1 segment-anything介绍
Segment Anything Model (SAM)来源于Facebook公司Meta AI实验室。据Mata实验室介绍,SAM 已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像领域上即开即用,无需额外的训练。在深度学习领域,这种能力通常被称为零样本迁移(这种能力正是GPT4 震惊世界的一大原因).
图像分割师计算机视觉中的一项关键任务,SAM是第一个致力于图像分割的基础模型。在此之前,分割作为计算机视觉的核心任务,已经得到广泛应用。但是,为特定任务创建准确的分割模型通常需要技术专家进行高度专业化的工作,此外,该项任务还需要大量的领域标注数据,种种因素限制了图像分割的进一步发展。
SAM具有极强的泛化能力,能够泛化到新任务和新领域。这种灵活性在图像分割领域尚属首创。最强大的是,Meta实现了一个完全不同的CV范式,你可以在一个统一框架prompt encoder内,指定一个点、一个边界框、一句话,直接一键分割出物体。
论文地址:segment-anything

1.1 SAM数据集
SA-1B是迄今为止世界上最大的分割数据集。包括来自11M许可和隐私保护图像的超过1B个掩码。SA-1B,使用我们的数据引擎的最后阶段完全自动收集,mask是高质量和多样性的。Meta AI与摄影师合作的供应商那里授权了一组1100万张新图片。这些图像是高分辨率的(平均3300×4950像素),Meta AI将发布其最短边设置为1500像素的降采样图像。明显高于许多现有的视觉数据集(COCO 的480×640像素)
SA-1B 的图像来自多个国家/地区的照片提供商,SA-1B比第二大的Open Images数据集有11倍多的图像和400倍多的掩码,并且经人工评估研究证实,这些掩码具有高质量和多样性,在某些情况下甚至在质量上可与之前更小、完全手动注释的数据集的掩码相媲美。

1.2 SAM模型
网络总共有三个部分:image_encoder、prompt_encoder和mask_decoder。
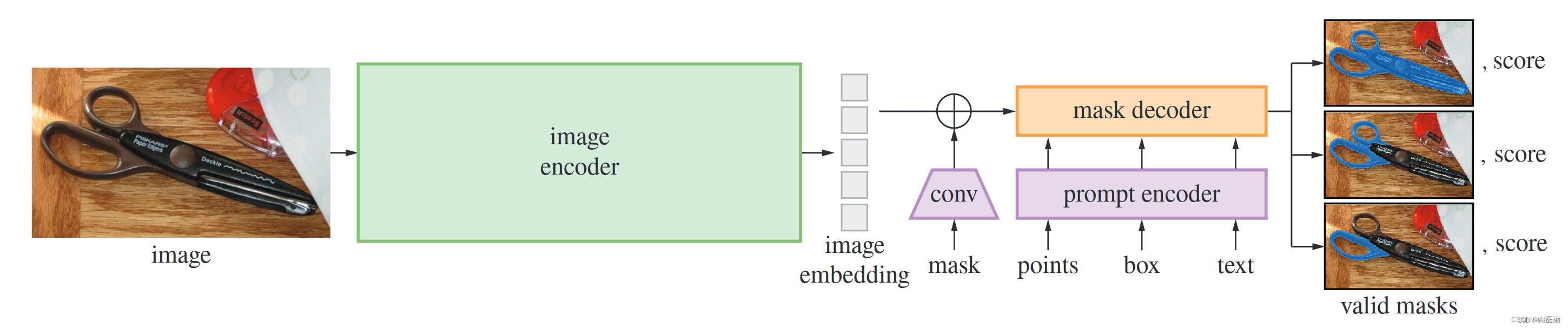
- Image encoder:SAM中的图像编码器采用标准的vit作为图像编码器,原始图像被等比和padding的缩放到1024大小,然后采用kernel size 为16,stride为16的卷积将图像离散化为64x64X768(W,H,C)的向量,向量在W和C上背顺序展平后再进入多层的transformer encoder,vit输出的向量再通过两层的卷积(kernel分别为1和3,每层输出接入layer norm2d)压缩到特征维度为256,具体的图像编码器支持vit-h,vit-l,vit-b,vit经过了MAE方式的预训练,MAE属于图像中自监督学习的一种,在MAE中原始图像如vit切割成不重叠的patch,保留部分patch进入vit架构的encoder进行学习patch的表示,学习到的patch表示和mask(灰色)的表示按照原始的patch顺序输入到vit架构的decoder,得到复原图像。loss为mask部分复原前后的l2 loss。训练完成后我们只使用encoder来提取图像特征
- Prompt encoder:基于分割的任务需求,SAM 支持的prompt包含 point,bbox,free text。在编码方式上,点、bbox(左上点,右下点)采用sincos的位置编码embedding+学习的类别的embedding(一共5种类别,前景和后景的点类别,非点类别、bbox的左上类别、右下类别)
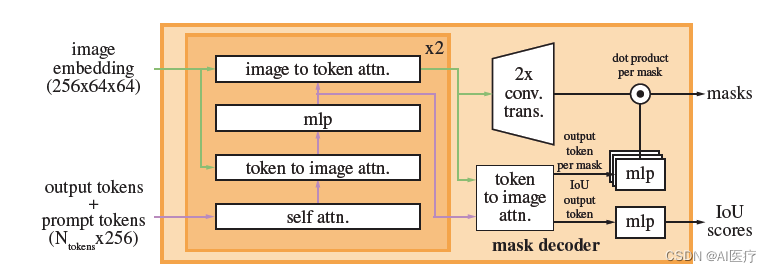
- mask decoder:分别采用clip(ViT-L/14@336px) 预训练好的text encoder 作为文本编码器,image encoder 作为图像编码器取代SAM的图像编码器(ViT-L/14@336px 输出的特征维度为768,而point和bbox的特征维度为256,所以还存在全连接进行特征维度对齐),将文本特征向量和图像特征向量进行l2 norm作为下一步使用。
1.3 数据引擎data engine
为了实现对新数据分布的强泛化,需要在大量和不同的掩码集上训练SAM。在线获取数据缺少mask标注。SAM的方案是构建一个“数据引擎”,SAM与model in the loop的数据集注释共同开发的SAM模型。分三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM协助注释器对掩码进行注释,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示可能的对象位置来为对象子集自动生成掩码,注释器专注于对其余对象的注释,帮助增加掩码的多样性。在最后一个阶段,我们用一个规则的前景点网格提示SAM,平均每张图像产生100个高质量的掩模。
1.4 SAM模型的优势和不同?
与传统图像分割方法相比,Segment Anything模型的优势和不同之处主要有以下几点:
- 不需要大量标注数据:传统的图像分割方法需要大量标注数据才能训练模型,而Segment Anything模型可以在不需要大量标注数据的情况下训练模型。
- 可以对任何物体进行分割:传统的图像分割方法通常只能对特定类型的物体进行分割,而Segment Anything模型可以对图像中的任何物体进行分割。
- 更准确:与传统的图像分割方法相比,Segment Anything模型可以更准确地对图像中的物体进行分割。
- 更快速:由于Segment Anything模型不需要大量标注数据,因此可以更快地训练模型。
通过使用Segment Anything模型,计算机视觉领域的研究人员和开发人员可以更轻松地训练模型,并提高计算机视觉应用程序的性能。
1.5 SAM模型未来发展方向
Segment Anything模型的未来发展方向和应用场景是非常广泛的。该模型可以用于许多计算机视觉应用程序,例如自动驾驶汽车、智能家居、安全监控、医疗图像分析等。此外,该模型还可以用于图像编辑和视频编辑,例如删除不需要的对象、更改背景等。这些应用程序将使我们的生活更加便利和安全。
Segment Anything模型的发布也可能会对计算机视觉行业产生重大影响。它可以帮助研究人员更好地理解图像分割问题,并提供一种新的方法来解决这个问题。此外,它还可以促进计算机视觉领域的进一步研究和发展
2 SAM运行环境构建
2.1 conda环境准备
conda环境准备详见:annoconda
2.2 运行环境安装
conda create -n sam python=3.9
activate sam
pip install torch==1.9.0
pip install torchaudio==0.9.0
pip install torchvision==0.10.0
pip install opencv-python==4.7.0.72
pip install pycocotools==2.0.6
pip install matplotlib==3.7.1
pip install onnxruntime==1.15.1
pip install onnx==1.14.0
git clone https://github.com/facebookresearch/segment-anything
cd segment-anything
pip install -e .
2.3 模型下载
SAM提供了三种型号的预训练模型,分别如下:
模型下载后,存储到根目录的checkpoint文件夹下,存储完成后显示如下:
ll checkpoint/
总用量 4090944
-rw-r--r-- 1 root root 375042383 6月 26 19:57 sam_vit_b.pth
-rw-r--r-- 1 root root 2564550879 6月 26 20:01 sam_vit_h.pth
-rw-r--r-- 1 root root 1249524607 6月 26 20:02 sam_vit_l.pth
3 SAM图片分割
原始图片存储在根目录的data文件夹下,./data/cat-dog.jpg,图片内容如下:

3.1 对指定位置进行分割
使用vit_b模型对图片进行指定位置分割,分割代码如下:
from segment_anything import SamPredictor, sam_model_registry
import numpy as np
import matplotlib.pyplot as plt
import cv2
import torch
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
image = cv2.imread('./data/cat-dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10, 10))
plt.imshow(image)
plt.axis('on')
plt.show()
sam_checkpoint = "./checkpoint/sam_vit_b.pth"
model_type = "vit_b"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
input_point = np.array([[500, 375]])
input_label = np.array([1])
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()
predictor.set_image(image) # 设置要分割的图像
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
for i, (mask, score) in enumerate(zip(masks, scores)):
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i + 1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()
运行代码后,得到的分割效果如下:

3.2 对整个图片进行分割
使用vit_b模型对整个图片进行分割,分割代码如下:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
import numpy as np
import matplotlib.pyplot as plt
import cv2
import torch
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
image = cv2.imread('./data/cat-dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10, 10))
plt.imshow(image)
plt.axis('on')
plt.show()
sam_checkpoint = "./checkpoint/sam_vit_b.pth"
model_type = "vit_b"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image)
plt.figure(figsize=(10, 10))
plt.imshow(image)
plt.axis('on')
plt.show()
plt.figure(figsize=(10, 10))
plt.imshow(image)
for i, mask in enumerate(masks):
show_mask(mask['segmentation'], plt.gca(), True)
# plt.title(f"Mask {i + 1}, Score: {mask['stability_score']:.3f}", fontsize=18)
plt.axis('off')
plt.show()
经过一段时间运行,分割效果如下:

3.3 通过命令行进行分割
通过命令行,使用vit_b的模型对图片进行分割,分割后的结果存储在根目录的output文件夹下:
python scripts/amg.py --checkpoint ./checkpoint/sam_vit_b.pth --model-type vit_b --input ./data/cat-dog.jpg --output ./output
分割结果如下:

有任何问题欢迎随时交流,如果您觉得有帮助,欢迎点赞、关注、收藏