在之前的BEV-Survey中,提到过,BEV Camera表示仅用视觉或者主要用视觉的算法来实现3D物体检测或者分割,这些cameras来自车身周边。
View Transform Module(VTM)的主要功能是将多视角相机的特征投射到BEV平面上。投影之后的BEV特征,通道C会包含来自当前格子对应的空间信息。
有两种主流方法来实现这个模块。作者把这两个方法叫forward project 和 backward project,我更喜欢上海AI Lab那篇综述里面的2D-3D和
3D-2D投影,这样更容易理解。
- VTM,直观的方案是,估计图像中每个像素的深度值,并使用相机校准参数来确定每个像素在三维空间中的对应位置,从而,将相机特征投影到BEV平面上。在这个过程中,深度预测的准确性至关重要。
为了解决深度预测这项具体挑战性的任务, Lift-Splat-Shoot (LSS) 率先使用深度分布来模拟每个像素深度的不确定性。
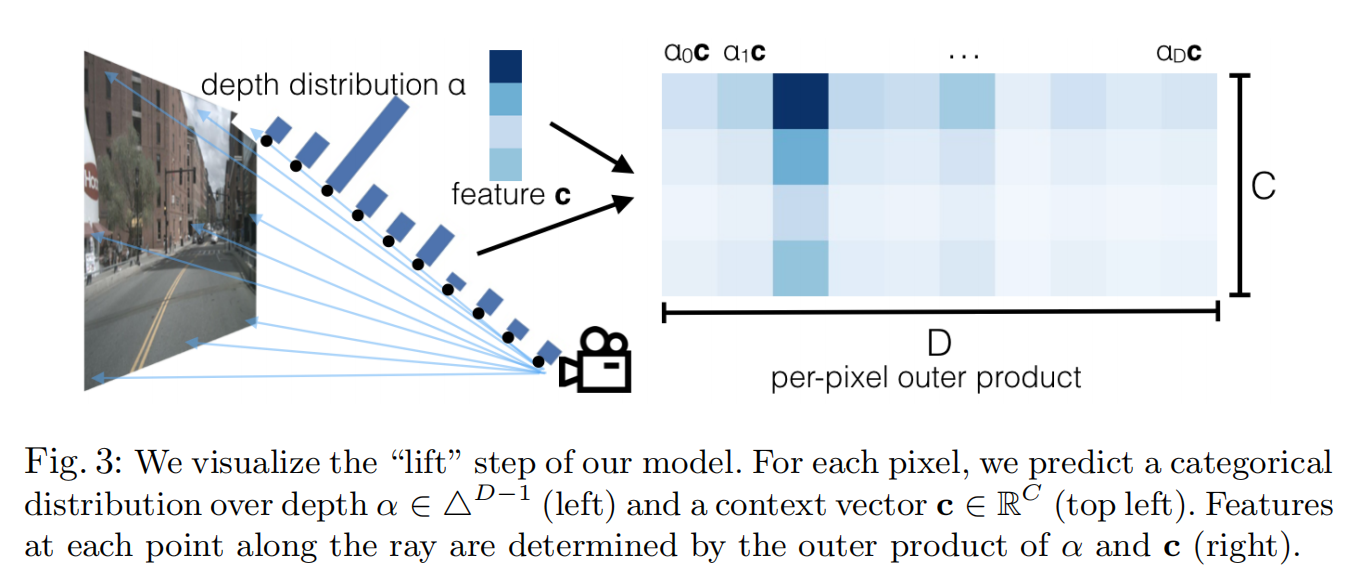
Lift完整操作过程如下图所示,模型对每个图像特征点预测C维语义特征c,以及D维深度分布概率α,然后将α与c做外积,得到HxWxDxC维的特征图,可以理解为HxWxD个视锥点的C维语义特征,它编码了自适应深度下的逐个图像特征点的语义信息。
图中第三个深度,即深度为的视锥点的深度分布概率比较高,那么在图中右侧,相比于此图像特征点的其它视锥点, 的语义特征最“显著”,也可以理解为这个图像特征点的信息更多地被编码到了视锥点 。
LSS的一个局限性是它生成离散和稀疏的BEV表示[1,12]。如图2所示,BEV特征的密度随距离的增加而减小。当在nuScenes数据集上使用LSS的默认设置时,只有50%的BEV Grid可以通过投影接收到有效的图像特征。如下图,BEV上的投影点根据不同的深度权重(图中不同的颜色)具有不同的图像特征。如果有的地方预测深度失效,那么可能会生成blank grid。
关于bev grids,如下图:
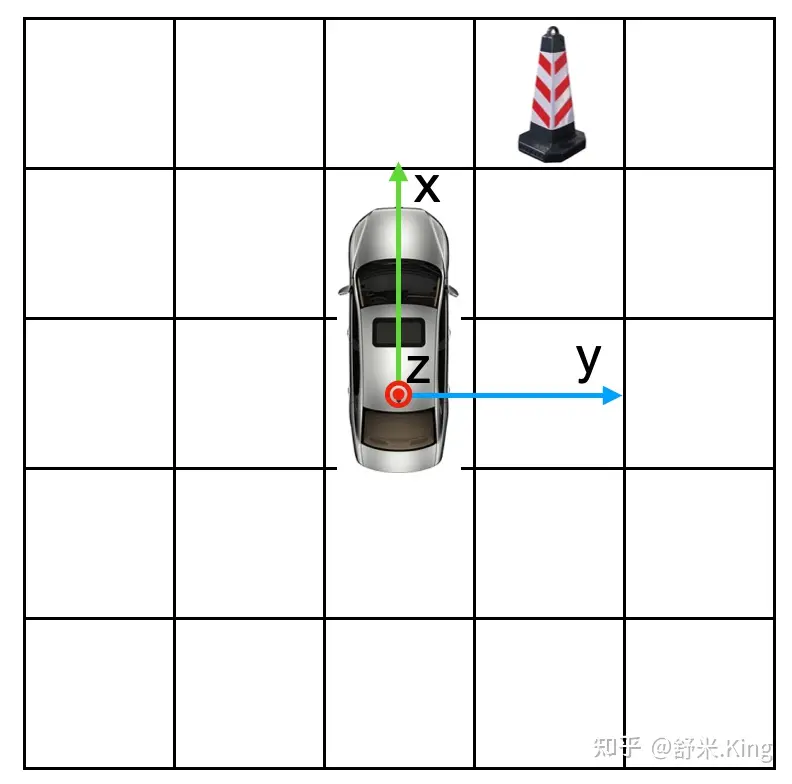
假设这里有200 x 200个 grids,这里为了方便只显示了5个(实际是200),如果每格代表0.5米,那么200 x 200gids就代表100米x100米的平面,那车的左右就各50米。如果在每个grid都填充C个通道的特征值作为contex,就组成了bev特征图。
- 另一种方法是,先对3D空间中的点进行处理,比如BEVFormer,提前填充的三维空间的坐标,然后将这些三维点投影到2D图像上,因此,每个预定义的三维空间位置都可以获得其相应的图像特征。该方法获得的BEV Grid表示比LSS表示更密集,每个BEV网格中都填充了相应的图像特征。
这种方法就像2D anchor based检测中提前设置了一堆anchors,但是与之学习的training data,太少,因为遮挡和深度不匹配,这就导致BEV Grids中的False Positive,或者说False Corresponding点太多。这种方法对深度信息的利用太少了,几乎默认深度信息分布是均匀的。如下图中,投影射线上的点几乎毫无区别地获得相同的图像特征。
如今,更准确的深度预测方法导致方法1相对方法2有更大的优势。
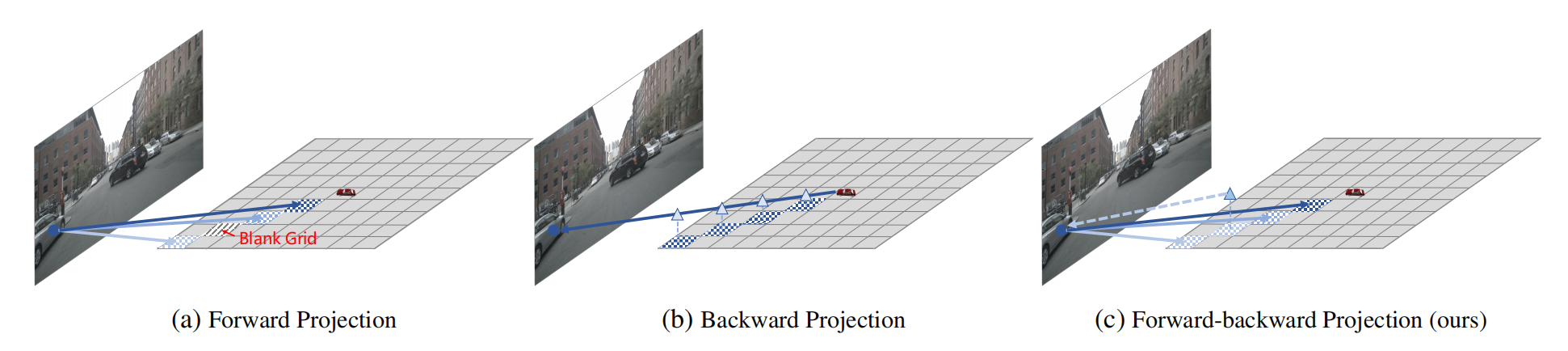
作者提出了一个FB VTM来解决现有vtm的局限性,如上图所示。为了解决由2D-3D投影产生的稀疏BEV表示的问题,我们利用3D-2D投影方法从之前的3D-2D投影中细化稀疏区域。然而,正如我们上面所介绍的,由于缺乏深度引导,3D-2D投影的投影容易出现假阳性特征。因此,如果只是简单组合是次优的。
为了有效地建立精确的3D-2D投影关系,作者设计了一种depth-aware的3D-2D方法,该方法可以通过深度一致性来衡量每个投影关系的质量。深度一致性由三维点与其对应的二维投影点之间的深度分布的距离决定。
利用这种depth-aware方法,给予不匹配投影较低的权值,减少了假阳性BEV特征引起的干扰。另外,对于目标检测任务,我们只关心前景对象,所以我们在使用3D-2D投影时,只关注BEV平面的前景区域,这样可以减少背景部分的false positive,减少计算负担。
通过细化的2D-3D投影的稀疏区域,减少3D-2D投影的假阳性特征,我们的FB-bev投影不仅解决了现有投影方法的缺陷,而且实现了现有投影方法的有效集成。
这篇论文的主要贡献:
我觉得主要就是这么几个关键词,精细化,深度感知机制,深度一致性机制
1: refine the blank grid that not activated by 2D-3D projection,使得grids不那么稀疏。
2: depth-aware 3D-2D projection method that overcomes the limitations of existing methods in effectively utilizing depth information,
integrates depth consistency into the projection process to establish a more accurate mapping relationship between the 3D and 2D spaces,减少false positive。
领域相关工作介绍:
作者根据他们使用的VTM,来介绍相关的BEV感知工作。
2D-3D投影:
LSS是这类方法的原型,LSS利用深度分布来建模深度的不确定性,并将多视图特征投射到同一BEV空间中。随后的方法在很大程度上遵循了这个范式。例如,BEVDet将这种投影方法应用于多视图三维检测领域。
CaDDN 和BEVDepth 提出利用激光雷达点云生成 depth ground truth,以监督深度预测模块。BEVDepth的研究结果表明,一个精确的深度预测模块可以显著提高模型的性能(直觉上都知道肯定的)。BEVstereo也是强调准确的深度估计的重要性。
此外,BEVFusion 将这一范式扩展到多模态感知领域,并提高了LSS范式的投影效率。随后也有很多方法通过工程实现改进了效率。
针对BEV特征的稀疏性,MatrixVT 主要集中在提高BEV生成过程中的计算效率,而不是强调BEV特征。
3D-2D投影:
OFT是第一个用这种投影方法的,这个范式不涉及三维空间中的复杂累计计算,而这个步骤是2D-3D投影中效率最低的一步。随后 ImVoxelNet 将这一范式从单眼感知扩展到多视角感知。这两种方法都将三维空间划分为体素,这增加了计算负担。
虽然DETR3D 没有引入显式的BEV特征,但它通过将目标中心投影回图像空间,从BEV的角度执行目标query的端到端学习。
BEVFormer 在BEV空间上聚合不同高度的特征,而不引入体素表示,从而减少了资源消耗。BEVFormer 还引入了可变形采样点和时序特征,促进了基于相机的感知的进一步发展。
对于感知头,BEVFormer 采用 Deformable DETR 和 Panoptic SegFormer 。BEVFormerV2 通过perspective supervision调整当前图像backbone,进一步发挥了3D-2D投影的潜力。
PolarFormer和PolarDETR 采用极坐标而不是笛卡尔坐标来进行投影过程。
方法[24–26]投影3-D锚点在4D特征而不是3D特征上。
PersFormer[27]使用逆透视映射(IPM)来引导图像空间上的投影点。
然而,现有的方法很少考虑在投影过程中引入深度,甚至有些工作将不依赖深度信息作为优势。
我们认为,在没有深度来衡量投影质量的情况下,这会增加了投影过程中的模糊性。
Projection-Free Methods
略
Methodology
我们提出的FB-BEV双管齐下。首先,一个基于2D-3D投影的VTM将生成一个初始的稀疏BEV表示。为了在最小化计算负担的同时获得最密集的BEV表示,采用前景区域建议网络Foreground Region Proposal Network来选择前景BEV网格。随后,另一个VTM利用这些前景网格作为BEV查询,并通过使用depth-aware机制将它们投影到图像上来细化它们。
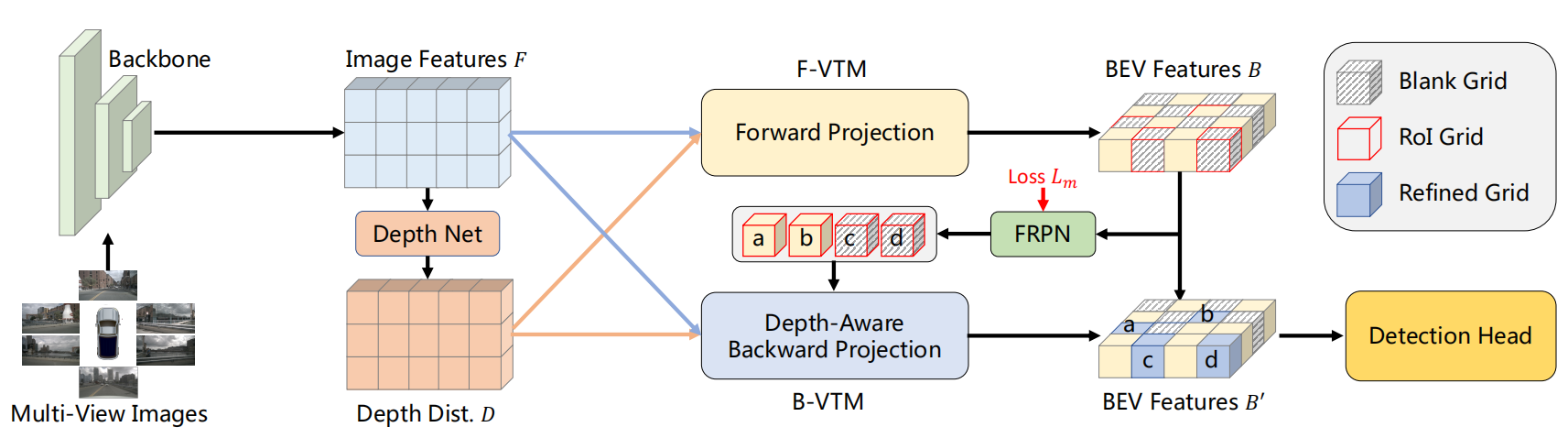
上图是FB-BEV的总体架构,首先,我们从二维骨干网中提取多视图特征,并利用深度网络生成深度分布。
然后,我们使用一个前向投影模块来生成BEV特征B,因为BEV特征B包含空白网格,所以FRPN生成一个前景掩模,并将前景感兴趣区域(RoI)网格提供给下一个具有depth-aware的3D-2D投影模块(图中的Grids{a,b,c,d})。
我们的B-VTM投影模块,使用RoI网格作为BEV查询,并通过使用深度一致性机制将其投影到图像上来改进这些查询。最后,我们通过添加细化的网格和BEV特征B,得到BEV特征B’ 。
FB-BEV主要由三个关键模块组成:2D-3D投影为F-VTM的视图转换模块为F-VTM,前景区域建议网络为FRPN,3D-2D投影的视图转换模块为B-VTM。
本文总体架构:
F-VTM根据相应的深度分布,将每个像素特征投影到三维空间中,从多视图特征中生成一个完整的BEV表示。FRPN是一个轻量级的二值化掩模预测器,用于选择前景对象所在的区域。B-VTM只负责优化位于FRPN生成的前景区域的BEV网格。
在推理过程中,我们将多视图RGB图像输入图像主干网络,获得图像特征
F
=
F
i
i
=
1
N
c
F={F_{i}}^{N_{c}}_{i=1}
F=Fii=1Nc,
F
i
F_i
Fi是第i个相机的视图特征,Nc是相机的总数。然后通过将图像特征F输入深度网,得到深度分布
D
=
D
i
i
=
1
N
c
D={D_{i}}^{N_{c}}_{i=1}
D=Dii=1Nc。
以视图特征F 和 深度分布D为输入,F-VTM将生成一个BEV特征
B
∈
R
C
×
H
×
W
B∈R^{C×H×W}
B∈RC×H×W,其中C为channel维度,H×W为BEV的空间形状。
FRPN以BEV特征B作为输入,并且预测一个二进制掩模
M
∈
R
H
×
W
M∈R^{H×W}
M∈RH×W来检测前景区域。
只有前景网格
B
[
s
i
g
m
o
i
d
(
M
)
>
t
f
]
B[sigmoid(M) > t_f ]
B[sigmoid(M)>tf] 将被输入到B-VTM中以进行进一步refine,其中
t
f
t_f
tf为前景阈值。
最终的BEV特征
B
′
∈
R
C
×
H
×
W
B'∈R^{C×H×W}
B′∈RC×H×W,是通过B-VTM得到的细化的BEV特征 和 B相加得到的。
最后,我们基于BEV特征
B
′
B'
B′执行3D检测任务。
F-VTM 投影:
我们的2D-3D投影模块F-VTM遵循了LSS的方法,Lift 和 Splat是用于VTM的2D-3D投影技术的两个基本步骤。
Lift步骤根据像素相应的深度分布,将二维图像中的每个像素投影到三维体素空间上。
Splat步骤通过sum pooling聚合每个体素内像素的特征值。
与BEV-Former 采用随机初始化的参数作为BEV queries 不同的是,我们将获得的3D体素表征压缩到BEV表征中,从而纳入更强的语义先验。
对于具体的实现,作者的F-VTM是基于BEVDet [9,32]和BEVDepth [15],它们代表了当前最先进的2D-3D投影设计。我们将F-VTM中的BEV特征表示为B。
FRPN:
从F-VTM中获得的BEV特征是稀疏的,并且有一些BEV网格没有被激活,因此包含空白信息。
为了获得更强的BEV表示,我们期望填充这些空白的BEV网格。然而,对于三维目标检测,我们的兴趣只在于有限的前景对象,它们占据了BEV特征的相对较小的一部分。
为了在BEV特征中定位这些前景目标,我们利用一个简单的分割网络从BEV特征B中生成一个二进制掩模
M
∈
R
H
×
W
M∈R^{H×W}
M∈RH×W。
在这个过程中的FRPN包括一个3×3的卷积层后面接着一个sigmoid函数,这使得它非常轻量级。
这个二进制掩模
M
g
t
M^{gt}
Mgt的GT是通过将前景目标投影到BEV平面上得到的【注:nuScenes并没有为2D图像提供语义分割标签。为了解决这个问题,我们 采用了 Segment Anything Model(SAM )进行自动标注。对于有nuScenes提供的边界框注释的类别,我们利用框来为每个物体生成高质量的语义掩码。】
在论文中,我们使用 Dice loss 和 cross-entropy loss的组合来监督FRPN。
在推理阶段,我们以F-VTM的BEV特征B作为输入,预测二进制掩模M,过滤掉低于阈值
t
f
t_f
tf的不必要的BEV网格。
**因此,我们得到了一组离散的BEV网格,{
Q
x
,
y
∣
M
[
(
x
,
y
)
]
>
t
f
{Q_{x,y}|M[(x,y)]>t_f}
Qx,y∣M[(x,y)]>tf}, 式中(x,y)为每个前景BEV网格的位置。每个BEV网格
Q
x
,
y
Q_{x,y}
Qx,y都可以看作是一个需要进一步细化的BEV Query,这部分类似于BEVFormer的BEV Query,所以输入到B-VTM模块的shape是H x W **。
为了保持前景区域的特征一致性,我们选择了同时包含空白和非空白网格的BEV网格。
3.4 B-VTM 投影 Depth-Aware Backwark Projection
本文的B-VTM 有2个作用:
本质上,它是BEVFormer的Spatial Cross Attention的改进版,被称为SCAda.
简单总结:
对于每一个位于(x, y)位置的BEV特征,我们可以计算其对应现实世界的坐标x’, y’。然后我们将BEV query 进行 lift 操作拉成一个体柱,并在Z轴上进行采样,文中采样4个点,获取高度不同的获3D points。
将这些3D点可以通过相机参数投影到图像上,这一步和BEVFormer一样。
相机上的点通过深度预测可以得到一个深度分布[
w
0
,
w
1
,
.
.
.
,
w
∣
D
∣
w_0,w_1,... ,w_{|D|}
w0,w1,...,w∣D∣ ],实验中|D|被设置为118。
之前lift的3D点,有各自对应的深度d,通过下面的公式2转换为深度分布向量,再通过3D点的深度分布向量 点乘 图片上点的深度分布向量。
这样,得到了2D点和3D点之间的深度一致性,由下面的图可以知道,这些3D点再图像上的投影点,离目标越近有更大的 深度一致性,
从下面的公式中可以看到,
F
d
F_d
Fd是一个Deformable Attention函数,将投影点作为参考点,在其附近采样N个特征点,这些特征点如果离目标近,会有更大的深度一致性。
。。。
有了3D points就能够通过相机内参获取3D points在2D平面的投影点,将投影点作为参考点(先验),在投影点附近基于Deformable Attention, 进行特征采样,然后BEV query使用加权的采样特征weighted sum 进行更新,从而完成了spatial 特征聚合
主要步骤:这里写的是BEVFormer,待改进
1 对每个BEV query 在高度为度Z轴上等距离采样4个3D points
2 将采样的4个3D points利用相机参数投影到图像上,得到投影点
3 利用Deformable attention,将投影点作为参考点,在其附近采样N个特征点,图中示例3个特征点
4 BEV query使用加权的采样特征进行更新,从而完成了spatial 空间的特征聚合
首先,它可以有效地以任意分辨率填充BEV,(并且只能生成指定区域的BEV特征,??不太懂这里),从而补偿由前向特征产生的稀疏特征。
其次,当与F-VTM投影方法相结合时,它们提供了更全面的BEV表示。
-
3.4.1 Depth Consistency 深度一致性
B-VTM投影的基本概念是基于摄像机投影矩阵
P
∈
R
3
×
4
P∈R^{3×4}
P∈R3×4,将一个三维点(x,y,z)投影到一个二维图像点(u,v)上。这个过程的数学表达如下:
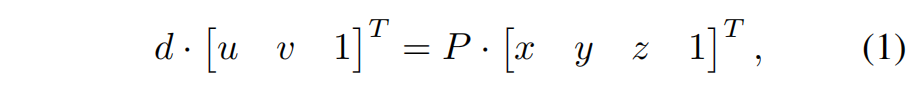
d表示3D点(x、y、z)在图像上的深度。对于任何3D点(λx,λy,λz),其中λ∈R+,它们在2D图像上共享相同的投影点(u,v)。因此,这些3D点(λx,λy,λz)表现出相似的图像特征,如图3所示。
2D-3D投影通过预测不同深度的不同权值来缓解了这一问题。
具体来说,对于每个点(u,v),它预测了每个离散深度depth (d0 + i∆), and i∈ {0, 1, · · · , |D|}的权重
w
i
w_i
wi,其中
d
0
,∆,
∣
D
∣
d_0,∆,|D|
d0,∆,∣D∣在实验中都是常数,D为一组离散深度,
d
0
d_0
d0为初始深度,∆为深度区间。因此,当考虑同一个点(u,v)上的两个离散深度(d0+i∆)和(d0+j∆)时,它落在基于方程1的三维点(xi、yi、zi)和(xj、yj、zj)上。
2D-3D投影方法利用预测的深度权值
w
i
w_i
wi和
w
j
w_j
wj来生成具有区分性的特征。
为了在3D-2D投影中加入深度,提高投影质量,本文引入了深度一致性
w
c
w_c
wc,
如下图所示。
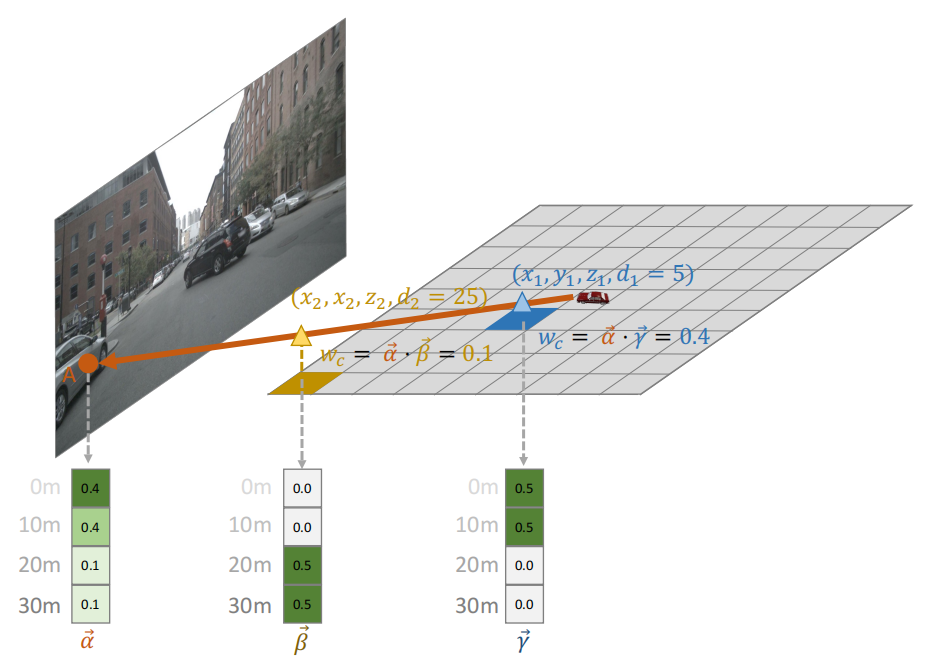
图解:具有深度感知能力的3D-2D投影利用深度一致性来区分投影射线上的特征。例如,点(x1、y1、z1)和(x2、y2、z2)位于同一条光线上,并且在图像上具有相同的投影点A。两点的深度分别为d1 = 5m和d2 = 25m。A点的预测深度分布为α。然后我们将深度值d1和d2转换为深度分布β和γ【我的理解是,通过下面介绍的公式将
d
i
d_i
di转换成
w
i
′
w^{'}_i
wi′】。两个点的深度一致性分别为α·γ=0.4和α·β = 0.1,因此离目标车较近的点(x1,y1、z1)具有更高的图像特征权重和更高的深度一致性。
由于在点(u,v)上有一个离散的深度分布向量[
w
0
,
w
1
,
.
.
.
,
w
∣
D
∣
w_0,w_1,... ,w_{|D|}
w0,w1,...,w∣D∣ ]已经可用。
把深度值d转换成深度分布向量
[
w
0
′
,
⋅
⋅
⋅
,
w
i
′
,
w
i
+
1
′
⋅
⋅
⋅
⋅
w
∣
D
∣
′
]
[w^{'}_0,···,w^{'}_{i},w^{'}_{i+1}····w^{'}_{|D|} ]
[w0′,⋅⋅⋅,wi′,wi+1′⋅⋅⋅⋅w∣D∣′],其中只有
w
i
′
,
w
i
+
1
′
w^{'}_{i},w^{'}_{i+1}
wi′,wi+1′非零,同时(d0 +∆)≤ d ≤(d0+(i+1)∆)。
w
i
′
=
1
−
d
−
d
0
−
i
∆
∆
,
w
i
+
1
′
=
1
−
w
i
′
w^{'}_i=1-\frac{d−d_0−i∆}{∆},w^{'}_{i+1}=1−w^{'}_{i}
wi′=1−∆d−d0−i∆,wi+1′=1−wi′。
注意|D|,
d
0
d_0
d0,∆在实验中分别被设置为了118,1和0.5。
深度一致性
w
c
w_c
wc可以计算为:
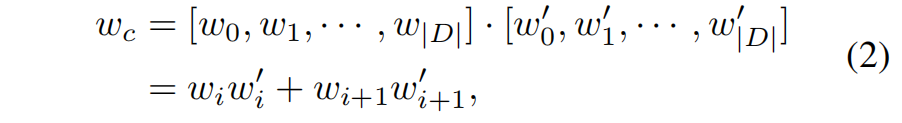
F-VTM投影采用离散深度值在三维空间中生成相应的离散三维投影点。在牺牲深度的连续性的同时,也影响了BEV特征的精度。对于我们的深度感知B-VTM投影,我们保证能够在任意分辨率下通过上述的深度一致性方法密集填充三维空间,并且保证投影质量。
-
3.4.2 实现
深度一致性是一种可以插入到任何现有的反向投影方法中的通用机制。在本文中,我们的深度感知B-VTM投影是基于BEVFormer中的空间交叉注意力机制,BEVFormer原始空间交叉注意(SCA)的投影过程可以表述为:
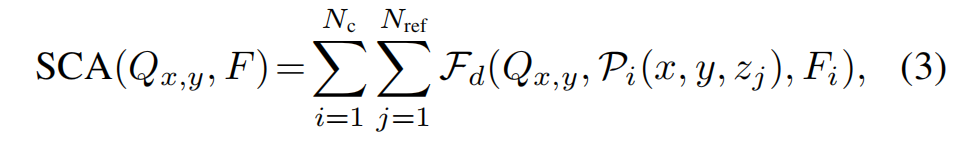
其中,Qx,y是位于(x,y)处的一个BEV查询,而F是多视图特征。
对于BEV平面上的每个点(x,y),BEVFormer将这个点提升到有不同高度
z
i
z_i
zi的
N
r
e
f
N_{ref}
Nref个3D点。
将
N
r
e
f
N_{ref}
Nref个3D点根据方程1得到第i幅图像上的投影点(ui,vi)。
F
d
F_d
Fd是一个Deformable Attention函数,将投影点作为参考点,在其附近采样N个特征点
Q
x
,
y
Q_{x,y}
Qx,y使用加权的采样特征进行更新,从而完成了spatial 空间的特征聚合。
利用本文的深度一致性,我们可以通过以下方法直接将SCA直接演化为深度感知SCA(SCAda):
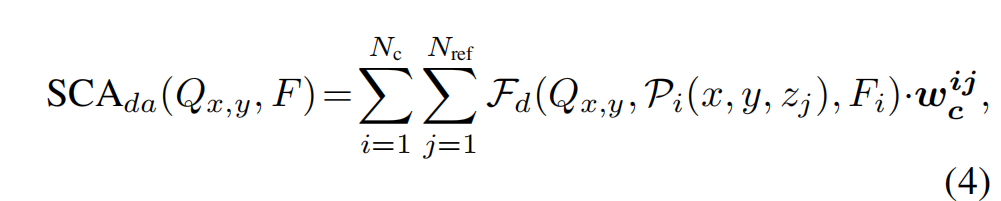
其中,
w
c
i
j
w_{c}^{ij}
wcij是3D点(x、y、zj)和2D点(ui、vi)之间的深度一致性。与原来的SCA相比,我们提出的SCAda能够沿纵向上产生更有区别性的BEV特征。由于我们的深度感知SCA的高效率,我们只使用一次反向投影,而不是叠加原始BEVFormer使用的6层。
实验
数据集:
略
实现细节:
通过遵循常见的实践,我们默认使用ResNet-50和图像大小为256×704提取特征,在训练过程中,我们采用了CBGS策略,并在图像和BEV层面上都应用了数据增强,其中包括根据BEVDet进行的随机缩放、翻转和旋转。
默认情况下,我们的模型使用batch-size=64 和学习率为2e- 4的AdamW 优化器,训练了20个epochs。在使用V2-99骨干训练FB-BEV进行测试集时,我们使用30个epochs训练模型without GBGS。
为了使用时序信息训练深度网络,我们使用BEVDepth 中的cemera-aware depth net,共计118个深度类别(|D|),d0 = 1和∆=0.5。
结合depth-aware的spatial cross attention,我们从[-5m,3m]均匀地采样预定义的高度,使用8个attention heads,并设置参考点个数
N
r
e
f
N_{ref}
Nref = 4。
BEV网格的形状默认为128×128,channel维度为256。前景掩模的阈值设置为
t
f
t_f
tf= 0.4。当引入时间信息时,我们堆叠了两个相邻关键帧的BEV特征,如BEVDet4D的val set。对于测试集,叠加的是9个之前的帧。
Baselines:
为了评估我们的新方法FB-BEV的有效性,我们分别与两种仅依赖于2D-3D和3D-2D投影技术的两种baseliens进行了比较。
值得注意的是,对于这些baselines,除了VTM外,我们在骨干、检测头和训练策略方面与FB-BEV保持一致。我们减少了FB-BEV的通道数和层数,以匹配计算成本。
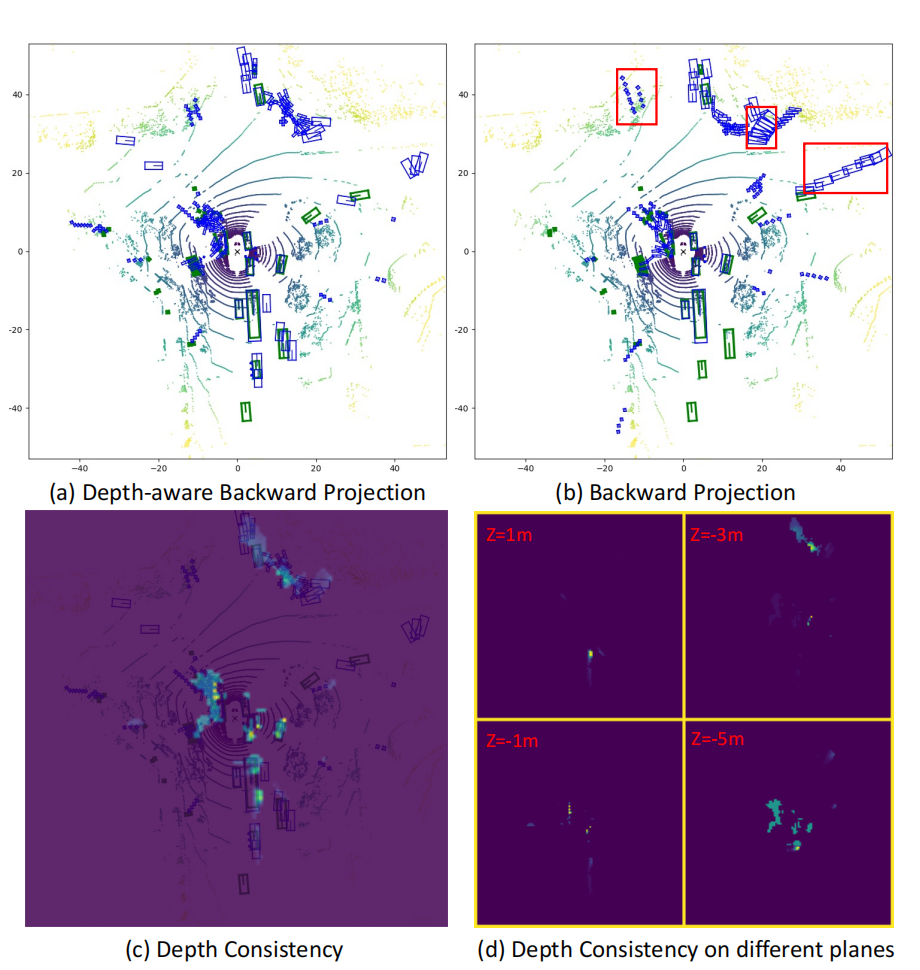 【图解:我们分别比较了(a)和(b)中有和没有深度感知反向投影的FB-BEV的可视化结果。(b)中的红框表示由于深度歧义,模型沿纵向方向产生的错误结果。图©显示了BEV平面上的深度一致性贴图,其中每个值都是不同高度下的深度一致性之和。在图(d)中,我们观察了不同高度的深度一致性图。】
【图解:我们分别比较了(a)和(b)中有和没有深度感知反向投影的FB-BEV的可视化结果。(b)中的红框表示由于深度歧义,模型沿纵向方向产生的错误结果。图©显示了BEV平面上的深度一致性贴图,其中每个值都是不同高度下的深度一致性之和。在图(d)中,我们观察了不同高度的深度一致性图。】
2D-3D投影:
对于2D-3D投影方法,我们采用BEVDet 和BEVDepth 作为基线。与BEVDet相比,BEVDepth使用点云来生成深度的地面真实值,并使用深度的地面真实值来训练深度网络。
3D-2D投影:
对于反向投影方法,我们选择BEVFormer作为基线。考虑到实现细节上的差异,我们将BEVFormer的VTM移植到BEVDet以进行公平的比较。值得一提的是,我们放弃了BEVFromer中的时序自注意模块。在本文中,我们将有时序信息的BEVFomer为BEVFormer-T。