聚合模型实际上就是将许多模型聚合在一起,从而使其分类性能更佳。
aggregation models: mix or combine hypotheses (for better performance)
下面举个例子:
你有
T
T
T 朋友,他们对于股票涨停的预测表现为
g
1
,
⋯
,
g
T
g_1,\cdots ,g_T
g1,⋯,gT。 常见的聚合(aggregation)方法有:
学到这里,可能有一种感觉,与模型选择比较相近,并根据直观印象,取平均获得是分类器一定比最好的差,比最差的好。所以会感觉 aggregation 用处不大,那现在看一下, aggregation 的真正的用处是什么?
以下图为例:
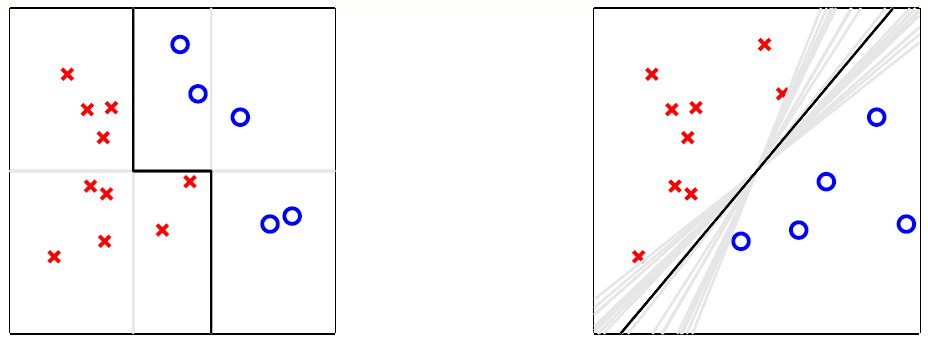
左侧第一个图中,实际上是使用三条竖线或横线实现了二分类,虽然竖线或横线是很弱的一种分类器,但是如此结合便获得了一个较强的分类器,其分类效果好于任何一个分类器独自分类的结果。
右侧第一个图中,是许多直线的取平均值获得的,这种状态存在于数据样本较少时,可以获取一种与SVM类似的效果,虽然这么多直线对于训练样本(采样数据)的分类效果一样,但是对于测试样本(全局数据)可能有更好的分类效果。
所以说真正的 aggregation 并不只是单纯的取平均而已,其可能是为了弥补当前分类器的不足(分类器分类性能较弱,分类器的泛化能力较弱)。即合理的聚合(aggregation)代表了更好的性能(performance)。
用于分类:
数学表达如下:
G ( x ) = sign ( ∑ t = 1 T g t ( x ) ) G(\mathbf{x})=\operatorname{sign} \left( \sum_{t=1}^{T} g_{t}(\mathbf{x}) \right) G(x)=sign(t=1∑Tgt(x))
有 T T T 个人,每人一票。当 g t g_{t} gt 预测值相近,那么性能不变。当 g t g_{t} gt 多样民主时,少数服从多数(majority can correct minority)
在多分类中的数学表达为:
G ( x ) = argmax 1 ≤ k ≤ K ∑ t = 1 T [ [ g t ( x ) = k ] ] G(\mathbf{x})=\underset{1 \leq k \leq K}{\operatorname{argmax}} \sum_{t=1}^{T}\left[\kern-0.15em\left[g_{t}(\mathbf{x})=k\right]\kern-0.15em\right] G(x)=1≤k≤Kargmaxt=1∑T[[gt(x)=k]]
用于回归:
G ( x ) = 1 T ∑ t = 1 T g t ( x ) G(\mathbf{x})=\frac{1}{T} \sum_{t=1}^{T} g_{t}(\mathbf{x}) G(x)=T1t=1∑Tgt(x)
当 g t g_{t} gt 预测值相近,那么性能不变。当 g t g_{t} gt 多样民主时,一些分类结果 g t ( x ) > f ( x ) g_{t}(\mathbf{x})>f(\mathbf{x}) gt(x)>f(x) ,另一些分类结果 g t ( x ) < f ( x ) g_{t}(\mathbf{x})<f(\mathbf{x}) gt(x)<f(x),那么理想状态取平均可以获得最佳解。
综合上述两种需求,多样性的 hypotheses 更容易使得融合模型性能更佳。
现在进行理论分析,其性能是否改善,这里以回归模型为例:
这里的取平均是针对全部的 hypothesis 或者说
T
T
T 个
g
t
g_t
gt 进行的,并针对的是随机的单个样本。
avg
(
(
g
t
(
x
)
−
f
(
x
)
)
2
)
=
avg
(
g
t
2
−
2
g
t
f
+
f
2
)
=
avg
(
g
t
2
)
−
2
G
f
+
f
2
=
avg
(
g
t
2
)
−
G
2
+
(
G
−
f
)
2
=
avg
(
g
t
2
)
−
2
G
2
+
G
2
+
(
G
−
f
)
2
=
avg
(
g
t
2
)
−
2
avg
(
g
t
)
G
+
G
2
+
(
G
−
f
)
2
=
avg
(
g
t
2
−
2
g
t
G
+
G
2
)
+
(
G
−
f
)
2
=
avg
(
(
g
t
−
G
)
2
)
+
(
G
−
f
)
2
\begin{aligned} \operatorname{avg}\left(\left(g_{t}(\mathrm{x})-f(\mathrm{x})\right)^{2}\right) &=\operatorname{avg}\left(g_{t}^{2}-2 g_{t} f+f^{2}\right) \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-2 G f+f^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-G^{2}+(G-f)^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-2 G^{2}+G^{2}+(G-f)^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-2\operatorname{avg}\left(g_{t}\right)G+G^{2}+(G-f)^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}-2 g_{t} G+G^{2}\right)+(G-f)^{2} \\ &=\operatorname{avg}\left(\left(g_{t}-G\right)^{2}\right)+(G-f)^{2} \end{aligned}
avg((gt(x)−f(x))2)=avg(gt2−2gtf+f2)=avg(gt2)−2Gf+f2=avg(gt2)−G2+(G−f)2=avg(gt2)−2G2+G2+(G−f)2=avg(gt2)−2avg(gt)G+G2+(G−f)2=avg(gt2−2gtG+G2)+(G−f)2=avg((gt−G)2)+(G−f)2
也就是说,在对全部训练样本 x n \mathbf{x}_n xn 进行分析取全部误差的平均值。这里 用 E \mathcal{E} E 表示平均值。举个例子: 1 N ∑ n = 1 N ( g t ( x n ) − f ( x n ) ) 2 = E ( g t − f ) 2 \frac{1}{N}\sum_{n = 1}^{N}\left(g_{t}(\mathrm{x}_n)-f(\mathrm{x}_n)\right)^{2} = \mathcal{E}\left(g_{t}-f\right)^{2} N1∑n=1N(gt(xn)−f(xn))2=E(gt−f)2。
avg ( E ( g t − f ) 2 ) = avg ( E ( g t − G ) 2 ) + E ( G − f ) 2 avg ( E out ( g t ) ) = avg ( E ( g t − G ) 2 ) + E out ( G ) ≥ + E out ( G ) \begin{aligned} \operatorname{avg}\left(\mathcal{E}\left(g_{t}-f\right)^{2}\right) &=\operatorname{avg}\left(\mathcal{E}\left(g_{t}-G\right)^{2}\right) & +\mathcal{E}(G-f)^{2}\\ \operatorname{avg}\left(E_{\text {out }}\left(g_{t}\right)\right) &=\operatorname{avg}\left(\mathcal{E}\left(g_{t}-G\right)^{2}\right) &+E_{\text {out }}(G) \\ & \geq & +E_{\text {out }}(G) \end{aligned} avg(E(gt−f)2)avg(Eout (gt))=avg(E(gt−G)2)=avg(E(gt−G)2)≥+E(G−f)2+Eout (G)+Eout (G)
即 G G G 优于 g t g_t gt 的平均值。
现在假设在分布为 P N P^{N} PN (i.i.d.) 的数据上选取大小为 N N N 的数据集 D t \mathcal{D}_{t} Dt,并通过 A ( D t ) \mathcal{A}\left(\mathcal{D}_{t}\right) A(Dt) 获取 g t g_{t} gt。那么执行无数次可以获取到 g ˉ \bar g gˉ,表达式如下:
g ˉ = lim T → ∞ G = lim T → ∞ 1 T ∑ t = 1 T g t = E D A ( D ) \bar{g}=\lim _{T \rightarrow \infty} G=\lim _{T \rightarrow \infty} \frac{1}{T} \sum_{t=1}^{T} g_{t}=\underset{\mathcal{D}}{\mathcal{E}} \mathcal{A}(\mathcal{D}) gˉ=T→∞limG=T→∞limT1t=1∑Tgt=DEA(D)
那么现在用 g ˉ \bar{g} gˉ 代替 G G G,之前所求仍然成立,即:
avg ( E out ( g t ) ) = avg ( E ( g t − g ˉ ) 2 ) + E out ( g ˉ ) \begin{aligned} \operatorname{avg}\left(E_{\text {out }}\left(g_{t}\right)\right) &=\operatorname{avg}\left(\mathcal{E}\left(g_{t}-\bar{g}\right)^{2}\right) &+E_{\text {out }}(\bar{g}) \\ \end{aligned} avg(Eout (gt))=avg(E(gt−gˉ)2)+Eout (gˉ)
其中
用于分类:
数学表达如下:
G ( x ) = sign ( ∑ t = 1 T α t ⋅ g t ( x ) ) with α t ≥ 0 G(\mathbf{x})=\operatorname{sign}\left(\sum_{t=1}^{T} \alpha_{t} \cdot g_{t}(\mathbf{x})\right) \text { with } \alpha_{t} \geq 0 G(x)=sign(t=1∑Tαt⋅gt(x)) with αt≥0
与均值融合相似,有 T T T 个人,但是每人 α t \alpha_t αt 票,而不是都只有一票。
用于回归:
min
α
t
≥
0
1
N
∑
n
=
1
N
(
y
n
−
∑
t
=
1
T
α
t
g
t
(
x
n
)
)
2
\min _{\alpha_{t} \geq 0} \frac{1}{N} \sum_{n=1}^{N}\left(y_{n}-\sum_{t=1}^{T} \alpha_{t} g_{t}\left(\mathbf{x}_{n}\right)\right)^{2}
αt≥0minN1n=1∑N(yn−t=1∑Tαtgt(xn))2
这里重温一下线性回归加非线性转换的结合模型,其数学表达如下:
min w i 1 N ∑ n = 1 N ( y n − ∑ i = 1 d ~ w i ϕ i ( x n ) ) 2 \min _{w_{i}} \frac{1}{N} \sum_{n=1}^{N}\left(y_{n}-\sum_{i=1}^{\tilde{d}} w_{i} \phi_{i}\left(\mathbf{x}_{n}\right)\right)^{2} wiminN1n=1∑N⎝⎛yn−i=1∑d~wiϕi(xn)⎠⎞2
可以看出两种非常相似。
所以说线性融合就是线性回归使用假设函数作为非线性转换工具,并且有约束条件。
那么该最优化问题可以写为:
min
α
t
≥
0
1
N
∑
n
=
1
N
err
(
y
n
,
∑
t
=
1
T
α
t
g
t
(
x
n
)
)
\min _{\alpha_{t} \geq 0} \frac{1}{N} \sum_{n=1}^{N} \operatorname{err}\left(y_{n}, \sum_{t=1}^{T} \alpha_{t} g_{t}\left(\mathbf{x}_{n}\right)\right)
αt≥0minN1n=1∑Nerr(yn,t=1∑Tαtgt(xn))
在实际运用中,常常不用约束条件
α
t
>
0
\alpha_t > 0
αt>0,因为:
if
α
t
<
0
⇒
α
t
g
t
(
x
)
=
∣
α
t
∣
(
−
g
t
(
x
)
)
\text { if } \alpha_{t}<0 \Rightarrow \alpha_{t} g_{t}(\mathbf{x})=\left|\alpha_{t}\right|\left(-g_{t}(\mathbf{x})\right)
if αt<0⇒αtgt(x)=∣αt∣(−gt(x))
也就是说认为
g
t
g_t
gt 的分类错误很高,与预测值常常相反。那么取反便会得到较好性能的分类器。
与模型选择一样,虽然使用训练集获取 g t g_t gt,但是最好使用验证集获取 α t \alpha_t αt。
前面提到的均值融合和线性融合实际上类似于滤波,将预测值乘以一个系数后输出,若将其视为一个模型,那么该模型表达式为 g ~ ( g 1 , g 2 , ⋯ , g T ) = α 1 g 1 + α 2 g 2 + ⋯ + α T g T \tilde g(g_1,g_2,\cdots,g_T) = \alpha_1 g_1 + \alpha_2 g_2 + \cdots + \alpha_T g_T g~(g1,g2,⋯,gT)=α1g1+α2g2+⋯+αTgT。那么 blending 的一般形式便不局限于输入参数的线性组合,可能 g ~ \tilde g g~ 是也是一个 hypothesis。
Given g 1 − , g 2 − , … , g T − g_{1}^{-}, g_{2}^{-}, \ldots, g_{T}^{-} g1−,g2−,…,gT− from D train , \mathcal{D}_{\text {train }}, Dtrain , transform ( x n , y n ) \left(\mathbf{x}_{n}, y_{n}\right) (xn,yn) in D val \mathcal{D}_{\text {val }} Dval to ( z n = Φ − ( x n ) , y n ) , \left(\mathbf{z}_{n}=\Phi^{-}\left(\mathbf{x}_{n}\right), y_{n}\right), (zn=Φ−(xn),yn), where
学习步骤如下:
优缺点:
在 any blending 的基础上,将原来的
g
t
g_t
gt 和
G
G
G 结合在一起再做一次融合。
blending : 在获取
g
t
g_t
gt 之后,进行聚合;
learning : 在聚合(学习)过程中获取
g
t
g_t
gt。
获得多样 g t g_t gt 的方法有:
下面便从数据出发,来满足假设函数的多样性。
那应该怎么做呢,在前面提到有共识便是一个模型的期望表现:
consensus g ˉ = expected g t from D t ∼ P N \text { consensus } \bar { g } = \text { expected } g _ { t } \text { from } \mathcal { D } _ { t } \sim P ^ { N } consensus gˉ= expected gt from Dt∼PN
其优于单个的 g t g_t gt。
其由两个部分组成,一个是无穷多个 g t g_t gt,另一个则是丰富的样本数据。对于第一个问题这里提供有限个但相当多个 g t g_t gt,第二个问题只能从手中的数据入手,来创造多样的样本数据集 D t \mathcal{D}_t Dt。
Bagging 实际上就是指 Bootstrap Aggregation,拔靴法实际上是从手中的数据重采样来获得仿真的 D t \mathcal{D}_t Dt。其实现方法是:
拔靴法(bootstrap aggregation)是一种简单的基于基算法(base algorithm A \mathcal A A)的融合算法(meta algorithm)。方法合理前提是:数据集的多样性和基算法 A \mathcal A A 对于随机数据敏感。
Adaptive Boosting (AdaBoost )实际上是从 Bagging 的核心 bootstrap 出发实现的一种融合算法。具体实现如下:
数据集的构造相当于对于不同样本的权重不同,也就是说重采样(Re-sample)过程相当于重赋予权重(Re-weighting)过程:
假设重采样如下:
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) , ( x 4 , y 4 ) } ⟹ bootstrap D ~ t = { ( x 1 , y 1 ) , ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 4 , y 4 ) } \begin{aligned} \mathcal { D } = \left\{ \left( \mathbf { x } _ { 1 } , y _ { 1 } \right) , \left( \mathbf { x } _ { 2 } , y _ { 2 } \right) , \left( \mathbf { x } _ { 3 } , y _ { 3 } \right) , \left( \mathbf { x } _ { 4 } , y _ { 4 } \right) \right\} \\ \stackrel { \text { bootstrap } } { \Longrightarrow } \tilde { \mathcal { D } } _ { t } = \left\{ \left( \mathbf { x } _ { 1 } , y _ { 1 } \right) , \left( \mathbf { x } _ { 1 } , y _ { 1 } \right) , \left( \mathbf { x } _ { 2 } , y _ { 2 } \right) , \left( \mathbf { x } _ { 4 } , y _ { 4 } \right) \right\} \end{aligned} D={(x1,y1),(x2,y2),(x3,y3),(x4,y4)}⟹ bootstrap D~t={(x1,y1),(x1,y1),(x2,y2),(x4,y4)}
原来的误差计算如下:
E
i
n
0
/
1
(
h
)
=
1
4
∑
(
x
,
y
)
∈
D
~
t
[
[
y
≠
h
(
x
)
]
]
E _ { \mathrm { in } } ^ { 0 / 1 } ( h ) = \frac { 1 } { 4 } \sum _ { ( \mathbf { x } , y ) \in \tilde { D } _ { t } } \left[\kern-0.15em\left[ y \neq h ( \mathbf { x } ) \right]\kern-0.15em\right]
Ein0/1(h)=41(x,y)∈D~t∑[[y=h(x)]]
现在则是:
E i n u ( t ) ( h ) = 1 4 ∑ n = 1 4 u n ( t ) ⋅ [ [ y n ≠ h ( x n ) ] ] E _ { \mathrm { in } } ^ { \mathrm { u }^{(t)} } ( h ) = \frac { 1 } { 4 } \sum _ { n = 1 } ^ { 4 } u _ { n } ^ { ( t ) } \cdot \left[\kern-0.15em\left[ y _ { n } \neq h \left( \mathbf { x } _ { n } \right) \right]\kern-0.15em\right] Einu(t)(h)=41n=1∑4un(t)⋅[[yn=h(xn)]]
其中 u 1 = 2 , u 2 = 1 , u 3 = 0 , u 4 = 1 u_1 = 2,u_2 = 1,u_3 = 0,u_4 = 1 u1=2,u2=1,u3=0,u4=1。
那么袋中的每一个 g t g_t gt 都是通过最小化加权误差(bootstrap-weighted error)获得的。
所以加权基算法(Weighted Base Algorithm)的数学表达为:
E i n u ( h ) = 1 N ∑ n = 1 N u n ⋅ err ( y n , h ( x n ) ) E _ { \mathrm { in } } ^ { \mathrm { u } } ( h ) = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } u _ { n } \cdot \operatorname { err } \left( y _ { n } , h \left( \mathbf { x } _ { n } \right) \right) Einu(h)=N1n=1∑Nun⋅err(yn,h(xn))
那么通过重新赋值获取多样的 g t g_t gt 是另一种可行的方法:
假如两个
g
t
g_t
gt 的获取方法如下:
g
t
←
argmin
h
∈
H
(
∑
n
=
1
N
u
n
(
t
)
[
[
y
n
≠
h
(
x
n
)
]
]
)
g
t
+
1
←
argmin
h
∈
H
(
∑
n
=
1
N
u
n
(
t
+
1
)
[
[
y
n
≠
h
(
x
n
)
]
]
)
\begin{aligned} g _ { t } & \leftarrow \underset { h \in \mathcal { H } } { \operatorname { argmin } } \left( \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t ) } \left[ \kern-0.15em \left[ y _ { n } \neq h \left( \mathbf { x } _ { n } \right) \right]\kern-0.15em\right] \right) \\ g _ { t + 1 } & \leftarrow \underset { h \in \mathcal { H } } { \operatorname { argmin } } \left( \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } \left[ \kern-0.15em \left[ y _ { n } \neq h \left( \mathbf { x } _ { n } \right) \right]\kern-0.15em\right] \right) \end{aligned}
gtgt+1←h∈Hargmin(n=1∑Nun(t)[[yn=h(xn)]])←h∈Hargmin(n=1∑Nun(t+1)[[yn=h(xn)]])
什么时候两个人分类器会很不一样呢?就是当 g t g_t gt 对于权重 u n ( t ) u _ { n } ^ { ( t ) } un(t) 的性能很好,但是 g t g_t gt 对于权重 u n ( t + 1 ) u _ { n } ^ { ( t + 1) } un(t+1) 的性能很差,最差的 g g g 则是随机值也就是说有 50% 的概率会预测准确。即:
∑ n = 1 N u n ( t + 1 ) [ [ y n ≠ g t ( x n ) ] ] ∑ n = 1 N u n ( t + 1 ) = 1 2 \frac {\sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } \left[ \kern-0.15em \left[y _ { n } \neq g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] } { \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } } = \frac { 1 } { 2 } ∑n=1Nun(t+1)∑n=1Nun(t+1)[[yn=gt(xn)]]=21
所以现在希望的效果是:
∑ n = 1 N u n ( t + 1 ) [ [ y n ≠ g t ( x n ) ] ] ∑ n = 1 N u n ( t + 1 ) = □ t + 1 □ t + 1 + ◯ t + 1 = 1 2 , where □ t + 1 = ∑ n = 1 N u n ( t + 1 ) [ [ y n ≠ g t ( x n ) ] ] ◯ t + 1 = ∑ n = 1 N u n ( t + 1 ) [ [ y n = g t ( x n ) ] ] \frac {\sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } \left[ \kern-0.15em \left[y _ { n } \neq g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] } { \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } } = \frac { \square_ { t + 1 } } { \square_ { t + 1 } + \bigcirc_{ t + 1 } } = \frac { 1 } { 2 } , \text { where } \\ \square_ { t + 1 } = \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } \left[ \kern-0.15em \left[y _ { n } \neq g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right]\\ \bigcirc_{ t + 1 } = \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } \left[ \kern-0.15em \left[y _ { n } = g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] ∑n=1Nun(t+1)∑n=1Nun(t+1)[[yn=gt(xn)]]=□t+1+◯t+1□t+1=21, where □t+1=n=1∑Nun(t+1)[[yn=gt(xn)]]◯t+1=n=1∑Nun(t+1)[[yn=gt(xn)]]
那么通过重新放缩权重(re-scaling (multiplying) weights)便可以实现,即:
对于 g t g_t gt 分类错误的样本:
u n ( t + 1 ) = ◯ t ⋅ u n ( t ) u _ { n } ^ { ( t + 1 ) } = \bigcirc_{ t } \cdot u _ { n } ^ { ( t ) } un(t+1)=◯t⋅un(t)
对于 g t g_t gt 分类正确的样本:
u n ( t + 1 ) = □ t ⋅ u n ( t ) u _ { n } ^ { ( t + 1 ) } = \square_{ t } \cdot u _ { n } ^ { ( t ) } un(t+1)=□t⋅un(t)
那么在实际中如何实现呢?这里提出放缩系数。
错误率
ϵ
t
\epsilon _ { t }
ϵt 定义如下:
ϵ
t
=
∑
n
=
1
N
u
n
(
t
)
[
[
y
n
≠
g
t
(
x
n
)
]
]
∑
n
=
1
N
u
n
(
t
)
\epsilon _ { t } = \frac {\sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t ) } \left[ \kern-0.15em \left[y _ { n } \neq g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] } { \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t) } }
ϵt=∑n=1Nun(t)∑n=1Nun(t)[[yn=gt(xn)]]
放缩系数的定义如下:
⋆
t
=
1
−
ϵ
t
ϵ
t
\mathbf { \star } _ { t } = \sqrt { \frac { 1 - \epsilon _ { t } } { \epsilon _ { t } } }
⋆t=ϵt1−ϵt
那么:
[ [ y n ≠ g t ( x n ) ] ] u n ( t + 1 ) ← u n ( t ) ⋅ ⋆ t [ [ y n = g t ( x n ) ] ] u n ( t + 1 ) ← u n ( t ) / ⋆ t \begin{aligned} \left[ \kern-0.15em \left[y _ { n } \neq g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] \quad u ^ { ( t + 1 ) } _ n &\leftarrow u ^ { ( t ) } _ n \cdot \mathbf { \star } _ { t } \\ \left[ \kern-0.15em \left[y _ { n } = g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] \quad u ^ { ( t + 1 ) } _ n &\leftarrow u ^ { ( t ) } _n / \mathbf { \star } _ { t } \end{aligned} [[yn=gt(xn)]]un(t+1)[[yn=gt(xn)]]un(t+1)←un(t)⋅⋆t←un(t)/⋆t
有了上述的前提,便可以设计一个由数据多样化创造的融合算法,而AdaBoost 除了上述一些前提外,还有一步,那就是 Linear Aggregation on the Fly,在学习中获得线性融合的参数 α t \alpha_t αt,即:
α t = ln ( ⋆ t ) \alpha_t = \ln(\mathbf { \star } _ { t }) αt=ln(⋆t)
u
(
1
)
=
[
1
N
,
⋯
,
1
N
]
u^{(1)} = \left[\frac{1}{N},\cdots,\frac{1}{N}\right]
u(1)=[N1,⋯,N1]
for
t
=
1
,
⋯
,
T
t = 1,\cdots,T
t=1,⋯,T
由 A ( D , u ( t ) ) \mathcal { A } \left( \mathcal { D } , \mathbf { u } ^ { ( t ) } \right) A(D,u(t)) 获取 g t g _ { t } gt , 其中 A \mathcal { A } A 用于优化权重为 u ( t ) \mathbf { u } ^ { ( t ) } u(t) 的加权误差。
由
u
(
t
)
\mathbf { u } ^ { ( t ) }
u(t) 更新
u
(
t
+
1
)
\mathbf { u } ^ { ( t+1 ) }
u(t+1)
[
[
y
n
≠
g
t
(
x
n
)
]
]
u
n
(
t
+
1
)
←
u
n
(
t
)
⋅
⋆
t
[
[
y
n
=
g
t
(
x
n
)
]
]
u
n
(
t
+
1
)
←
u
n
(
t
)
/
⋆
t
\begin{aligned} \left[ \kern-0.15em \left[y _ { n } \neq g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] \quad u ^ { ( t + 1 ) } _ n &\leftarrow u ^ { ( t ) } _ n \cdot \mathbf { \star } _ { t } \\ \left[ \kern-0.15em \left[y _ { n } = g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] \quad u ^ { ( t + 1 ) } _ n &\leftarrow u ^ { ( t ) } _n / \mathbf { \star } _ { t } \end{aligned}
[[yn=gt(xn)]]un(t+1)[[yn=gt(xn)]]un(t+1)←un(t)⋅⋆t←un(t)/⋆t
其中: ϵ t = ∑ n = 1 N u n ( t + 1 ) [ [ y n ≠ g t ( x n ) ] ] ∑ n = 1 N u n ( t + 1 ) \epsilon _ { t } = \frac {\sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } \left[ \kern-0.15em \left[y _ { n } \neq g _ { t } \left( \mathbf { x } _ { n } \right) \right] \kern-0.15em \right] } { \sum _ { n = 1 } ^ { N } u _ { n } ^ { ( t + 1 ) } } ϵt=∑n=1Nun(t+1)∑n=1Nun(t+1)[[yn=gt(xn)]], ⋆ t = 1 − ϵ t ϵ t \mathbf { \star } _ { t } = \sqrt { \frac { 1 - \epsilon _ { t } } { \epsilon _ { t } } } ⋆t=ϵt1−ϵt
计算线性融合系数 α t = ln ( ⋆ t ) \alpha_t = \ln(\mathbf { \star } _ { t }) αt=ln(⋆t)
获得最终hypothesis: G ( x ) = sign ( ∑ t = 1 T α t g t ( x ) ) G ( \mathbf { x } ) = \operatorname { sign } \left( \sum _ { t = 1 } ^ { T } \alpha _ { t } g _ { t } ( \mathbf { x } ) \right) G(x)=sign(∑t=1Tαtgt(x))
AdaBoost 的 VC bound 如下:
E
o
u
t
(
G
)
≤
E
i
n
(
G
)
+
O
(
O
(
d
v
c
(
H
)
⋅
T
log
T
)
⏟
d
v
c
of all possible
G
⋅
log
N
N
)
E _ { \mathrm { out } } ( G ) \leq E _ { \mathrm { in } } ( G ) + O ( \sqrt { \underbrace { O \left( d _ { \mathrm { vc } } ( \mathcal { H } ) \cdot T \log T \right) }_{d_{\mathbf{vc}} \text{ of all possible } G} \cdot \frac { \log N } { N } } )
Eout(G)≤Ein(G)+O(dvc of all possible G
O(dvc(H)⋅TlogT)⋅NlogN
)
原作者有证明最多经过 T = log ( N ) T= \log(N) T=log(N) 次迭代,便可以实现 E in ( G ) = 0 E_{\text{in}}(G) = 0 Ein(G)=0,只要基模型比随机数性能优越即可 ϵ t ≤ ϵ < 1 2 \epsilon _ { t } \leq \epsilon < \frac { 1 } { 2 } ϵt≤ϵ<21。
也就是说,如果基模型 g g g 很弱(weak),但是总比随机数优秀,那么由AdaBoost + A \mathcal A A 获取的 G G G 也会很强(strong)。
数学表达如下:
h
s
,
i
,
θ
(
x
)
=
s
⋅
sign
(
x
i
−
θ
)
h _ { s , i , \theta } ( \mathbf { x } ) = s \cdot \operatorname { sign } \left( x _ { i } - \theta \right)
hs,i,θ(x)=s⋅sign(xi−θ)
一共有三个参数 特征(feature) i i i,阈值(threshold) θ \theta θ ,方向(direction) s s s。其实现的功能便是一个分界点,特征(feature) i i i 表达的是在第 i i i 维的分解点,阈值(threshold) θ \theta θ 代表在本维度的分界点位于 θ \theta θ,方向(direction) s s s 代表了分界点两边的样本类型。
这是一个弱模型,但是将其作为 AdaBoost 的基模型便可以实现高精度预测了,并且效率很高,时间复杂度为: O ( d ⋅ N log N ) O(d \cdot N \log N) O(d⋅NlogN)
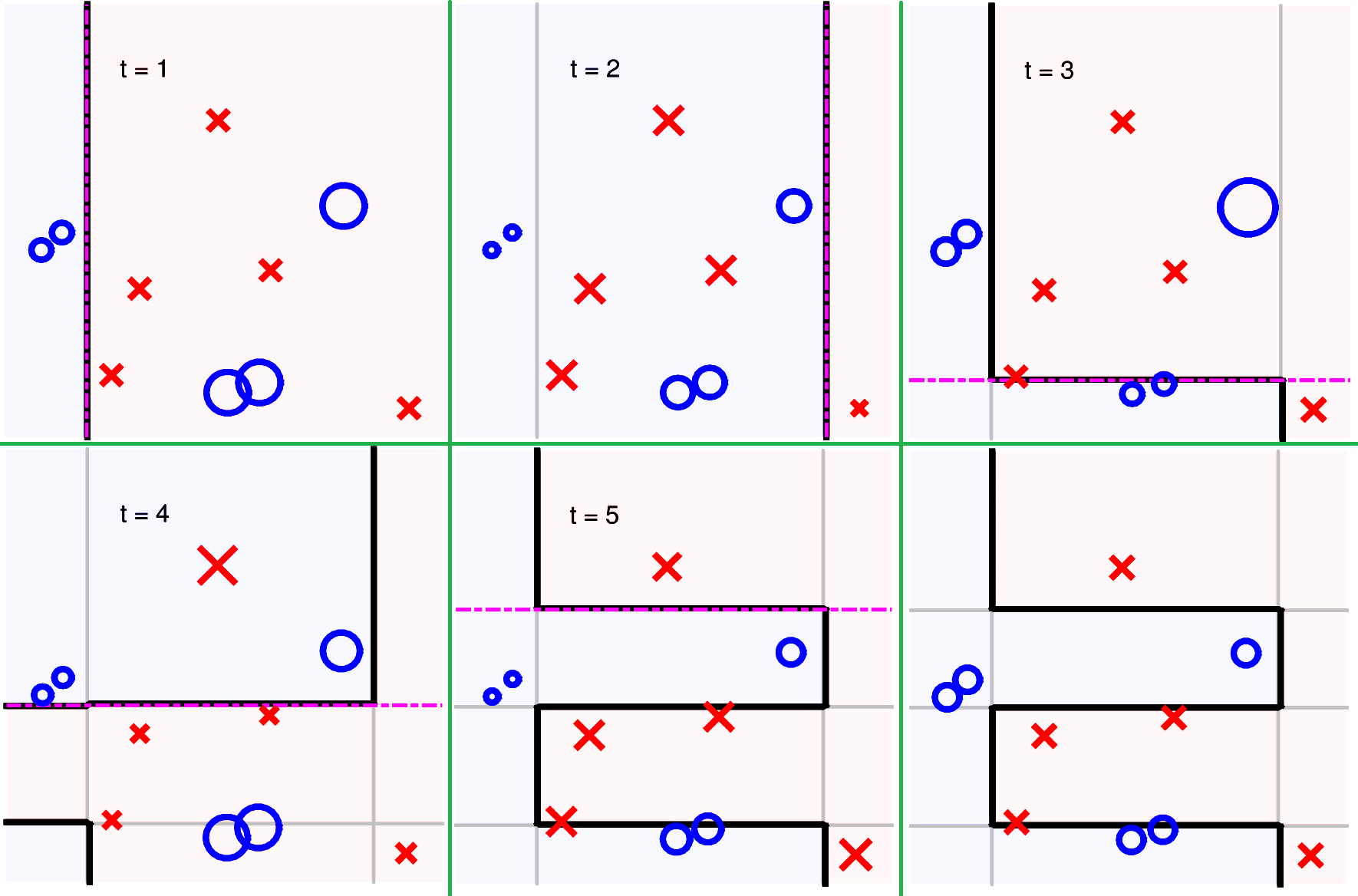
若使用 Decision Stump 作为 AdaBoost 的基模型,假设一个简单的数据集如下分布:
那么其学习过程的一种状态可能如下表达: