最近沉迷Python爬虫学习,很有意思,即时刹车,坚持一步一学习,一步一整理
Kettle目前工作用于数据库搬运,例如Oracle定时搬运到mysql中间表,以便于加速查询
1.相关学习资料
【尚硅谷】大数据技术之Kettle视频教程
网盘资料下载:https://pan.baidu.com/s/1JxwmmPoeFc7HZuK-E5jzhg
提取码:g1jo
2.Kettle概述
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle 这个ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle(现在已经更名为PDI,Pentaho Data Integration-Pentaho数据集成)。
2.1 Kettle的两种设计
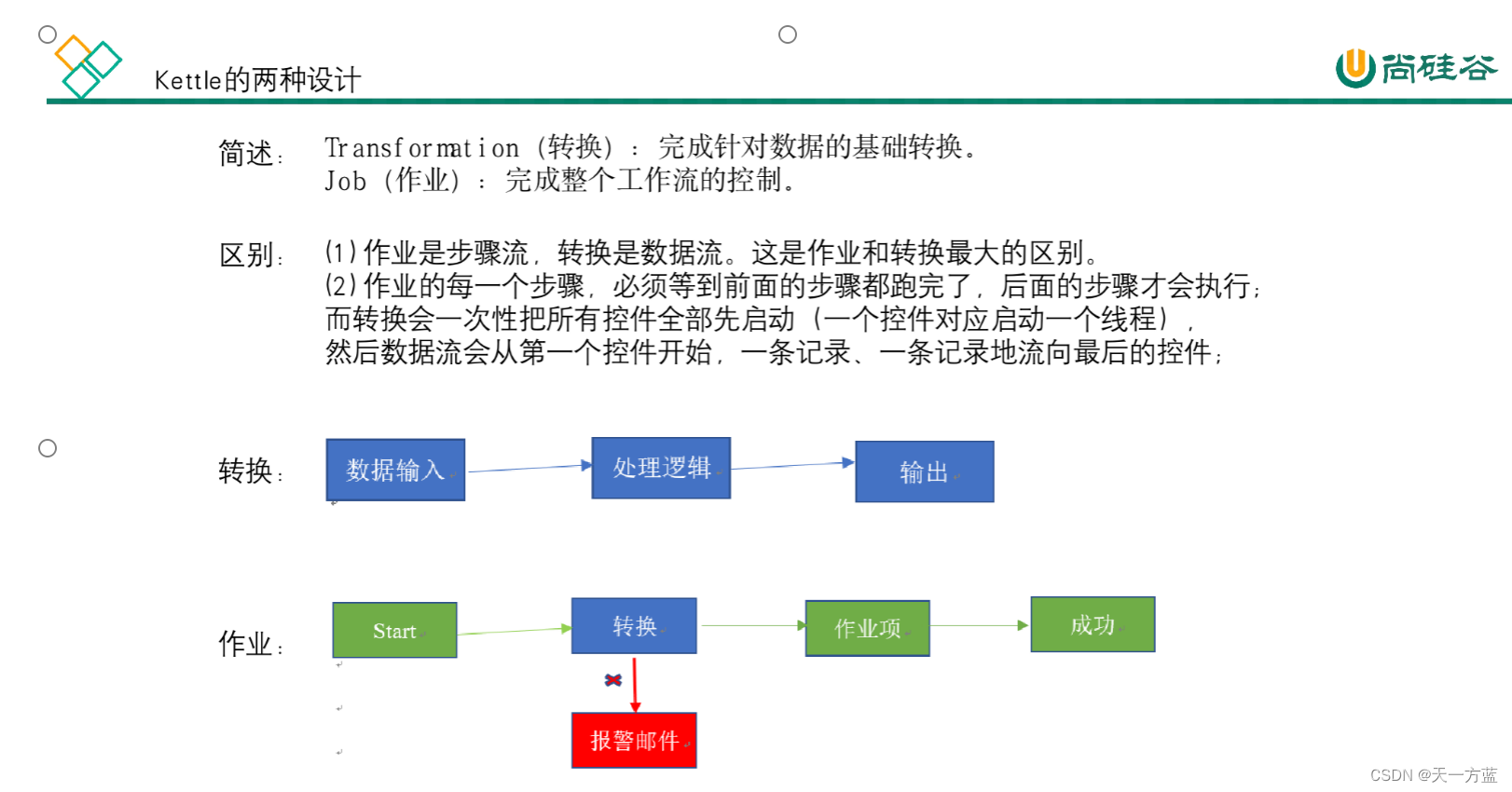
2.2 Kettle的核心组件

3 安装部署(参考视频)
4 Kettle调优
1、调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本

参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
2、 调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
3、尽量使用数据库连接池;
4、尽量提高批处理的commit size;
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
6、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
7、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
8、插入大量数据的时候尽量把索引删掉;
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
10、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
12、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤)
5 Linux 部署调度任务注意点
一般情况在win上编辑好,直接放到Linux上定时调度
Linux设置kettle的任务启动
6 总结
1.ETL为大数据岗位常见工作内容,借助工具更简单。
2.大数据时则是大量工具运用,除此之外写sql加工数据。
3.kettle工具入门大数据既简单又容易了解日常工作,可接受度较高。