一、基数排序介绍
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序。
多关键字排序:
加入现在一个员工表,要求按照工资排序,年龄相同的员工按照年龄排序。
解决方法:
先按照年龄进行排序,再按照工资进行排序
二、基数排序的实例过程
举例:如对32,13,94,52,17,54,93排序,是否可以看作多关键字排序?
可以,十位看作是第一关键字,个位看作是第二关键字。
排序过程:
第一步:按照个位分桶
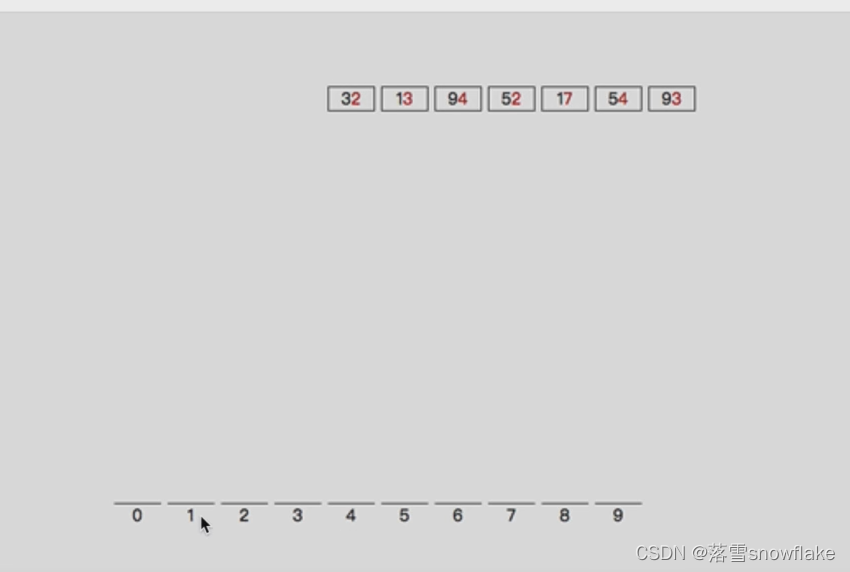
按照个位数分好桶如下图:

第二步:从前往后依次输出:
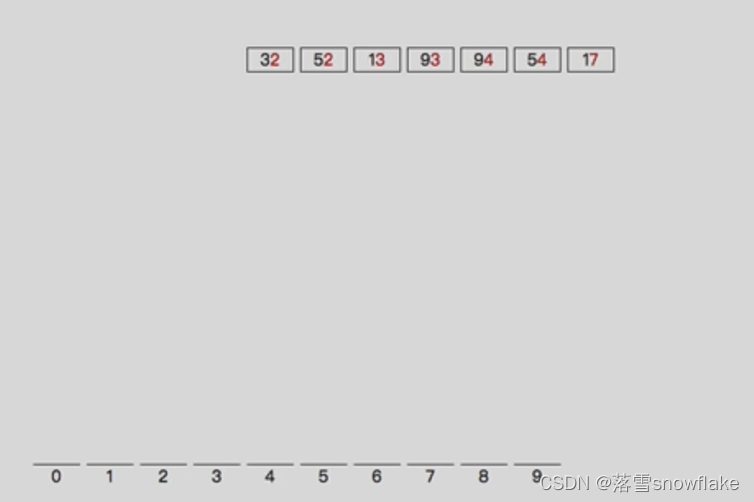
第三步:按照十位数分桶

第四步:出桶
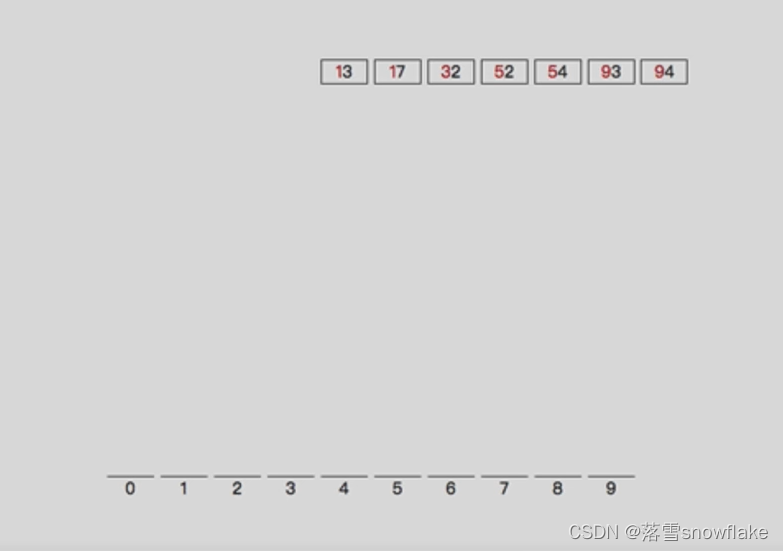
三、基数排序的Python代码实现
def radix_sort(li):
"""基数排序,装桶输出不做排序"""
max_num=max(li)#最大值99->2,888->3,10000->5
it=0
#循环条件:如果10的it次方小于等于max_num
while 10 ** it <=max_num:
buckets=[[] for _ in range(10)] #生成10个桶
for var in li:
"""
取数字个位数的值:987%10 取余
取数字十位数的值:(987//10)%10 取整再取余
取数字百位数的值:(987//100)%10 对100取整再取余
"""
digit=(var//10**it)%10
buckets[digit].append(var)#分桶
#分桶完成,将数据依次取出
li.clear()
for buc in buckets:
li.extend(buc) #将数据重新写回li
it +=1
import random
li=list(range(100))
random.shuffle(li)
print(li)
radix_sort(li)
print(li)
运行结果:
[47, 51, 78, 93, 71, 70, 97, 73, 22, 30, 6, 87, 46, 86, 41, 54, 96, 57, 76, 60, 1, 20, 33, 81, 7, 0, 2, 42, 4, 32, 75, 69, 48, 13, 26, 63, 37, 25, 66, 80, 31, 67, 16, 82, 85, 88, 94, 50, 8, 98, 72, 89, 11, 56, 74, 65, 12, 52, 9, 36, 91, 23, 45, 84, 5, 34, 55, 95, 68, 24, 79, 44, 99, 3, 83, 35, 10, 59, 53, 62, 14, 49, 21, 15, 58, 38, 39, 92, 40, 77, 27, 43, 29, 18, 90, 64, 17, 61, 28, 19]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
Process finished with exit code 0
四、基数排序的算法性能
时间复杂度:O(kn),这里的k = log10n,而快速排序是O(nlog2n)。由此可见基数排序比快排要快。但是当数字范围越来越大,k越来越大时,效率会慢于快排。
空间复杂度:O(k+n),基数排序空间上会消耗一个桶,空间消耗也是比较大的。因此最常用的还是快速排序和python自带的排序。
'''分析函数的写法'''
def list_to_buckets(li,base,iteration):
"""
列表到桶
:param li:
:param base: 分的桶的个数
:param iteration: 装桶是第几次迭代
:return:
"""
buckets = [[] for _ in range(base)]
for number in li:
digit = (number//(base ** iteration))%base
buckets[digit].append(number)
return buckets
def buckets_to_list(buckets):
return [x for bucket in buckets for x in bucket]
'''取到二维数组中的某个值'''
# li = []
# for bucket in buckets:
# for num in bucket:
# li.append(num)
def radix_sort(li,base=10):
maxval=max(li)
it=0
while base **it <=maxval:
li=buckets_to_list(list_to_buckets(li,base,it))
it+=1
return it
import random
li=[random.randint(0,100) for _ in range(10)]
random.shuffle(li)
s=radix_sort(li)
print(s)