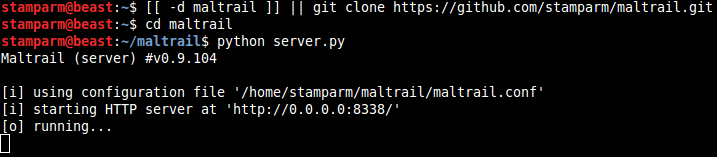
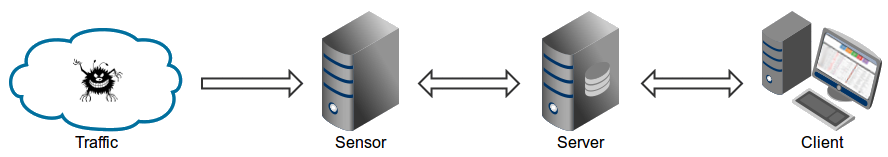maltrail是一款轻量级的恶意流量检测系统,其工作原理是通过采集网络中各个开源黑样本(包括IP、域名、URL),在待检测目标机器上捕获流量并进行恶意流量匹配,匹配成功则在其web页面上展示命中的恶意流量。
aboc, adylkuzz, agaadex, alienspy, almalocker, alureon, android_acecard,
android_adrd, android_alienspy, android_arspam, android_backflash,
android_basebridge, android_boxer, android_chuli, android_claco,
android_coolreaper, android_counterclank, android_cyberwurx,
android_dendoroid, android_dougalek, android_droidjack,
android_droidkungfu, android_enesoluty, android_ewalls, android_ewind,
android_exprespam, android_fakebanco, android_fakedown, android_fakeinst,
android_fakelog, android_fakemart, android_fakemrat, android_fakeneflic,
android_fakesecsuit, android_feabme, android_flexispy, android_frogonal,
android_geinimi, android_ghostpush, android_ginmaster, android_gmaster,
android_godwon, android_golddream, android_gonesixty, android_ibanking,
android_kemoge, android_lockdroid, android_lovetrap, android_maistealer,
android_maxit, android_oneclickfraud, android_opfake,
android_ozotshielder, android_pikspam, android_pjapps, android_qdplugin,
android_repane, android_roidsec, android_samsapo, android_sandorat,
android_selfmite, android_simplocker, android_skullkey, android_sndapps,
android_spytekcell, android_stealer, android_stels, android_teelog,
android_tetus, android_tonclank, android_torec, android_uracto,
android_usbcleaver, android_walkinwat, android_windseeker, android_wirex,
android_xavirad, android_zertsecurity, andromem, androm, angler, anuna,
apt_adwind, apt_aridviper, apt_babar, apt_bisonal, apt_blackenergy,
apt_blackvine, apt_bookworm, apt_carbanak, apt_careto, apt_casper,
apt_chches, apt_cleaver, apt_copykittens, apt_cosmicduke, apt_darkhotel,
apt_darkhydrus, apt_desertfalcon, apt_dragonok, apt_dukes,
apt_equationgroup, apt_fin4, apt_finfisher, apt_gamaredon, apt_gaza,
apt_gref, apt_groundbait, apt_htran, apt_ke3chang, apt_lazarus,
apt_lotusblossom, apt_magichound, apt_menupass, apt_miniduke, apt_naikon,
apt_nettraveler, apt_newsbeef, apt_oceanlotus, apt_pegasus, apt_potao,
apt_quasar, apt_redoctober, apt_russiandoll, apt_sauron, apt_scarletmimic,
apt_scieron, apt_shamoon, apt_snake, apt_snowman, apt_sobaken, apt_sofacy,
apt_stealthfalcon, apt_stonedrill, apt_stuxnet, apt_tibet, apt_turla,
apt_tvrms, apt_volatilecedar, apt_waterbug, apt_weakestlink, apt_xagent,
arec, artro, autoit, avalanche, avrecon, axpergle, azorult, bachosens,
badblock, balamid, bamital, bankapol, bankpatch, banloa, banprox, bayrob,
bedep, blackshades, blockbuster, bredolab, bubnix, bucriv, buterat,
calfbot, camerashy, carbanak, carberp, cerber, changeup, chanitor, chekua,
cheshire, chewbacca, chisbur, cloudatlas, cobalt, conficker, contopee,
corebot, couponarific, criakl, cridex, crilock, cryakl, cryptinfinite,
cryptodefense, cryptolocker, cryptowall, ctblocker, cutwail, defru,
destory, dircrypt, dmalocker, dnsbirthday, dnschanger, dnsmessenger,
dnstrojan, dorifel, dorkbot, dragonok, drapion, dridex, dropnak, dursg,
dyreza, elf_aidra, elf_billgates, elf_darlloz, elf_ekoms, elf_groundhog,
elf_hacked_mint, elf_mayhem, elf_mokes, elf_pinscan, elf_rekoobe,
elf_shelldos, elf_slexec, elf_sshscan, elf_themoon, elf_turla, elf_xnote,
elf_xorddos, elpman, emogen, emotet, evilbunny, expiro, fakben, fakeav,
fakeran, fantom, fareit, fbi_ransomware, fiexp, fignotok, filespider,
findpos, fireball, fraudload, fynloski, fysna, gamarue, gandcrab, gauss,
gbot, generic, glupteba, goldfin, golroted, gozi, hacking_team, harnig,
hawkeye, helompy, hiloti, hinired, immortal, injecto, invisimole,
ios_keyraider, ios_muda, ios_oneclickfraud, ios_specter, ios_xcodeghost,
iron, ismdoor, jenxcus, kegotip, kingslayer, kolab, koobface, korgo,
korplug, kovter, kradellsh, kronos, kulekmoko, locky, lollipop, luckycat,
majikpos, malwaremustdie.org.csv, marsjoke, matsnu, mdrop, mebroot,
mestep, misogow, miuref, modpos, morto, nanocor, nbot, necurs, nemeot,
neshuta, netwire, neurevt, nexlogger, nigelthorn, nivdort, njrat,
nonbolqu, notpetya, nuclear, nuqel, nwt, nymaim, odcodc, oficla, onkods,
optima, osx_keranger, osx_keydnap, osx_mami, osx_mughthesec, osx_salgorea,
osx_wirelurker, padcrypt, palevo, parasite, paycrypt, pdfjsc, pepperat,
pghost, phytob, picgoo, pift, plagent, plugx, ponmocup, poshcoder,
powelike, proslikefan, pushdo, pykspa, qakbot, rajump, ramnit, ransirac,
reactorbot, redsip, remcos, renocide, reveton, revetrat, rincux, rovnix,
runforestrun, rustock, sage, sakurel, sality, satana, sathurbot, satori,
scarcruft, seaduke, sefnit, selfdel, shifu, shimrat, shylock, siesta,
silentbrute, silly, simda, sinkhole_abuse, sinkhole_anubis,
sinkhole_arbor, sinkhole_bitdefender, sinkhole_blacklab,
sinkhole_botnethunter, sinkhole_certgovau, sinkhole_certpl,
sinkhole_checkpoint, sinkhole_cirtdk, sinkhole_conficker,
sinkhole_cryptolocker, sinkhole_drweb, sinkhole_dynadot, sinkhole_dyre,
sinkhole_farsight, sinkhole_fbizeus, sinkhole_fitsec, sinkhole_fnord,
sinkhole_gameoverzeus, sinkhole_georgiatech, sinkhole_gladtech,
sinkhole_honeybot, sinkhole_kaspersky, sinkhole_microsoft, sinkhole_rsa,
sinkhole_secureworks, sinkhole_shadowserver, sinkhole_sidnlabs,
sinkhole_sinkdns, sinkhole_sugarbucket, sinkhole_supportintel,
sinkhole_tech, sinkhole_tsway, sinkhole_unknown, sinkhole_virustracker,
sinkhole_wapacklabs, sinkhole_xaayda, sinkhole_yourtrap,
sinkhole_zinkhole, skeeyah, skynet, skyper, smokeloader, smsfakesky,
snifula, snort.org.csv, sockrat, sohanad, spyeye, stabuniq, synolocker,
tdss, teamspy, teerac, teslacrypt, themida, tinba, torpig, torrentlocker,
troldesh, tupym, unruy, upatre, utoti, vawtrak, vbcheman, vinderuf,
virtum, virut, vittalia, vobfus, vundo, waledac, wannacry, waprox, wecorl,
wecoym, wndred, xadupi, xpay, xtrat, yenibot, yimfoca, zaletelly, zcrypt,
zemot, zeroaccess, zeus, zherotee, zlader, zlob, zombrari, zxshell,
zyklon, etc.