一、协程(Coroutine)简介
协程,又称微线程,纤程。英文名Coroutine。
协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。
比如子程序A、B:def A():
print '1'
print '2'
print '3'
def B():
print 'x'
print 'y'
print 'z'
假设由协程执行,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:
1
2
x
y
3
z
但是在A中是没有调用B的,所以协程的调用比函数调用理解起来要难一些。
看起来A、B的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持还非常有限,用在generator中的yield可以一定程度上实现协程。虽然支持不完全,但已经可以发挥相当大的威力了。
来看例子:
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:import time
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
time.sleep(1)
r = '200 OK'
def produce(c):
c.next()
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
if __name__=='__main__':
c = consumer()
produce(c)
执行结果:
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator(生成器),把一个consumer传入produce后:
首先调用c.next()启动生成器;
然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
consumer通过yield拿到消息,处理,又通过yield把结果传回;
produce拿到consumer处理的结果,继续生产下一条消息;
produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
二、C/C++ 协程
首先需要声明的是,这里不打算花时间来介绍什么是协程,以及协程和线程有什么不同。如果对此有任何疑问,可以自行 google。与 Python 不同,C/C++ 语言本身是不能天然支持协程的。现有的 C++ 协程库均基于两种方案:利用汇编代码控制协程上下文的切换,以及利用操作系统提供的 API 来实现协程上下文切换。典型的例如:
libco,Boost.context:基于汇编代码的上下文切换
phxrpc:基于 ucontext/Boost.context 的上下文切换
libmill:基于 setjump/longjump 的协程切换
一般而言,基于汇编的上下文切换要比采用系统调用的切换更加高效,这也是为什么 phxrpc 在使用 Boost.context 时要比使用 ucontext 性能更好的原因。关于 phxrpc 和 libmill 具体的协程实现方式,以后有时间再详细介绍。

交流讨论领取资料看这里
三、libco 协程的创建和切换
在介绍 coroutine 的创建之前,我们先来熟悉一下 libco 中用来表示一个 coroutine 的数据结构,即定义在 co_routine_inner.h 中的 stCoRoutine_t:
struct stCoRoutine_t
{
stCoRoutineEnv_t *env; // 协程运行环境
pfn_co_routine_t pfn; // 协程执行的逻辑函数
void *arg; // 函数参数
coctx_t ctx; // 保存协程的下文环境
...
char cEnableSysHook; // 是否运行系统 hook,即非侵入式逻辑
char cIsShareStack; // 是否在共享栈模式
void *pvEnv;
stStackMem_t* stack_mem; // 协程运行时的栈空间
char* stack_sp; // 用来保存协程运行时的栈空间
unsigned int save_size;
char* save_buffer;
};
我们暂时只需要了解表示协程的最简单的几个参数,例如协程运行环境,协程的上下文环境,协程运行的函数以及运行时栈空间。后面的 stack_sp,save_size 和 save_buffer 与 libco 共享栈模式相关,有关共享栈的内容我们后续再说。

交流讨论领取资料看这里
四、协程创建和运行
由于多个协程运行于一个线程内部的,因此当创建线程中的第一个协程时,需要初始化该协程所在的环境 stCoRoutineEnv_t,这个环境是线程用来管理协程的,通过该环境,线程可以得知当前一共创建了多少个协程,当前正在运行哪一个协程,当前应当如何调度协程:
struct stCoRoutineEnv_t
{
stCoRoutine_t *pCallStack[ 128 ]; // 记录当前创建的协程
int iCallStackSize; // 记录当前一共创建了多少个协程
stCoEpoll_t *pEpoll; // 该线程的协程调度器
// 在使用共享栈模式拷贝栈内存时记录相应的 coroutine
stCoRoutine_t* pending_co;
stCoRoutine_t* occupy_co;
};
上述代码表明 libco 允许一个线程内最多创建 128 个协程,其中 pCallStack[iCallStackSize-1] 也就是栈顶的协程表示当前正在运行的协程。当调用函数 co_create 时,首先检查当前线程中的 coroutine env 结构是否创建。这里 libco 对于每个线程内的 stCoRoutineEnv_t 并没有使用 thread-local 的方式(例如gcc 内置的 __thread,phxrpc采用这种方式)来管理,而是预先定义了一个大的数组,并通过对应的 PID 来获取其协程环境。
static stCoRoutineEnv_t* g_arrCoEnvPerThread[204800]
stCoRoutineEnv_t *co_get_curr_thread_env()
{
return g_arrCoEnvPerThread[ GetPid() ];
}
初始化 stCoRoutineEnv_t 时主要完成以下几步:
为 stCoRoutineEnv_t 申请空间并且进行初始化,设置协程调度器 pEpoll。
创建一个空的 coroutine,初始化其上下文环境( 有关 coctx 在后文详细介绍 ),将其加入到该线程的协程环境中进行管理,并且设置其为 main coroutine。这个 main coroutine 用来运行该线程主逻辑。
当初始化完成协程环境之后,调用函数 co_create_env 来创建具体的协程,该函数初始化一个协程结构 stCoRoutine_t,设置该结构中的各项字段,例如运行的函数 pfn,运行时的栈地址等等。需要说明的就是,如果使用了非共享栈模式,则需要为该协程单独申请栈空间,否则从共享栈中申请空间。栈空间表示如下:
struct stStackMem_t
{
stCoRoutine_t* occupy_co; // 使用该栈的协程
int stack_size; // 栈大小
char* stack_bp; // 栈的指针,栈从高地址向低地址增长
char* stack_buffer; // 栈底
};
使用 co_create 创建完一个协程之后,将调用 co_resume 来将该协程激活运行:
void co_resume( stCoRoutine_t *co )
{
stCoRoutineEnv_t *env = co->env;
// 获取当前正在运行的协程的结构
stCoRoutine_t *lpCurrRoutine = env->pCallStack[ env->iCallStackSize - 1 ];
if( !co->cStart )
{
// 为将要运行的 co 布置上下文环境
coctx_make( &co->ctx,(coctx_pfn_t)CoRoutineFunc,co,0 );
co->cStart = 1;
}
env->pCallStack[ env->iCallStackSize++ ] = co; // 设置co为运行的线程
co_swap( lpCurrRoutine, co );
}
函数 co_swap 的作用类似于 Unix 提供的函数 swapcontext:将当前正在运行的 coroutine 的上下文以及状态保存到结构 lpCurrRoutine 中,并且将 co 设置成为要运行的协程,从而实现协程的切换。co_swap 具体完成三项工作:
记录当前协程 curr 的运行栈的栈顶指针,通过 char c; curr_stack_sp=&c 实现,当下次切换回 curr时,可以从该栈顶指针指向的位置继续,执行完 curr 后可以顺利释放该栈。
处理共享栈相关的操作,并且调用函数 coctx_swap 来完成上下文环境的切换。注意执行完 coctx_swap之后,执行流程将跳到新的 coroutine 也就是 pending_co 中运行,后续的代码需要等下次切换回 curr 时才会执行。
当下次切换回 curr 时,处理共享栈相关的操作。
对应于 co_resume 函数,协程主动让出执行权则调用 co_yield 函数。co_yield 函数调用了 co_yield_env,将当前协程与当前线程中记录的其他协程进行切换:
void co_yield_env( stCoRoutineEnv_t *env )
{
stCoRoutine_t *last = env->pCallStack[ env->iCallStackSize - 2 ];
stCoRoutine_t *curr = env->pCallStack[ env->iCallStackSize - 1 ];
env->iCallStackSize--;
co_swap( curr, last);
}
前面我们已经提到过,pCallStack 栈顶所指向的即为当前正在运行的协程所对应的结构,因此该函数将 curr 取出来,并将当前正运行的协程上下文保存到该结构上,并切换到协程 last 上执行。接下来我们以 32-bit 的系统为例来分析 libco 是如何实现协程运行环境的切换的。
五、协程上下文的创建和切换
libco 使用结构 struct coctx_t 来表示一个协程的上下文环境:
struct coctx_t
{
if defined(__i386__)
void *regs[ 8 ];
else
void *regs[ 14 ];
endif
size_t ss_size;
char *ss_sp;
};
可以看到,在 i386 的架构下,需要保存 8 个寄存器信息,以及栈指针和栈大小,究竟这 8 个寄存器如何保存,又是如何使用,需要配合后续的 coctx_swap 来理解。我们首先来回顾一下 Unix-like 系统的 stack frame layout,如果不能理解这个,那么剩下的内容就不必看了。
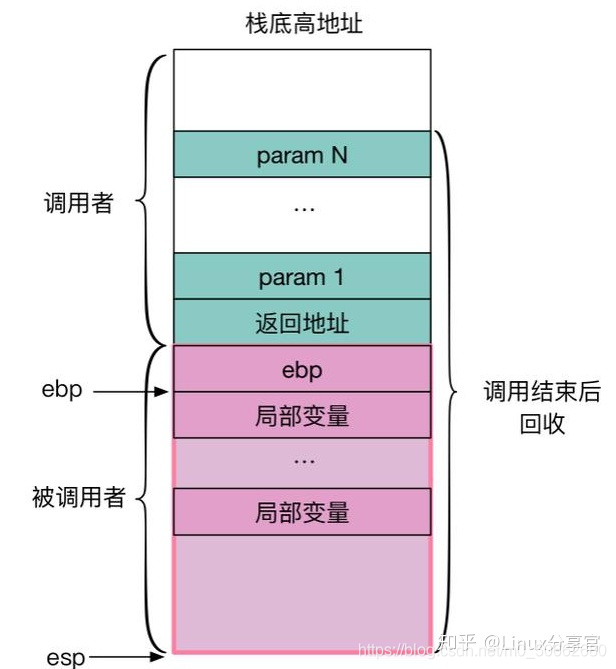
结合上图,我们需要知道关键的几点:
函数调用栈是调用者和被调用者共同负责布置的。Caller 将其参数从右向左反向压栈,再将调用后的返回地址压栈,然后将执行流程交给 Callee。
典型的编译器会将 Callee 函数汇编成为以 push %ebp; move %ebp, %esp; sub $esp N; 这种形式开头的汇编代码。这几句代码主要目的是为了方便 Callee 利用 ebp 来访问调用者提供的参数以及自身的局部变量(如下图)。
当调用过程完成清除了局部变量以后,会执行 pop %ebp; ret,这样指令会跳转到 RA 也就是返回地址上面执行。这一点也是实现协程切换的关键:我们只需要将指定协程的函数指针地址保存到 RA 中,当调用完 coctx_swap 之后,会自动跳转到该协程的函数起始地址开始运行。
了解了这些,我们就来看一下协程上下文环境的初始化函数 coctx_make:
int coctx_make( coctx_t ctx, coctx_pfn_t pfn, const void s, const void *s1 )
{
char *sp = ctx->ss_sp + ctx->ss_size - sizeof(coctx_param_t);
sp = (char*)((unsigned long)sp & -16L);
coctx_param_t param = (coctx_param_t)sp ;
param->s1 = s;
param->s2 = s1;
memset(ctx->regs, 0, sizeof(ctx->regs));
ctx->regs[ kESP ] = (char)(sp) - sizeof(void);
ctx->regs[ kEIP ] = (char*)pfn;
return 0;
}
这段代码应该比较好理解,首先为函数 coctx_pfn_t 预留 2 个参数的栈空间并对其到 16 字节,之后将实参设置到预留的栈上空间中。最后在 ctx 结构中填入相应的,其中记录 reg[kEIP] 返回地址为函数指针 pfn,记录 reg[kESP] 为获得的栈顶指针 sp 减去一个指针长度,这个减去的空间是为返回地址 RA 预留的。当调用 coctx_swap 时,reg[kEIP] 会被放到返回地址 RA 的位置,待 coctx_swap 执行结束,自然会跳转到函数 pfn 处执行。
coctx_swap(ctx1, ctx2) 在 coctx_swap.S 中实现。这里可以看到,该函数并没有使用 push %ebp; move %ebp, %esp; sub $esp N; 开头,因此栈空间分布中不会出现 ebp 的位置。coctx_swap 函数主要分为两段,其首先将当前的上下文环境保存到 ctx1 结构中:
leal 4(%esp), %eax // eax = old_esp + 4
movl 4(%esp), %esp // 将 esp 的值设为 &ctx1(即ctx1的地址)
leal 32(%esp), %esp // esp = (char*)&ctx1 + 32
pushl %eax // ctx1->regs[EAX] = %eax
pushl %ebp // ctx1->regs[EBP] = %ebp
pushl %esi // ctx1->regs[ESI] = %esi
pushl %edi // ctx1->regs[EDI] = %edi
pushl %edx // ctx1->regs[EDX] = %edx
pushl %ecx // ctx1->regs[ECX] = %ecx
pushl %ebx // ctx1->regs[EBX] = %ebx
pushl -4(%eax) // ctx1->regs[EIP] = RA, 注意:%eax-4=%old_esp
这里需要注意指令 leal 和 movl 的区别。leal 将 eax 的值设置成为 esp 的值加 4,而 movl 将 esp 的值设为 esp+4 所指向的内存上的值,也就是参数 ctx1 的地址。之后该函数将 ctx2 中记录的上下文恢复到 CPU 寄存器中,并跳转到其函数地址处运行:
movl 4(%eax), %esp // 将 esp 的值设为 &ctx2(即ctx2的地址)
popl %eax // %eax = ctx1->regs[EIP],也就是 &pfn
popl %ebx // %ebx = ctx1->regs[EBP]
popl %ecx // %ecx = ctx1->regs[ECX]
popl %edx // %edx = ctx1->regs[EDX]
popl %edi // %edi = ctx1->regs[EDI]
popl %esi // %esi = ctx1->regs[ESI]
popl %ebp // %ebp = ctx1->regs[EBP]
popl %esp // %esp = ctx1->regs[ESP],即(char)(sp) - sizeof(void)
pushl %eax // RA = %eax = &pfn,注意此时esp已经指向了新的esp
xorl %eax, %eax // reset eax
ret
上面的代码看起来可能有些绕:
首先 line 1 将 esp 设置为参数 ctx2 的地址,后续的 popl 操作均在 ctx2 的内存空间上执行。
line 2-9 将 ctx2->regs[] 中的内容恢复到相应的寄存器中。还记得在前面 coctx_make 中设置了 regs[EIP] 和 regs[ESP] 吗?这里刚好就对应恢复了相应的值。
当执行完 line 9 之后,esp 已经指向了 ctx2 中新的栈顶指针,由于在 coctx_make 中预留了一个指针长度的 RA 空间,line 10 刚好将新的函数指针 &pfn 设置到该 RA 上。
最后执行 ret 指令时,函数流程将跳到 pfn 处执行。这样,整个协程上下文的切换就完成了。
六、如何使用 libco
我们首先以 libco 提供的例子 example_echosvr.cpp 来介绍应用程序如何使用 libco 来编写服务端程序。 在 example_echosvr.cpp 的 main 函数中,主要执行如下几步:
创建 socket,监听在本机的 1024 端口,并设置为非阻塞;
主线程使用函数 readwrite_coroutine 创建多个读写协程,调用 co_resume 启动协程运行直到其挂起。这里我们忽略掉无关的多进程 fork 的过程;
主线程继续创建 socket 接收协程 accpet_co,同样调用 co_resume 启动协程直到其挂起;
主线程调用函数 co_eventloop 实现事件的监听和协程的循环切换;
函数 readwrite_coroutine 在外层循环中将新创建的读写协程都加入到队列 g_readwrite 中,此时这些读写协程都没有具体与某个 socket 连接对应,可以将队列 g_readwrite 看成一个 coroutine pool。当加入到队列中之后,调用函数 co_yield_ct 函数让出 CPU,此时控制权回到主线程。
主线程中的函数 co_eventloop 监听网络事件,将来自于客户端新进的连接交由协程 accept_co 处理,关于 co_eventloop 如何唤醒 accept_co 的细节我们将在后续介绍。accept_co 调用函数 accept_routine 接收新连接,该函数的流程如下:
检查队列 g_readwrite 是否有空闲的读写 coroutine,如果没有,调用函数 poll 将该协程加入到 Epoll 管理的定时器队列中,也就是 sleep(1000) 的作用;
调用 co_accept 来接收新连接,如果接收连接失败,那么调用 co_poll 将服务端的 listen_fd 加入到 Epoll 中来触发下一次连接事件;
对于成功的连接,从 g_readwrite 中取出一个读写协程来负责处理读写;
再次回到函数 readwrite_coroutine 中,该函数会调用 co_poll 将新建立的连接的 fd 加入到 Epoll 监听中,并将控制流程返回到 main 协程;当有读或者写事件发生时,Epoll 会唤醒对应的 coroutine ,继续执行 read 函数以及 write 函数。
上面的过程大致说明了控制流程是如何在不同的协程中切换,接下来我们介绍具体的实现细节,即如何通过 Epoll 来管理协程,以及如何对系统函数进行改造以满足 libco 的调用。
七、通过 Epoll 管理和唤醒协程
Epoll 监听 FD
上一章节中介绍了协程可以通过函数 co_poll 来将 fd 交由 Epoll 管理,待 Epoll 的相应的事件触发时,再切换回来执行 read 或者 write 操作,从而实现由 Epoll 管理协程的功能。co_poll 函数原型如下:
int co_poll(stCoEpoll_t *ctx, struct pollfd fds[],
nfds_t nfds, int timeout_ms)
stCoEpoll_t 是为 libco 定制的 Epoll 相关数据结构,fds 是 pollfd 结构的文件句柄,nfds 为 fds 数组的长度,最后一个参数表示定时器时间,也就是在 timeout 毫秒之后触发处理这些文件句柄。这里可以看到,co_poll 能够同时将多个文件句柄同时加入到 Epoll 管理中。我们先看 stCoEpoll_t 结构:
struct stCoEpoll_t
{
int iEpollFd; // Epoll 主 FD
static const int _EPOLL_SIZE = 1024 * 10; // Epoll 可以监听的句柄总数
struct stTimeout_t *pTimeout; // 时间轮定时器
struct stTimeoutItemLink_t *pstTimeoutList; // 已经超时的时间
struct stTimeoutItemLink_t *pstActiveList; // 活跃的事件
co_epoll_res *result; // Epoll 返回的事件结果
};
以 stTimeout_ 开头的数据结构与 libco 的定时器管理有关,我们在后面介绍。co_epoll_res 是对 Epoll 事件数据结构的封装,也就是每次触发 Epoll 事件时的返回结果,在 Unix 和 MaxOS 下,libco 将使用 Kqueue 替代 Epoll,因此这里也保留了 kevent 数据结构。
```clike
struct co_epoll_res
{
int size;
struct epoll_event *events; // for linux epoll
struct kevent *eventlist; // for Unix or MacOs kqueue
};
co_poll 实际是对函数 co_poll_inner 的封装。我们将 co_epoll_inner 函数的结构分为上下两半段。在上半段中,调用 co_poll 的协程 CC 将其需要监听的句柄数组 fds 都加入到 Epoll 管理中,并通过函数 co_yield_env 让出 CPU;当 main 协程的事件循环 co_eventloop 中触发了 CC 对应的监听事件时,会恢复 CC的执行。此时,CC 将开始执行下半段,即将上半段添加的句柄 fds 从 epoll 中移除,清理残留的数据结构,下面的流程图简要说明了控制流的转移过程:
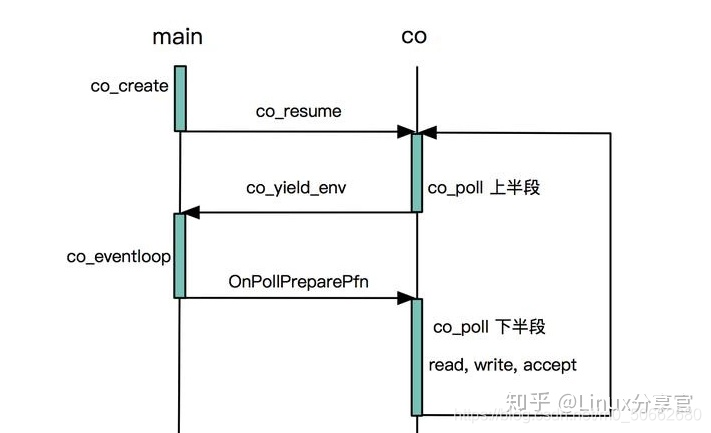
有了上面的基本概念,我们来看具体的实现细节。co_poll 首先在内部将传入的文件句柄数组 fds 转化为数据结构 stPoll_t,这一步主要是为了方便后续处理。该结构记录了 iEpollFd,ndfs,fds 数组,以及该协程需要执行的函数和参数。有两点需要说明的是:
1、对于每一个 fd,为其申请一个 stPollItem_t 来管理对应 Epoll 事件以及记录回调参数。libco 在此做了一个小的优化,对于长度小于 2 的 fds 数组,直接在栈上定义相应的 stPollItem_t 数组,否则从堆中申请内存。这也是一种比较常见的优化,毕竟从堆中申请内存比较耗时;
2、函数指针 OnPollProcessEvent 封装了协程的切换过程。当传入指定的 stPollItem_t 结构时,即可唤醒对应于该结构的 coroutine,将控制权交由其执行;
co_poll 的第二步,也是最关键的一步,就是将 fd 数组全部加入到 Epoll 中进行监听。协程 CC 会将每一个 epoll_event 的 data.ptr 域设置为对应的 stPollItem_t 结构。这样当事件触发时,可以直接从对应的 ptr中取出 stPollItem_t 结构,然后唤醒指定协程。
如果本次操作提供了 Timeout 参数,co_poll 还会将协程 CC 本次操作对应的 stPoll_t 加入到定时器队列中。这表明在 Timeout 定时触发之后,也会唤醒协程 CC 的执行。当整个上半段都完成后,co_poll 立即调用 co_yield_env 让出 CPU,执行流程跳转回到 main 协程中。
从上面的流程图中也可以看出,当执行流程再次跳回时,表明协程 CC 添加的读写等监听事件已经触发,即可以执行相应的读写操作了。此时 CC 首先将其在上半段中添加的监听事件从 Epoll 中删除,清理残留的数据结构,然后调用读写逻辑。
八、定时器实现
协程 CC 在将一组 fds 加入 Epoll 的同时,还能为其设置一个超时时间。在超时时间到期时,也会再次唤醒 CC 来执行。libco 使用 Timing-Wheel 来实现定时器。关于 Timing-Wheel 算法,可以参考,其优势是 O(1) 的插入和删除复杂度,缺点是只有有限的长度,在某些场合下不能满足需求。

回过去看 stCoEpoll_t 结构,其中 pTimeout 代表时间轮,通过函数 AllocateTimeout 初始化为一个固定大小(60 1000)的数组。根据 Timing-Wheel 的特性可知,libco 只支持最大 60s 的定时事件。而实际上,在添加定时器时,libco 要求定时时间不超过 40s。成员 pstTimeoutList 记录在 co_eventloop 中发生超时的事件,而 pstActiveList 记录当前活跃的事件,包括超时事件。这两个结构都将在 co_eventloop 中进行处理。
下面我们简要分析一下加入定时器的实现:
int AddTimeout( stTimeout_t apTimeout, stTimeoutItem_t apItem,
unsigned long long allNow )
{
if( apTimeout->ullStart == 0 ) // 初始化时间轮的基准时间
{
apTimeout->ullStart = allNow;
apTimeout->llStartIdx = 0; // 当前时间轮指针指向数组0
}
// 1. 当前时间不可能小于时间轮的基准时间
// 2. 加入的定时器的超时时间不能小于当前时间
if( allNow < apTimeout->ullStart || apItem->ullExpireTime < allNow )
{
return __LINE__;
}
int diff = apItem->ullExpireTime - apTimeout->ullStart;
if( diff >= apTimeout->iItemSize ) // 添加的事件不能超过时间轮的大小
{
return __LINE__;
}
// 插入到时间轮盘的指定位置
AddTail( apTimeout->pItems +
(apTimeout->llStartIdx + diff ) % apTimeout->iItemSize, apItem );
return 0;
}
定时器的超时检查在函数 co_eventloop 中执行。
九、EPOLL 事件循环
main 协程通过调用函数 co_eventloop 来监听 Epoll 事件,并在相应的事件触发时切换到指定的协程执行。有关 co_eventloop 与 应用协程的交互过程在上一节的流程图中已经比较清楚了,下面我们主要介绍一下 co_eventloop 函数的实现:
上文中也提到,通过 epoll_wait 返回的事件都保存在 stCoEpoll_t 结构的 co_epoll_res 中。因此 co_eventloop 首先为 co_epoll_res 申请空间,之后通过一个无限循环来监听所有 coroutine 添加的所有事件:
for(;;)
{
int ret = co_epoll_wait( ctx->iEpollFd,result,stCoEpoll_t::_EPOLL_SIZE, 1 );
...
}
对于每一个触发的事件,co_eventloop 首先通过指针域 data.ptr 取出保存的 stPollItem_t 结构,并将其添加到 pstActiveList 列表中;之后从定时器轮盘中取出所有已经超时的事件,也将其全部添加到 pstActiveList 中,pstActiveList 中的所有事件都作为活跃事件处理。
对于每一个活跃事件,co_eventloop 将通过调用对应的 pfnProcess 也就是上图中的OnPollProcessEvent 函数来切换到该事件对应的 coroutine,将流程跳转到该 coroutine 处执行。
最后 co_eventloop 在调用时也提供一个额外的参数来供调用者传入一个函数指针 pfn。该函数将会在每次循环完成之后执行;当该函数返回 -1 时,将会终止整个事件循环。用户可以利用该函数来控制 main 协程的终止或者完成一些统计需求。
首先恭喜您,能够认真的阅读到这里,如果对部分理解不太明白,建议先将文章收藏起来,然后对不清楚的知识点进行查阅,然后在进行阅读,相应你会有更深的认知。如果您喜欢这篇文章,就点个赞或者【关注我】吧!!