在系统设计的时候,你是否也遇到过这两个问题:
1、大量请求造成数据库压力过大
2、大量数据库查询造成请求执行时间过长
本文将介绍在高并发、大数据环境下,以上两种问题的应对思路。
一、请求合并
首先思考一个场景,在高并发的系统中,在每秒内有大量的请求要访问数据库,如果不考虑缓存,怎么才能够处理降低数据库压力。有的同学可能会说这多简单啊,增加带宽,加内存提升服务器性能。
如果不用这些方法呢?那么就可以用到请求合并的方法,将一段时间内的请求进行合并,然后统一提交查询数据库,能够做到将几十个甚至上百个查询进行批量处理。
当然,这么做也有一个前提,就是这些请求对实时性的要求不能太高。在这个条件下,牺牲一定的处理时间,来减少网络连接数,这么处理是一种性价比非常高的方法。
首先我们模拟一个场景,在不进行合并请求的情况下进行1000次请求,使用Postman进行请求测试,并使用Druid连接池进行数据库的监控:
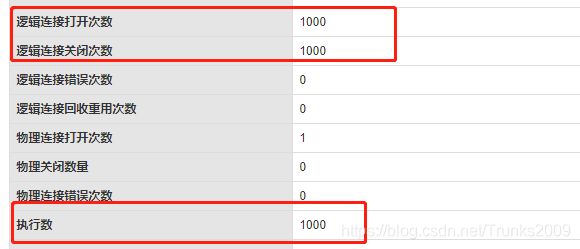
可以看出,实际进行了1000次数据库的访问。在超高流量的情况下,这种访问方式是十分危险的,所以减少数据库的访问就成了当务之急。
再看看之前提到的请求合并,实现起来有这么几个问题需要解决:
1、以什么粒度作为合并请求的规则:
这里推荐按照时间粒度去合并请求,不推荐按照请求数量达到一定值再进行合并是因为有可能一段时间内请求数量比较少,达不到阈值则无法执行,造成早到达的请求等待非常长的时间。
Java中的ScheduledExecutorService提供了定时调度机制,且本身实现了ExecutorService接口,所以本身也支持线程池的所有功能。
2、如何存放一段时间的请求:
存放请求的方式就比较多了,我们知道,在高并发系统的设计中,消息队列被普遍应用于解耦,使用消息队列存放请求是非常合适的做法。由于我们这里是单机环境,能够保证线程安全的阻塞队列LinkedBlockingQueue就能简单实现我们的需求。
3、如何将请求的结果返回给请求
自从JAVA 1.5以后引入了Future接口,用于处理异步调用和并发事务。Future表示一个可能还没有完成的异步任务的结果,针对这个结果可以添加Callback以便在任务执行成功或失败后作出相应的操作。
简单的说,我们可以用它来接收线程的执行结果。
好了,请求的合并、执行、返回三大步骤都梳理清楚了,让我们看看具体怎么实现。
@Service
public class BatchQueryService {
//队列用来存放请求
private LinkedBlockingQueue<Request> queue = new LinkedBlockingQueue<>();
@Autowired
ItemService queryItemService;
//封装请求
class Request {
String code;
CompletableFuture<Map<String, Object>> future;
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public CompletableFuture<Map<String, Object>> getFuture() {
return future;
}
public void setFuture(CompletableFuture<Map<String, Object>> future) {
this.future = future;
}
}
@PostConstruct
public void init() {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(() -> {
int size = queue.size();
if (size == 0)
return;
List<Request> requests = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
Request request = queue.poll();
requests.add(request);
}
System.out.println("批量处理了" + size + "条请求");
List<String> codes = new ArrayList<>();
for (Request request : requests) {
codes.add(request.getCode());
}
List<Map<String, Object>> responses = queryItemService.queryByCodes(codes);
//结果集完成--> 把请求分发给每一个具体的Request
Map<String, Map<String, Object>> responseMap = new HashMap<>();
for (Map<String, Object> response : responses) {
String code = response.get("code").toString();
responseMap.put(code, response);
}
//返回请求
for (Request request : requests) {
Map<String, Object> result = responseMap.get(request.getCode());
request.future.complete(result);
}
}, 0, 200, TimeUnit.MILLISECONDS);
}
//根据code进行单个查询
public Map<String, Object> queryItem(String code) {
Request request = new Request();
request.setCode(code);
CompletableFuture<Map<String, Object>> future = new CompletableFuture<>();
request.setFuture(future);
queue.add(request);
try {
return future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return null;
}
}
使用1000个线程对请求合并方法进行测试:
@ResponseBody
@RequestMapping("/batchQuery")
public String batchQuery(){
Thread thread[]=new Thread[1000];
for (int i = 0; i <1000 ; i++) {
int j=i;
thread[i]=new Thread(new Runnable() {
@Override
public void run() {
queryService.queryItem(j + "");
}
});
thread[i].start();
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return "ok";
}
看一下控制台输出结果:

Druid监控:
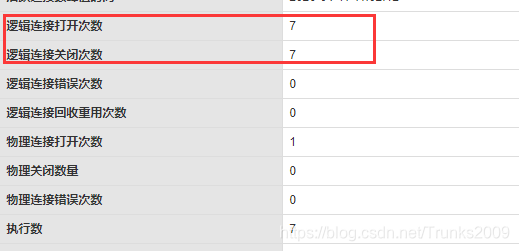
原本1000次的数据库操作被我们减少到了7次,实际对数据库的访问降到了之前的0.7%。当然,实际业务环境中可能定时调度的时间间隔不会增加到200ms这么大,这里只是为了演示一下请求合并能够发挥的巨大潜能。
最后对请求合并进行一下总结:
优点显而易见,通过请求合并减少了数据库的网络连接,降低数据库压力。最大化的利用的系统的IO,来提升系统的吞吐性能。
当然它也存在一定的局限性,仅能够用于对请求实时性要求不高的高并发系统,如果系统的应用场景不是在高并发场景下,那么根本没有使用请求合并的必要。
二、分而治之
其实在学数据结构和算法的时候,大家应该都接触过分而治之的思想,其实说白了就是递归调用本函数的一个过程,在这个过程中,不断把任务变小,简化计算的流程。这种思想,在进行系统架构的时候同样适用。如果一个请求要访问大量的数据,那么我们就可以将这个任务拆分分别执行,最终再将执行结果返回给客户端。
这里就要引入JDK 1.7后提供的一个多线程执行框架Fork/Join,它能够把一个大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果。
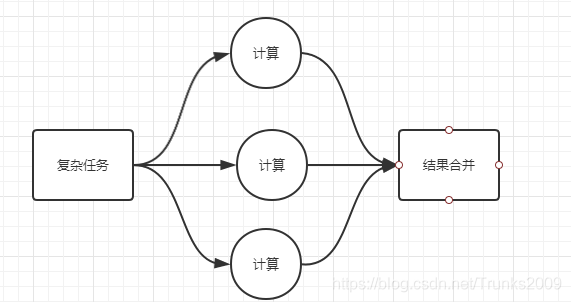
ForkJoin框架为我们提供了RecursiveAction和RecursiveTask来创建ForkJoin的任务,简单来说:
Recursiveaction 用于创建没有返回值的任务
RecursiveTask 用于创建有返回值的任务
举个例子,还是用上一小节中我们的数据,现在数据库中存储了id从0到9999的一万件商品,我们要对其总值进行求和(别问为什么不直接用sum()函数,举个例子而已)。
@ResponseBody
@RequestMapping("/single")
public int single() {
long startTime = System.currentTimeMillis();
int sum = 0;
for (int i = 0; i < 1000; i++) {
sum += itemService.queryByCode(i + "").getPrice();
}
System.out.println(sum);
long endTime = System.currentTimeMillis();
System.out.println("程序运行时间:" + (endTime - startTime) + "ms");
return sum;
}
看一下程序运行时间,5235毫秒:

使用ForkJoin对任务进行划分:
public class ForkJoinTask extends RecursiveTask<Integer> {
private int arr[];
private int start;
private int end;
private static final int MAX = 500;
public ForkJoinTask(int[] arr, int start, int end){
this.arr=arr;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum=0;
if((end - start) < MAX) {
//直接做业务工作
for (int i = start; i < end; i++) {
sum += arr[i];
}
return sum;
} else{
//继续拆分
int middle = (start + end) / 2;
ForkJoinTask left=new ForkJoinTask(arr, start, middle);
ForkJoinTask right=new ForkJoinTask(arr, middle, end);
left.fork();
right.fork();
return left.join() + right.join();
}
}
}
再运行测试:
@ResponseBody
@RequestMapping("/fork")
public int forkJoin() {
long startTime = System.currentTimeMillis();
int arr[] = new int[10000];
for (int i = 0; i < 1000; i++) {
arr[i]=i;
}
ForkJoinPool pool=new ForkJoinPool();
ForkJoinTask task=new ForkJoinTask(arr,0,arr.length);
Integer sum = pool.invoke(task);
System.out.println(sum);
long endTime = System.currentTimeMillis();
System.out.println("程序运行时间:" + (endTime - startTime) + "ms");
return sum;
}
再看一下程序运行时间,只有6毫秒:
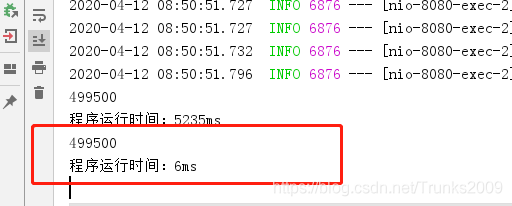
是不是觉得快了很多,直接将运行速度提升了800多倍!其实ForkJoin运行速度快的原因还有一个黑科技,那就是当一个线程在完成自己的任务队列的处理任务后,会帮助其他线程完成任务,完成后再放回其他队列,这也被称为工作窃取。
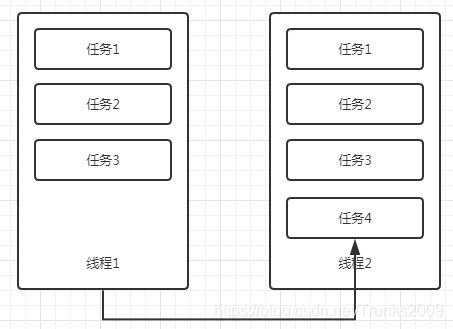
如上图所示,线程1在完成自己的任务后,发现线程2还有任务没有完成,这时它会去取到线程2没有完成的任务,做完后再把结果放回线程2。
除此之外,我们还可以通过增加线程数量进一步加快运行速度,线程数量的选择可以根据具体业务环境进行配置优化。
ForkJoinPool pool=new ForkJoinPool(Runtime.getRuntime().availableProcessors()*4);
总结:
本文分别从请求合并和分而治之两种角度介绍了系统的优化,可以看出,在平常的工作中,代码优化这一条路还有很长要走。文中所有的代码大家可以从我的github获取。
https://github.com/trunks2008/RequestMerge
如果您喜欢这篇文章,欢迎关注订阅我的微信公众号 “码农参上”,不定时发布最新文章
公众号后台回复“面试”获取海量大厂面试资料