提升树Boosting Tree算法实例详解_程大海的博客-CSDN博客
从提升树Boosting Tree过度到梯度提升Gradient Boosting_程大海的博客-CSDN博客
GBDT梯度提升之回归算法个人理解_程大海的博客-CSDN博客_梯度回归算法
GBDT梯度提升之二分类算法个人理解_程大海的博客-CSDN博客_gbdt二分类
GBDT梯度提升之多分类算法个人理解_程大海的博客-CSDN博客_gbdt可以多分类吗
XGBoost算法个人理解_程大海的博客-CSDN博客_xgboost 叶子节点权重
交叉熵损失与极大似然估计_程大海的博客-CSDN博客_极大似然估计和交叉熵
使用泰勒展开解释梯度下降方法参数更新过程_程大海的博客-CSDN博客
AdaBoost算法实例详解_程大海的博客-CSDN博客_adaboost算法实例
AdaBoost算法其实很精炼,算法流程也好理解,但是看了算法的解释版本之后,什么前向分布算法,什么指数损失函数之后有点迷糊了。抛开这些理论性的推导不谈(其实是因为能力有限),通过例子直观的了解AdaBoost算法的计算过程。
简要叙述一下AdaBoost算法的主要过程:
AdaBoost为每个数据样本分配权重,权重符合概率分布,初始权重符合均匀分布,串行训练M个模型,依据每轮训练的模型的错误率(被误分类样本的权重之和)确定当前模型在最终模型中的权重,以及更新训练样本的权重,误分类样本权重升高,分类正确的样本权重降低。
下图的算法流程来自于《统计学习方法》。


下面通过具体的实例来理解AdaBoost算法的流程,例子来自于《统计学习方法》。

第一轮迭代:

此时得到的组合模型中只有一个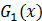 ,此时
,此时 的分类结果就是最终模型的分类结果。第一轮迭代中6,7,8(6,7,8指的是x的值,不是指的序号)被误分类。此时得到的组合模型在训练数样本上的预测结果如下:
的分类结果就是最终模型的分类结果。第一轮迭代中6,7,8(6,7,8指的是x的值,不是指的序号)被误分类。此时得到的组合模型在训练数样本上的预测结果如下:
| X |
y |

|

|

|
分类结果 |
| 0 |
1 |
0.4236 |
0.4236 |
1 |
正确 |
| 1 |
1 |
0.4236 |
0.4236 |
1 |
正确 |
| 2 |
1 |
0.4236 |
0.4236 |
1 |
正确 |
| 3 |
-1 |
-0.4236 |
-0.4236 |
-1 |
正确 |
| 4 |
-1 |
-0.4236 |
-0.4236 |
-1 |
正确 |
| 5 |
-1 |
-0.4236 |
-0.4236 |
-1 |
正确 |
| 6 |
1 |
-0.4236 |
-0.4236 |
-1 |
错误 |
| 7 |
1 |
-0.4236 |
-0.4236 |
-1 |
错误 |
| 8 |
1 |
-0.4236 |
-0.4236 |
-1 |
错误 |
| 9 |
-1 |
-0.4236 |
-0.4236 |
-1 |
正确 |
其中sign符号函数如下:

第二轮迭代:

第二轮迭代中3,4,5被误分类,此时得到的最终模型是前两轮模型的线性组合。那么在当前的组合条件下 的分类结果是怎样的?
的分类结果是怎样的?
| X |
y |

|

|

|

|
分类结果 |
| 0 |
1 |
0.4236 |
0.6496 |
1.0732 |
1 |
正确 |
| 1 |
1 |
0.4236 |
0.6496 |
1.0732 |
1 |
正确 |
| 2 |
1 |
0.4236 |
0.6496 |
1.0732 |
1 |
正确 |
| 3 |
-1 |
-0.4236 |
0.6496 |
0.226 |
1 |
错误 |
| 4 |
-1 |
-0.4236 |
0.6496 |
0.226 |
1 |
错误 |
| 5 |
-1 |
-0.4236 |
0.6496 |
0.226 |
1 |
错误 |
| 6 |
1 |
-0.4236 |
0.6496 |
0.226 |
1 |
正确 |
| 7 |
1 |
-0.4236 |
0.6496 |
0.226 |
1 |
正确 |
| 8 |
1 |
-0.4236 |
0.6496 |
0.226 |
1 |
正确 |
| 9 |
-1 |
-0.4236 |
-0.6496 |
-1.0732 |
-1 |
正确 |
第三轮迭代:


第三轮迭代中0,1,2,9被误分类,此时得到的最终模型是前三轮模型的线性组合。那么在当前的组合条件下 的分类结果是怎样的?
的分类结果是怎样的?
| X |
y |

|

|

|

|
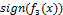
|
分类结果 |
| 0 |
1 |
0.4236 |
0.6496 |
-0.7514 |
0.3218 |
1 |
正确 |
| 1 |
1 |
0.4236 |
0.6496 |
-0.7514 |
0.3218 |
1 |
正确 |
| 2 |
1 |
0.4236 |
0.6496 |
-0.7514 |
0.3218 |
1 |
正确 |
| 3 |
-1 |
-0.4236 |
0.6496 |
-0.7514 |
-0.5254 |
-1 |
正确 |
| 4 |
-1 |
-0.4236 |
0.6496 |
-0.7514 |
-0.5254 |
-1 |
正确 |
| 5 |
-1 |
-0.4236 |
0.6496 |
-0.7514 |
-0.5254 |
-1 |
正确 |
| 6 |
1 |
-0.4236 |
0.6496 |
0.7514 |
0.9774 |
1 |
正确 |
| 7 |
1 |
-0.4236 |
0.6496 |
0.7514 |
0.9774 |
1 |
正确 |
| 8 |
1 |
-0.4236 |
0.6496 |
0.7514 |
0.9774 |
1 |
正确 |
| 9 |
-1 |
-0.4236 |
-0.6496 |
0.7514 |
-0.3218 |
-1 |
正确 |
经过三轮迭代之后,在训练集上的错误率为0。
AdaBoost是如何侧重于误分类的样本的?
经过上面的算法流程介绍,下面我们就来通过一个简图看一下AdaBoost是如何通过调整训练样本的权重来是模型逐步关注分类错误的样本的。

1、初始化权重。首先在第1轮的时候,初始化一个权重分布
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)