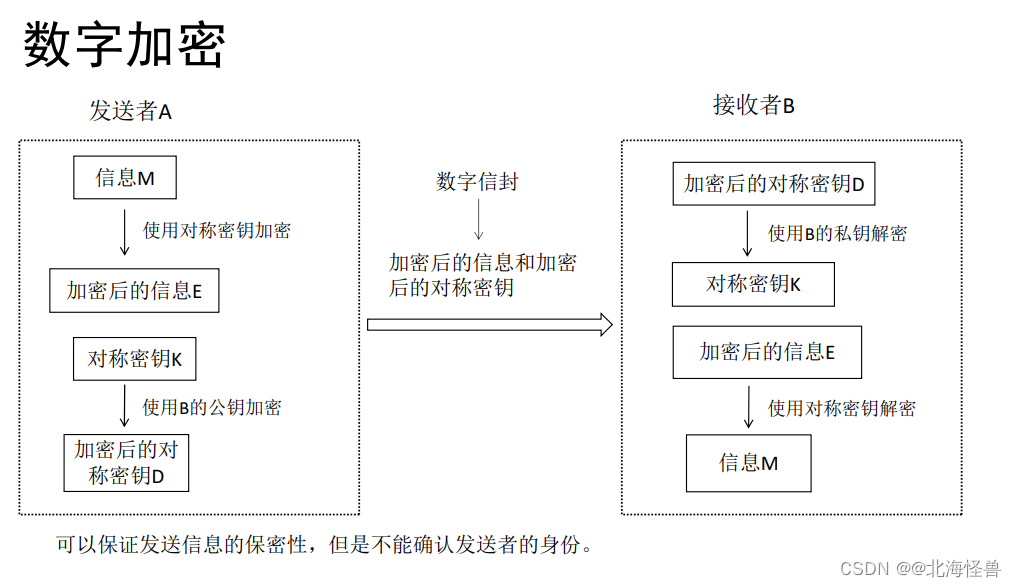
♥ 数字签名和数字加密的区别和联系
(1)数字签名使用的是发送方的密钥对,任何拥有发送方公开密钥的人都可以验证数字签名的正确性;
数字加密使用的是接收方的密钥对,是多对一的关系,任何知道接收方公开密钥的人都可以向接收方发送数据,但只有唯一拥有接收方私有密钥的人才能对信息解密。
(2)数字签名只采用了非对称加密算法,它能保证发送信息的完整性、身份认证和不可否认性,但不能保证发送信息的保密性;
数字加密(数字信封)采用了对称密钥算法和非对称密钥算法相结合的方法,它能保证发送信息的保密性(18年第11题)
例题1:假定用户A、B 分别从I1、I2两个CA取得了各自的证书,I1、I2互换公钥是A 、B 互信的必要条件。(17年第9题)
例题2:用户A从CA获得用户B的数字证书,并利用(CA 的公钥)验证数字证书的真实性。(11年第7题)
字典攻击:在破解密码或密钥时,逐一尝试用户自定义词典中的可能密码(单词或短语)的攻击方式。与暴力破解的区别是,暴力破解会逐一尝试所有可能的组合密码,而字典攻击会使用一个预先定义好的单词列表(可能的密码)。
密码盐:在密码学中,是指通过在密码任意固定位置插入特定的字符串,让散列后的结果和使用原始密码的散列结果不相符,这种过程称为加盐。
如果密码泄露,黑客可以利用他们数据字典中的密码,加上泄露的密码盐,然后进行散列,然后再匹配,由于密码盐可以加在任意位置,也加大了破解的难度。所以即使密码盐泄露,字典攻击和不加盐时的效果是不一样的。
计算机可靠性概述
(1)计算机系统的可靠性:是指从它开始运行(t=0)到某时刻 t 这段时间内能正常运行的概率,用R(t)表示。
(2)计算机系统的失效率:是指单位时间内失效的元件数与元件总数的比例,用λ表示。
(3)平均无故障时间(MTBF):两次故障之间能正常工作的时间的平均值称为
平均无故障时间MTBF=1/λ
(4)计算机系统的可维修性:一般平均修复时间(MTRF)表示,指从故障发生到机器修复平均所需的时间。
(5)计算机系统的可用性:指计算机的使用效率,它以系统在执行任务的任意时刻能正常工作的概率A表示。
A=MTBF/(MTBF+MTRF)
计算机可靠模型(10年第2题/11年第6题/17年第4题/19年第4题)
(1) 串联系统
当且仅当所有的子系统都能正常工作时,系统才能正常工作。
R = R1R2……RN
(2) 并联系统
只要有一个子系统正常工作,系统就能正常工作。
R = 1 - (1- R1)(1- R2)……(1- RN)
(3) N模冗余系统
在N 个系统中,只要有n+1 个或n+1 个以上子系统能正常工作,系统就能正常的工作。
例题:
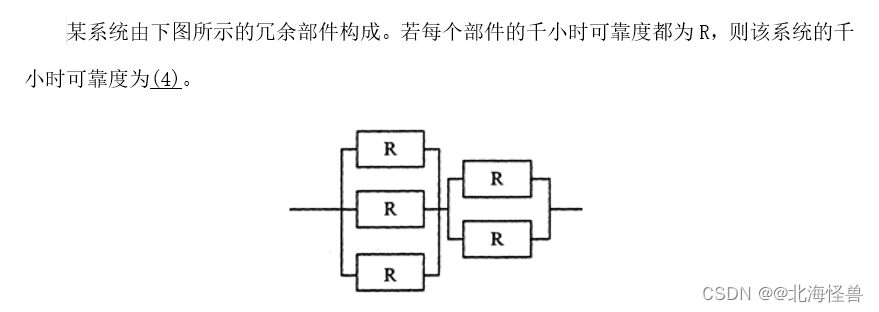
解析:计算机系统是一个复杂的系统,而且影响其可靠性的因素也非常繁复,很难直接对其进行可靠性分析。若采用串联方式,则系统可靠性为每个部件的乘积R=R1×R2×R3×…×Rn;若采用并联方式,则系统的可靠性为R=1-(1-R1)×(1-R2)×(1-R3)×…×(1-Rn)。
在本题中,既有并联又有串联,计算时首先我们要分别计算图中两个并联后的可靠度,它们分别为(1-(1-R)3)和(1-(1-R)2)。,然后是两者串联,根据串联的计算公式,可得系统的可靠度为
(1-(1-R)3)(1-(1-R)2)。
媒体的分类(14年第12-13题)
媒体可分为感觉媒体、表示媒体、表现媒体、存储媒体和传输媒体。
(1) 感觉媒体
直接作用于人的感官,产生感觉(视、听、嗅、味、触觉)的媒体,语言、音乐、音响、图形、动画、数据、文字等都是感觉媒体。
(2) 表示媒体
指用来表示感觉媒体的数据编码。
(3) 表现媒体 (13年第13题)
进行信息输入或输出的媒体。如键盘
(4) 存储媒体
用于存储表示媒体的物理实体。如光盘
(5) 传输媒体
传输表示媒体的物理实体。如光缆
声音是感觉媒体。(15年第12题)
声音的三个要素:
音强:即音量,是声音的强度,取决于声间的振幅。
音调:由声音的频率决定。
音色:指声音的感觉特性
1. 声音信号的数字化
(13年第11题)
A/D 转换是模拟信号转换为数字信号,比如声音转二进制;
D/A 转换是数字信号转换为模拟信号,比如二进制转声音。
(1) 采样(17年第13题)
每隔一个时间间隔就在模拟声音的波形上取一个幅度值,这个间隔时间称为采样频率。
常用的采样频率为8kHZ、11.025kHz、16kHz、22.05kHz(FM广播音质)、44.1kHz(CD音质)、48kHz(DVD音频或专业领域),频率越高音质越好。采样频率不应低于声音信号最高频率的两倍。
(2) 量化
就是把经过采样得到的瞬时值将其幅度离散,即用一组规定的电平,把瞬时抽样用最接近的电平值来表示。
量化的级别通常用位(bit)来表示,位数越高则音质越好。
(3) 编码
将声音数据写成计算机的数据格式。
每秒钟所需的存储量可由下式估算出:
文件的字节数 = 采样频率(Hz) * 采样位数 *声道数/8
补充知识点:
(09年第12题)
亚音信号(次音信号):频率范围 < 20Hz
音频信号:频率范围 20Hz~20kHz
超音频信号(超声波):频率范围 > 20kHz
1.颜色
(1)颜色三要素
色调:人眼看到一种或多种波长的光时所产生的彩色感觉。
亮度:表示色所具有的亮度
饱和度:指某一颜色的深浅程度(或浓度)
2. 图像数据获取
3. 图像的属性
(1)分辨率(12年第12题/13年第12题/14年第14题/17年第14题)
是指组成一幅图像的像素密度;也是水平和垂直的像素表示;即用每英寸多少点(dpi)表示数字化图像的大小。
水平分辨率表明显示器水平方向上显示出的像素点数目,垂直分辨率表明垂直方向上显示出的像素点数目。显示深度是指显示器t 显示每个像素点颜色的二进制位数。
用300dpi来扫描一幅3*4英寸的彩色照片,那么得到一幅900 × 1200个像素点的图像
DPI (Dots Per Inch,每英寸点数) 通常用来描述数字图像输入设备(如图像扫描仪)或点阵图像输出设备(点阵打印机)输入或输出点阵图像的分辨率。
| 例:使用150DPI 的扫描分辨率扫描一幅3×4英寸的彩色照片,得到原始的24位真彩色图像的数据量是()Byte (16年第14题) 解:150DPI的扫描分辨率表示每英寸的像素为150个。 (3×150)×(4×150)×24/8 = 810000 |
补充知识点:
(16年第12题)
WAV 为微软公司开发的一种声音文件格式,它符合RIFF 文件规范,用于保存Windows 平台及其应用程序所广泛支持。
BMP(全称Bitmap)是Windows 操作系统中的标准图像文件格式,可以分为两类:设备相关位图(DDB)和设备无关位图(DIB),使用非常广。BMP文件所占的空间很大。
MP3 是一种音频压缩技术,其全称是动态影像专家压缩标准音频正面3
MOV 即QuickTime 影片格式,它是Apple 公司开发的一种音频、视频文件格式,用于存储常用数字媒体类型。
(16年第13题)
PowerPoint 是微软公司的演示文稿软件。
Premiere 是一款常用的视频编辑软件,由Adobe 公司推出,广泛应用于广告制作和电视节目制作中。
Acrobat 是由Adobe 公司开发的一款PDF (Portable Document Format) 编辑软件。
Photoshop 是由Adobe Systems 开发和发行的图像处理软件。
CIF(Common Intermediate Format) 常用的标准化图像格式。CIF 像素=352×288(11年第13题)
由ISO制定的MPEG系列标准中,MPEG-7称为“多媒体内容描述接口 "(multimedia content description interface)。该标准是建立对多媒体内容的描述标准,满足包括静止图像、图形、3D模型、音频、话音、视频以及以上元素组合在一起的合成多媒体信息的应用领域的要求,并兼顾标准的通用性和扩展性的要求。(11年第14题)
进制的缩写
二进制:Binary,简称 B
八进制:Octal,简称 O
十进制:Decimal,简称 D
十六进制:Hexadecimal,简称 H
数的进制
a. 二进制:用 0 和 1 表示

b. 八进制:用 0~7 表示

c. 十进制:用 0~9 表示

d. 十六进制:用 0~9 和 A~F表示

进制转换
(1) 十进制转为二/八/十六进制(整除取余法):
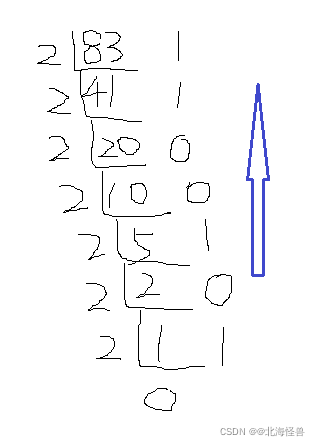
① 正整数转换成二进制:
把被转换的十进制整数反复地除以2,直到商为0,所得的余数(从末位读起)就是这个数的二进制表示。简称“除2取余法”。计算机内部表示数的字节单位是定长的,如8位,16位,或32位。所以,位数不够时,高位补零。
例:(83)10=(01010011)2
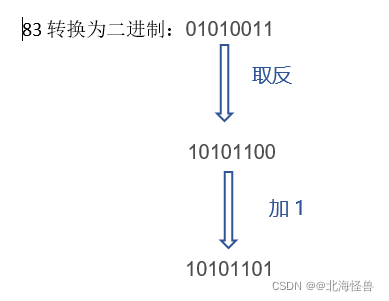
② 负整数转换为二进制
先是将对应的正整数转换成二进制后,对二进制取反,然后对结果再加一。
例:(-83)10=(10101101)2
③ 小数位转换为二进制
对小数点后面的数乘以2,取结果的整数部分(1或者0),然后再用小数部分再乘以2,再取结果的整数部分……以此类推,直到小数部分为0或者位数已经够了。
例:0.125转换成二进制的小数部分0.001

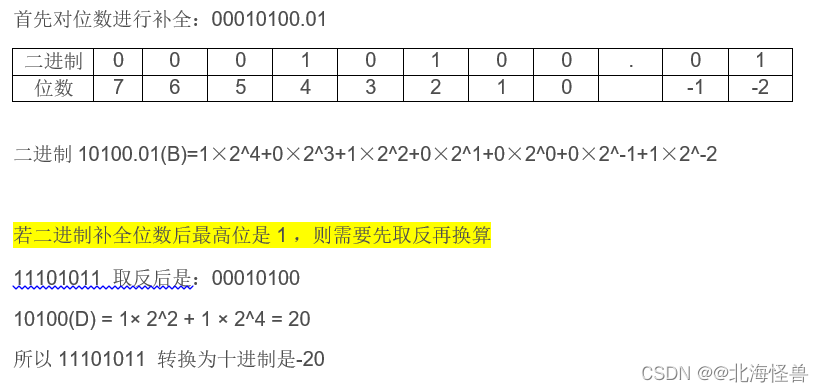
(2) 二/八/十六进制转为十进制(按权展开)
① 整数二进制用数值乘以2的幂次依次相加,小数二进制用数值乘以2的负幂次依次相加。
② 整数八进制用数值乘以8的幂次依次相加,小数八进制用数值乘以8的负幂次依次相加。

③ 整数十六进制用数值乘以16的幂次依次相加,小数十六进制用数值乘以16的负幂次依次相加。

(3) 八/十六进制转换为二进制
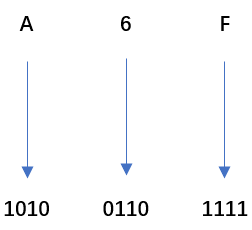
① 八进制357(O)转为二进制:011101111
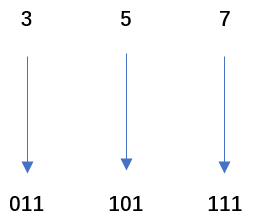
② 十六进制A6F(H) 转为二进制:101001101111
内存
1K= 2^10=1024KB=2 ^ 10B
C语言、C++、Shell、Python、Java语言及其他相近的语言使用字首“0x”,例如“0x5A3”。开头的“0”令解析器更易辨认数,而“x”则代表十六进制(就如“O”代表八进制)。在“0x”中的“x”可以大写或小写。对于字符量C语言中则以0x+两位十六进制数的方式表示,如0xFF。
机器字长为n,最高位是符号位,其定点整数的最大值为2^(n-1)-1(14年第2题)
机器字长为n,最高位为符号位,则剩余的n-1 位用来表示数值,其最大值是这n-1 位都为1 ,也就是2^(n-1)-1
海明码(09年第1题/14年第3题/17年第5题)
海明码是一种多重(复式)奇偶检错编码。它将信息用逻辑形式编码,以便能够检错和纠错。用在海明码中的全部传输码字是由原来的信息和附加的奇偶校验位组成的。每一个这种奇偶位被编在传输码字的特定位置上。
在数据位之间插入 k 个校验位,通过扩大码距来实现检错和纠错。
设数据位是 n 位,校验位是 k 位,则 n 和 k 必须满足以下关系:
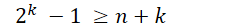
k常取满足该关系的最小值
在计算机中,各类运算等可以采用补码进行,特别是对于有符号数的运算。
在计算机中涉及补码的目的:
一是为了使符号位能与有效值部分一起参加运算,从而简化运算规则,使运算部件的设计更简单;
二是为了使减法运算转换为加法运算,进一步简化计算机中运算器的线路设计。
因此在计算机系统中常采用补码来表示和运算数据,原因是采用补码可以简化计算机运算部件的设计。
例:计算机指令一般包括操作码和地址码两部分,为分析执行一条指令,则其(操作码和地址码都应存入指令寄存器(IR))
解:程序被加载到内存后开始运行,当CPU执行一条指令时,先把它从内存储器取到缓冲寄存器DR中,再送入IR暂存,指令译码器根据IR的内容产生各种微操作指令,控制其他的组成部件工作,完成所需的功能。
指令寄存器(IR) 用来保存当前正在执行的一条指令。当执行一条指令时,先把它从内存取到数据寄存器(DR) 中,然后再传送到IR。而指令又分为操作码和地址码。
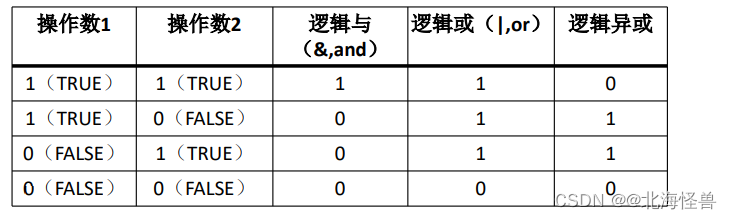
(10年第4题/12年第20题/17年第2题)
• 逻辑与(又称逻辑乘,类似于且,AND):两个操作数同时为真则为真,否则哪怕有一个操作数为假,则为假。
• 逻辑或(又称逻辑加,类似于或,OR):两个操作数只要其中一个为真即为真。
• 逻辑异或:(相异为真,相同为假)
• 逻辑非(NOT,类似于取反,!-):操作数为真,则结果为假;操作数为假,则结果为真。
例题:
17年第2题
要判断字长为16位的整数a的低四位是否全为0,则(A )
A. 将a与0x000F进行"逻辑与"运算,然后判断运算结果是否等于0
B. 将a与0x000F进行"逻辑或"运算,然后判断运算结果是否等于F
C. 将a与0xFFF0进行"逻辑异或"运算,然后判断运算结果是否等于0
D. 将a与0xFFF0进行"逻辑与"运算,然后判断运算结果是否等于F
12年第20题
对于逻辑表达式“x and y or not z”,and、or、not分别是逻辑与、或、非运算,优先级从高到低为not、and、or,and、or为左结合,not为右结合,若进行短路计算,则( )。
A. x为真时,整个表达式的值即为真,不需要计算y和z的值
B. x为假时,整个表达式的值即为假,不需要计算y和z的值
C. x为真时,根据y的值决定是否需要计算z的值
D. x为假时,根据y的值决定是否需要计算z的值
补充知识点:
在计算机信息处理中,“哈夫曼编码”是一种一致性编码法(又称“熵编码法”),用于数据的无损耗压缩。这一术语是指使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的。出现概率高的字符使用较短的编码,出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的。(11年第12题)
常用的寻址方式:(12年第4题)
(1)立即寻址。操作数就包含在指令中。
(2)直接寻址。操作数存放在内存单元中,指令中直接给出操作数所在存储单元的地址。
(3)寄存器寻址。操作数存放在某一寄存器中,指令中给出存放操作数的寄存器名。
(4)寄存器间接寻址。操作数存放在内存单元中,操作数所在存储单元的地址在某个寄存器中。
(5)间接寻址。指令中给出操作数地址的地址。
(6)相对寻址。指令地址码给出的是一个偏移量(可正可负),操作数地址等于本条指令的地址加上该偏移量。
(7)变址寻址。操作数地址等于变址寄存器的内容加偏移量。
反编译是编译的逆过程。反编译通常不能把可执行文件还原成高级语言源代码,只能转换成功能上等价的汇编程序。(09年第24题)
补充说明:(09年第25题)
Javasript 并不是严格意义的面向对象语言,而是一种基于对象、事件驱动编程的客户端动态脚本语言。
Ruby 是一种开源的面向对象程序设计的服务器端动态脚本语言。
脚本语言是为了缩短传统的编写-编译-链接-运行过程而创建的计算机编程语言。此命名起源于一个脚本“screenplay”,每次运行都会使对话框逐字重复。早期的脚本语言经常成为批处理语言或工作控制语言。一个脚本通常是解释运行而非编译。(16年第21题)
程序设计语言的基本成分:(19年第23题)
(1) 数据
(2) 运算
(3) 控制
顺序、选择、循环
(4) 传输
在程序中,可由程序员(用户)命名的有变量、函数和数据类型(17年第20题)
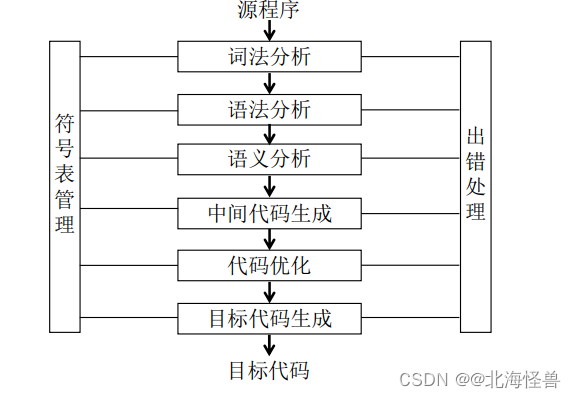
编译过程
(1)词法分析
• 任务:对源程序从前到后(从左到右)逐个字符地扫描,从中识别出 一个个“单词”符号。“单词”符号是程序设计语言的基本语法单位, 如关键字(保留字)、标识符、常数、运算符和标点符号、左右括号等。
(2)语法分析 (17年第22题)
• 任务:根据语言的语法规则,在词法分析的基础上,分析单词串是否构成短语和句子,即是否为合法的表达式、语句和程序等基本语言结构,同时检查和处理程序中的语法错误。
• 如果源程序没有语法错误,语法分析后就能正确地构造出其语法树。
(3)语义分析 (21年上)
• 任务:分析各语法结构的含义,检查源程序是否包含静态语义错误, 并收集类型信息供后面的代码生成阶段使用。
• 语义分析的一个主要工作是进行类型分析和检查。一个数据类型一般包含两个方面的内容:类型的载体及其上的运算。例如:整除取余运算符只能对整型数据进行运算,如果运算对象为浮点数,则认为是一种类型不匹配的错误。
(4)中间代码生成
• 任务:根据语义分析的输出生成中间代码。
• 常用的中间代码有:
① 后缀式(逆波兰式)(10年第17题/11年第20题)
优点:根据运算对象和运算符的出现次序进行计算,不需要使用括号,也便于使用栈实现求值。
② 四元式(三地址码)(16年第22题)
(操作符,操作数1,操作数2,结果)
③ 树形表示
(5)代码优化
• 由于编译器将源程序翻译成中间代码的工作是机械的、按固定模式进 行的,因此,生成的中间代码往往在时间和空间方面的效率较差。当 需要生成高效的目标代码时,就必须进行优化。
• 优化过程可以在中间代码生成阶段进行,也可以在目标代码生成阶段 进行。
(6)目标代码生成
• 目标代码生成是编译器工作的最后一个阶段。
• 任务:把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码和汇编指令代码。
• 这个阶段的工作与具体的机器密切相关。
(7)符号表管理(10年第18题/14年第22题)
作用:记录源程序中各种符号(变量等)的必要信息,以辅助语义的正确性检查和代码生成,在编译过程中需要对符号表进行快速有效地查找、插入、修改和删除等操作。
符号表的建立可以始于词法分析阶段,也可以放到语法分析和语义分析阶段,但符号表的使用有时会延续到目标代码的运行阶段。
(8)出错处理
源程序中不可避免地会有一些错误,大致分为静态错误和动态错误。
① 动态错误发生在程序运行时,如:变量取零时作除数、引用数组下标错误等。
② 静态错误是指编译阶段发现的程序错误,可分为语法错误和静态语义错误。
i 语法错误:单词拼写错误、标点符号错、表达式中缺少操作数、括号不匹配等 有关语言结构上的错误。
ii 静态语义错误:语义分析时发现的运算符和运算对象类型不合法等错误。
(17年第21题)
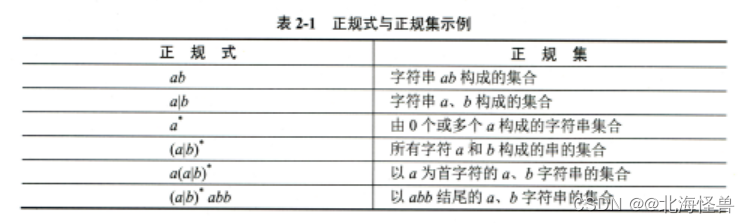
编译和解释的区别:(19年第21题)
在编译方式下,机器上运行的是与源码程序等价的目标程序,源程序和编译程序都不再参与目标程序的执行过程,程序运行速度快;而在解释方式下,解释程序和源程序(或其某种等价表示)要参与到程序的运行过程中,运行程序的控制权在解释程序,边解释边执行,程序运行速度慢。
基础概念
(1) 中缀表达式:
即我们通常所使用的表达式。如(a+b)c-d
(2)前缀表达式(波兰式):
将运算符写在前面,操作数写在后面,且不使用括号。如-×+abcd
(3)后缀表达式(逆波兰式):
将运算符写在后面,操作数写在前面,且不使用括号。ab+cd-
三种表达式之间的转换(11年第21题/12年第22题)
例:(a+b)×c-d
(1)中缀表达式转前缀表达式:
① 按计算顺序全部加上括号: (((a+b)×c)-d)
② 把每一对括号内的运算符移到括号前面: -(×(+(ab)c)d)
③ 把所有括号去掉:-×+abcd
(2)中缀表达式转后缀表达式:
① 按计算顺序全部加上括号: (((a+b)×c)-d)
② 把每一对括号内的运算符移到括号后面: (((ab)+c)d)-
③ 把所有括号去掉:ab+cd-
逻辑与运算优先级高于逻辑或
逻辑与运算的短路求值逻辑:若x为假,则可知“x^y” 的值为假,无需再对y求值,因此只有在x为真时继续对y 求值




线性表的查找方法 (09年第26题)
(1) 顺序查找
算法非常简单,但是效率较低,因为它是用所给关键字与线性表中各元素的关键字逐个比较,直到成功或失败。
(2) 折半查找
优点是比较次数少,查找速度快,平均性能好;
缺点是要求待查表是有序表,且插入和删除困难。
适用于不经常变动而查找频繁的有序列表。
一般不进行表的插入和删除操作。
需要对中间元素进行快速定位,在链表结构上无法实现。
(3) 分块查找
又称索引查找,主要用于分块有序表的查找。所谓分块有序是指将线性表 L (一堆数组)分成m个子表(要求每个子表的长度相等),且第 i+1 个子表中的每一个项目均大于第 i 个子表中的所有项目。因此,分块查找的关键在于建立索引表,其查找的平均长度介于顺序查找和折半查找之间。
例题:
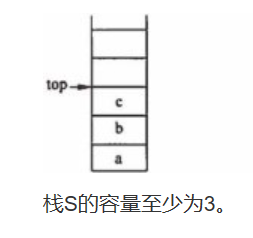
设栈 s 和队列 q 的初始状态为空,元素a、b、c、d、e依次进入栈s,当一个元素从栈中出来后立即进入队列q。若从队列的输出端依次得到元素c、d、b、a、e,则栈s的容量至少为()
解:看栈最多的时候能容纳多少元素。
字符串是一串文字及符号的简称,是一种特殊的线性表。
字符串的基本数据元素是字符,常常把一个串作为一个整体来处理。
串的定义及基本运算
串是仅由字符构成的有限序列,是取值范围受限的线性表。
一般记为 S=‘a1a2…an’,其中 S 是串名,单引号括起来的字符序列是串值。
• 串长:即串的长度,指字符串中的字符个数。
• 空串:长度为0的空串,空串不包含任何字符。
• 空格串:由一个或多个空格组成的串。
• 子串:由串中任意长度的连续字符构成的序列称为子串。
• 串相等:指两个串长度相等且对应位置上的字符也相同。
• 串比较:两个串比较大小时以字符的ASCII码值作为依据。
串的存储结构
(1)顺序存储:用一组地址连续的存储单元来存储串值的字符序列

(2)链式存储:字符串可以采用链表作为存储结构,当用链表存储串 中的字符时,每个结点中可以存储一个字符,也可以存储多个字符。

字符串运算
串的模式比较
数组
1)数组的定义及基本运算
一维数组是长度固定的线性表,数组中的每个数据元素类型相同。n维数组是定长 线性表在维数上的扩张,即线性表中的元素又是一个线性表。
2)数组的顺序存储
由于数组一般不做插入和删除,且元素个数和元素之间的关系不再发生变动,那 么数组适合采用顺序存储结构。
二维数组的存储结构可分为以行为主序(按行存储)和以列为主序 (按列存储)两种方法。
设每个数据元素占用L个单元,m、n为数组的行数和列数,那么:
以行为主序优先存储的地址计算公式为: Loc(aij)=Loc(a11)+((i-1)×n+(j-1))×L
以列为主序优先存储的地址计算公式为: Loc(aij)=Loc(a11)+((j-1)×m+(i-1))×L
矩阵
• 这里主要讨论一些特殊矩阵的压缩存储的问题。
• 对多个值相同的元素可以只分配一个存储单元,零元素不分配存储单 元。
• 下面主要讨论对称矩阵、三对角矩阵、稀疏矩阵。
1) 特殊矩阵
(1)对称矩阵
若矩阵An×n中的元素有aij=aji(1≤i,j≤n)的特点,则称之为对称矩阵。 如:
• 则矩阵An×n的n2个元素可以压缩存储到可以存放n(n+1)/2个元素的存储 空间中。 • 假设以行为主序存储下三角(包括对角线)中的元素,并以一个一维 数组B[n(n+1)/2]作为n阶对称矩阵A中元素的存储空间,则B[k] (0≤k<n(n+1)/2)与矩阵元素aij(aji)之间存在着一一对应的关系:
(2)三对角矩阵
• 对角矩阵是指矩阵中的非零元素都集中在以主对角线为中心的带状区 域中,其余的矩阵元素都为零。
• 下面主要考虑三对角矩阵,即只有主对角线及其左右两边为非零元素。
• 若以行为主序将n阶三对角矩阵An×n的非零元素存储在一维数组B[k] (0≤k<3n-2)中,则元素位置之间的对应关系为: k=3 × (i-1)-1+j-i+1=2i+j-3 (1≤i,j≤n)
2)稀疏矩阵:
• 在一个矩阵中,若非零元素的个数远远少于零元素的个数,且非零元 素的分布没有规律,则称之为稀疏矩阵。
• 可以用一个三元组(i,j,aij)唯一确定矩阵中的一个元素。
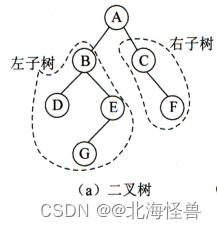
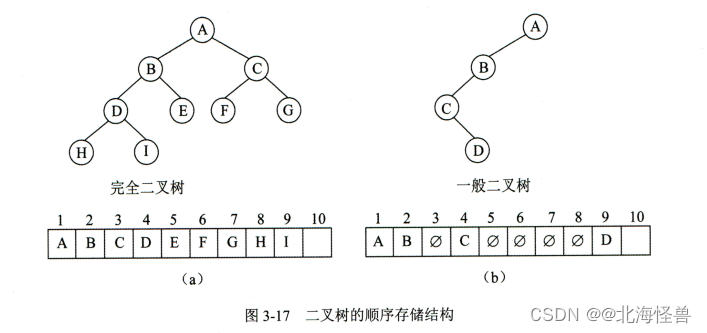
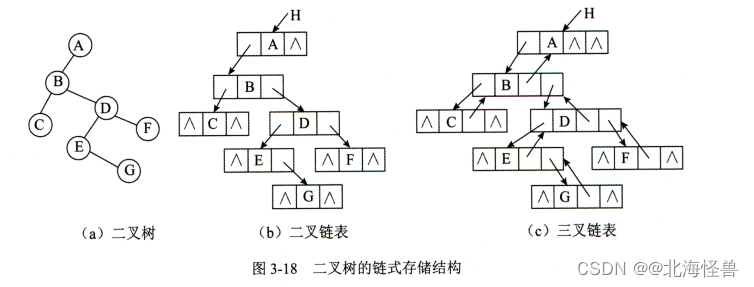
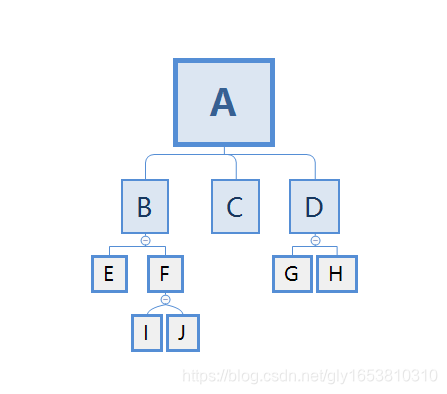
给定N个权值作为N个叶子结点,构造一颗二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
霍夫曼树可以用来进行通信电文的编码和解码。
B-树是一种平衡的多路查找树
(1) B-树中,所有非终端结点也就是非叶子结点都会包含关键字;
(2) 所有叶子结点都出现在同一层次上并且不带信息(可以看作是外部结点或查找失败的结点),层次相同也就是高度相同,从根结点到每个叶子结点的路径长度相同;
(3) 所有非终端结点包含的关键字数量是不确定的,指向的子树个数也是不确定的。
1. 图的定义及术语
图G(Graph)是由两个集合:V和E所组成的,V是有限的非空顶点 (Vertex)集合,E是用顶点表示的边(Edge)集合,图G的顶点集和边集分别记为V(G)和E(G),而将图G记作G=(V,E)。
可以看出,一个顶点集合与连接这些顶点的边的集合可以唯一表示一个图。
在图中,数据结构中的数据元素用顶点表示,数据元素之间的关系用边表示
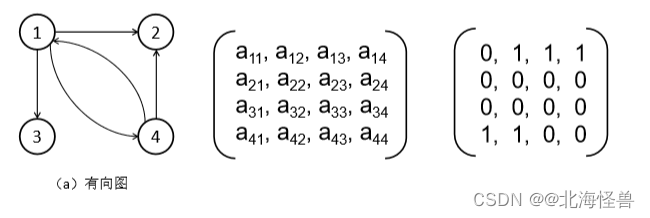
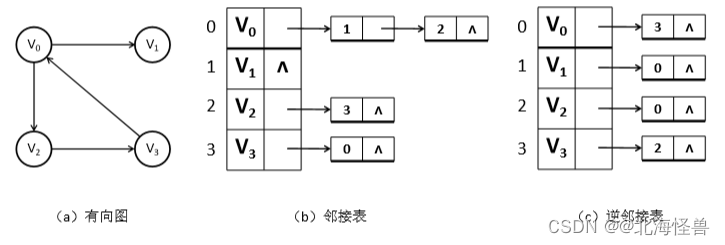
1)有向图:图中每条边都是有方向的。从顶点vi到顶点vj表示为<vi,vj>, 而从顶点vj到顶点vi表示为<vj,vi>。有向边也称为弧。起点称为弧尾, 终点称为弧头。
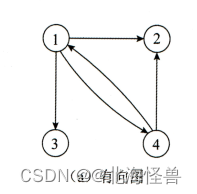
有向图a的顶点集合为: V(a)={1,2,3,4}
边的集合为: E(a)={<1, 2>,<1, 3>,<4, 2>,<1, 4>,<4, 1>}
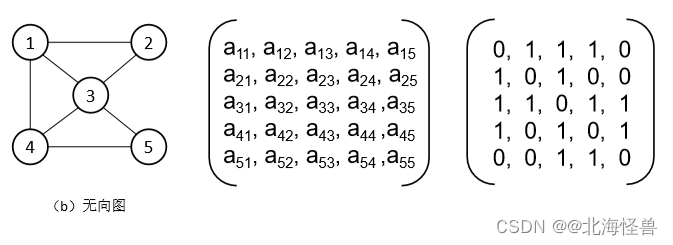
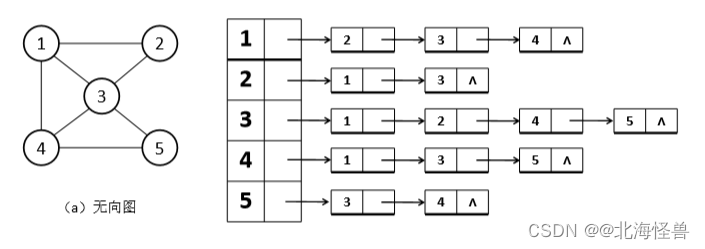
2)无向图:图中每条边都是无方向的。顶点 vi和 vj之间的边用(vi,vj)表 示。在无向图中,(vi,vj)和(vj,vi)表示的是同一条边。
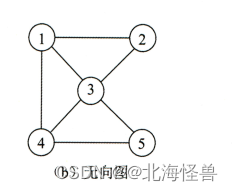
左侧无向图b的顶点集合为: V(b)={1,2,3,4,5}
边的集合为: E(b)={(1, 2),(1, 3),(1, 4),(4, 5),(2, 3),(3, 4), (3, 5)}
3)完全图:若一个无向图具有n个顶点,而每一个顶点与其他n-1个顶点之间都有边,则称之为无向完全图。显然,含有n个顶点的无向完全图 共有n(n-1)/2条边,类似地,有n个顶点的有向完全图中弧的数目为 n(n-1),即任意两个不同顶点之间都存在方向相反的两条弧。
4)度、出度、入度:
顶点 v 的度是指关联于该顶点的边的数目,记作D(v)
若为有向图,度表示该顶点的入度和出度之和
顶点的入度是以该顶点为终点的有向边的数目
顶点的出度指以该顶点为起点的有向边的数目
5)路径
6)子图
7)连通图
8)强连通图
9)网:边或者弧具有权值的图
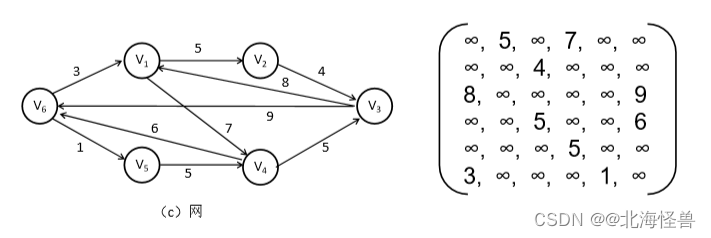
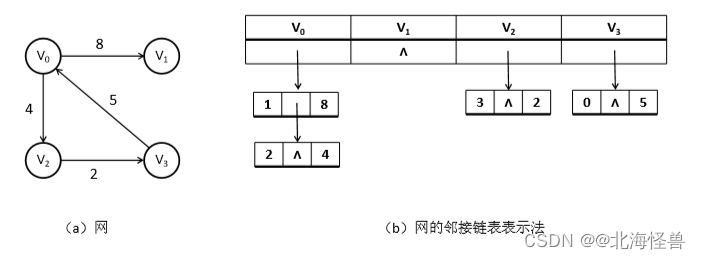
2)邻接链表表示法
邻接链表是为图的每一个顶点建立一个单链表,第i个单链表中的节点 表示依附于顶点vi的表(对于有向图是以vi为尾的弧)。
• 邻接链表中的表节点有表节点和表头节点两种类型:
无向图的邻接链表表示法
有向图的邻接链表表示法
带权值的网的邻接链表表示法
可参考这篇博文,结合动画浅显易懂:六大排序算法
1. 直接插入排序
• 具体做法是:在插入第 i 个记录时,R1,R2,… ,Ri-1已经排好序,将记录Ri 的关键字 ki 依次与关键字 ki-1,ki-2,… ,k1进行比较,从而找到 Ri 应该插入的位置,插入位置及其后的记录依次向后移动。
例:
待排序列:35 12 67 29 51
第1步:35
第2步:12 35
第3步:12 35 67
第4步:12 29 35 67
第5步:12 29 35 51 67
2. 冒泡排序
• 首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则交换两个记录的值,然后比较第二个记录和第三个记录的关键字,依此类推
(左边大于右边交换一趟排下来最大的在右边)
待排序列:35 12 67 29 51
第一次冒泡排序:
①:12 35 67 29 51
②:12 35 67 29 51
③:12 35 29 67 51
④:12 35 29 51 67
第二次冒泡排序:
①:12 35 29 51 67
②:12 29 35 51 67
3. 简单选择排序 (不稳定的排序算法) (21年上第6题)
• n个记录进行简单选择排序的基本方法是: 通过 n-i 次关键字之间的比较,从 n-i+1 个记录中选出关键字最小的记录,并和第 i(1≤i≤n)个记录进行交换,当 i 等于 n 时所有记录有序排列
找出每次剩下数字中的最小值
例:
待排序列:35 12 67 29 51
①:找出最小值12,与第一个关键字进行交换:12 35 67 29 51
②:找出剩下4个记录中的最小值29,与第二个关键字交换:12 29 67 35 51
③:找出剩下3个记录中的最小值35,与第三个关键字交换:12 29 35 67 51
④:找出剩下2个记录中的最小值51,与第四个关键字交换:12 29 35 51 67
4. 希尔排序
• 希尔排序又称 “缩小增量排序”,是对直接插入排序方法的改进。 (21年上第9题)
• 先将整个待排记录序列分割成若干子序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序
例:
待排序列: 48 37 64 96 75 12 26 48 54 03
d1=5(距离为5的倍数的记录为同一组): 48 37 64 96 75 12 26 48 54 03
d1=5 排序后: 12 26 48 54 03 48 37 64 96 75
d2=3(距离为3的倍数的记录为同一组): 12 26 48 54 03 48 37 64 96 75
d2=3 排序后: 12 03 48 37 26 48 54 64 96 75
d3=1(距离为1的倍数的记录为同一组,即所有记录为一组): 12 03 48 37 26 48 54 64 96 75
d3=1 排序后: 03 12 26 37 48 48 54 64 75 96
5. 快速排序
• 通过一趟排序将待排的记录划分为独立的两部分,称为前半区和后半区,其中,前半区中记录的关键字均不大于后半区记录的关键字,然后再分别对这两部分记录继续进行快速排序,从而使整个序列有序。
• 具体做法:附设两个位置指示变量 i 和 j ,它们的初值分别指向序列的第一个记录和最后一个记录。设枢轴记录(通常是第一个记录)的关键字为 pivot,则首先从 j 所指位置起向前搜索,找到第一个关键字小于 pivot 的记录时将该记录向前移到 i 指示的位置,然后从 i 所指位置起向 后搜索,找到第一个关键字大于 pivot 的记录时将该记录向后移到 j 所指位置,重复该过程直至 i 与 j 相等为止

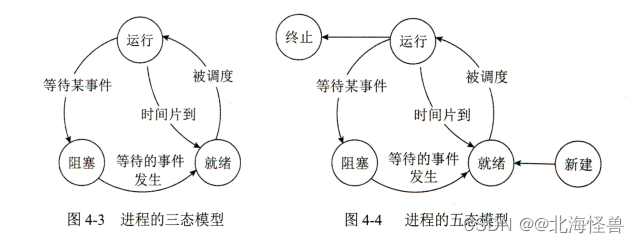
进程是资源分配和独立运行的基本单位,进程两个基本属性:可拥有资源的独立单位;可独立调度和分配的基本单位。(20年第21题)
| if((S=S-1)≥0) 继续执行本进程 else //(S=S-1)<0 挂起本进程(本进程等待),转到另一个进程 |
| if ((S=S+1)>0) 不唤醒队列中的等待进程,继续执行本进程 else //(S=S+1)≤0 唤醒队列中的等待进程,同时继续执行本进程 |
例题:生产者消费者问题
生产者进程P1不断地生产产品送入缓冲区,消费者进程P2不断地从缓冲区中取产品消费。
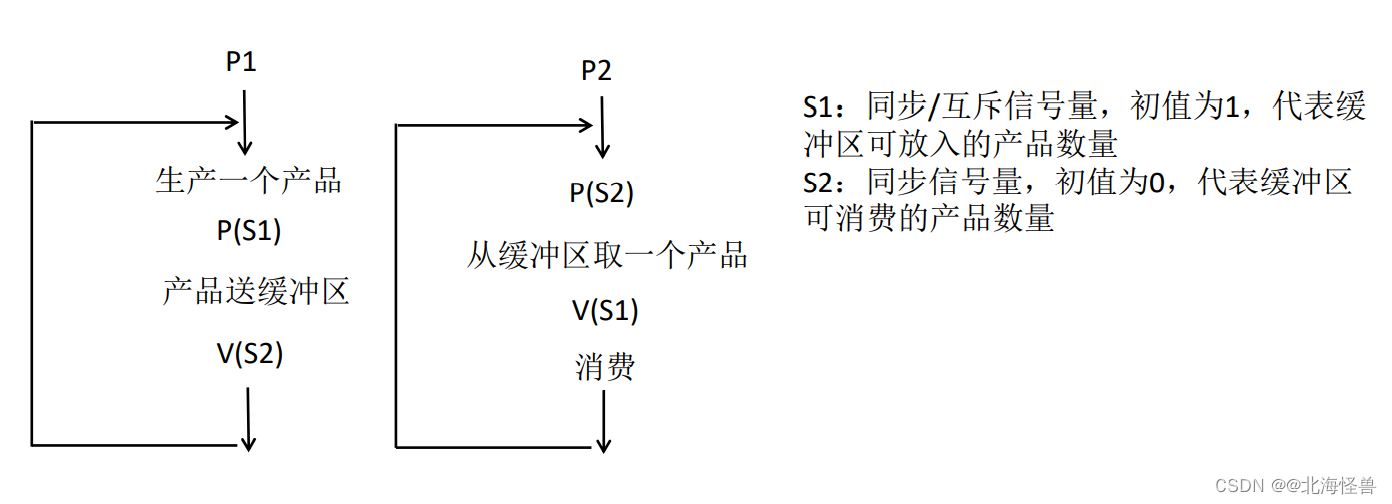
一个生产者和一个消费者,缓冲区中可存放n件产品,生产者不断地生产产品,消费者不断地消费产品,如何利用PV操作实现生产者和消费者的同步。
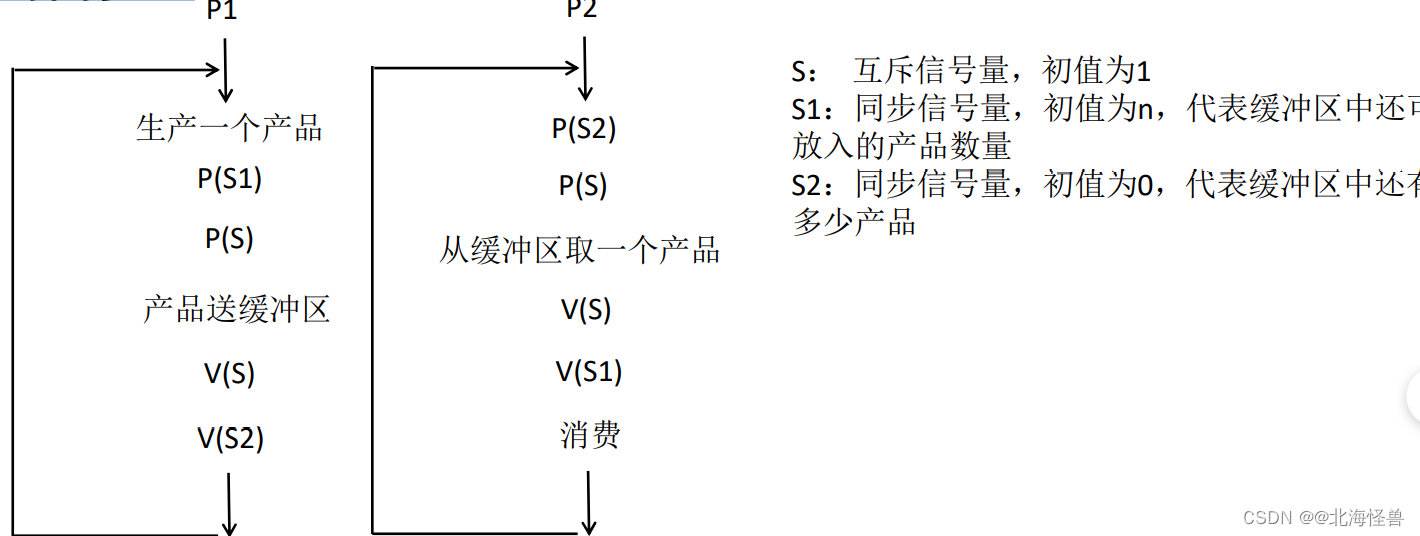
(09年第21、22题)
死锁:是指两个以上的进程互相都要求对方已经占有的资源导致无法继续运行下去的现象。
| 例:现有5个进程,每个进程都需要4个资源,而系统一共有15个资源, 会发生死锁吗? 系统中共有 n 个进程共享同一类资源,当每个进程都需要 k 个资源时, 至少需要多少个资源才不会发生死锁? 至少需要资源:M = (k-1)×n+1 |
♥ 注:不要死记公式,可以去了解哲学家进餐问题。假设有 n 个哲学家一起用餐,每个哲学家需要 2 支筷子才能够正常用餐,那么至少需要多少支筷子才可以保证 n 个哲学家都能正常用餐。可以想象 n 个哲学家围坐在一个圆桌前,先按顺序一人发一支筷子,那么只需要再多一支筷子就能满足条件。
3. 进程资源图
4. 死锁产生的原因及4个必要条件(21年第20题)
① 互斥条件
② 请求保持条件
③ 不可剥夺条件 :破坏不可剥夺条件的方法就是强制剥夺资源
④ 环路条件
5. 死锁的处理
死锁的处理策略有:
① 鸵鸟策略(不理睬策略)
② 预防策略
③ 避免策略
④ 检测与解除死锁
1)死锁预防:采用某种策略限制并发进程对资源的请求。
(1)预先静态分配法:破坏“不可剥夺条件”
(2)资源有序分配法:破坏了“环路条件”
2)死锁避免:如银行家算法。(12年第23、24、25题)
银行家算法对于进程发出的每一个系统可以满足的资源请求命令加以检测,如果发现分配资源后系统进入不安全状态,则不予分配;若分配资源后系统仍处于安全状态,则实施分配。提高了资源的利用率,但是检测分配后系统是否安全增加了系统开销。
假设系统中有三类互斥资源R1、R2和R3,可用资源数分别为8、7和4,在T0时刻系统中有P1,P2,P3,P4,P5这5个进程,这些进程对资源的最大需求量和已分配资源数如下图所示。那么进程按什么序列执行,系统状态是安全的
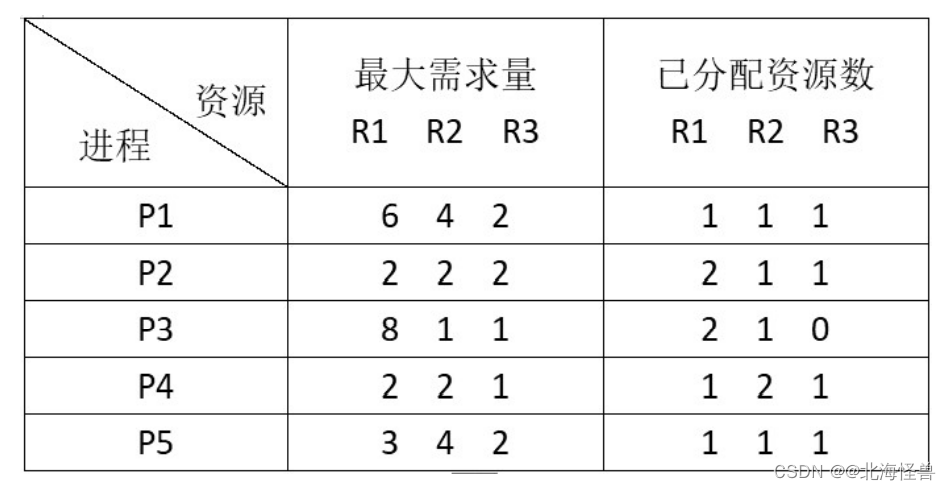
解题思路
第一步:计算已经用掉的资源数和剩下可用的资源数:
| R1 | R2 | R3 | |
|---|---|---|---|
| 总资源数 | 8 | 7 | 4 |
| 已经使用的资源数 | 7 | 6 | 4 |
| 剩下的资源数 | 1 | 1 | 0 |
第二步:计算进程还需要的资源数
| R1 | R2 | R3 | |
|---|---|---|---|
| P1 | 5 | 3 | 1 |
| P2 | 0 | 1 | 1 |
| P3 | 6 | 0 | 1 |
| P4 | 1 | 0 | 0 |
| P5 | 2 | 3 | 1 |
第三步:给确定接下来的进程执行顺序
还剩下1 1 0 ,那么可以先执行P4,
P4 执行完成之后释放资源后,资源所剩数目:2 3 1
可以执行的进程是P2 和P5,
如果限制性P2 ,那么执行完成后释放资源后所剩资源数:4 4 2
然后执行P5 ,执行完成后释放的资源数:
3)死锁检测:系统定时地运行一个程序来检测是否发生死锁,若有,则设法加以解除。
4)死锁解除:(21年上)
① 资源剥夺法
② 撤销进程法
传统进程的两个基本属性:
① 可拥有资源的独立单位
② 可独立调度和分配的基本单位
传统进程在创建、撤销和切换中,系统必须为之付出较大的时空开销。
引入线程后:线程作为调度和分配的基本单位,进程作为独立分配资源的单位。
一个进程中有多个线程,共享该进程的资源。
线程基本不拥有资源,每个线程自己独有资源很少,线程共享地址空间,但线程的私有数据,线程栈又是单独保存的。(13年上第22题/21年上第19题)
不共享的资源:程序计数器、寄存器和栈。
多个线程共享的有:内存地址空间、代码、数据、文件,全局变量,记账信息等
线程的种类(根据操作系统内核是否对线程可感知)(20年第20题)
(1)用户级线程 (User-Level Threads)
不依赖于内核。该类线程的创建、撤销和切换都不利用系统调用来实现。 用户线程由应用程序所支持的线程实现,内核意识不到用户级线程的实现。
(2)内核支持线程(Kernel-Supported Threads)
依赖于内核。该类线程的创建、撤销和切换都利用系统 调用来实现。内核级线程又称为内核支持的线程。
1. 存储器的结构
(1) 逻辑地址(虚拟地址、相对地址)
程序员使用的地址只是用符号命名的一个地址,称为符号名地址,这个地址并不是主存中真实存在的地址。
(2)物理地址(绝对地址)
是主存中真实存在的地址。
(3)存储空间
逻辑地址空间(地址空间)是逻辑地址的集合,物理地址空间(存储空间)是物理地址的集合
2. 地址重定位
一个程序,没有运行时,存储在外存,程序运行时,需要装载到内存中,就需要把程序中的指令和数据的逻辑地址转换为对应的物理地址, 这个转换的过程称为地址重定位。
静态重定位:在程序装入主存时已经完成了逻辑地址到物理地址的变化,在程序的执行期间不会再发生变化。
动态重定位:在程序运行期间完成逻辑地址到物理地址的变换。
1. 分区存储管理
把主存划分成若干个区域,每个区域分配给一个作业使用。这就是分区存储管理方式。分为固定分区、可变分区和可重定位分区。
(1)固定分区:系统生成时已经分好区。
(2)可变分区:是一种动态分区方式,存储空间的划分是在作业装入时进行的,故分区的个数是可变的,分区的大小刚好等于作业的大小。
(3)可重定位分区:分配好的区域可以移动。
2. 分区保护

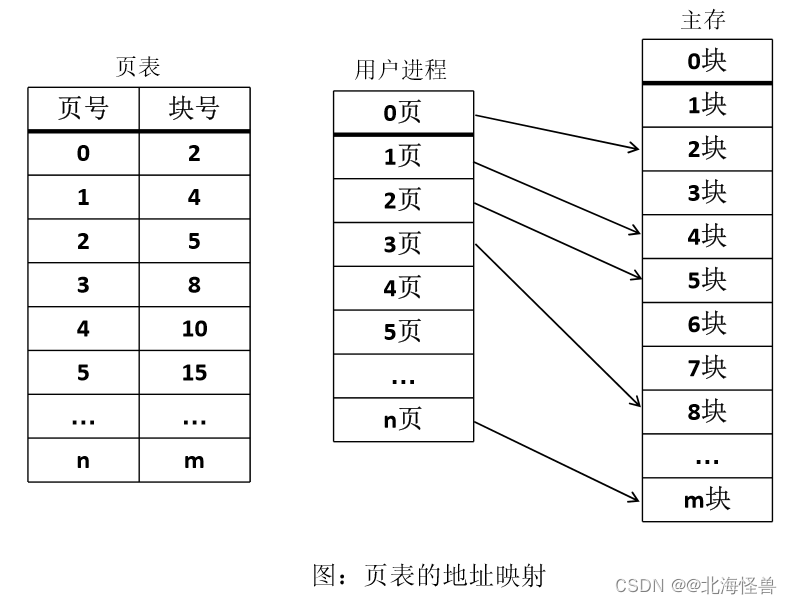
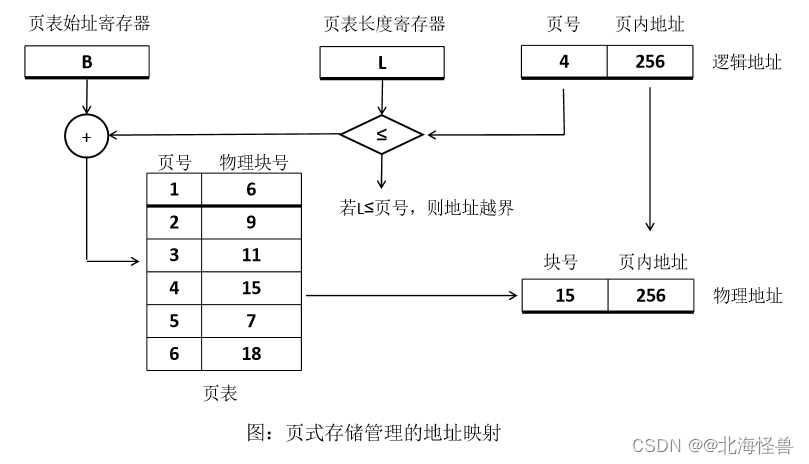
• 在分段存储管理中,将用户程序或作业的地址空间按内容划分为段,比如主程序 一段,子程序一段,数据专门放一段,每个段的长度是不等的,但是每个段占用一个连续的分区。进程中的各个段可以离散地分配到主存的不同分区中。在系统中为每个进程建立一张段映射表,简称为“段表”
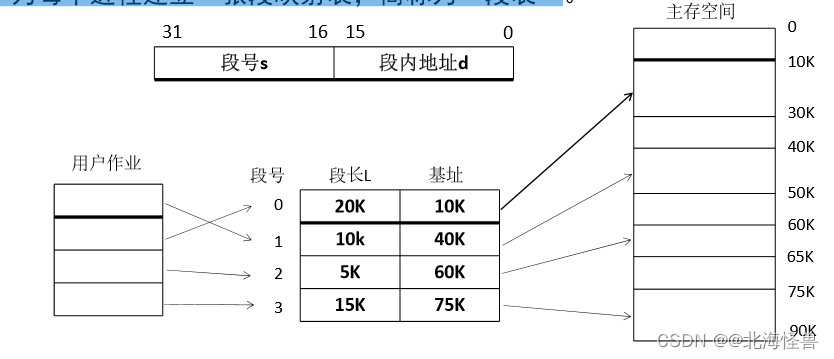
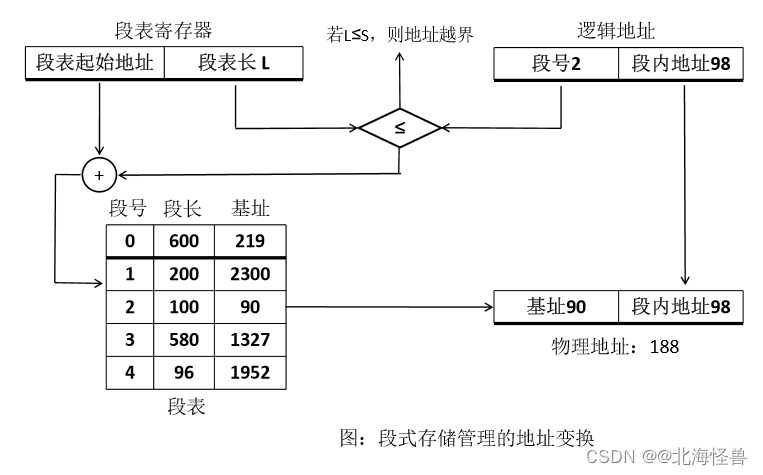
• 先将整个主存划分成大小相等的存储块(页框), 将用户程序按程序的逻辑关系分为若干个段,然后再将段划分成页。
段页式系统中同时有段表和页表:
• 段表:段号、页表始址、页表长度
• 页表:页号、物理块号
• 逻辑地址:段号、段内页号、页内地址
• 物理地址:块号、页内地址
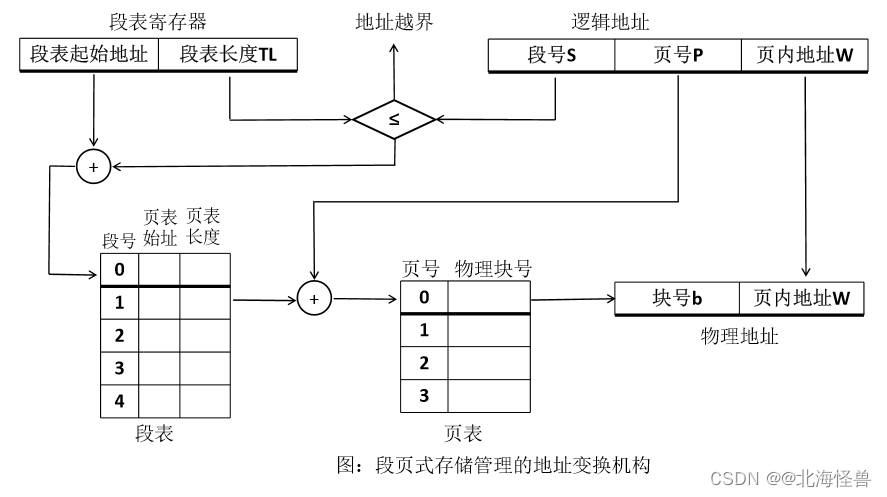
常用的虚拟管理器由主存-辅存两级存储器组成。(13年第1题)
程序局部性原理
程序在执行时将呈现出局部性规律,即在一段时间内,程序的执行仅限于某个部分,它所访问的存储空间也局限于某个区域内。
(1)时间局限性:程序中的某条指令一旦执行,则不久的将来很有可能再次被访问;某个存储单元如果被访问,不久的将来它很可能再次被访问。
(2)空间局限性:一旦程序访问了某个存储单元,则不久的将来,其附近的存储单元也最有可能被访问。
• 如果我们运行程序的时候,允许将作业的一部分装入主存即可运行程序,而其余部分可以暂时留在磁盘上,等需要的时候再装入主存。这样一来,一个小的主存空间就可以运行比它大的一个作业。从用户角度看,系统具有的主存容量比实际的主存容量要大得多,称为虚拟存储器。
虚拟存储器的实现
(1)请求分页系统
(2)请求分段系统
(3)请求段页式系统
请求分页管理的实现
• 在纯分页的基础上增加了请求调页功能,页面置换功能。
• 在请求分页系统中,每当所要访问的页面不在主存时便产生一个缺页中断。
页面置换算法
(1)最佳置换算法
是一种理想化的算法,即选择那些是永不使用的, 或者是在最长时间内不再被访问的页面置换出去。
(2)先进先出置换算法 (FIFO)
优先淘汰最先进入主存的页面,也就 是在内存中停留时间最长的页面。
(3)最近最少未使用算法 (LRU)
优先淘汰最近这段时间用得最少的页 面。系统为每一个页面设置一个访问字段,记录这个页面自上次被访问 以来所经历的时间T,当要淘汰一个页面时,选择T最大的页面。
(4)最近未用置换算法 (NUR)
优先淘汰最近一段时间未引用过的页面。 系统为每一个页面设置一个访问位,访问位为1代表访问过,为0代表没有被访问过,置换页面时选择访问位为0的置换出去。
• 设备管理的目标主要是如何提高设备的利用率,即提高CPU与 I/O 设备之间的并行操作速度,并为用户提供方便、统一的界面。
• 为了提供设备的利用率,我们采用了“分层构造”的思想,即把设备管理软件组织成为一系列的层次。
• 主要分为4层:
① 中断处理程序(16年第23题)
当用户通过键盘或鼠标进入某应用系统时,通常最先获得键盘或鼠标输入信息的是中断处理程序
② 设备驱动程序
③ 与设备无关的系统软件
④ 用户级软件
• 各层之间既相互独立,又彼此协作
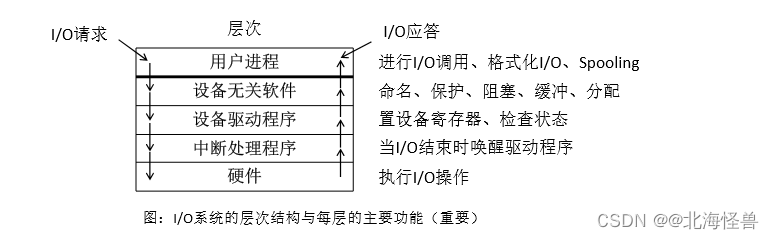
例:某用户进程现在需要读取硬盘中的数据。
① 与设备无关软件检查高速缓存中有没有要读的数据块,如果有,则直接从高速缓存中调取;如果没有,则调用设备驱动程序,向 I/O 硬件发出一个请求。
② 用户进程转为阻塞状态,等待磁盘操作的完成。磁盘操作完成时,硬件产生一个中断,转入中断处理程序。
③ 中断处理程序检查中断的原因,认识到这时磁盘读取数据的操作已经完成,于是唤醒用户进程取回从磁盘 读取的信息,此次 I/O 请求结束。
④ 用户进程得到了需要读取的数据内容,由阻塞转为就绪状态,继续运行。
按照是否可以被屏蔽,中断的种类(10年第3题)
(1)不可屏蔽中断(非屏蔽中断)
不可屏蔽中断源一旦提出请求,CPU 必须无条件响应,而对可屏蔽中断源的请求,CPU 可以响应,也可以不响应。
典型的非屏蔽中断源的例子是电源掉电
(2)可屏蔽中断
例子是打印机中断

磁盘调度的分类:先进行移臂调度,再进行旋转调度。
磁盘调度的目标是使磁盘的平均寻道时间最少。
读取磁盘数据的时间 = 寻道时间 + 旋转延迟 + 数据传输时间
• 文件的逻辑结构:从用户角度看到的文件组织形式就是文件的逻辑结构,但实际上这些文件在内存上的存放方式可能并不是这样的。
(1)有结构的记录式文件
(2)无结构的流式文件
• 文件的物理结构:从实现的角度看,文件在存储器上的存放方式。
(1)连续结构
(2)链接结构
(3)索引结构
(4)多个物理块的索引表
(1)一级目录结构:只有一张目录表,不允许重名,查找速度慢,不能实现文件共享。
(2)二级目录结构:由主文件目录和用户目录组成。
(3)多级目录结构:我们熟悉的Windows 系统,以及UNIX 系统都采用这种多级目录结构。
(14年第27题)
绝对路径:是指从根目录“\”开始的完整文件名,即它是由从根目录开始的所有目录名以及文件名构成。
相对路径:是从当前工作目录下的路径名。
• 在将文件保存到外存时,我们首先要知道哪些存储空间是“占用”的, 哪些存储空间是“空闲”的。因此我们需要对磁盘空间进行管理。
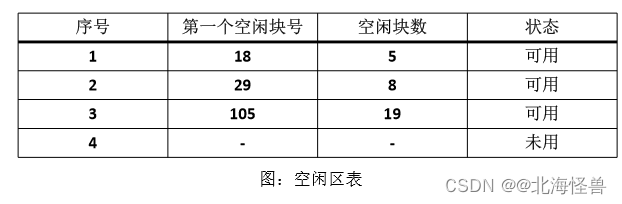
• 常用的空闲空间的管理方法有空闲区表、位示图、空闲块链和成组链接法。
(1)空闲区表
操作系统为磁盘的所有空闲区建立一张空闲表。它适用于连续文件结构。
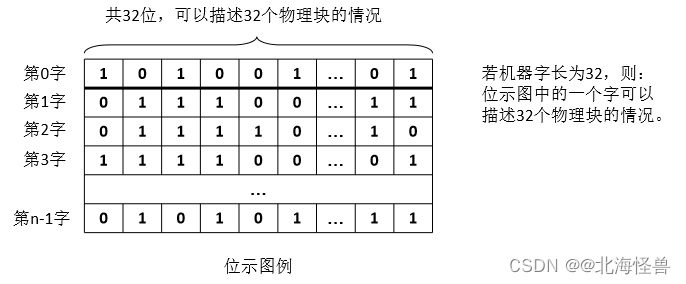
(2)位示图
在外存上建立一张位示图(bitmap),记录文件存储器的使用情况。每一位对应文件存储器上的一个物理块,0表示空闲,1表 示占用。
(3)空闲块链
每一个空闲物理块中设置一个指针,它指向下一个空 闲物理块,所有空闲物理块构成一个链表,链表的头指针放在文件存储 器的一个特定位置上(如管理块中)。
(4)成组链接法
在系统中将空闲块分成若干个组,每100个空闲块为一组,每组的第一个空闲块登记了下一组空闲块的物理盘块号和空闲块总数。
短期调度(进程调度 / 低级调度 / 微观调度)
一般情况下使用最多的就是短期调度,这也就是通常所说的调度。它的主要任务是按照某种策略和算法将处理机分配给一个处于就绪状态的进程,分为抢占式和非抢占式。
中期调度(交换调度)
核心思想是将进程从内存或从CPU竞争中移出,从而降低多道程序设计的程度,之后进程能被重新调入内存,并从中断处继续执行,这种交换的操作可以调整进程在内存中的存在数量和时机。
长期调度(作业调度/高级调度)
它的频率比较低,主要用来控制内存中进程的数量。
作业调度算法
(1)先来先服务
按作业到达的先后顺序进行调度。
(2)短作业优先
按作业运行时间的长短进行调度,即启动要求运行时间最短的作业。
(3)响应比高优先
响应比高的作业优先启动。
响应比:RP = 作业响应时间/作业执行时间 =(作业等待时间+作业执行时间)/作业执行时间
(4)优先级调度算法
按照系统设定的优先级或者用户指定的优先级, 优先级高的先调度。
(5)均衡调度算法
根据系统的运行情况和作业本身的特性对作业进x行分类,力求均衡地使用系统的各种资源,即注意发挥系统效率,又使用户满意。
例:假设所有作业同时到达,平均周转时间最短的调度算法是:短作业优先(21年上第18题)
时间片轮转调度 (13年第21题)
是一种最古老、最简单、最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
基本原理:系统将所有的就绪进程按先来先服务的原则排成一个队列,每次调整时,把CPU 分配给队首进程,并令其执行一个时间片。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便根据此信号来停止该进程的执行,并将它送往就绪队列的末尾,然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。因此用户一次响应的时间为 q=n×q
最适用于交互式系统。
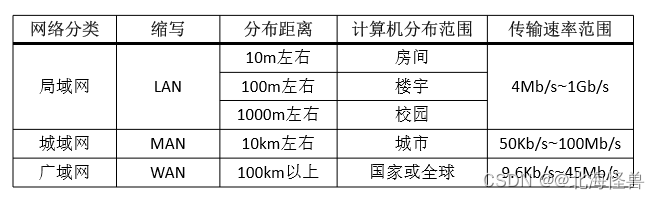
(1)局域网 (LAN)
传输距离有限,传输速度高,以共享网络资源为目的的网络系统。
(2)城域网 (MAN)
规模介于局域网和广域网之间的一种较大范围的高速网络,一般覆盖临近的多个单位和城市。
(3)广域网 (WAN)
又称远程网,它是指覆盖范围广、传输速率相对较低、以数据通信为主要目的的数据通信网。
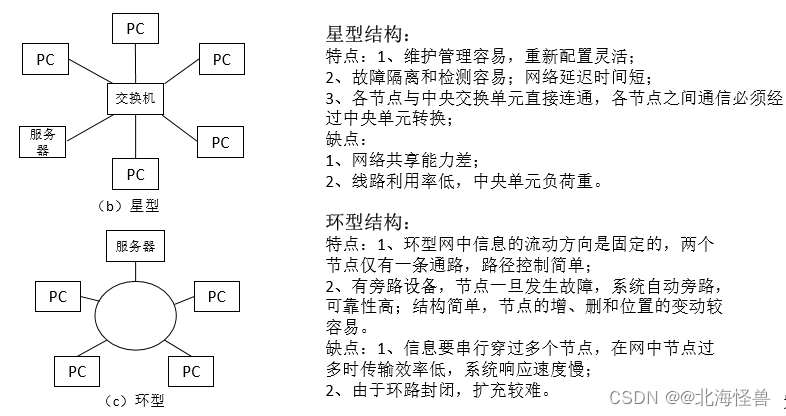
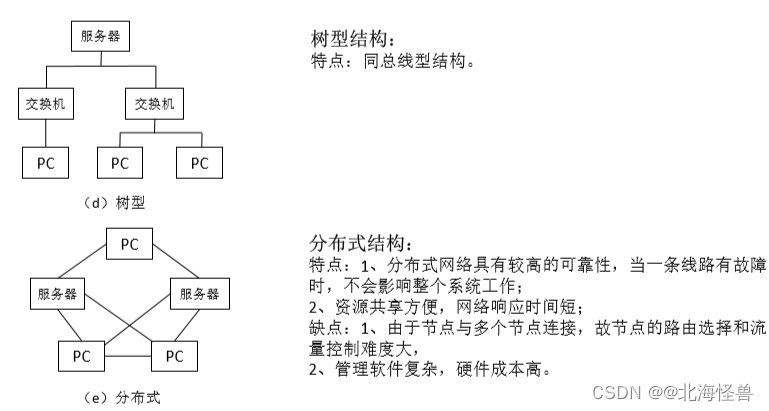
概念:是指网络中通信线路和节点的几何顺序,用以表示整个网络的结构外貌,反映各节点之间的结构关系。
常见的网络拓扑结构有总线型、星型、环型、树型和分布式结构等

路由类型:
当一个Windows 服务器收到一个IP 数据包时,先查找主机路由,再查找网络路由(直连网络和远程网络),这些路由查找失败时,最后才查找默认路由。
| 路由类型 | 说明 |
|---|---|
| 直连网络ID | 用于直接连接网络,Interface(或 next hop)可以为空 |
| 远程网络ID | 用于不直接连接的网络,可以通过其他路由器到达这种网络,Interface字段是本地路由器的 IP 地址 |
| 主机路由 (Host route) |
到达特定主机的路由,子网掩码为255.255.255.255 |
| 默认路由 (Default route) |
无法找到确定路由时使用的路由,目标网络和网络掩码都是0.0.0.0 |
| 持久路由 (Persistent route) |
利用route add -p命令添加的表项,每次初始化时,这种路由都会加入Windows的注册表中,同时加入路由表 |
VLAN的优点:(15年第67题)
允许逻辑地划分网段。
把局域网划分成多个VLAN,使得网络接入不再局限于物理位置的约束,这样就简化了在网络中增加、移除和移动主机的操作,特别是动态的配置VLAN,无论主机在哪里,他都处于自己的VLAN中。
(11年第68题/16年第7题)
总结: (16年第7题)
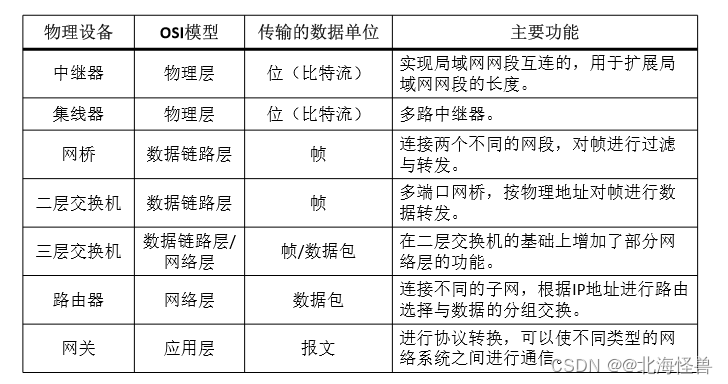
• TCP/IP 协议是Internet 的核心协议,是迄今为止发展最为成熟的互联网络协议 系统。TCP/IP 包含以下五个特性:
(1)逻辑编址。每一台连入互联网的设备都要分配一个IP地址,一个IP地址包 含网络号,子网络号和主机号,因此可以通过IP地址很方便地找到对应的设备。
(2)路由选择。在TCP/IP协议中包含了专门用于定义路由器如何选择网络路径 的协议,即IP数据包的路由选择。
(3)域名解析。为了方便用户记忆,专门设计了一种更方便的字母式地址结构, 称为域名。将域名映射为IP地址的操作,称为域名解析。
(4)错误检测与流量控制。TCP/IP协议可以检测数据信息的传输错误,确认已 传递的数据信息已被成功接收,监测网络系统中的信息流量,防止出现网络拥塞。
1. TCP/IP分层模型
在TCP/IP协议栈中,各层级的数据单元
应用层——消息、报文(message)
传输层——数据段(segment)
网络层——分组、数据包(packet)
链路层——帧(frame)
物理层——比特流
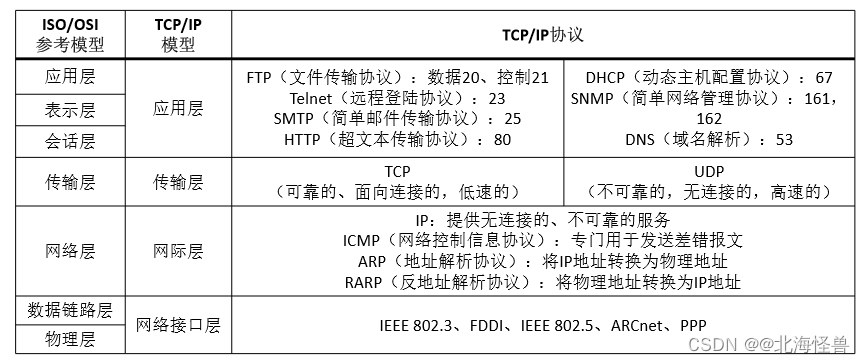
2. 网络接口层协议
3. 网际层协议IP
IP 所提供的服务通常被认为是无连接的和不可靠的,它将差错检测和流量控制之类的服务授权给了其他的各层协议,这正是TCP/IP 能够高效率工作的一个重要保证。
• 其主要功能包括:
(1)将上层数据(TCP/UDP数据)或同层的其他数据(如ICMP数据)封 装到IP数据报中
(2)将IP数据报传送到最终目的地
(3)为了使数据能够在链路层上进行传输对数据进行分段
(4)确定数据报到达其他网络中的目的地的路径
文件传输协议FTP利用TCP 连接在客户机和服务器之间上传和下载文件。FTP 协议占用了两个TCP 端口,FTP 服务器监听21号端口,准备接收用户的连接请求。当用户访问FTP 服务器时便主动与服务器的21号端口建立了控制连接。如果用户要求下载文件,则必须等待服务器的20号端口主动发出建立数据连接的请求,文件传输完成后数据连接随之释放。在客户端看来,这种处理方式被叫做被动式FTP,Windows系统中默认的就是这种处理方式。由于有的防火墙阻止由外向内主动发起的连接请求,所以FTP 数据连接可能由于防火墙的过滤而无法建立。为此有人发明了一种主动式FTP,即数据连接也是由客户端主动请求建立的,但是在服务器中接收数据连接的就不一定是20号端口了。
4. ARP和RARP
ARP协议(地址解析协议)(11年第66-67题)
用来将32位的IP 地址解析为48位的物理地址。
OSI 模型中ARP 协议属于数据链路层,而在TCP/IP 模型中,ARP 协议属于网络层。
RARP 是ARP 的逆过程,将物理地址转化为IP地址
实现IP 地址与MAC 地址之间的变换。
RARP(反向地址解析协议)
主要应用于无盘站,通过该协议从服务器上取得它的IP 地址。网络管理员在局域网网关路由器里创建一个表以映射物理地址(MAC)和对应的IP 地址。当机器启动时,其RARP 客户机程序需要向路由器上的RARP 服务器请求相应的IP地址。假设在路由表中已经设置了一个记录,RARP 服务器将会返回IP 地址给机器,此机器就会存储起来使用。
5. ICMP协议
由于IP协议是一个不可靠、非连接的尽力传送协议,数据报是采用分组交换方式在网络上传送的。因此当路由器不能够选择路由器或传送数据报时,或检测到一个异常条件影响它转发数据报时,就需要通知初始源网点采取措施避免问题。而完成这个任务的机制就是ICMP,它是IP 的一部分,属于网络层协议,其报文是封装在IP 协议数据单元中进行传送的,在网络中起到差错和拥塞控制的作用。
6. 传输层协议TCP
是一种面向连接的、可靠的、基于字节流的传输层通信协议。
TCP为了保证报文传输的可靠,给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失)将会被重传。
TCP三次握手
第一次握手
客户端发送连接请求报文段,将SYN 设置为1,Seq为x;然后,客户端进入SYN_SEND 状态,等待服务器的确认。
第二次握手
服务器收到客户端的SYN 报文段,需要对这个SYN 报文段进行确认,设置ACK 为x+1(Seq + 1);同时,自己还要发送SYN 请求信息,将SYN 置为1,Seq为y;服务器端将上述所有信息放到一个报文段(即SYN + ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态
第三次握手
客户端收到服务器的SYN + ACK 报文段。然后将ACK 设置为y+1,向服务器发送ACK 报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP 三次握手。
7. 传输层协议UDP
UDP (User Datagram Protocol,用户数据报协议)是一种无连接的传输层协议,它主要用于不要求分组顺序到达的传输中,分组传输顺序的检查与排序由应用层完成,提供简单的不可靠的信息传送服务。
UDP 报文没有可靠性保证、顺序保证和流量控制字段等,可靠性较差。但是正因为UDP 协议的控制选项较少,在数据传输过程中延迟小、数据传输效率高,适合对可靠性要求不高的应用程序,或者可以保障可靠性的应用程序,如DNS、TFTP、SNMP等
工作在UDP 协议之上的应用是 VoIP(VoiceOver Internet Protocol)。(13年第47题)
8. 应用层协议
默认情况下,FTP服务器的控制端口为21,数据端口 为20(16年第66题)
电子邮件应用程序利用POP3 协议接收邮件。
POP3 服务默认的TCP 端口号是110.(10年第46题)
域名
(1)域名的格式
• 计算机主机名.本地名.组名.最高层域名
例:www.hust.edu.cn;www.cnnic.net.cn;www.5566.net;www.sina.com
(2)URL 的格式 (15年第68题)
协议://主机.域名[:端口号]/路径/文件名
例:http://210.42.87.56:80/ducument/admin/a1/index.html https://www.abc.com:443/text/a2/login.htm
ftp://ftp.hust.edu.cn/a3/img/b4.jpg
• https 是一种通过计算机网络进行安全通信的传输协议,经由http 进行通信,利用SSL/TLS建立全信道,加密数据包。https 使用的主要目的是提供对网站服务器的身份认证,同时保护交换数据的隐私与完整性。
IP地址
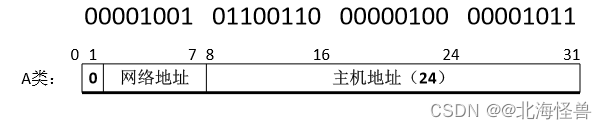
(1)IP地址的格式:一个IP地址占4字节(32位),转成十进制后,为4个十进制数字,中间用 “.” 隔开。每个十进制数字的取值范围为0~255。 129.102.4.11 10000001 01100110 00000100 00001011
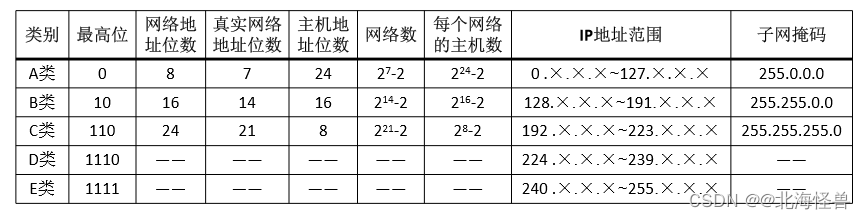
(2)IP地址的分类:IP地址可以分为5类:A类、B类、C类、D类、E类。
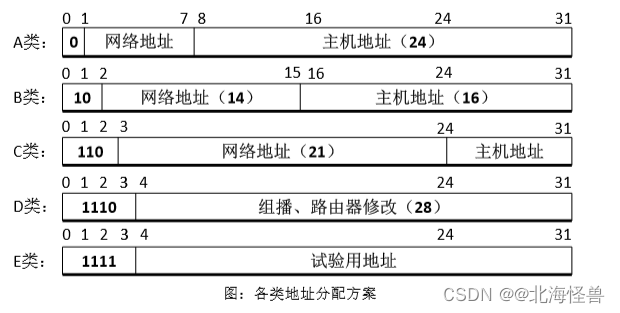
① A类地址:
• 标识方法:最高位为0。
• 真正的网络地址为1-7位(第2至第8位)。
• 那么A类地址的第一个字节的十进制是0127,共支持1126个网络,即共有27-2个 网络号。
• 主机地址为后24位,那么每个网络最多有224-2个主机地址。 • 为何要-2?因为:在IP地址中,全0代表的是网络地址,全1代表的是广播地址, 这两个为特殊用途IP地址,不可作为主机地址使用。
② B类地址:
• 标识方法:最高位为10。
• 真正的网络地址为2-15位(第3至第16位)。
• 那么B类地址的第一个字节的十进制是128~191,共有214-2个网络号。
• 主机地址为后面的16位,那么每个网络最多有216-2个主机地址。

③ C类地址:为我们最常见的IP地址。
• 标识方法:最高位为110。
• 真正的网络地址为3-23位(第4至第24位)。
• 那么C类地址的第一个字节的十进制是192~223,共有221-2个网络号。
• 主机地址为后面的8位,那么每个网络最多有28-2个主机地址。

④ D类地址:标识方法:最高位为1110。
• 用于组播,例如用于路由器修改。D类网络地址第一个字节的十进制为224~239。

⑤ E类地址:标识方法:最高位为1111。
• E类地址为实验保留。D类网络地址第一个字节的十进制为240~255。

NAT技术
IPv6简介
• 现在的IP 协议的版本号为4,所以也称之为IPv4,IPv4 的IP 地址共32位,4个字 节,最多可以有232个IP 地址。
• IPv6 的地址空间为128位,共16个字节,理论上最多可以有2128个IP 地址。
• IPv6 采用冒号十六进制记法。16位为一组,用相应的十六进制表示,各组之间 用 “:” 分隔。
例如:
686E:8C64:FFFF:FFFF:0:1180:96A:FFFF
• 允许0压缩,即一连串的0可以用一对冒号表示,如: FF05:0:0:0:0:0:0:B3 FF05::B3 • IPv6
还可以和IPv4结合使用,如: 0:0:0:0:0:0:128.10.1.1 ::128.10.1.1
HTTPS (Hyper Text Transfer Protocol over Secure Socke Layer) 是以安全为目标的HTTP 通道,使用SSL 协议对报文进行封装。(16年第8题/17年第7题)
• 使用各类Internet服务时,可以使用端口号进行区分,TCP 和UDP 协议的端口号为 16位,支持065535的端口号。其中01023为公共端口,1024~65535需要注册登 记。
(09年第8题)
例:假定用户A、B分别从I1、I2两个CA取得了各自的证书,(I1、I2互换公钥)是AB互信的必要条件。
系统的保护机制应该公开 (21年第10题)
1. 常见的网络攻击技术
(1)篡改消息
是指一个合法消息的某些部分被修改、删除、延迟、重新排序等。
如修改传输消息中的数据,将“允许甲执行操作”改为“允许乙执行操作”。
(2)伪造(伪装、假冒)
是指某个实体假扮成其他实体,从而以欺骗的方式获取一些合法用户的权利和特权。
(3)重放(21年第14题)
是指攻击者发送一个目的主机已接收过的包,来达到欺骗系统的目的, 主要用于身份认证过程,破坏认证的正确性。
♥ 防范重放攻击的方法
① 加时间戳
② 一次一密的方式
(4)拒绝服务 (DOS)(21年上第11题)
是指攻击者不断地对网络服务系统进行干扰,改变其正常的作业流程,执行无关程序使系统响应减慢甚至瘫痪,影响正常用户的使用,甚至使合法用户被排斥而不能进入计算机网络系统或不能得到相应的服务。
注意:拒绝服务攻击并不会造成用户密码的泄露。
① 宽带攻击指以极大的通信量冲击网络,使得所有可用网络资源都被消耗殆尽,最后导致合法的用户请求无法通过。
② 连通性攻击指用大量的连接请求冲击计算机,使得所有可用的操作系统都被消耗殆尽,最终计算机无法再处理合法用户的请求。
③ 分布式拒绝服务攻击DDoS是一种基于DoS的特殊形式的拒绝服务攻击,是一种分布的、协同的大规模攻击方式。
(5)窃听(截取)
是指攻击者在未经用户同意和认可的情况下获得了信息或相关的数据。(被动攻击)
(6)流量分析(通信量分析)
是指攻击者虽然从截获的消息中无法得到消息的真实内容, 但攻击者还是能通过观察这些数据报的模式,分析确定出通信双方的位置、通信的次数及消息的长度,获知相关的敏感信息。
(7)字典攻击
一种破解用户密码或密钥的一种攻击方式。事先将所有可能的密码口令形 成一个列表(字典),在破解密码或密钥时,逐一将字典中的密码口令(或组合)尝试进 行匹配。
(8)社会工程学攻击
是指通过与他人进行合法的交流,来使其心理受到影响,做出某些动作或者是透露一些机密信息的方式。这通常被认为是一种欺诈他人以收集信息、行骗和入侵计算机系统的行为。
(9)SQL注入攻击 (21年上第13题)
把SQL 命令插入Web 表单的输入域或页面的请求查找字符串,欺骗服务器执行恶意的SQL 命令。在某些表单中,用户输入的内容直接用来构造(或者影响)动态 SQL 命令,或作为存储过程的输入参数,这类表单特别容易受到SQL 注入式攻击。
(10)会话劫持
是指攻击者在初始授权之后建立一个连接,在会话劫持以后,攻击者具有合法用户的特权权限。
例如,一个合法用户登录一台主机,当工作完成后, 没有切断主机。然后,攻击者乘机接管,因为主机并不知道合法用户的连接已经断开,于是,攻击者能够使用合法用户的所有权限。典型的实例是“TCP会话劫持”。
(11)漏洞扫描(09年第7题)
是一种自动检测远程或本地主机安全漏洞的软件,通过漏洞扫描器可以自动发现系统的安全漏洞。
通常利用通过端口漏洞扫描来检测远程主机状态,获取权限从而攻击远程主机。(16年第9题)
(12)缓冲区溢出
攻击者利用缓冲区溢出漏洞,将特意构造的攻击代码植入有缓冲区漏洞的程序之中,改变漏洞程序的执行过程,就可以得到被攻击主机的控制权。
2. 主动攻击与被动攻击
(1)主动攻击
主动攻击会导致某些数据流被篡改或者产生虚假的数据流。如:篡改消息、伪造消息、重放和拒绝服务。
(2)被动攻击
与主动攻击不同的是,被动攻击中攻击者并不对数据信息做任何修改, 也不产生虚假的数据流。如窃听、流量分析等攻击方式。
3. 安全的分类
(1)物理安全
物理安全是保护计算机网络设备、设施以及其他媒体免 遭地震、水灾、火灾等环境事故及人为操作失误及各种计算机犯罪行为 导致的破坏。主要是场地安全与机房安全。
(2)网络安全
与网络相关的安全。
(3)系统安全
主要指操作系统的安全。
(4)应用安全
与应用系统相关的安全。
MIME 它是一个互联网标准,扩展了电子邮箱标准,使其能够支持,与安全无关。
PGP(Pretty Good Privacy,优良保密协议),是一套用于信息加密、验证的应用程序。
特洛伊木马 (09年第9题/14年第7题)
通过网络传播的病毒,分为客户端和服务器端两部分,服务器端位于被感染的计算机,客户端是用来控制目标机器的部分,放在攻击者的机器上。特洛伊木马服务器运行后会试图建立网络连接,所以计算机感染特洛伊木马后的典型现象是有未知程序试图建立的网络连接。
“X卧底”
可以窃取手机上的通讯录、呼叫记录、短信记录等隐私数据,还能窃听通话。如果手机上有GPS 功能,“X卧底” 还能调用这项功能获得机主的位置。(13年第8题)
欢乐时光、熊猫烧香、CIH 都是针对计算机的病毒
蜜罐 (21年第12题)
蜜罐就是杀毒软件公司故意用一个防范很差的电脑上网,让它中毒,然后收录到病毒库,这样的杀毒软件就能不断的查杀新出现的病毒,这样引病毒上钩的防范措施就很差的电脑称为蜜罐
蠕虫病毒
不需要宿主程序,它是一段独立的程序或代码,因此也就避免了受宿主程序的牵制,可以不依赖于宿主程序而独立运行,从而主动的实施攻击
防火墙技术 (14年第9题)
防火墙阻挡对网络的非法访问和不安全数据的传递,使得本地系统和网络免于受到许多网络安全威胁。防火墙主要用于逻辑隔离外部网络与受保护的内部网络。
防火墙技术经历了包过滤、应用代理网关和状态检测技术三个发展阶段。
防火墙的性能及特点主要由以下两方面所决定:(14年第8题)
① 工作层次
这是决定防火墙效率及安全的主要因素。一般来说,工作层次越低,则工作效率越高,但安全性就低了;反之,工作层次越高,工作效率越低,则安全性越高。
② 防火墙采用的机制
如果采用代理机制,则防火墙具有内部信息隐藏的特点,相对而言,安全性高,效率低;如果采用过滤机制,则效率高,安全性却降低了
DMZ (Demilitarized zone,隔离区或者非军事化区)
它是为了解决安装防火墙后外部网络不能访问内部网络服务器的问题,而设立的一个非安全系统与安全系统之间的缓冲区,这个缓冲区位于企业内部网络和外部网之间的小网络区域内,在这个小网络区域内可以放置一些必须公开的服务器设施,如企业Web 服务器、FTP 服务器和论坛等。另一方面,通过这样一个DMZ 区域,更加有效地保护了内部网络,因为这种网络部署比起一般的防火墙方案,对攻击者来说又多了一道关卡,因此安全程度从高到低排序为:内网>DMZ>外网(13年第8题)
在IE浏览器中,安全级别最高的区域设置是受限站点。(11年第9题)
其中Internet 区域设置适用于Internet 网站,但不适用于列在受信任和受限制区域的网站;本地Intranet 区域设置适用于在Intranet 中找到的所有网站;可信任站点区域设置适用于你信任的网站;而受限站点区域设置适用于可能会损坏你计算机或文件的网站,它的安全级别高
计算机病毒的分类
文件型:感染可执行文件(包含EXE 和COM 文件)
引导型:影响软盘或硬盘的引导扇区
目录型:修改硬盘上存储的所有文件的地址
宏病毒:某些程序创建的文本文档、数据库、电子表格等文件 (11年第8题)
| 层次 | 层的名称 | 英文 | 主要功能 |
|---|---|---|---|
| 7 | 应用层 | Application Layer | 处理网络应用 |
| 6 | 表示层 | Presentation Layer | 数据表示 |
| 5 | 会话层 | Session Layer | 互连主机通信 |
| 4 | 传输层 | Transport Layer | 端到端连接 |
| 3 | 网络层 | Nework Layer | 分组传输和路由选择 |
| 2 | 数据链路层 | Data Link Layer | 传送以帧为单位的信息 |
| 1 | 物理层 | Physical Layer | 二进制传输 |
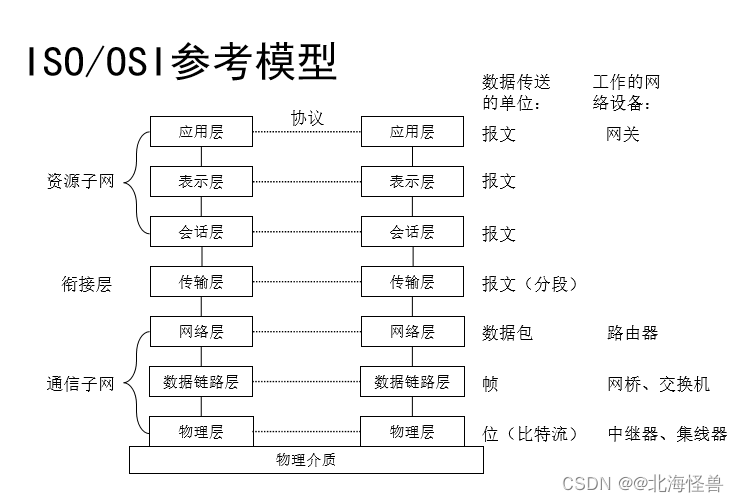
1、物理层
是OSI 参考模型的最低层或第一层。
物理层协议要解决的是主机、工作站等数据端设备与通信线路上通信设备之间的接口问题。
四个特性:
(1) 机械特性
规定了DTE 和DCE 之间的连接形式,包括连接器形状、几何尺寸、引线数目和排列方式等。
(2) 电气特性
规定了发送器和接收器的电气参数及其其他有关电路的特征。电气特性决定了传送速率和传输距离。
(3) 功能特性
接口信号分为数据信号、控制信号和时钟信号。
(4) 规程特性
操作顺序
2、数据链路层
数据链路层工厂把流量控制和差错控制合并在一起。
数据链路层分为MAC(媒介访问控制层)和LLC(逻辑链路控制层)
服务访问点为MAC 地址。
3、网络层
网络层解决对的问题是路由选择、网络拥塞、异构网络互联等问题,其服务访问点为逻辑地址(网络地址)
网络层安全协议:IPSec
4、传输层
服务访问点为端口。
代表协议:TCP、UDP、SPX协议
5、会话层
管理和协调不同主机上各种进程之间的通信,即负责建立、管理和终止应用程序之间的会话。
6、表示层
处理流经结点的数据编码的表示方式问题
7、应用层
直接为端用户服务,提供各类应用程序的接口和用户接口。
例如:HTTP、Telnet、FP、SMTP
数据库安全机制 (11年第46题)
授权机制:指定用户对数据库对象的操作权限
视图机制:通过视图访问而将基本表中视图外的数据对用户屏蔽
数据加密:对存储和传输数据库的数据进行加密
用户标识与鉴别:指用户进入数据库系统时提供自己的身份标识,由系统鉴定为合法用户,只有合法用户才可以进入
(13年第47、48题/16年第28题)
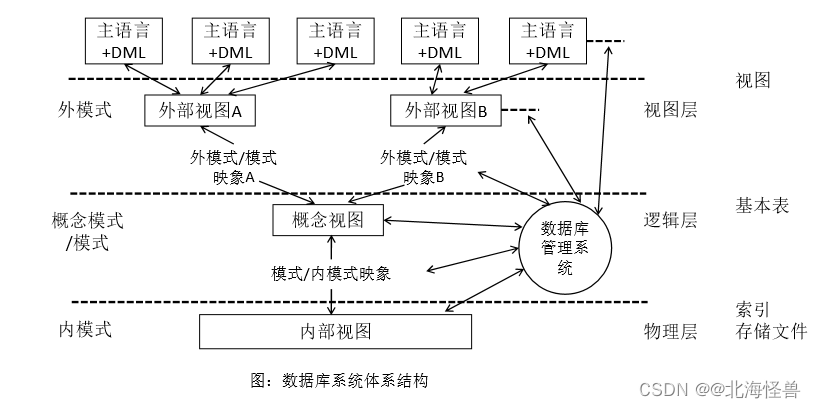
1. 数据抽象
(1)物理层:描述数据在存储器中是如何存储的。
(2)逻辑层:描述数据库中存储什么数据以及这些数据间存在什么关系。
(3)视图层:描述整个数据库的某个部分
2. 数据库的三级模式结构
3. 模式 (10年第23题/11年第28-29题/12年第30-31题/13年第32题/14年第28题)
(1) 模式(概念级)
又称概念模式或逻辑模式。他是由数据库设计者综合所有用户的数据,按照统一的观点构造的全局逻辑结构,是对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图。(逻辑层,基本表)
(2) 外模式(用户级)
又称子模式,它是某个或某几个用户所看到的的数据库视图,是与某一应用有关的数据库结构。(视图层,视图)
(3) 内模式(物理级) (16年第28题)
又称存储模式,它是数据库中全体数据的内部表示或低层描述,是数据库最低一级的逻辑描述,它描述了数据在存储介质上的存储方式和物理结构,对应着实际存储在外存储介质上的数据库。(物理层,存储文件)
4. 两级映像(11年第28-29题/14年第29题/17年第28题)
数据库系统在三级模式之间提供了两级映像:
(1) 模式/内模式的映像:(21年第63题)
该映像存在于概念和内部级之间,实现了概念模式到内模式之间的相互转换。
保证了数据与应用程序的物理独立性,简称数据的物理独立性。
(2) 外模式/模式的映像:
该映像存在于外部级和概念级之间,实现了外模式到概念模式之间的相互转换。
保证了数据与程序的逻辑独立性,简称数据的逻辑独立性。
正因为这两级映射保证了数据库中的数据具有较高的逻辑独立性和物理独立性。数据的独立性是指数据与程序独立,将数据的定义从程序中分离出去,由DBMS 负责数据的存储,从而简化应用程序,大大减少应用程序编制的工作量。
5. 数据的独立性:
(1)数据的物理独立性
它是指当数据库的内模式发生改变时,数据的逻辑结构不变。
(2)数据的逻辑独立性 (17年第28题)
它是指用户的应用程序与数据库的逻辑结构是相互独立的,数据的逻辑结构发生变化后,用户程序也可以不修改,但是,为了程序能够正确执行,需要修改外模式/模式之间的映像。比如重建视图。
1)概念数据模型
也称为信息模型,按用户的观点对数据和信息建模,是现实世界到信息世界的第一层抽象,强调其语义表达功能,易于用户理解
2)基本数据模型
数据模型的三要素:(17年第30题/19年第33题)
(1) 数据结构
(2) 数据操作
(3) 数据约束
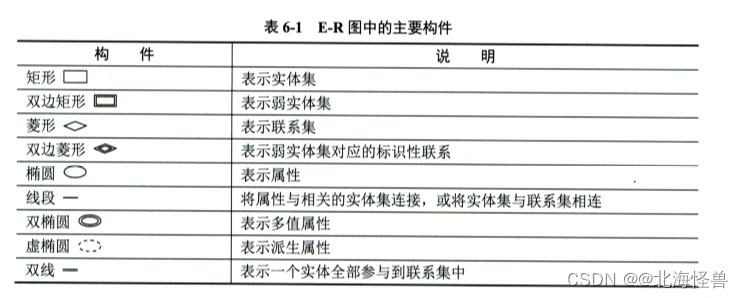
实体-联系(E-R)方法是概念模型中常用的方法,该方法直接从现实世界中抽象出实体和实体间的联系,然后用非常直观的E-R图来表示数据模型。
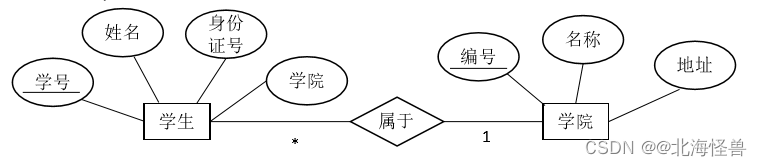

(2)一对多(1: *):一个教师可以教授多门课程,一门课程只能被一位教师讲授。

(3)多对多(* : )(19年第34题)
一个学生可以选修多门课程,一门课程可以由多位学生选修

2)两个以上不同实体集之间的联系 (三元联系)
(1)1:1:1:
(2)1:1::
(3)1:::一个特护病房有多个病人和多个医生, 一个医生只负责一个病房,一个病人只属于一个 病房。
(4):