Elasticsearch 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro.html
1. 模拟请求
用于查看 es 服务是否正常启动
# 模拟请求
GET /
2. 分词器相关
ik 分词器是 es 的扩展插件,需要自行安装
ik 分词器开源地址:https://github.com/medcl/elasticsearch-analysis-ik
# 标准分词器
POST /_analyze
{
"analyzer": "standard",
"text": "Hello world!!"
}
# 英文分词器
POST /_analyze
{
"analyzer": "english",
"text": "Hello world!!"
}
# 中文分词器,无效果
POST /_analyze
{
"analyzer": "chinese",
"text": "你好呀!!"
}
# ik分词器-最少模式,分词结果:[程序员]
POST /_analyze
{
"analyzer": "ik_smart",
"text": ["程序员"]
}
# ik分词器-最多模式,分词结果:[程序员,程序,员]
POST /_analyze
{
"analyzer": "ik_max_word",
"text": ["程序员"]
}
3. 索引库相关
下面示例添加了一个名为 blog 的索引库
包含的字段有:id, author, title, content
后续的更新添加了一个 tags 字段
其中,copy_to 用于将字段值复制给 all 字段,将来匹配查询只需对 all 字段匹配即可,避免多字段匹配带来的的性能问题
另外 all 字段内容不会被展示
# 创建索引库
PUT /blog
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"author": {
"type": "keyword",
"copy_to": "all"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"all": {
"type": "text"
, "analyzer": "ik_max_word"
}
}
}
}
# 查询索引库
GET /blog
# 修改索引库(只能添加新字段)
PUT /blog/_mapping
{
"properties": {
"tags": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
}
}
}
# 删除索引库
DELETE /blog
4. 文档相关
文档的增删查改操作示例
其中 blog 为上面创建的索引库
其中 1 为文档的 _id,是字符串类型,而非数字
_id 是每个文档都有的元字段,而非索引库中的 id 属性字段
# 新增文档
# 新增文档
POST /blog/_doc/1
{
"id": "1",
"author": "云中鹤",
"title": "年轻人要制服诱惑",
"content": "必须制服环境中的诱惑,才能做到心中无愧。"
}
# 查询
GET /blog/_doc/1
# 删除
DELETE /blog/_doc/1
# 更新(全量修改,覆盖旧文档)
PUT /blog/_doc/1
{
"id": "1",
"author": "云中鹤",
"title": "此文章不可见"
}
# 更新(增量修改,只更新指定属性)
POST /blog/_update/1
{
"doc": {
"content": "文章已被封禁!"
}
}
5. 查询相关
# ---------- 查询相关 ------------
# match_all 查询所有(有分页限制,并非全部)
GET /blog/_search
{
"query": {
"match_all": {}
}
}
# match 字段匹配查询
GET /blog/_search
{
"query": {
"match": {
"all": "制服"
}
}
}
# multi_match 多字段匹配查询
GET /blog/_search
{
"query": {
"multi_match": {
"query": "制服",
"fields": ["title", "content"]
}
}
}
# term 精确查询(只可指定一个字段)
GET /blog/_search
{
"query": {
"term": {
"author": {
"value": "云中鹤"
}
}
}
}
# range 范围查询(gt 表示大于,lt 表示小于,e 表示包含等于,可只指定一端)
GET /blog/_search
{
"query": {
"range": {
"id": {
"gte": 1,
"lte": 20
}
}
}
}
6. GEO 查询
下例是在 hotel 索引库中,根据 location 字段进行 geo 范围查询(location 之外的均为关键字)
在 geo 坐标中,前为纬度,后为经度
# ---------- GEO 查询 ------------
# distance 以圆心与距离查询
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"location": "39.90, 116.38"
}
}
}
# bounding_box 以矩形范围查询(指定左上与右下两点坐标)
GET /hotel/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 39.90,
"lon": 116.38
},
"bottom_right": {
"lat": 39.00,
"lon": 116.00
}
}
}
}
}
7. 组合查询
- must:必须匹配所有子查询,且运算
- should:选择性匹配子查询,或运算
- must_not:必须不匹配所有子查询,非运算
- filter:必须匹配,效果与 must 相同,但不参与算分
使用 should 同时并列使用了 must 或者 filter,则 should 无效
有下面两种解决方法:
- bool 中添加
"minimum_should_match": 1属性,表示必须至少匹配一个 should 中的条件,若不存在 should 语句,则查不到文档
- 在 must 中嵌套添加 bool 查询,其中只包含 should 查询条件
示例:
# ---------- 组合查询 ------------
# Boolean Query
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "酒店"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"minimum_should_match": 1,
"should": [
{
"term": {
"brand": {
"value": "如家"
}
}
},
{
"term": {
"brand": {
"value": "速8"
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 39.9,
"lon": 116.38
}
}
}
]
}
}
}
8. 得分加权
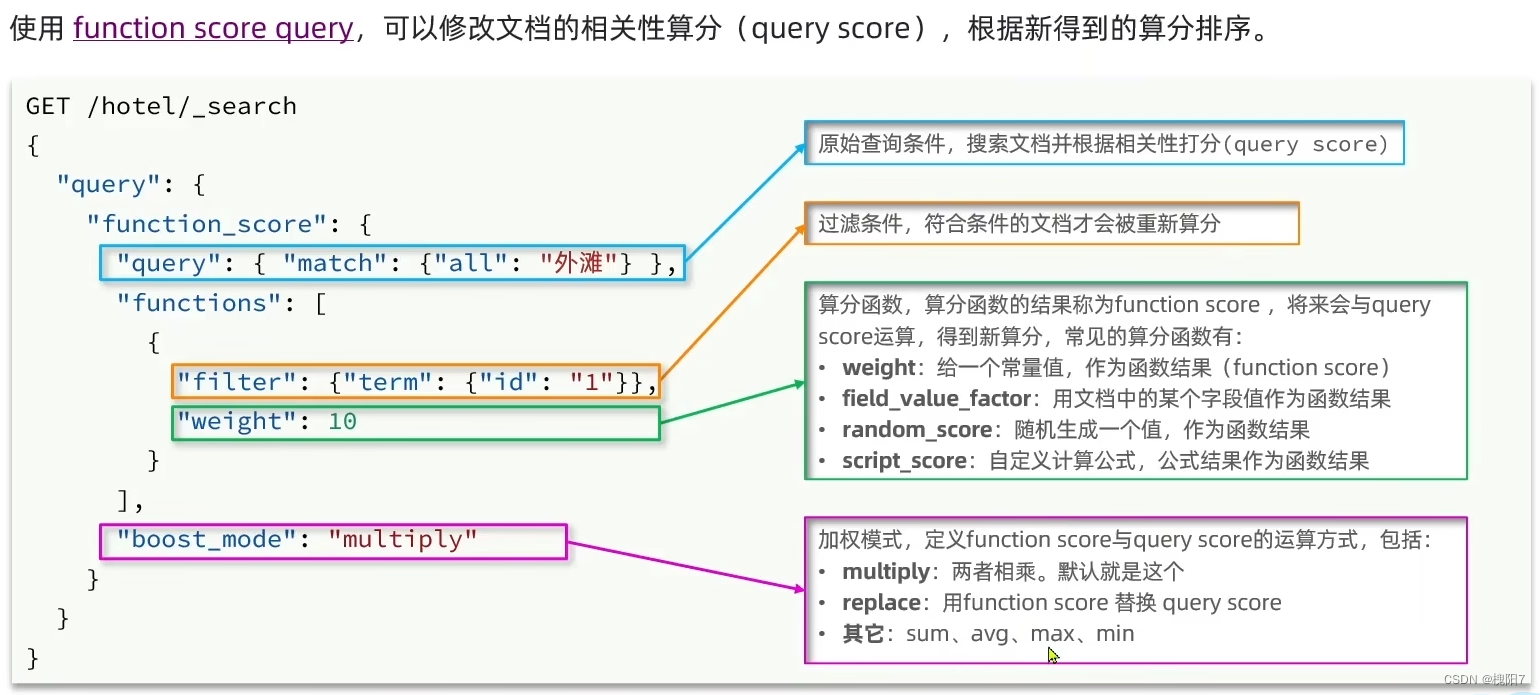 functions 是一个数组,若某一文档符合多个,则使函数结果相乘,再做 boost_mode 的操作
functions 是一个数组,若某一文档符合多个,则使函数结果相乘,再做 boost_mode 的操作
查到的文档中的 _score 字段表示得分
示例:
# Function Score
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "酒店北京"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 10
}
],
"boost_mode": "sum"
}
}
}
9. 排序
可排序的类型有 keyword 类型,数值类型,日期类型,地理坐标距离(字符串按照字典序)
asc 表示升序,desc 表示降序
多个排序规则先按照第一个规则排序,相等时按照下一个规则排序,以此类推
“sort” 属性与最外层的 “query” 并列
查到的文档会有 sort 属性,包含了排序依据的值
示例:
# hotel 为索引库名,price 与 location 为库中字段名
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "asc"
}
},
{
"_geo_distance": {
"location": {
"lat": 39.00,
"lon": 116.00
},
"order": "asc",
"unit": "km"
}
}
]
}
10. 分页
默认只返回前 10 个文档的信息
一般使用 from 与 search_after 两种方式进行分页
from 方式涉及深度分页问题,底层为逻辑分页,可能消耗较大内存,结果集上限为 10,000 条
search_after 方式依赖于排序,通过指定上一页最后一条数据的排序值来搜索下一页,不可随机分页(注意处理相同值问题)
# from + size 分页
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 0,
"size": 10
}
# search_after + size 分页(price 可能相同,但 id 唯一)
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": "asc"
},
{
"id": "asc"
}
],
"search_after": [
0,
0
],
"size": 10
}
11. 高亮
高亮用于强调搜索出的文档中,与搜索词的匹配位置
示例:
# highlight
GET /hotel/_search
{
"query": {
"match": {
"all": "酒店,北京"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false",
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}
上例中 all 为拷贝字段,name 为需要高亮的字段,两种不为同一字段,需要加 "require_field_match": "false" 属性
es 默认高亮前后添加 <em> 标签,不写 pre_tags,post_tags 也可生效
搜索出的文档后会跟上 highlight 属性值,为高亮后的字段