h
w
,
b
(
x
)
=
b
+
w
x
h_{w,b}(x)=b+wx
hw,b(x)=b+wx
w
w
w和
b
b
b是参数,为了方便运算,可以给
x
x
x加上一个
x
0
=
1
x_0=1
x0=1
h
w
,
b
(
x
)
=
b
x
0
+
w
x
1
h_{w,b}(x)=bx_{0}+wx_{1}
hw,b(x)=bx0+wx1
损失函数
J
(
w
,
b
)
=
1
2
m
∑
i
=
1
m
(
h
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
J(w,b)=\frac{1}{2m}\sum_{i=1}^{m}(h_{w,b}(x^{(i)})-y^{(i)})^{2}
J(w,b)=2m1i=1∑m(hw,b(x(i))−y(i))2 为了避免不恰当的数据范围带来损失过大或过小,(例如若数据数值过大,损失可能会在
1
0
5
10^5
105或者
1
0
6
10^6
106这个数量级,不适合直观分析)在评估损失的时候,可以对
h
w
,
b
(
x
(
i
)
)
h_{w,b}(x^{(i)})
hw,b(x(i))和
y
(
i
)
y^{(i)}
y(i)先进行标准化,使得损失数值在可评估的范围内。但在进行梯度下降时,不进行此操作
优化算法——批梯度下降(BGD)
w
j
=
w
j
−
α
∂
∂
w
j
J
(
w
,
b
)
=
w
j
−
α
1
m
∑
i
=
1
m
(
h
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
w_j=w_{j}-\alpha\frac{\partial}{\partial{w_j}}{J(w,b)}=w_{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}{(h_{w,b}(x^{(i)})-y^{(i)})x^{(i)}}
wj=wj−α∂wj∂J(w,b)=wj−αm1i=1∑m(hw,b(x(i))−y(i))x(i)
b
j
=
b
j
−
α
∂
∂
b
j
J
(
w
,
b
)
=
w
j
−
α
1
m
∑
i
=
1
m
(
h
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
b_j=b_{j}-\alpha\frac{\partial}{\partial{b_j}}{J(w,b)}=w_{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}{(h_{w,b}(x^{(i)})-y^{(i)})}
bj=bj−α∂bj∂J(w,b)=wj−αm1i=1∑m(hw,b(x(i))−y(i)) 这里,我们可以使用
θ
\theta
θ统一标识参数,包括
w
w
w和
b
b
b。
即,第
j
j
j个参数
θ
j
\theta_j
θj的更新可以写为:
θ
j
=
θ
j
−
α
∂
∂
w
j
J
(
θ
;
x
)
=
w
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
\theta_{j}=\theta_{j}-\alpha\frac{\partial}{\partial{w_j}}{J(\theta;\mathbf{x})}=w_{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})x^{(i)}}
θj=θj−α∂wj∂J(θ;x)=wj−αm1i=1∑m(hθ(x(i))−y(i))x(i) 其中
α
\alpha
α是学习率。
2. 多变量线性回归
多变量线性回归试图找出多个变量和预测值之间的关系。例如,房子大小、房子卧室数量和房价之间的关系。
特征缩放(标准化)
在样本的不同特征数值差异过大的时候,基于梯度的优化方法会出现一些问题。例如存在如下回归方程:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
h_{\theta}(x)=\theta_{0}+\theta_{1}x_{1}+\theta_{2}x_{2}
hθ(x)=θ0+θ1x1+θ2x2 假设
x
2
x_{2}
x2的范围是
0
∼
1
0\sim1
0∼1,
x
1
x_1
x1的范围是
1
0
3
∼
1
0
4
10^3\sim10^4
103∼104。我们根据梯度同时优化
θ
0
∼
θ
2
\theta_0\sim\theta_2
θ0∼θ2,使得其均改变了相同的大小,那么显然在输入样本相同的情况下,
θ
1
\theta_1
θ1的变动会比
θ
2
\theta_2
θ2导致更大的输出的变化。这也可以理解为模型对
θ
1
\theta_1
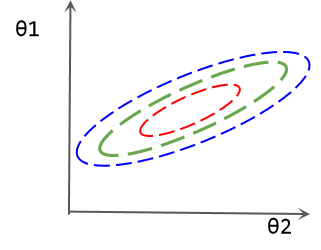
θ1更敏感。如下损失等线图所示,
θ
1
\theta_1
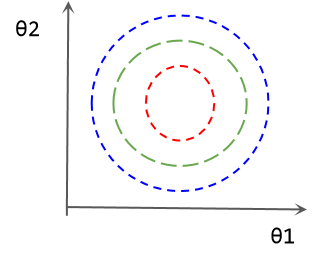
θ1的微小变动会带来损失的剧烈变化。这种情况下,参数的优化会更加困难。 解决这个问题的方法之一就是特征缩放,将两个特征缩放到相同的范围内。例如,可以进行z-score标准化工作:
x
n
e
w
=
x
−
μ
σ
x_{new} = \frac{x-\mu}{\sigma}
xnew=σx−μ 其中,
μ
\mu
μ是数据集的均值,
σ
\sigma
σ是标准差,新数据的分布是均值为0,标准差为1的分布。 数据标准化后的参数等损失图如下所示:
参数的逆缩放
由于对数据进行了缩放,所以最后得到的参数也会出现相应的缩放。其具体关系如下:
θ
0
+
θ
1
∼
d
+
1
x
1
∼
d
+
1
−
μ
x
σ
x
=
y
−
μ
y
σ
y
\theta_{0}+\theta_{1\sim d+1}\frac{x_{1\sim d+1}-\mu_{x}}{\sigma_{x}}=\frac{y-\mu_{y}}{\sigma_{y}}
θ0+θ1∼d+1σxx1∼d+1−μx=σyy−μy 这里我们对
y
y
y也进行了标准化,事实上也可以不这么做,对性能没有任何影响。但是对y的标准化使得参数变得更小,对于初始化为0的参数能更快达到收敛。
在标准化
y
y
y这种情况下,参数的逆缩放公式为:
θ
1
∼
d
+
1
n
e
w
=
θ
1
∼
d
+
1
σ
x
σ
y
\theta_{1\sim d+1}^{new}=\frac{\theta_{1\sim d+1}}{\sigma_{x}}\sigma_{y}
θ1∼d+1new=σxθ1∼d+1σy 得到:
θ
0
σ
y
+
θ
1
∼
d
+
1
n
e
w
(
x
1
∼
d
+
1
−
μ
x
)
=
y
−
μ
y
\theta_{0}\sigma_{y}+\theta_{1\sim d+1}^{new}(x_{1\sim d+1}-\mu_{x})=y-\mu_{y}
θ0σy+θ1∼d+1new(x1∼d+1−μx)=y−μy
θ
0
n
e
w
=
θ
0
σ
y
+
μ
y
−
θ
1
∼
d
+
1
n
e
w
μ
x
\theta_{0}^{new}=\theta_{0}\sigma_{y}+\mu_{y}-\theta_{1\sim d+1}^{new}\mu_{x}
θ0new=θ0σy+μy−θ1∼d+1newμx 其中,在向量化运算时,
θ
1
∼
d
+
1
n
e
w
\theta_{1\sim d+1}^{new}
θ1∼d+1new和
μ
x
\mu_{x}
μx均为(1,d)的向量,乘法应该采用向量内积。
3. 线性回归算法代码实现
向量实现
设数据
x
\boldsymbol{x}
x的维度是
(
n
,
d
)
(n,d)
(n,d),其中n是样本数量,d是样本特征的维度。为了计算方便,我们在样本上添加一个额外数值全为1的特征维度,使其维度变为
(
n
,
d
+
1
)
(n,d+1)
(n,d+1)
预测 令参数
θ
\boldsymbol{\theta}
θ的维度为(1, d+1),则
x
θ
⊤
\boldsymbol{x\theta^{\top}}
xθ⊤或
(
θ
x
⊤
)
⊤
\boldsymbol{(\theta x^{\top})^{\top}}
(θx⊤)⊤可以得到维度为
(
n
,
1
)
(n,1)
(n,1)的预测结果
h
θ
(
x
)
h_{\boldsymbol{\theta}}(\boldsymbol{x})
hθ(x)。
梯度下降 第j个参数的梯度下降公式为:
θ
j
=
θ
j
−
α
∂
∂
w
j
J
(
θ
;
x
)
=
w
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
\theta_{j}=\theta_{j}-\alpha\frac{\partial}{\partial{w_j}}{J(\theta;\mathbf{x})}=w_{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})x^{(i)}}
θj=θj−α∂wj∂J(θ;x)=wj−αm1i=1∑m(hθ(x(i))−y(i))x(i) 事实上,这里我们把
θ
0
\theta_{0}
θ0作为偏置,其梯度应该为:
∂
∂
w
0
J
(
θ
;
x
)
=
w
0
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
\frac{\partial}{\partial{w_0}}{J(\theta;\mathbf{x})}=w_{0}-\alpha \frac{1}{m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})}
∂w0∂J(θ;x)=w0−αm1i=1∑m(hθ(x(i))−y(i)),由于我们在数据中补充了全为1的特征维度
x
0
x_0
x0,所以其可以和其他参数一样使用上面的公式计算。 设
e
r
r
o
r
error
error矩阵
β
\boldsymbol{\beta}
β为
h
θ
(
x
)
−
x
h_{\boldsymbol{\theta}}(\boldsymbol{x})-\boldsymbol{x}
hθ(x)−x,维度为
(
n
,
1
)
(n,1)
(n,1),则
x
⊤
β
/
n
\boldsymbol{x^{\top}\beta} /n
x⊤β/n是维度为
(
d
+
1
,
1
)
(d+1,1)
(d+1,1)的梯度矩阵。
x
⊤
β
=
[
x
(
1
)
x
(
2
)
⋯
]
×
[
h
(
x
(
1
)
)
−
y
(
1
)
h
(
x
(
2
)
)
−
y
(
2
)
⋮
]
=
[
∑
i
=
1
n
(
h
(
x
(
i
)
)
−
y
(
i
)
)
x
0
(
1
)
∑
i
=
1
n
(
h
(
x
(
i
)
)
−
y
(
i
)
)
x
1
(
1
)
⋮
]
\boldsymbol{x^{\top}\beta}= \left[ \begin{matrix} x^{(1)}& x^{(2)} &\cdots \end{matrix} \right] \times \left[ \begin{matrix} h(x^{(1)})-y^{(1)}\\ h(x^{(2)})-y^{(2)}\\ \vdots \end{matrix} \right] =\left[ \begin{matrix} \sum_{i=1}^{n}{(h(x^{(i)})-y^{(i)})x_{0}^{(1)}}\\ \sum_{i=1}^{n}{(h(x^{(i)})-y^{(i)})x_{1}^{(1)}}\\ \vdots \end{matrix} \right]
x⊤β=[x(1)x(2)⋯]×h(x(1))−y(1)h(x(2))−y(2)⋮=∑i=1n(h(x(i))−y(i))x0(1)∑i=1n(h(x(i))−y(i))x1(1)⋮
x
⊤
β
/
n
\boldsymbol{x^{\top}\beta} /n
x⊤β/n中的每个元素就是对应参数的梯度。