- 创建MyUrl.py 编写爬取图片代码
爬取图片,实际上就是对网页信息的读取。而selenium可以很好的做到这一点,相对于beautifulsoup只能爬取静态前端源码的缺点,selenium可以解析由js文件生成的动态网页信息。这篇文章主要拿开源网站https://openi.nlm.nih.gov/作为示例。

很明显,网页信息由js文件动态生成。无法直接使用beautifulsoup获取网页信息。
使用selenium获取网页信息:
driver = webdriver.Chrome()
search_url = "https://openi.nlm.nih.gov/gridquery?q=hand&m=1&n=100"
driver.get(search_url)
此时获得的网页信息也鼠标右键“检查”浏览到的代码一致,而不是“查看页面源代码”。
观察网页信息,找到需要获取的信息。
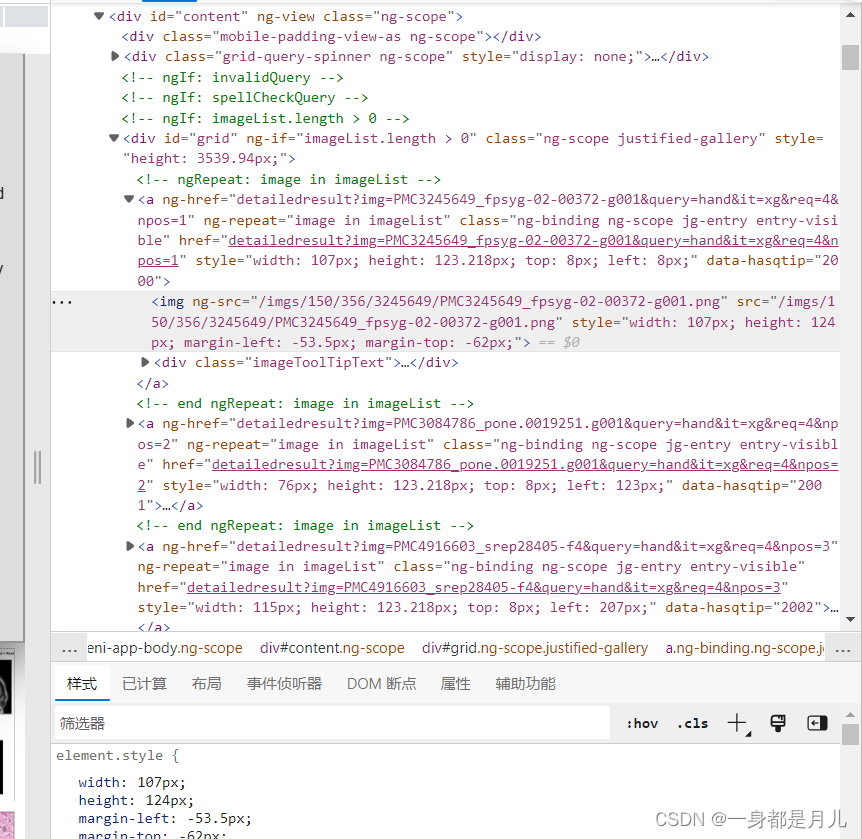
可以看到所有图片都被分到了一个id为“grid”的class下。a标签对则是每个图片的具体信息。如果你想获得缩略图,你就可以直接获取img标签对src的值,这就是缩略图的图像链接。
但是缩略图根本看不清,爬下来没有意义,我们需要做的是获取原图。显然,原图的图像链接并不在这个网页上,一般我们需要点击缩略图的图标跳转到详细信息页面才能看到原图。所以爬取图片也是一样,我们需要先爬取所有详细信息页面的链接,再去所有详细信息页面爬取原图。
在这里,详细信息页面的url就是a标签对中的ng-href的值
driver = webdriver.Chrome()
search_url = "https://openi.nlm.nih.gov/gridquery?q=hand&m=1&n=100"
driver.get(search_url)
time.sleep(3)
tag = driver.find_element(By.ID, "grid").get_attribute("outerHTML")
pattern = re.compile(r'a.*ng-href="(.*?)"')
match = re.findall(pattern, tag)
driver.quit()
关于driver得到的webElement属性的详细内容可以参考:
https://www.jianshu.com/p/cc91666c338d
https://blog.csdn.net/m0_49076971/article/details/126233151
由此可以获取所有详细信息页面url。爬取原图同理。
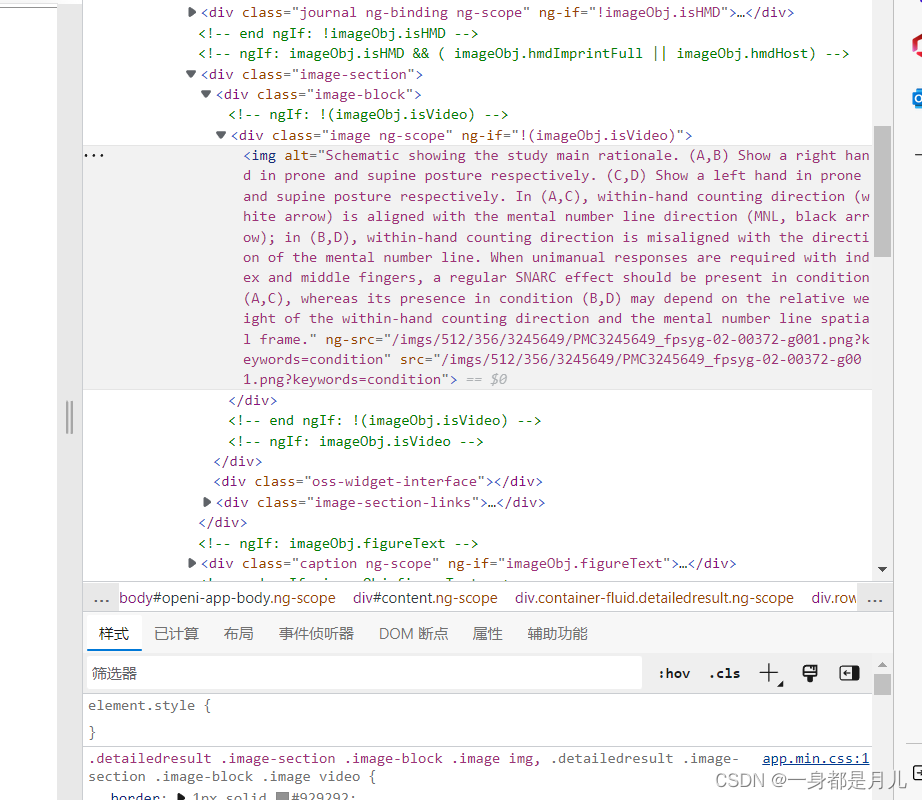
进入原图所在页面。"image.ng-scope"下的ng-src的值就是原图的图像链接。
driver = webdriver.Chrome()
pattern = re.compile(r'img.*ng-src="(.*?)"')
base_url = "https://openi.nlm.nih.gov/"
driver.get(base_url + det)
time.sleep(3)
img_tag = driver.find_element(By.CLASS_NAME, "image.ng-scope").get_attribute("outerHTML")
match = re.findall(pattern, img_tag)
real_url = base_url + match[0]
driver.quit()
下载图片
os.chdir(self.path)
img_name = url.split("/")[-1].split("?")[0]
resp = requests.get(url)
byte = resp.content
with open(img_name, "wb") as f:
f.write(byte)
如果爬取很少图片还勉强可以使用for循环,但是图片数量较大时for循环效率会非常低。因此使用多进程。
pool = Pool(processes=10)
pool.map(img.get_detail, get_page(total))
map()函数。需要传递两个参数,第一个参数就是需要引用的函数,第二个参数是一个可迭代对象,它会把需要迭代的元素一个个的传入第一个参数我们的函数中
详细内容请参考:https://blog.csdn.net/weixin_38819889/article/details/107815272
MyUrl.py 完整源码
import random
import re
import time
import more_itertools
import requests
import os
import sys
from multiprocessing.pool import Pool
from selenium import webdriver
from selenium.webdriver.common.by import By
def get_url(det):
driver = webdriver.Chrome()
pattern = re.compile(r'img.*ng-src="(.*?)"')
base_url = "https://openi.nlm.nih.gov/"
driver.get(base_url + det)
time.sleep(3)
img_tag = driver.find_element(By.CLASS_NAME, "image.ng-scope").get_attribute("outerHTML")
match = re.findall(pattern, img_tag)
real_url = base_url + match[0]
driver.quit()
return real_url
def get_page(tot):
if tot <= 100:
page = [0]
elif 100 < tot <= 1000:
count = int(tot / 100) + 1
page = random.sample(range(0, count), count)
elif 1000 < tot <= 5000:
count = 10
page = random.sample(range(0, count), 10)
else:
page = random.sample(range(0, 51), 10)
return page
def get_path(path):
temp = path.split("/")
real_path = ""
for i in range(0, len(temp)):
real_path += temp[i]
if i != len(temp) - 1:
real_path += "//"
return real_path
class Img:
text = None
path = None
def get_detail(self, index):
driver = webdriver.Chrome()
m = index * 100 + 1
n = m + 99
search_url = "https://openi.nlm.nih.gov/gridquery?q={}&m={}&n={}".format(self.text, m, n)
driver.get(search_url)
time.sleep(3)
tag = driver.find_element(By.ID, "grid").get_attribute("outerHTML")
pattern = re.compile(r'a.*ng-href="(.*?)"')
match = re.findall(pattern, tag)
driver.quit()
return match
def get_img(self, url):
os.chdir(self.path)
img_name = url.split("/")[-1].split("?")[0]
resp = requests.get(url)
byte = resp.content
with open(img_name, "wb") as f:
f.write(byte)
def set_text(self, text):
self.text = text
def set_path(self, path):
self.path = path
if __name__ == '__main__':
inputText = sys.argv[1]
numText = int(sys.argv[2])
total = int(sys.argv[3])
filePath = sys.argv[4]
print(inputText, numText, total, filePath)
img = Img()
img.set_text(inputText)
img.set_path(get_path(filePath))
pool = Pool(processes=10)
try:
detail = list(more_itertools.collapse(pool.map(img.get_detail, get_page(total))))
imgUrl = pool.map(get_url, random.sample(detail, int(numText)))
pool.map(img.get_img, imgUrl)
print("Images download completed!")
pool.close()
pool.join()
except:
print("Something went wrong...[MyUrl.py]")
- main.py完成窗口类
基础内容没什么好说的,信号和槽。主要需要解决的问题有两个,第一个是如果不使用子线程运行耗时任务(爬取图片),主界面会直接卡死(显示未响应,甚至直接卡退)。第二个是怎样调用MyUrl.py中的方法。因为进程池只能写在main函数中(if name == ‘main’:),我尝试通过类名或者创建对象去调用都没能成功,所以只能直接运行py文件,然后通过获取控制台的打印信息来代替返回值(如果大佬有更好的方法欢迎评论区留言)。
子进程的构建:
class MyThread(QThread):
signal_1 = pyqtSignal(str)
def run(self):
if self.flag == 0:
driver = webdriver.Chrome()
driver.get("https://openi.nlm.nih.gov/gridquery?q={}".format(self.text))
time.sleep(3)
try:
total = driver.find_element(By.CLASS_NAME, "regular.ng-binding").text.split()[5]
self.total = total
self.signal_1.emit(total)
except:
message = driver.find_element(By.CLASS_NAME, "no-results.ng-scope").text
self.signal_1.emit(message)
driver.quit()
class MainWidget(QWidget):
def __init__(self, parent=None):
super(MainWidget, self).__init__(parent)
self.thread = MyThread(self)
self.thread.signal_1.connect(self.receive_msg)
def receive_str(self, text):
self.timer.stop()
self.count = 0
self.ui.textEdit.append(text)
self.ui.downBtn.setEnabled(True)
详细内容请参考:https://blog.csdn.net/geji001/article/details/126773317
运行并获取MyUrl.py在控制台的打印信息:
try:
command = "F:\Anaconda3\python.exe C:/Users/Oceans/Desktop/MyImage/MyUrl.py {} {} {} {}".format(
self.text, self.num, self.total, self.file_path)
with os.popen(command, "r") as p:
r = p.read().split("\n")
r.remove('')
print(r)
self.signal_2.emit(r[-1])
except:
self.signal_2.emit("Something went wrong...[main.py]")
os.popen() 方法用于从一个命令打开一个管道。read()方法可以获取到所有打印的信息。由于通过\n进行分割,得到的列表最后一个元素为空,所以再进行remove。
详细内容请参考:https://blog.csdn.net/xc_zhou/article/details/96445422
可能会报错UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xad in position
PyCharm下解决方案:

编码全部调整为GBK即可
还有可能出现报错SyntaxError: Non-UTF-8 code starting with ‘\xc9’ in file…
这是由于文件中出现了中文字符(包括中文注释)
第一种解决方案,将中文全部替换为英文
第二种可以参考 https://www.cnblogs.com/coco2015/p/11203212.html
main.py 完整源码:
import sys
import time
import tkinter as tk
import os
from tkinter import filedialog
from PyQt5.QtCore import QThread, pyqtSignal, QTimer
from selenium.webdriver.common.by import By
from PyQt5 import uic
from PyQt5.QtWidgets import QApplication, QWidget
from selenium import webdriver
class MainWidget(QWidget):
text = None
total = None
num = None
def __init__(self, parent=None):
super(MainWidget, self).__init__(parent)
self.ui = uic.loadUi("./MyUI.ui")
self.thread = MyThread(self)
self.timer = QTimer(self)
self.count = 0
self.ui.searchBtn.clicked.connect(self.search_click)
self.ui.downBtn.clicked.connect(self.download_click)
self.thread.signal_1.connect(self.receive_msg)
self.thread.signal_2.connect(self.receive_str)
self.timer.timeout.connect(self.operate)
def operate(self):
self.count += 1
str_time = str(self.count)
self.ui.timeLabel.setText("Running time: " + str_time + " Seconds")
def search_click(self):
self.timer.start(1000)
self.ui.textEdit.clear()
self.ui.searchBtn.setEnabled(False)
input_edit = self.ui.inputEdit.text()
print(input_edit)
if input_edit != "" and input_edit.isspace() is False:
self.text = self.ui.inputEdit.text()
self.ui.textEdit.setText("Search: {}".format(self.text))
self.ui.textEdit.append("Loading...")
self.thread.get_total(self.text)
self.thread.start()
else:
self.ui.downBtn.setEnabled(False)
self.ui.textEdit.setText("Please enter content")
def receive_msg(self, msg):
self.timer.stop()
self.count = 0
if msg.isnumeric():
self.ui.downBtn.setEnabled(True)
self.ui.textEdit.setText("Search: {}".format(self.text))
self.ui.textEdit.append("Results: {}".format(msg))
self.total = int(msg)
self.ui.searchBtn.setEnabled(True)
else:
self.ui.downBtn.setEnabled(False)
self.ui.searchBtn.setEnabled(True)
self.ui.textEdit.setText('Search: "{}"'.format(self.text))
self.ui.textEdit.append(msg)
def download_click(self):
self.timer.start(1000)
self.ui.downBtn.setEnabled(False)
num_edit = self.ui.numEdit.text()
print(num_edit)
if num_edit.isnumeric():
if int(num_edit) > self.total:
self.ui.textEdit.append("Cannot exceed the total")
self.ui.downBtn.setEnabled(True)
return
elif int(num_edit) > 100:
self.ui.textEdit.append("Up to 100")
self.ui.downBtn.setEnabled(True)
return
root = tk.Tk()
root.withdraw()
file_path = filedialog.askdirectory()
print(file_path)
if file_path == "":
self.ui.downBtn.setEnabled(True)
return
self.ui.textEdit.setText(file_path)
self.num = int(num_edit)
self.ui.textEdit.append("Start crawling images...")
self.thread.get_img(self.num, file_path)
self.thread.start()
else:
self.ui.textEdit.append("Please enter a positive integer")
self.ui.downBtn.setEnabled(True)
def receive_str(self, text):
self.timer.stop()
self.count = 0
self.ui.textEdit.append(text)
self.ui.downBtn.setEnabled(True)
class MyThread(QThread):
signal_1 = pyqtSignal(str)
signal_2 = pyqtSignal(str)
flag = None
text = None
num = None
total = None
file_path = None
def __init__(self, main_form):
super(MyThread, self).__init__()
self.main_form = main_form
def get_total(self, text):
self.text = text
self.flag = 0
def get_img(self, num, file_path):
self.num = num
self.file_path = file_path
self.flag = 1
def run(self):
if self.flag == 0:
driver = webdriver.Chrome()
driver.get("https://openi.nlm.nih.gov/gridquery?q={}".format(self.text))
time.sleep(3)
try:
total = driver.find_element(By.CLASS_NAME, "regular.ng-binding").text.split()[5]
self.total = total
self.signal_1.emit(total)
except:
message = driver.find_element(By.CLASS_NAME, "no-results.ng-scope").text
self.signal_1.emit(message)
driver.quit()
elif self.flag == 1:
try:
command = "F:\Anaconda3\python.exe C:/Users/Oceans/Desktop/DataAcquisition/MyImage/MyUrl.py {} {} {} {}".format(
self.text, self.num, self.total, self.file_path)
with os.popen(command, "r") as p:
r = p.read().split("\n")
r.remove('')
print(r)
self.signal_2.emit(r[-1])
except:
self.signal_2.emit("Something went wrong...[main.py]")
if __name__ == '__main__':
myapp = QApplication(sys.argv)
myWidget = MainWidget()
myWidget.ui.show()
sys.exit(myapp.exec_())
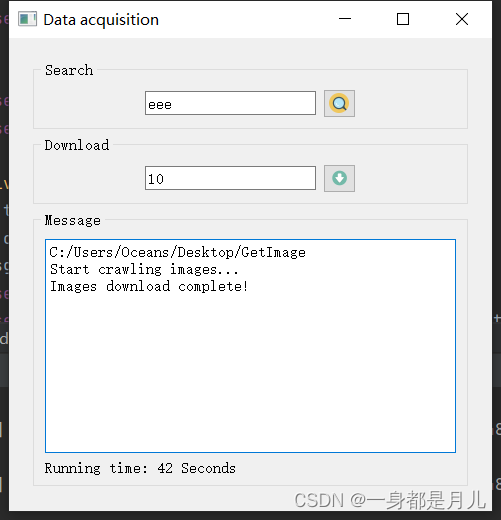
- 运行效果
完整项目(含ui文件):https://download.csdn.net/download/Oceansssss/87173745
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)