增量测试
在执行模块测试过程中,我们主要有两点考虑:第一,如何设计一个有效的测试用例集。第二,将模块组装成工作程序的方式。第二点考虑很重要,因为它涉及模块测试用例编写的形式、可能用到的测试工具类型、模块编码和测试的顺序、生成测试用例的成本以及调试(定位并修复检查出的错误)的 成本等。简而言之,它具有实际重要性。
在这一节中,我们将讨论两类方法,增量 测试和非增量测试。在下一节中,我们将探讨两种增量方法:自顶向下的和自底向 上的开发或测试过程。 这里需要考虑的问题是:软件测试是否应先独立地测试每个模块,然后再将这 些模块组装成完整的程序?还是先将下一步要测试的模块组装到测试完成的模块 集合中,然后再进行测试?第一种方法称为非增量测试或“崩溃(big-bang ) ”测 试,而第二种方法称为增量测试或集成。
图 5-7 所示的程序可作为一个例子。矩形框代表程序的 6 个模块(子程序或过 程),连接模块间的线条代表程序的控制层次,也就是说,模块 A 调用模块 B、C 和 D,模块 B 调用模块 E 等等。作为传统方法的作增量测试是按如下方式进行的: 首先,对 6 个模块中的每一个模块进行单独的模块测试,将每个模块视为一个独立 实体。根据环境(例如,是人机交互式的,还是使用批处理计算工具)和参与人数, 这些模块可以同时或按次序进行测试。最后,将这些模块组装或集成(例如“连接 编辑”)为完整的程序。
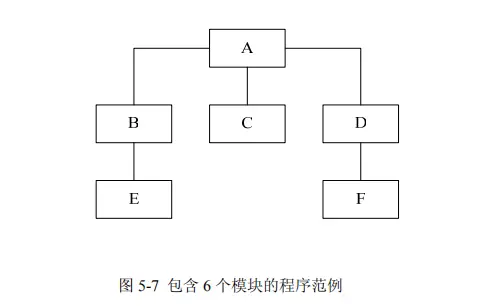
测试单独的模块需要一个特殊的驱动模块(drive module)和一个或多个桩模块 (stub module)。举例来说,测试模块 B,首先要设计测试用例,然后将测试用例作为输入参数由驱动模块传递给模块 B。驱动模块是人们编写的一个小模块,用来将测试用例驱动或传输到被测模块中(也可以用测试工具替代)。驱动模块还必须向 测试人员显示模块 B 的结果。此外,由于模块 B 调用了模块 E,所以还必须使用一 个额外的组件,该组件在模块 B 调用模块 E 时接受模块 B 的控制指令。这就由桩 模块来完成它是一个被命名为“E”的特殊模块,用来模拟模块 E 的功能。当所有 6 个模块的模块测试都完成之后,就将这些模块组装成完整的程序。

另一种可选择的方法是增量测试。不同于独立地测试每个模块,增量测试首先 将下一个要测试的模块组装到前面已经测试过的模块集合中去。
现在要给出对图 5-7 所示的程序进行增量测试的步骤还为时太早,因为还有大 量可能的增量方法。一个关键问题是我们究竟是从程序的顶部开始、还是从底部开 始进行测试。由于这个问题将在下一节中讨论,我们暂且假设从底部开始测试。
第 二步先测试模块 E、C 和 F,可以并行测试(由三个人进行),也可串行进行。请注意,我们必须要为每个模块准备一个驱动模块,但不是桩模块。下一步是测试模块 B 和 D,但不是单独地测试它们,而是分别将其与模块 E 和 F 组装在一起。换言之, 要测试模块 B,应编写驱动模块和集成测试用例,将模块 B 和 E 组合起来测试.
将下一个要测试的模块组装到前面已经测试过的模块集合或子集中去,这个增长的过 程会一直进行到测试完最后一个模块(本例中是模块 A)为止,请注意,这个过程也可以自顶向下进行。下面是几个显而易见的结论:
1. 非增量测试所需的工作量要多一些。对于图 5-7 所示的程序,需要准备 5 个驱动模块和 5 个桩模块(假设顶部的模块不需要驱动模块)。自底向上的 增量测试需要 5 个驱动模块,但不需要桩模块。自顶向下的增量测试需要 5个桩模块,但不需要驱动模块。增量测试所需的工作量要少一些,因为 使用了前面测试过的模块来取代非增量测试中所需要的驱动模块(如果从顶部开始测试)或桩模块(如果从底部开始测试)。
2. 如果使用了增量测试,可以较早地发现模块中与不匹配接口、不正确假设相关的编程错误。这是由于尽早地对模块组合进行了集成测试。然而,如 果采用非增量测试,只有到了测试过程的最后阶段,模块之间才能“互相 看到”。
3. 因此如果使用了增量测试,调试会进行得容易一些,我们假定存在着与模块间接口或假设相关的编程错误(根据经验而来的合理假设),那么,如果使用非增量测试,直到整个程序组装之后,这些错误才会浮现出来。到了 这个时候,我们就难以定位错误。因为它可能存在于程序内部的任何位置, 相反,如果使用增量测试,这种类型的错误就很容易发现,因为该错误很 可能与最近添加的模块有关。
4. 增量测试会将测试进行得更彻底。如果当前正在测试模块 B,要么是模块 E,要么是模块 A(取决于测试是从底部还是从顶部开始的)被当作结果而 执行。虽然模块 E 或模块 A 先前已经进行了完全的测试,但将其作为 B 的 模块测试结果而执行,则会诱发出一个新的情况,可能会暴露出先前测试 过的模块 E 或模块 A 中存在的一个新缺陷。另一方面,如果使用的是非增 量测试,对模块 B 的测试仅影响到其本身。换言之,增量测试使用先前测 试过的模块,取代了非增量测试中使用的桩模块或驱动模块。因此,到最后一个模块测试完成时,实际的模块经受到了更多的检验。
5. 非增量测试所占用的机器时间显得少一些。如果使用自底向上的方法测试 图 5-7 中的模块 A,在执行 A 的过程中,模块 B、C、D、E 和 F 也会执行 到。而在对模块 A 的非增量测试中,仅会执行模块 B、C 和 E 的桩模块。 自顶向下的增量测试的情况也是如此。如果测试的是模块 F,那么在执行 模块 F 时还会执行模块 A、B、C、D 和 E;而在对模块 F 的非增量测试中, 仅有模块 F 的驱动模块与其一起执行。因此,完成一次增量测试所需执行 的机器指令,显然多于采用非增量测试方法所需的指令。但此消彼长的是, 非增量测试要比增量测试需要更多的驱动模块和桩模块,开发这些驱动模 块和桩模块是要占用机器时间的。
6. 模块测试阶段开始时,如果使用的是非增量测试,就会有更多的机会进行 并行操作(也就是说,所有的模块可以同时测试)。对于大型的软件项目〔模 块和人员都很多),这可能十分重要,因为在模块测试开始之时,项目的人 员数量常常处于最高峰。
总的来说,第 1 条~第 4 条结论是增量测试的优点,而第 5、6 条结论是其不 利之处。考虑到计算机行业当前的趋势(硬件成本已经降低而且势必会持续下去, 硬件的功能不断增加,而人力劳动成本和软件错误的代价在不断增长),再考虑到错误发现得越早,改正它的成本也越低,我们会看到第 1 条至第 4 条结论的重要性 日益突出,而第 5 条结论越来越显得不那么重要。
如果有一个缺点的话,第 6 条结 论似乎确是一个薄弱的缺点。从而我们可以得出结论,增量测试要更好一些。