整理不易,希望对各位学习软件测试能带来帮助
第七章 引入测试报告与结构优化
我想在开始本章的学习之前先来先来回顾一下目前的测试结构,因为本章节会对结构做一个改进,以
帮助我们更好的实施自动化测试。

本章的重点就是抛弃 log.txt 这种丑陋日志文件,引入漂亮的 HTMLTestRunner 测试报告,并且对目前的结构做一些调整,其实能适合 HTMLTestRunner 报告的生成,另一方面使用例更容易编写和扩展。
第一节、生成 HTMLTestRunner 测试报告
在脚本运行完成之后,除了在 log.txt 文件看到运行日志外,我们更希望能生一张漂亮的测试报告来展
示用例执行的结果。
HTMLTestRunner 是 Python 标准库的 unittest 模块的一个扩展。它生成易于使用的 HTML 测试报告。
HTMLTestRunner 是在 BSD 许可证下发布。
首先要下 HTMLTestRunner.py 文件,下载地址:
http://tungwaiyip.info/software/HTMLTestRunner.html
Windows :将下载的文件放入…\Python27\Lib 目录下。
Linux(ubuntu):下需要先确定 python 的安装目录,打开终端,输入 python 命令进入 python 交互模
式,通过 sys.path 可以查看本机 python 文件目录,如图
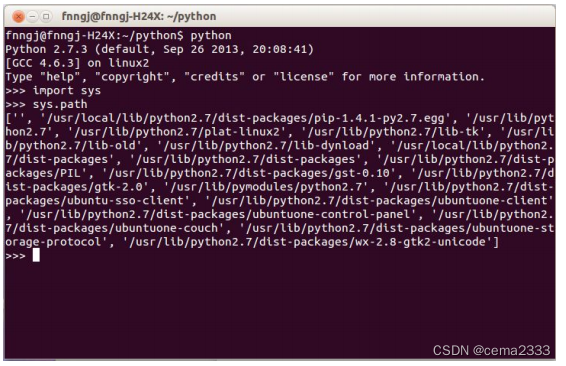
以管理员身份将 HTMLTestRunner.py 文件考本到/usr/lib/python2.7/dist-packages/ 目录下:
root@user-H24X:/home/user/python# cp HTMLTestRunner.py /usr/lib/python2.7/dist-packages/
(提示,切换到 root 用户切换才能拷贝文件到系统目录)
在 python 交互模式引入 HTMLTestRunner 包,如果没有报错,则说明添加成功。
>>> import HTMLTestRunner
>>>
下面继续以 baidu.py 文件为例生成 HTMLTestRunner 测试报告:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
import unittest, time, re
import HTMLTestRunner #引入 HTMLTestRunner 包
class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.verificationErrors = []
self.accept_next_alert = True
#百度搜索用例
def test_baidu_search(self):
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("kw").send_keys("selenium webdriver")
driver.find_element_by_id("su").click()
time.sleep(2)
driver.close()
#百度设置用例
def test_baidu_set(self):
driver = self.driver
#进入搜索设置页
driver.get(self.base_url + "/gaoji/preferences.html")
#设置每页搜索结果为 100 条
m=driver.find_element_by_name("NR")
m.find_element_by_xpath("//option[@value='100']").click()
time.sleep(2)
#保存设置的信息
driver.find_element_by_xpath("/html/body/form/div/input").click()
time.sleep(2)
driver.switch_to_alert().accept()
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
#定义一个单元测试容器
testunit=unittest.TestSuite()
#将测试用例加入到测试容器中
testunit.addTest(Baidu("test_baidu_search"))
testunit.addTest(Baidu("test_baidu_set"))
#定义个报告存放路径,支持相对路径
filename = 'D:\\selenium_python\\report\\result.html'
fp = file(filename, 'wb')
#定义测试报告
runner =HTMLTestRunner.HTMLTestRunner(
stream=fp,
title=u'百度搜索测试报告',
description=u'用例执行情况:')
#运行测试用例
runner.run(testunit)
代码分析:
import HTMLTestRunner
要使用 HTMLTestRunner 首先要导入模块
TestSuite()
在第六章 unittest 单元测试框架解析中有过讲解,TestSuite()可以被看作一个容器(测试套件),
通过 addTest 方法我们可罗列具体所要执行的测试用例。当然了,如果使用 unittest.main() 的话默认会执
行所有以 test 开头的测试用例。
filename = 'D:\\selenium_python\\report\\result.html'
fp = file(filename, 'wb')
定位报告文件的存放路径。
runner =HTMLTestRunner.HTMLTestRunner(
stream=fp,
title=u'百度搜索测试报告',
description=u'用例执行情况:')
定义 HTMLTestRunner 测试报告,stream 定义报告所写入的文件;title 为报告的标题;description 为报告的说明与描述。
runner.run(testunit)
运行测试容器中的用例,并将结果写入的报告中。
脚本运行结束,生成测试报告,如图
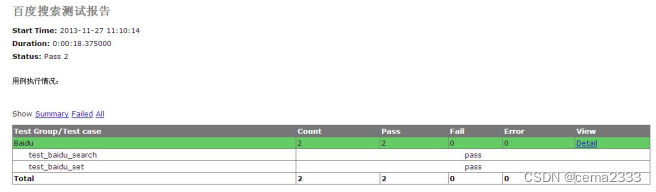
问题思考:
这个报告是根据一个.py 文件生成的,这样就迫使我们把所有用例都写在一个.py 文件里,如果我们每一个用例都写在不同的.py 文件里将生成很多个报告,这样做不便于阅读;但写在一个.py 文件里,如果用例非常多的话,同样不便于维护。下面将进一步学习 TestSuite 的使用以帮助我们解决这个问题。
第二节、测试套件
现在我们来进一步学习 TestSuite(测试套件)的使用,从来帮助我们解决上一节中的遗留问题。我们
之前使用 TestSuite 只是在一个.py 文件里添加多个测试用例,那么可不可以法把多个.py 文件中的用例通过测试套件来组织?答案是肯定。这一节就来解决这个问题,我们最终要达到的目的如图 7.3。
通过测试套件组织的用例结构:
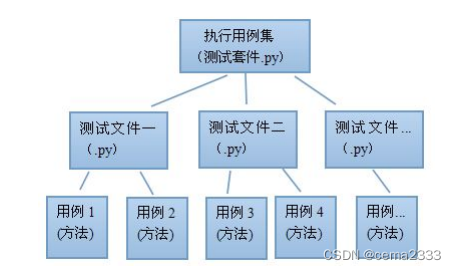
测试套件的问题解决了,所有用例生成一张测试报告的问题自然也可以解决了。
7.2.1、测试套件实例
下面通过一个完整例子来说明如何通过套件组建我们的测试用例。
baidu.py
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
import unittest, time, re
class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.verificationErrors = []
self.accept_next_alert = True
#百度搜索用例
def test_baidu_search(self):
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("kw").send_keys("selenium webdriver")
driver.find_element_by_id("su").click()
time.sleep(2)
driver.close()
#百度设置用例
def test_baidu_set(self):
driver = self.driver
#进入搜索设置页
driver.get(self.base_url + "/gaoji/preferences.html")
#设置每页搜索结果为 100 条
m=driver.find_element_by_name("NR")
m.find_element_by_xpath("//option[@value='100']").click()
time.sleep(2)
#保存设置的信息
driver.find_element_by_xpath("/html/body/form/div/input").click()
time.sleep(2)
driver.switch_to_alert().accept()
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
youdao.py
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
import unittest, time, re
class Youdao(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://www.youdao.com"
self.verificationErrors = []
self.accept_next_alert = True
#有道搜索用例
def test_youdao_search(self):
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("query").send_keys(u"虫师")
driver.find_element_by_id("qb").click()
time.sleep(2)
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
上面的两个测试用例文件分析,baidu.py 文件编写了两种用例,youdao.py 文件中编写一条用例,分
别运行两个用例文件都可以正常的进行测试。
下面我们创建 all_tests.py 文件,通过套件的方式来执行这两个文件里的三条用例(注意,all_tests.py 文件要与 baidu.py 和 youdao.py 在同一目录下):
#coding=utf-8
import unittest
#这里需要导入测试文件
import baidu,youdao
testunit=unittest.TestSuite()
#将测试用例加入到测试容器(套件)中
testunit.addTest(unittest.makeSuite(baidu.Baidu))
testunit.addTest(unittest.makeSuite(youdao.Youdao))
#执行测试套件
runner = unittest.TextTestRunner()
runner.run(testunit)
运行结果:
>>> ================================ RESTART ================================
>>>
...
Time Elapsed: 0:00:23.922000
这里与前面稍有不同的是用到了 unittest 的 makeSuite:
makeSuite 用于生产 testsuite 对象的实例,把所有的测试用例组装成 TestSuite,最后把 TestSuite 传给
TestRunner 进行执行。
baidu.Baidu
baidu 为导入的.py 文件,Baidu 为类名,调用类名,默认类下面的所有以 test 开头的方法(测试用例)
会被执行。
7.2.2、整合 HTMLTestRunner 测试报告
通过测试套件解决执行多个测试文件的问题,那么生成多个测试文件的 HTMLTestRunner 报告的问题
自然也解决了。打开 all_tests.py 文件,将生成 HTMTestRunner 报告的相关代码添加进来:
#coding=utf-8
import unittest
#这里需要导入测试文件
import baidu,youdao
import HTMLTestRunner
testunit=unittest.TestSuite()
#将测试用例加入到测试容器(套件)中
testunit.addTest(unittest.makeSuite(baidu.Baidu))
testunit.addTest(unittest.makeSuite(youdao.Youdao))
#执行测试套件
#runner = unittest.TextTestRunner()
#runner.run(testunit)
#定义个报告存放路径,支持相对路径。
filename = 'D:\\selenium_python\\report\\result2.html'
fp = file(filename, 'wb')
runner =HTMLTestRunner.HTMLTestRunner(
stream=fp,
title=u'百度搜索测试报告',
description=u'用例执行情况:')
#执行测试用例
runner.run(testunit)
本例中并没有引入新方法,希望读者能将代码敲写一遍,认真体会代码的含义。
下面查看 D:\selenium_python\report\目录下所生成有报告:
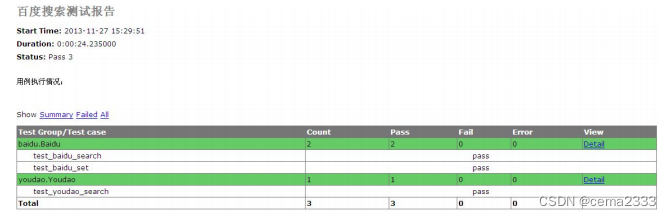
多个测试用例(.py)文件被整合到一个报告中的,这样在编写新的测试用例后,在 all_tests.py 文件中
添加到测试套件中就可以了。
7.2.3、易读的测试报告
虽然在我们在测试用例开发时为每个用例添加了注释,但测试报告一般是给非测试人员阅读的,如果能在报告中为每一个测试用例添加说明,那么将会使报告更加易于阅读。
打开我们的测试用例文件,为每一个测试用例(方法)下面添加注释,如下:
……
#百度搜索用例
def test_baidu_search(self):
u"""百度搜索"""
driver = self.driver
driver.get(self.base_url + "/")
……
再次打开生成的测试报告:

小 u 是避免中文引起的乱码问题。有读者可能会对三引号的作用比好奇。
这里再来回顾一下引号的使用:
单双引号的使用:
#输出字符串
>>> print 'abc'
abc
>>> print "abc"
abc
输出带引号的字符串
>>> print "ab'c'de"
ab'c'de
>>> print 'ab"c"d'
ab"c"d
>>> print "ab"c"d"
SyntaxError: invalid syntax
在 python 中是不区分单双引号的,但必须要成对出现。而且引号之间左则开始找最近一个引号默认和
自己是一对,如:“ab"c"d” ,被拆分为"ab"、c、“d” ,因为 c 不是字符串,所以,就会提示语法错误。
三引号的使用:
>>> print """ 我可以写
任意多行
的注释
"""
我可以写
任意多行
的注释
>>> a= ''' 任意多行的
注释
'''
>>> print a 任意多行的
注释
三引号用于表示多行注释,同样三引号也不分单双,而且我们可以把一个多行注释做为一个字符串赋
值给一个变量。
再来看看函数下面的三引号使用:
>>> def fun(a=3,b=5):
"""加法运算的函数"""
c= a+b
print c
>>> fun()
8
>>> help(fun)
Help on function fun in module __main__:
fun(a=3, b=5)
加法运算的函数
定一个 fun()函数并在函数下面加注释,调用函数时并没有发现注释信息,但是使用 help()查看 fun 函数,然后注释信息就显示出来了。我们编写的类下面的测试用例方法也是一样的原理。
7.2.3、报告文件名取当前时间
每次运行测试之前之前都要手动的去修改报告的名称,如果有修改就会把之前的报告覆盖,这样做就
会显示得很麻烦,那么有没有办法使每次生成的报告名称都不一样,为了更好的取分报告可以在报告中添加当前的时间,这样我们要想查找某天某时所生成的报告就会变得非常容易。
对于 time 模块来说我们并不陌生,一直在使用 sleep()给测试用例程序添加休眠时间,那么有没有取当
前时间的方法?下面打开 python IDLE 学习 time 下面的几个新方法。
>>> time.time()
1385701893.75
>>> time.ctime()
'Fri Nov 29 13:14:41 2013'
>>> time.localtime()
time.struct_time(tm_year=2013, tm_mon=11, tm_mday=29, tm_hour=13, tm_min=11,
tm_sec=22, tm_wday=4, tm_yday=333, tm_isdst=0)
>>> time.strftime("%Y%m%d%H%M%S", time.localtime())
'20131129131356'
>>> time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
'2013-11-29 13:14:06'
time.time() 获取当前时间戳
time.localtime() 当前时间的 struct_time 形式
time.ctime() 当前时间的字符串形式
time.strftime(“%Y-%m-%d %H:%M:%S”, time.localtime())
如:2013-11-29 13:14:06
我们已经知道了 time 下面的这个方面的可以取到前面实践,我们要做的就是把取到的当前时间加到测试报告的文件名中。
打开 all_test.py 做如下修改:
……
#取前面时间
now = time.strftime("%Y-%m-%M-%H_%M_%S",time.localtime(time.time()))
#把当前时间加到报告中
filename = "D:\\selenium_python\\report\\"+now+'result.html'
fp = file(filename, 'wb')
runner =HTMLTestRunner.HTMLTestRunner(
stream=fp,
title=u'百度搜索测试报告',
description=u'用例执行情况:')
……
重新运行所有测试用例,查看生成的测试报告的文件名,如图 6.x 中最上面文件,文件名以前面运行
实践命名,所以很容易地找到想要的报告,而且在每次运行测试前不用修改手动修改报告的名字。
第三节、结构改进
到目前为止,我们已经成功的解决了通过测试套件执行多个测试用例文件的问题,并且将输出结果整合在一个测试报告里,目的达到了。但目前的测试结构并不合理,我们需要进一步对结构进行调整,以便于测试的维护是管理。
7.3.1、all_tests.py 文件移出来
我们首先要调整的是 all_tests.py 文件的位置, all_tests.py 是执行所有用例的程序,而并非测试用例本
身,所以应该把它移出来。结构上会更为合理。

目录结构应该是这样的,test_case 目录下存放具体的执行用例,all_tests.py 应该从 test_case 目录分离
出来。那么直接把 all_tests.py 文件移出来后运行一下:
>>> ================================ RESTART ================================
>>>
Traceback (most recent call last):
File "D:\selenium_python\all_tests.py", line 5, in <module>
import baidu,youdao
ImportError: No module named baidu
提示我们找不到 baidu 和 youdao 两个文件;修改 all_tests.py 文件,另外,需要在 test_case 目录下创
建一个__init__.py 文件,文件内容可以为空。将 D:\selenium_python\test_cast 目录添加到 sys.path 下:
#coding=utf-8
import unittest
#把 test_case 目录添加到 path 下,这里用的相对路径
import sys
sys.path.append("\test_case")
from test_case import youdao
from test_case import baidu
#这里需要导入测试文件
import baidu,youdao
……
现在可以正常运行 all_tests.py 文件了,init.py 文件的作用是什么?为什么需要将测试目录添加到
系统的 path 才能调用?下一小节解析__init__.py 文件的作用。
7.3.2、init.py 文件解析
关于__init__.py 文件的作用,老王 python 的博客中清晰的说明,这里引用截取博客中的部作内容,帮
助理解。
还记得上面提到的__init__.py 文件吧,这文件是干嘛的,为什么要在引用的目录下加这个文件?
要弄明白这个问题,首先要知道,python 在执行 import 语句时,到底进行了什么操作,按照 python 的文档,它执行了如下操作:
第 1 步,创建一个新的,空的 module 对象(它可能包含多个 module);
第 2 步,把这个 module 对象插入sys.module 中
第 3 步,装载 module 的代码(如果需要,首先必须编译)
第 4 步,执行新的 module中对应的代码。
在执行第 3 步时,首先要找到 module 程序所在的位置,搜索的顺序是:
当前路径 (以及从当前目录指定的sys.path),然后是 PYTHONPATH,然后是 python 的安装设置相关的 默认路径。正因为存在这样的顺序,如果当前路径或PYTHONPATH 中存在与标准 module 同样的 module,则 会覆盖标准 module。也就是说,如果当前目录下存在xml.py,那么执行 import xml 时,导入的是当前目录下 的 module,而不是系统标准的 xml。
了解了这些,我们就可以先构建一个 package,以普通 module 的方式导入,就可以直接访问此 package 中的各个 module了。python 中的 package 必须包含一个__init__.py 的文件。
------以上引用“老王 python”
理解了上面这段话也就明白了为什么,all_tests.py 和测试用例(.py)文件在一个目录下时可以正
常调用,移出来之后就提示找不到模块了;python 查找模块是先从当前目录下查找,如果找不到再到
python 的安装设置的相关路径下查找。这也是为什么我们把 D:\selenium_python\test_cast 目录添加到
系统 path 下,就可以正常的调用了。为了标识一下目录是可引用的包,那么就需要在目录下创建一个
__ init__.py 文件。
其实__init__.py 文件中可以有内容;我们在导入一个包时,实际上导入了它的__init__.py 文件。
在__init__.py 文件中添加导入包。
import baidu
import youdao
然后,all_tests.py 文件可是这样修改:
#coding=utf-8
import unittest
import sys
sys.path.append("\test_case")
from test_case import *
“*” 星号表示导入 test_case 目录下的所有文件;在 test_case 目录下创建新的测试用例文件,只用在__init__.py 文件下添加就可以了。而对于 all_tests.py 文件来说不需要做任何修改。
7.3.3、把公共模块文件移进去
理解 python 调用包的机制,那么就可以随意的调整我们目录结构,使其更便于管理。在第五章中,我们 webcloud.py 测试用例的登录和退出进行了模块化,分别创建了 login.py 和 quit_login.py 两个文件,他们属于公共模块,并非完整的用例本身,所以我们可以单独创建一个文件夹,将他们移进去。
在 test_case 目录下创建 public 目录,把 login.py 和 quit_login.py 文件移进去。同样需要在 public
目录下创建空的__init__.py 文件;同时修改 test_case 目录下的 webcloud.py 文件:
#把 public 目录添加到 path 下,这里用的相对路径
import sys
sys.path.append("\public")
#导入登录、退出模块
from public import login
from public import quit_login ……
#私有云登录用例
def test_login(self):
driver = self.driver
driver.get(self.base_url +
"/login/?referrer=http%3A%2F%2Fwebcloud.kuaibo.com%2F")
#调用登录模块
login.login(self)
#调用退出模块
quit_login.quit_(self)
……
关于模块的创建与调用请参考本书第四章内容。
第四节、用例的读取
7.3.1、改进用例的读取
打开 all_tests.py 文件,虽然导入包的部分我们用“from test_case import * ”方便的替换具体
导入每个文件的做法,但在测试套件部分,我们会发现每创建一条用例(.py 文件)都需要在测试套件中
添加,随着用例的增加,测试套件可能要罗列几百上千条用例,非常不便于管理。
....
testunit=unittest.TestSuite()
#将测试用例加入到测试容器(套件)中
testunit.addTest(unittest.makeSuite(baidu.Baidu))
testunit.addTest(unittest.makeSuite(youdao.Youdao))
testunit.addTest(unittest.makeSuite(webcloud.Login))
.....
那么我们可不可以通过一个 for 循环来解决这个问题,首先需要把用例文件组装一数组,通过循环读取的方法来读取测试套件中的每一条用例;
先来熟悉一下 python 中数组的使用,继续在 python 交互模式下练习。
>>> array = [1,2,3]
>>> print array
[1, 2, 3]
>>> array2=['a','b','c']
>>> print array
[1, 2, 3]
>>> array3=['abc',123,"中国人"]
>>> for data in array3:
print data
abc
123
中国人
数组中括号表示,里面元素之间用逗号分割;可以数字或字符串,我们通过 for 语句可以循环读取数组的元素。
下面和我一起动手来实现这个功能吧!修改后 all_tests.py 文件如下:
#coding=utf-8
import unittest
#把 test_case 目录添加到 path 下,这里用的相对路径
import sys
sys.path.append("\test_case")
#导入 test_case 目录下的所有文件
from test_case import *
import HTMLTestRunner
#将用例组装数组
alltestnames = [
baidu.Baidu,
youdao.Youdao,
webcloud.Login,
]
#创建测试套件
testunit=unittest.TestSuite()
#循环读取数组中的用例
for test in alltestnames:
testunit.addTest(unittest.makeSuite(test))
#定义个报告存放路径,支持相对路径
filename = 'D:\\selenium_python\\report\\result.html'
fp = file(filename, 'wb')
runner =HTMLTestRunner.HTMLTestRunner(
stream=fp,
title=u'百度搜索测试报告',
description=u'用例执行情况:')
#执行测试用例
runner.run(testunit)
为了使 all_tests.py 文件在用例增加或删除时不需要做任何修改,我们可把 alltestnames 数组放到
一个单独的文件中,创建 allcase_list.py 文件,与 all_tests.py 保持同级目录:
#coding=utf-8
#把 test_case 目录添加到 path 下,这里用的相对路径
import sys
sys.path.append("\test_case")
from test_case import *
#用例文件列表
def caselist():
alltestnames = [
baidu.Baidu,
youdao.Youdao,
webcloud.Login,
]
print "success read case list!!"
return alltestnames
因为在 allcase_list.py 文件调用用例,所以,我们也需要把导入用例文件的相关操作移动过来。这
样 all_tests.py 文件将会显得更加清爽,下面在 all_tests.py 文件中调用 caselist 函数:
……
import allcase_list #调用数组文件
#获取数组方法
alltestnames = allcase_list.caselist()
……
再次运行 all_tests.py 文件。发现可以正常的实现用例的读取。
7.3.2、discover 解决用例的读取
回顾一下,到目前位置,我们的结构复杂了很多,处理问题的过程也变得复杂的很多,假如我们创建了一条用例 aaa.py,需要在用例当前目录下打开__init__.py 文件,添加“import aaa”;还需要打开allcase_list.py 文件,在 alltestnames 数组中添加 aaa.calss_name 。然后,用例才能添加到测试套件
中执行。
在第三章中我们通过编写一个 python 小程序可以轻松地解决用例文件的读取,这所以会变得复杂,一方面是我们模块化一部分代码,最主要的原因是引入了 HTMLTestRunner 测试报告,接着为了整合报告不得不利用测试套件来读取用例。
那么 unittest 有没有提供一种简单的方法,可以通过文件的名称来判断是否为测试用例文件,如何为用例文件则自动添加到测试套件中。有的,通过查询文档发现 unittest 的 TestLoader 成员下面提供了discover()方法可解决这个问题。
TestLoader:测试用例加载器,其包括多个加载测试用例的方法。返回一个测试套件。
discover(start_dir,pattern=‘test*.py’,top_level_dir=None)
找到指定目录下所有测试模块,并可递归查到子目录下的测试模块,只有匹配到文件名才能被加载。如果启动的不是顶层目录,那么顶层目录必须要单独指定。
start_dir :要测试的模块名或测试用例目录。
pattern=‘test*.py’ :表示用例文件名的匹配原则。星号“*”表示任意多个字符。
这里需要说明一个测试用例的创建规则:我们在实际的测试用开发中用例的创建也应该分两个阶段,用例刚在目录下被创建,可命名为 aa.py ,当用例创建完成并且运行稳定后再添加到测试套件中。那么可
以将 aa.py 重新命名为 start_aa.py ,那么测试套件在运行时只识别并运行 start 开头的.py 文件。
理解了这个规则,我们就可以按照一个约定来命名自己用例文件名。这里我们将 baidu.py 、youdao.py
和 webcoud.py 三个文件重命名为以 start_开头。
top_level_dir=None:测试模块的顶层目录。如果没顶层目录(也就是说测试用例不是放在多级目录
中),默认为 None。
理解了 discover()方法的结构,下面看如何应用到实际项目中,打开 all_tests.py 文件:
#coding=utf-8
import unittest
import HTMLTestRunner
import os ,time
listaa='D:\\selenium_python\\test_case'
def creatsuitel():
testunit=unittest.TestSuite()
#discover 方法定义
discover=unittest.defaultTestLoader.discover(listaa,
pattern ='start_*.py',
top_level_dir=None)
#discover 方法筛选出来的用例,循环添加到测试套件中
for test_suite in discover:
for test_case in test_suite:
testunit.addTests(test_case)
print testunit
return testunit
alltestnames = creatsuitel()
now = time.strftime('%Y-%m-%M-%H_%M_%S',time.localtime(time.time()))
filename = 'D:\\selenium_python\\report\\'+now+'result.html'
fp = file(filename, 'wb')
runner =HTMLTestRunner.HTMLTestRunner(
stream=fp,
title=u'百度搜索测试报告',
description=u'用例执行情况:')
#执行测试用例
runner.run(alltestnames)
查看生成的 HTML 测试报告:
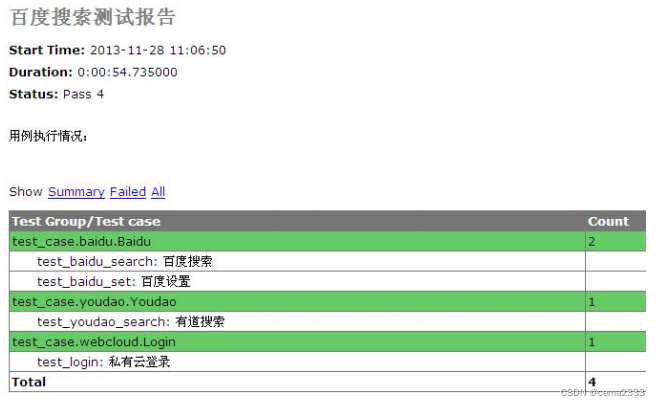
如图虽然生成的报告中,最后一条用例显得和前面的用例不太协调,但是我们的所面临的问题得到了解决,成功的引入并整合和了 HTMLTestRunner 测试报告。通过 discover() 解决了用例读取的麻烦。
回顾当前目录结构:

test_case 目录用于存具体的用例,/test_case/public 目录存入测试用例所调用的公共模块;data
目录用于存放参数化的数据;report 目录用于存放测试报告,,all_case.py 文件执行 test_case 目录中
的测试用例。
总结:
本节对目录结果结构做了很多的调整,起因是为了使用 HTMLTestRunner 测试报告,为了使所有用例文件整合在一个报告中,我们又引入了测试套件,为了使各种文件不至于混乱的放在一个目录下,我们又做文件做了分目录存放。在这个过程中,我们绕了不少弯路,笔者认为每个人的学习过程是这样的,不走弯路永远不知道哪条路最好,而且在这个过程中我们学到了更多 python 编程技术,开阔了解决问题的方法和思路。
未完待续
关注我,每天持续更新软件测试小知识
软件测试打卡交流聚集地点我,每天都有教学直播【暗号:CSDN】