本篇博客的目的是:
将下图这样的输入(每个tensor表示一个句子,01为句子标签):
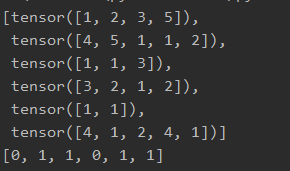
转化为下图所示的输出(batch_size=2)
元组的第一个元素为填充后的句子向量,第二个元素为句子长度,第三个元素为句子的label。

为什么需要这样的处理?
如果需要使用RNN模型处理序列数据,肯定不能将变长的序列直接输入模型,所以需要在输入前对其进行填充。这里需要注意的是,在有些情况下,输入数据不仅需要填充,并且需要在数据传送过程中记录句子的原始长度,例如在RNN中,如果句子长度差别较大,例如最大长度是50,但大多数句子长度<10,这样会导致很多句子中有很多填充的0,这会导致最后得到的hn是相同的。
第一步:建立Dataset
class SentenceDataSet(Dataset):
def __init__(self, sent, sent_label):
self.sent = sent
self.sent_label = sent_label
def __getitem__(self, item):
return self.sent[item], self.sent_label[item]
def __len__(self):
return len(self.sent)
dataset = SentenceDataSet(x, y)
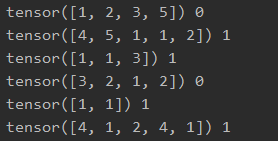
for xi, yi in dataset:
print(xi, yi)
输出为:
第二步:建立DataLoader
在建立dataloader时需要注意:默认情况下dataloader会将batch中的所有数据条目的各个维度的数据直接进行拼接,由于在本博客的例子中句子序列的长度不相等,不能直接拼接,所以下面通过自己实现collate_fn函数自定义batch中的多个数据条目的组织方式。
def collate_fn(batch_data):
"""
自定义 batch 内各个数据条目的组织方式
:param data: 元组,第一个元素:句子序列数据,第二个元素:长度 第2维:句子标签
:return: 填充后的句子列表、实际长度的列表、以及label列表
"""
batch_data.sort(key=lambda xi: len(xi[0]), reverse=True)
data_length = [len(xi[0]) for xi in batch_data]
sent_seq = [xi[0] for xi in batch_data]
label = [xi[2] for xi in batch_data]
padded_sent_seq = pad_sequence(sent_seq, batch_first=True, padding_value=0)
return padded_sent_seq, data_length, torch.tensor(y, dtype=torch.float32)
data_loader = DataLoader(dataset, batch_size=2, collate_fn=collate_fn)
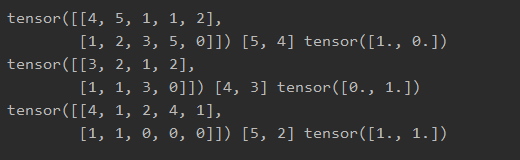
for data in data_loader:
print(data)
输出:
参考链接
pytorch dataloader官方教程
博客:处理LSTM+embedding变长序列
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)