本文数据来自于大数据可视化技术这本书
用于复习
1. 饼图
1.1 基础饼图
import pandas as pd
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType
data=pd.read_csv("vote_result.csv",encoding="utf-8")
c = (
Pie(init_opts = opts.InitOpts(theme=ThemeType.WALDEN))#ThemeType.WALDEN用于更换不同风格颜色
.add("interest",data.values.tolist())
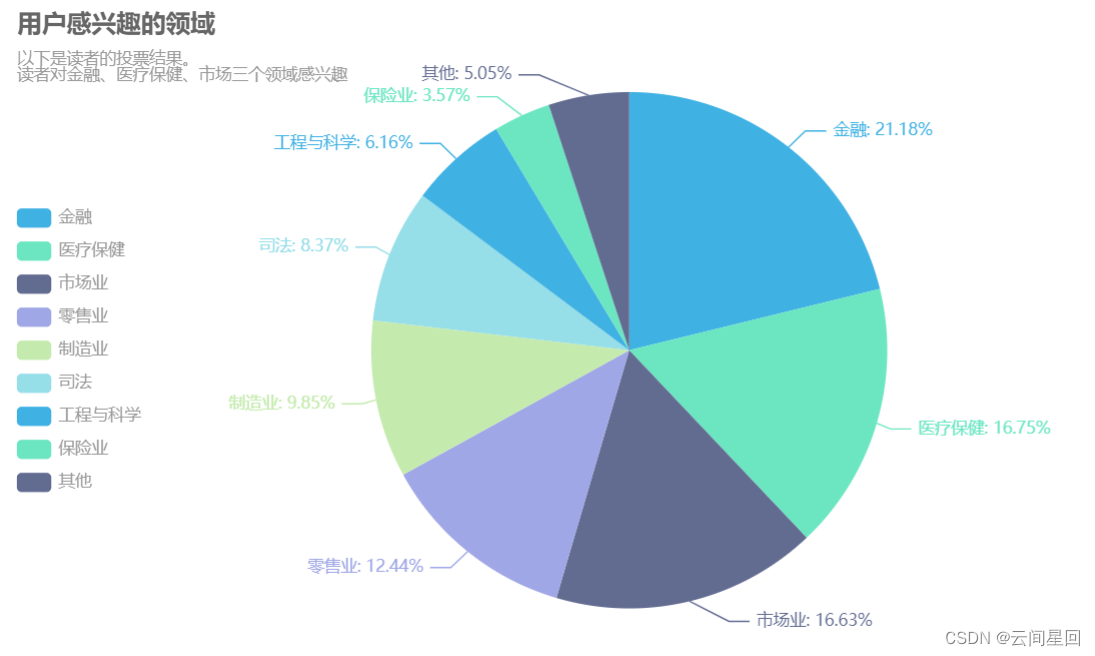
.set_global_opts(title_opts=opts.TitleOpts(title="用户感兴趣的领域",
subtitle="以下是读者的投票结果。\n读者对金融、医疗保健、市场三个领域感兴趣",
pos_left="left" ),
legend_opts=opts.LegendOpts(pos_left="left",
pos_top="middle",
orient="vertical")
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
.render("pie.html")
)
- 2.玫瑰图
import pandas as pd
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType
data=pd.read_csv("vote_result.csv",encoding="utf-8")
p=(
Pie(init_opts=opts.InitOpts(theme=ThemeType.ESSOS))
.add(" ",data.values.tolist(),
radius=["30%", "75%"],
center=["55%", "50%"],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=False),
)
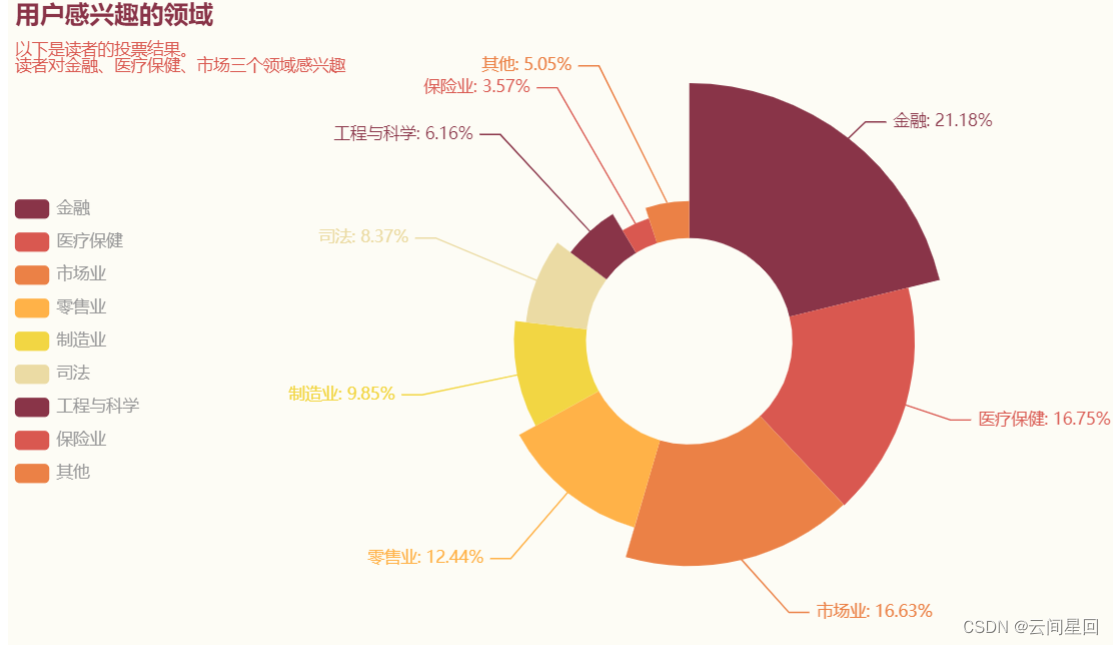
.set_global_opts(title_opts=opts.TitleOpts(title="用户感兴趣的领域",
subtitle="以下是读者的投票结果。\n读者对金融、医疗保健、市场三个领域感兴趣",
pos_left="left" ),
legend_opts=opts.LegendOpts(pos_left="left",
pos_top="middle",
orient="vertical")
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
.render("pie_rose.html")
)
2.柱状堆叠图
2.1 基本堆叠数据图
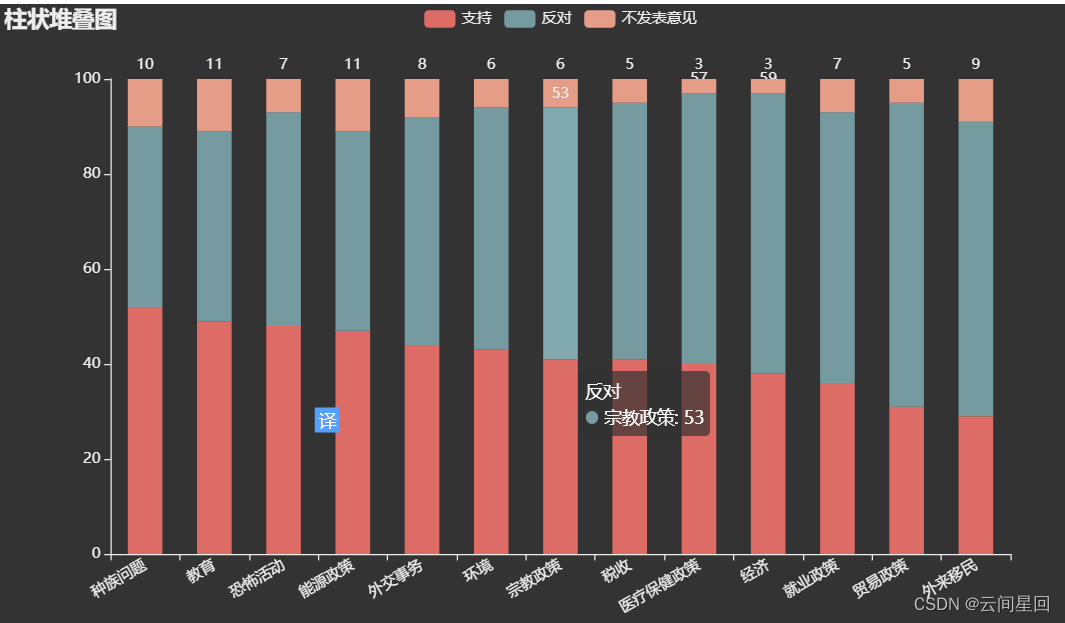
根据对奥巴马支持率的民意调查数据president_approval_rate.csv进行堆叠柱形图的绘制
from pyecharts.charts import Bar
import pandas as pd
from pyecharts import options as opts
from pyecharts.globals import ThemeType
pre_approval_rate = pd.read_csv("presidential_approval_rate.csv")
bar = (
Bar(init_opts = opts.InitOpts(theme = ThemeType.DARK))
.add_xaxis(pre_approval_rate['political_issue'].tolist())
.add_yaxis("支持", pre_approval_rate['support'].tolist(), stack="1", category_gap="50%")
.add_yaxis("反对", pre_approval_rate['oppose'].tolist(), stack="1", category_gap="50%")
.add_yaxis("不发表意见", pre_approval_rate['no_opinion'].tolist(), stack="1", category_gap="50%")
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title = "柱状堆叠图"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)))
)
bar.render_notebook()
2.2
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
import pandas as pd
pre_approval_rate = pd.read_csv("presidential_approval_rate.csv")
list_support=['支持','反对','不发表意见']
bar = Bar(init_opts = opts.InitOpts(theme = ThemeType.DARK))
bar.add_xaxis(list_support)
for i in range(pre_approval_rate.iloc[:,0].size):
issue = pre_approval_rate.loc[i,'political_issue']
bar.add_yaxis(issue, [int(x) for x in pre_approval_rate.loc[i,['support','oppose','no_opinion']]],
stack=True, category_gap="50%")
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
bar.set_global_opts(title_opts=opts.TitleOpts(title = "柱状图数据堆叠示例", pos_left='center'),
legend_opts=opts.LegendOpts(orient="vertical", pos_right="5%"))
bar.render_notebook()
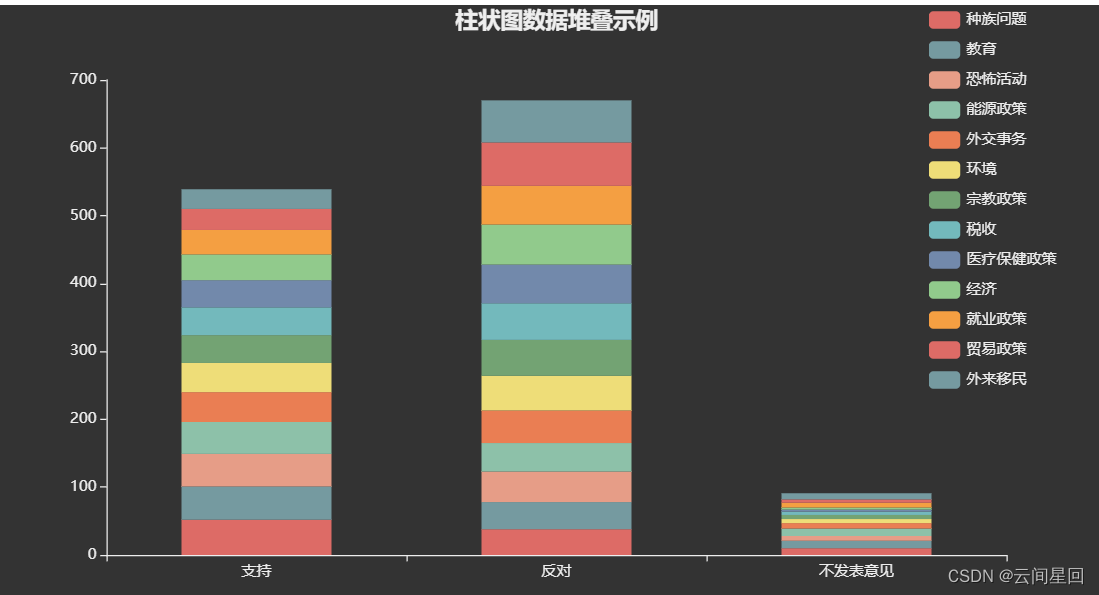
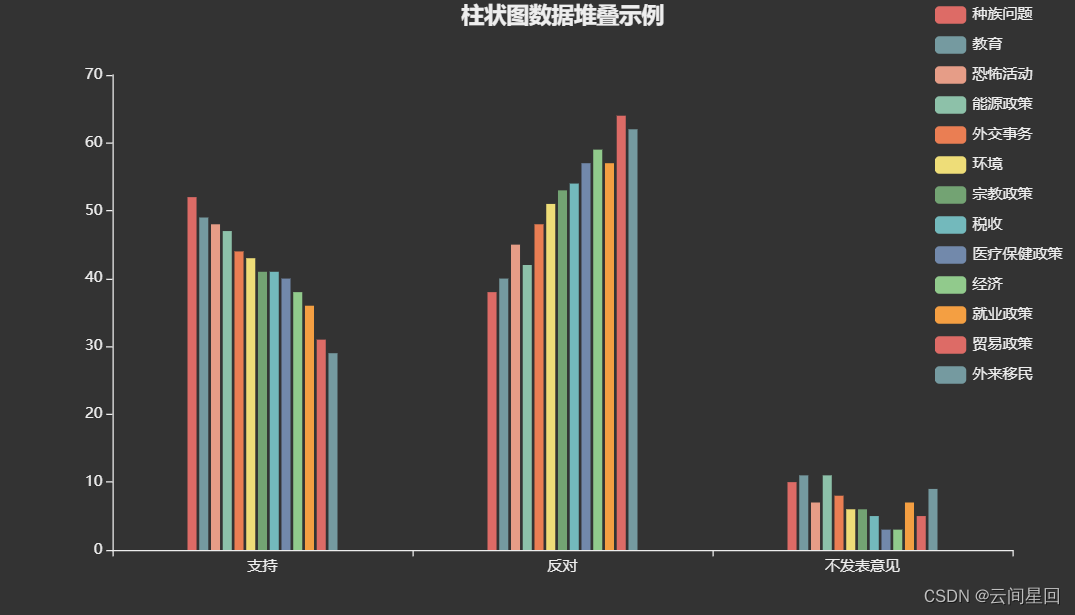
2.3 非堆叠图形展示
3.时堆叠比例图
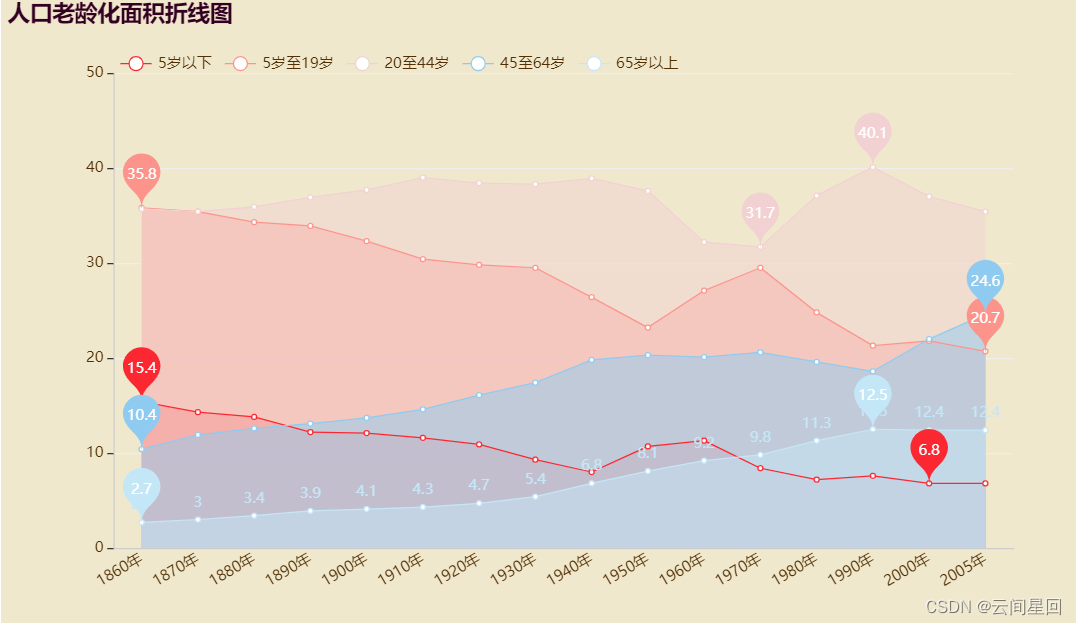
对1860-2005年人口老龄化数据us_population_by_age.csv进行图形绘制
import pyecharts.options as opts
from pyecharts.charts import Line
import pandas as pd
from pyecharts.globals import ThemeType
year_population_age = pd.read_csv('us_population_by_age.csv')
#面积折线图
(
Line(init_opts=opts.InitOpts(theme=ThemeType.ROMANTIC))
.add_xaxis(xaxis_data=year_population_age['year'].tolist())
.add_yaxis(
series_name="5岁以下",
# stack="总量",
y_axis=year_population_age['year_under5'].tolist(),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="5岁至19岁",
# stack="总量",
y_axis=year_population_age['year5_19'].tolist(),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="20至44岁",
# stack="总量",
y_axis=year_population_age['year20_44'].tolist(),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="45至64岁",
# stack="总量",
y_axis=year_population_age['year45_64'].tolist(),
label_opts=opts.LabelOpts(is_show=False)
)
.add_yaxis(
series_name="65岁以上",
# stack="总量",
y_axis=year_population_age['year65above'].tolist(),
label_opts=opts.LabelOpts(is_show=True, position="top"),
)
.set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),#填充面积
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max",name="最大值"),
opts.MarkPointItem(type_="min",name="最小值")])
)
.set_global_opts(
title_opts=opts.TitleOpts(title="人口老龄化面积折线图"),
legend_opts=opts.LegendOpts(type_="scroll",pos_top="8%", pos_left="10%", orient="horizontal"),#图例配置项
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=True,axislabel_opts=opts.LabelOpts(rotate=30))
)
.render_notebook()
)