一、概述
spark Streaming是对核心Spark API的一个扩展,用来实现对实时流数据的处理,并且具有很好的可扩展性、高吞吐量和容错性。Spark Streaming支持从多种数据源提取数据,例如:Kafka、Flume、Kinesis,或者是TCP套接子。同时也能提供一些高级API来表达复杂的算法,如map、reduce、join以及window等。再处理完数据后,Spark Streming还可以将处理完的数据推送到文件系统、数据库或者实时仪表盘上,用来做具体的展示。

Spark Streaming的内部工作原理
从下图可以看出,Spark Streaming从实时数据流接入数据,再将其划分为一个个小批量供后续的Spark engine处理,因此,Spark Streaming是按一个个小批量来处理数据流的。

Spark Streaming这种持续的数据流提供了一个高级抽象:discretized stream(离散数据流),即DStream。DStream可以从输入数据源获得,如Kafka、Flume、Kinesis,也可以从其他DStream通过算子操作获得。在其内部,一个DStream就是包含了一系列的RDDs。
二、wordCount示例
在执行spark streaming代码前,我们需要导入相关的一些依赖包:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.5</version>
<!--<scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.6.6</version>
</dependency>
大家可以根据自身的版本到Maven上去下载:
spark-streaming依赖包
Scala版:
//创建一个streamingContext,至少包含2个工作线程,并将批次间隔设为2秒。
val conf = new SparkConf().setMaster("local[2]").setAppName("wordCount")
val ssc = new StreamingContext(conf,Seconds(2))
//创建一个连接到hostname:port的DStream
val lines = ssc.socketTextStream("hadoop01",9999)
//将每一行分割成多个单词
val words = lines.flatMap(_.split("\\s+"))
//对每批次中的单词进行统计
val wordCounts = words.map((_,1)).reduceByKey(_+_)
//将该DStream产生的RDD的投十个元素打印在控制台上
wordCounts.print()
//启动流式计算
ssc.start()
//等到直到计算停止
ssc.awaitTermination()
代码执行到wordCounts.print()时,Spark Streaming只是将计算逻辑设置好,此时并没有真正开始处理数据。直到ssc.start()才开始启动。
java版:
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetWorkCount");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(2));
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("hadoop01", 9999);
//Split each line into words
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split("\\s+")).iterator());
//count each word in each batch
JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
//print the first ten elements of eache RDD generated in this DStream to the console
wordCounts.print();
jsc.start();//start the computation
jsc.awaitTermination(); //wait for the computation to terminate
执行完代码,需要运行netcat,将其作为data server
nc -lk 9999
结果展示:
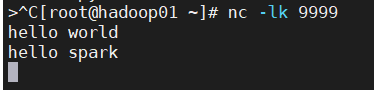

到这一步为止,大家也算是迈出了学习spark Streaming的第一步!接下来带大家一起慢慢揭开sparkStreaming的神秘面纱。
三、初始化StreamingContext
在我们执行代码前,首先需要在入口代码中创建一个StreamingContext对象,而StreamingContext对象需要一个SparkConf对象作为其构造参数。也就是我们前面代码开头写的那一部分:
val conf = new SparkConf().setMaster("local[2]").setAppName("wordCount")
val ssc = new StreamingContext(conf,Seconds(2))
setAppName是给应用起的名字,这个名字会展示在spark集群的web UI上。而setMaster是Spark,Mesos or YARN cluster URL,在这里我采用的是本地测试,用local[*]为其赋值。通常在实际工作中,不应该将master参数放到代码里,而是通过spark-submit的参数来传递master的值。具体操作这里就不再赘述。这里我设置完local[*],该值传给master后,spark Streaming将在本地进程中启动n个线程运行,n与本地系统CPU core数相同。
StreamingContext会在内部创建一个SparkContext对象(SparkContext是所有Spark应用的入口,在StreamingContext对象中可以这样访问:ssc.sparContext)。
StreamingContext对象也可以通过已有的SparkContext对象来创建,例如:
val conf = new SparkConf().setMaster("local[2]").setAppName("wordCount")
val sc = SparkContext.getOrCreate(conf)
val ssc = new StreamingContext(sc,Seconds(2))
创建完一个context后,我们还需要做一下步骤:
- 创建DStream对象,定义输入数据源;
- 基于DStream定义好计算逻辑和输出;
- 调用streamingContext.start()启动接收并处理数据;
- 调用streamingContext.awaitTermination()等待流式处理结束(不论是发生异常错误还是手动结束);
- 可以通过streamingContext.stop()来手动停止处理流程。
注意:
- streamingContext一旦启动,就不能再对其计算逻辑进行添加或修改。
- streamingContext被stop后,就无法restart;
- 单个JVM虚拟机同一时间只能包含一个active的StreamingContext;
- StreamingContext.stop()会把关联的SparkContext对象stop掉,如果不想这一情况发生,可以将StreamingContext.stop的可选参数stopSparkContext设为false;
- 一个SparkContext对象可以和多个StreamingContext对象关联,前提是对前一个StreamingContext.stop(sparkContext=false),然后创建新的StreamingContext对象即可。
四、DStreams(离散数据流)
DStream是Spark Streaming最基本的抽象。它代表了一种连续的数据流,要么从某种数据原提取数据,要么从其他数据流映射转换过来。DStream内部由一系列连续的RDD组成,每个RDD都是不可变、分布式的数据集。每个RDD都包含了特定时间间隔内的一批数据,如图所示:

任何作用于DStream的算子,都会转化为对其内部RDD的操作。例如,在前面的wordCount例子中,我们将lines这个DStream转换成words DStream对象,其作用于lines上的flatMap算子,会施加于lines中的每个RDD上,并生成新的对应的RDD,而这些新生产的RDD对象就组成了words这个DStream对象,其过程如图:

五、输入DStream和接收器
输入DStream代表从某种流式数据源流入的数据流。在前面的例子中,lines对象就是输入DStream,它代表从netcat server收到的数据流。每个输入DStream(除了文件数据流)都和一个接收器Receiver相关联,而接收器就是专门从数据源拉取数据到内存中的对象。
Spark Streaming主要提供两种内建的流式数据源:
- Basic sources:基础数据源。在StreamingContext API中可以直接使用,如文件系统,套接字连接或者Alla actor;
- Advanced srouces:高级数据源。需要依赖外部工具,如:Kafka、Flume、Kinesis等。
注意:
- 如果本地运行Spark Streaming应用,记得不能将master设为”local” 或 “local[1]”。这两个值都只会在本地启动一个线程。而如果此时你使用一个包含接收器(如:套接字、Kafka、Flume等)的输入DStream,那么这一个线程只能用于运行这个接收器,而处理数据的逻辑就没有线程来执行了。因此,本地运行时,一定要将master设为”local[n]”,其中 n > 接收器的个数;
- 将Spark Streaming应用置于集群中运行时,同样,分配给该应用的CPU core数必须大于接收器的总数。否则,该应用就只会接收数据,而不会处理数据。
Basic sources
File Streams
spark streaming提供了textFileStreamAPI方便我们直接对文件进行访问,例如:
val conf = new SparkConf().setMaster("local[2]").setAppName("fileStream")
val ssc = new StreamingContext(conf,Seconds(5))
val stream = ssc.textFileStream("data/in")
val wordCount = stream.flatMap(v => v.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
wordCount.print()
ssc.start()
ssc.awaitTermination()
Spark Streaming将监视该"data/in"目录,并处理该目录下任何新建的文件,但需要注意以下几点:
- 该目录下各个文件数据格式必须一致;
- 目录中的文件必须通过moving或者renaming来创建,直接在目录下新建一个文件无法读取其中的数据;
- 文件传到指定目录下后,就不能再改动。如果这个文件后续还有写入,这些新写入的数据也不会被读取;
- 文件数据流不是基于接收器的,所以不需要为其单独分配一个CPU core。
Custom Receivers
自定义接收器。顾名思义,就是我们自定义一个数据源用来接收数据,然后用spark stream读取。
实现自定Receivers我们需要继承一个抽象类Receiver,同时从写两个方法:
- onStart():开始接收数据时执行的运算;
- onStop():停止数据操作
onStart()和onStop()两个不能一直处于阻塞状态。通常情况下,onStart应确保数据是可以被接收到的,而onstop应确保接收到数据后的线程已经停止。我们也可以用isStopped()来接收线程,用于检查这些线程是否应该停止接收数据。而当我们接收到数据之后,也可以把用store(data)把数据存储在Spark的内部。
下面我们举一个例子来简单看一下自定义Receiver的用法。
Scala版
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.SparkConf
import org.apache.spark.internal.Logging
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.receiver.Receiver
class CustomReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) with Logging{
//create a socket connection and receive data until receive is stopped
private def receive(): Unit ={
var socket:Socket=null
var userInput:String=null
try{
//connect to host:port
socket = new Socket(host,port)
//until stopped or connection broken continue reading
val reader = new BufferedReader(
new InputStreamReader(socket.getInputStream(),StandardCharsets.UTF_8)
)
userInput = reader.readLine()
while (!isStopped()&&userInput!=null) {
store(userInput)
userInput=reader.readLine()
}
reader.close()
socket.close()
//Restart in an attempt to connect again when server is active again
restart("Trying to connect again")
}catch {
case e:java.net.ConnectException=>
//restart if could not connect to server
restart("Error connecting to "+host+":"+port,e)
case t:Throwable=>
//restart if there is any ohter error
restart("Error receiving data",t)
}
}
override def onStart(): Unit = {
//start the tread that receives data over a connection
new Thread("Socket Receiver"){
override def run(): Unit = {
receive()
}
}.start()
}
override def onStop(): Unit = {
//There is nothing much to do as the thread calling receive()
// is designed to stop by itself if isStopped() returns false
}
}
object CustomReceiver{
def main(args: Array[String]): Unit = {
//Create the context with a 2 second batch size
val conf = new SparkConf().setMaster("local[2]").setAppName("CustomeReceiver")
val ssc = new StreamingContext(conf,Seconds(2))
// Create an input stream with the custom receiver on target ip:port and count the
// word in input stream of \n delimited text (eg.generated by 'nc')
val lines = ssc.receiverStream(new CustomReceiver(args(0),args(1).toInt))
val wordCounts = lines.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
java版:
import org.apache.spark.SparkConf;
import org.apache.spark.storage.StorageLevel;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.receiver.Receiver;
import scala.Tuple2;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ConnectException;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class JavaCustomReceiver extends Receiver {
String host = null;
int port = -1;
public JavaCustomReceiver(String host_,int port_) {
super(StorageLevel.MEMORY_AND_DISK_2());
host = host_;
port = port_;
}
@Override
public void onStart() {
//start the thread that receives data over a connection
new Thread(new Runnable() {
@Override
public void run() {
try {
receive();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
@Override
public void onStop() {
}
/*Create a socket connection and receive data untio receive is stopped*/
private void receive() throws IOException {
Socket socket = null;
String userInput = null;
try {
//connect to the server
socket = new Socket(host, port);
BufferedReader reader = new BufferedReader(
new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8)
);
//Until stopped or connection broken continue reading
while (!isStopped() && (userInput = reader.readLine()) != null) {
System.out.println("Received data '" + userInput + "'");
store(userInput);
}
reader.close();
socket.close();
//Restart in an attempt to connect again when server is active again
restart("Trying to connect again");
} catch (ConnectException ce) {
//restart if could not connect to server
restart("Conld not connect,", ce);
} catch (Throwable t) {
//restart if there is any other error
restart("Error receiving data",t);
}
}
public static void main(String[] args) throws InterruptedException {
if (args.length < 2) {
System.err.println("Usage:JavaCustomReceiver<hostname><port>");
System.exit(1);
}
SparkConf conf = new SparkConf().setAppName("JavaCustomeReceiver").setMaster("local[*]");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(2));
/*Create an input stream with the custom receiver on target ip:port and count the
* word in input stream of \n delimited text (eg.generated by 'nc')*/
JavaReceiverInputDStream lines = jsc.receiverStream(new JavaCustomReceiver(args[0], Integer.parseInt(args[1])));
JavaDStream words = lines.flatMap(x -> Arrays.asList(x.toString().split("\\s+")).iterator());
JavaPairDStream<String,Integer> wordCount = words.mapToPair(s -> new Tuple2<>(s, 1))
.reduceByKey((i1, i2) -> (int)(i1) + (int)i2);
wordCount.print();
jsc.start();
jsc.awaitTermination();
}
}
接收器的可靠性
根据数据的可靠性,可以分成两种数据源。其中,像Kafka、Flume这种数据源,它们支持对所传输的数据进行确认,系统收到这类可靠数据源过来的数据,发出确认信息,这样可以保证数据不会丢失,因此接收器也相应的分为两类:
- Reliable Receiver:可靠接收器。在成功接收并保存好Spark数据副本后,向可靠数据源发送确认信息;
- Unreliable Receiver:不可靠接收器。当其接收到数据后,不会发送任何确认信息。不过这种接收器常用于不支持确认的数据源,或者不想引入数据确认的复杂性的数据源。
六、Transformations算子
和RDD类似,DStream也支持通过transformation算子映射成新的DStream。DStream支持很多RDD上常见的transformation算子,举些例子让大家感受一下:
| Transformation算子 |
含义 |
| map(func) |
将原DStream中的每个元素通过func自定义函数映射为新的元素,返回一个新的DStream |
| flatMap(func) |
和map类似,不过每个输入的元素不再是映射为一个输出,而是映射为0到多个 |
| filter(func) |
根据func条件筛选出元素,返回一个新的DStream |
| repartition(numPartitions) |
通过增加或减少分区数来改变DStream的并行度 |
| union(otherStream) |
取DStream和其他DStream元素的并集,返回一个新的DStream |
| count() |
通过统计每个DStream中各个RDD元素的个数,返回一个新的,包含单元素RDDs的DStream |
| reduce(func) |
返回一个包含单元素RDDs的DStream,其中每个元素是通过源RDD中各个RDD的元素经func(func输入两个参数并返回一个同类型结果数据)聚合得到的结果。func必须满足结合律,以便支持并行计算。 |
| countByValue() |
当DStream包含的元素类型是键值对类型时,返回一个新的,(K,Long)类型的DStream。K是源DStream中的各个元素,Long值是K出现的次数 |
| reduceByKey(func,[numTasks]) |
如果源DStream 包含的元素为 (K, V) 键值对,则该算子返回一个新的也包含(K, V)键值对的DStream,其中V是由func聚合得到的。注意:默认情况下,该算子使用Spark的默认并发任务数(本地模式为2,集群模式下由spark.default.parallelism 决定)。你可以通过可选参数numTasks来指定并发任务个数 |
| join(otherStream, [numTasks]) |
如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中源DStream和otherDStream中每个K都对应一个 (K, (V, W))键值对元素 |
| cogroup(otherStream, [numTasks]) |
如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中每个元素类型为包含(K, Seq[V], Seq[W])的tuple。 |
| transform(func) |
返回一个新的DStream,其包含的RDD为源RDD经过func操作后得到的结果。利用该算子可以对DStream施加任意的操作。 |
| updateStateByKey(func) |
返回一个包含新”状态”的DStream。源DStream中每个key及其对应的values会作为func的输入,而func可以用于对每个key的“状态”数据作任意的更新操作 |
下面我们挑几个算子详细介绍一下。
updateStateByKey
updateStateByKey算子支持维护一个任意的状态,要实现这一点,需要两步:
- 定义状态—状态数据可以是任意类型;
- 定义更新函数—使用函数来指定如何使用以前的状态结合输入流中的新值来更新状态。
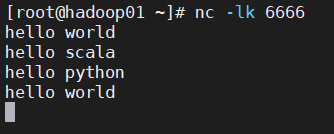
在每一个批次数据到达后,Spark都会调用函数来更新所有已有的key的状态,如果状态更新函数返回None,则对应的键值对会被删除。听起来可能会有点抽象,下面我们举个例子来验证一下:
val conf = new SparkConf().setMaster("local[2]").setAppName("updateStateByKey")
val ssc = new StreamingContext(conf,Seconds(2))
ssc.checkpoint("data/checkpoint")
val msg = ssc.socketTextStream("hadoop01",6666)
val pair = msg.flatMap(v=>v.split("\\s+")).map((_,1))
val wordsCount: DStream[(String, Int)] = pair.updateStateByKey {
case (seq, buffer) => {
val sum: Int = buffer.getOrElse(0) + seq.sum
Option(sum)
}
}
wordsCount
wordsCount.print()
ssc.start()
ssc.awaitTermination()
我们来分析一下这段代码。
首先需要注意的,就是在调用updateStateByKey前,需要配置检查点目录。
接下来我们来看下updateStateByKey算子的源码(当然不止这一种用法,还有另外6中,这里只拿例子中的用法来分析):
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
updateStateByKey中,定义了一个updateFunc函数,里面的参数类型为Seq数组和Option,即我们代码中的seq和buffer。
seq是新传入进来的数据组成的数组,而‘旧’数据就保存在buffer中。当开始运算时,按照相同的key值,分到同一个数组中,这里假设为(1,1,1,1)。然后通过seq.sum求出元素的和,就得到该key出现的次数。然后和buffer中“旧”的数据相加,这里做个判断,如果没有数据,则为0(getOrElse(0))。该updateFunc的返回值类型为Option[s]。此时,我们就得到了一个新状态下的DStream。具体表现就是数据状态会一直保留在最后一次更新后的状态,我们可以看下运行结果:

transform
transform支持任意RDD到RDD的映射操作。即可以用transform算子来包装任何API所不支持的RDD算子。例如,将DStream每批次中的RDD与另一个Dataset进行关联(join)操作,DStream API并没有提供这个功能,但是我们却可以使用transform来实现。
在做实例之前,我们先来看下transform的源码:
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U] = ssc.withScope {
val cleanedF = context.sparkContext.clean(transformFunc, false)
transform((r: RDD[T], _: Time) => cleanedF(r))
}
def transform[U: ClassTag](transformFunc: (RDD[T], Time) => RDD[U]): DStream[U] = ssc.withScope {
val cleanedF = context.sparkContext.clean(transformFunc, false)
val realTransformFunc = (rdds: Seq[RDD[_]], time: Time) => {
assert(rdds.length == 1)
cleanedF(rdds.head.asInstanceOf[RDD[T]], time)
}
new TransformedDStream[U](Seq(this), realTransformFunc)
}
transform有两种用法。一种是定义一个函数transformFun作为参数,自定义函数的参数为RDD和Time类型,RDD是我们接收到的数据,transformFun的返回值类型也是一个RDD。还有一种是把一个other DStream和transformFun作为参数。两种用法最后的返回值类型都是DStream类型。
这里选择数据源为Kafka中提取。
val conf = new SparkConf().setMaster("local[2]").setAppName("transformDemo")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParms: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.30:9092,192.168.136.31:9092,192.168.136.32:9092,"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "transform")
)
val kafkaMsg: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("kafkaDemo"), kafkaParms)
)
val res: DStream[((String, String), Int)] = kafkaMsg.transform((rdd, timestamp) => {
val format: SimpleDateFormat = new SimpleDateFormat("yyyyMMdd HH:mm:ss")
val time: String = format.format(timestamp.milliseconds)
val value: RDD[((String, String), Int)] = rdd.flatMap(_.value().toString.split("\\s+"))
.map(x => ((x, time), 1))
.reduceByKey(_ + _)
value
})
res.print()
ssc.start()
ssc.awaitTermination()
通过Kafka生产消息,我们就可以在控制台查看运算结果:
#kafka-console-producer.sh --topic kafkaDemo --broker-list 192.168.136.30:9092
hello world
hello scala
hello java
hello python

注:这里调用transform包含的算子,其调用时间间隔和批次是相同的,所以可以基于时间改变对RDD的操作。如:在不同批次,调用不同的RDD算子,设置不同的RDD分区或者广播变量等。
七、window算子
spark Streaming同样也提供基于时间窗口的计算。你可以对某一个滑动时间窗内的数据施加特定的tranformation算子。如图所示:

每次窗口滑动时,源DStream中落入窗口的RDD就会被合并成新的windowed DStream。在上图的例子中,这个操作会施加于3个RDD单元,而滑动距离是2个RDD单元。由此可以得出任何窗口相关操作都需要指定一下两个参数:
- window length:窗口长度,即窗口覆盖的时间长度,上图中为3;
- sliding interval:滑动距离,即窗口启动的时间间隔,上图中为2.
这两个参数必须是DStream批间隔(图中为1)的整数倍。
下面我们来看下常用的窗口算子有哪些。
| transformation |
含义 |
| window(windowLength, slideInterval) |
将DStream窗口化,并返回一个新的DStream |
| countByWindow(windowLength,slideInterval) |
返回数据流在滑动窗口中的元素个数 |
| reduceByWindow(func, windowLength,slideInterval) |
基于数据流在一个滑动窗口内的元素,用func做聚合,返回一个单元素数据流。func必须满足结合律,以便支持并行计算 |
| reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) |
基于(K, V)键值对DStream,将一个滑动窗口内的数据进行聚合,返回一个新的包含(K,V)键值对的DStream,其中每个value都是各个key经过func聚合后的结果。注意:如果不指定numTasks,其值将使用Spark的默认并行任务数(本地模式下为2,集群模式下由 spark.default.parallelism决定)。当然,你也可以通过numTasks来指定任务个数 |
| reduceByKeyAndWindow(func, invFunc,windowLength,slideInterval, [numTasks]) |
和前面的reduceByKeyAndWindow() 类似,只是这个版本会用之前滑动窗口计算结果,递增地计算每个窗口的归约结果。当新的数据进入窗口时,这些values会被输入func做归约计算,而这些数据离开窗口时,对应的这些values又会被输入 invFunc 做”反归约”计算。举个简单的例子,就是把新进入窗口数据中各个单词个数“增加”到各个单词统计结果上,同时把离开窗口数据中各个单词的统计个数从相应的统计结果中“减掉”。不过,你的自己定义好”反归约”函数,即:该算子不仅有归约函数(见参数func),还得有一个对应的”反归约”函数(见参数中的 invFunc)。和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数。注意,这个算子需要配置好检查点(checkpointing)才能用 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) |
基于包含(K, V)键值对的DStream,返回新的包含(K, Long)键值对的DStream。其中的Long value都是滑动窗口内key出现次数的计数。和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数 |
window算子
源码:
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}
这个源码容易理解,这里就不过多解释,直接上代码示例(wordCount):
val conf = new SparkConf().setMaster("local[2]").setAppName("transformDemo")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParms: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.30:9092,192.168.136.31:9092,192.168.136.32:9092,"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "transform")
)
val kafkaMsg: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("kafkaDemo"), kafkaParms)
)
//前面的代码,我们都是在做数据的采集,接下来做需求运算
val value: DStream[(String, Int)] = kafkaMsg.flatMap(_.value().toString.split("\\s+")).map((_,1)).reduceByKey(_+_)
//实现窗口,窗口大小为4s,每次滚动2s
val res: DStream[(String, Int)] = value.window(Seconds(4),Seconds(2))
res.print()
ssc.start()
ssc.awaitTermination()
结果:

通过从Kafka采集来的数据,我们可以看出,在刚开始的4s内数据,数据为(hello,1),(world,1),(hello,1),(java,1),再经过2s后,窗口大小不变,依然为4,但数据只截取到了(hello,1),(java,1),这就是slideDuration发挥了作用。
reduceByWindow算子
源码:
//用法一:传入三个参数,除了窗口大小和间隔时长外,还要加一个自定义函数,用来做窗口间数据的逻辑运算
def reduceByWindow(
reduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.reduce(reduceFunc).window(windowDuration, slideDuration).reduce(reduceFunc)
}
//用法二:这里要传四个参数,和用法一相比,多了个invReduceFunc,当窗口滚动完
//一个窗口大小后,前一个窗口中的数据和新窗口中的数据做关联运算,新的数据保存在新的窗口中
def reduceByWindow(
reduceFunc: (T, T) => T,
invReduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.map((1, _))
.reduceByKeyAndWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration, 1)
.map(_._2)
}
示例:
代码其他部分都一样,这里只展示需求实现部分
....
val value: DStream[String] = kafkaMsg.flatMap(_.value().toString.split("\\s+"))
val res = value.reduceByWindow(_+":"+_,Seconds(4),Seconds(2))

当窗口滚动的时候,数据之间拼接到一起。下面我们再添加一个参数,看下效果:
val value: DStream[String] = kafkaMsg.flatMap(_.value().toString.split("\\s+"))
//窗口之间用","拼接
val res: DStream[String] = value.reduceByWindow(_+":"+_,_+","+_,Seconds(4),Seconds(2))

当走完4s后,前一个窗口中的数据与后一个窗口中的数据,用“,”拼接在一起,组成新的DStream。
窗口算子的用法还是比较简单的,这里就不再一一展示其他的用法,大家可以在掌握相应的原理和用法后,可以自己多去检验一下。
八、DStream输出算子
输出算子可以将DStream的数据推送到外部系统,如数据库或者文件系统。因为输出算子会将最终完成转换的数据输出到外部系统,因此只有输出算子调用时,才会真正触发DStream transformation算子的真正执行,类似于RDD的action算子。
| 输出算子 |
含义 |
| print() |
在driver节点上打印DStream每个批次中的前10个元素 |
| saveAsTextFiles(prefix, [suffix]) |
将DStream的内容保存到文本文件。每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]” |
| saveAsObjectFiles(prefix, [suffix]) |
将DStream内容以序列化Java对象的形式保存到顺序文件中。每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]” |
| saveAsHadoopFiles(prefix, [suffix]) |
将DStream内容保存到Hadoop文件中。每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]” |
| foreachRDD(func) |
这是最通用的输出算子了,该算子接收一个函数func,func将作用于DStream的每个RDD上。func应该实现将每个RDD的数据推到外部系统中,比如:保存到文件或者写到数据库中。注意,func函数是在streaming应用的驱动器进程中执行的,所以如果其中包含RDD的action算子,就会触发对DStream中RDDs的实际计算过程。 |
saveAsTextFile
val res: Unit = kafkaMsg.foreachRDD(x => {
val words: RDD[(String, Int)] = x.flatMap(_.value().toString.split("\\s+")).map((_, 1)).reduceByKey(_ + _)
words.saveAsTextFile("data/save")
})
这种方法,我们可以把数据保存在本地目录下。需要注意的是,因为是实时流数据,我们运算来的数据只能在文件中保存我们定义的时间。时间一过,就会被新的数据所覆盖。此时,如果想让数据长久保存下来,我们可以为文件名加上一个时间戳。这样,每当当产生一个运算结果时,都会生成一个新的文件,不会覆盖原先的文件。
val res: Unit = kafkaMsg.foreachRDD(x => {
val words: RDD[(String, Int)] = x.flatMap(_.value().toString.split("\\s+")).map((_, 1)).reduceByKey(_ + _)
val time = System.currentTimeMillis()
words.saveAsTextFile("data/save"+"-"+time)
注:如果你的文件分区过多,想把它们保存在一个文件中,可以在保存前自定义分区。
words.repartition(1).saveAsTextFile("data/save")
我们也可以把数据保存到HDFS上去:
words.repartition(1).saveAsTextFile("hdfs://192.168.136.30:9000/data/save"+"-"+time)
当hdfs文件过多的时候,可以采取文件合并的方式,把这些文件合并为一个文件,保存到本地:
hdfs dfs -getmerge /data/save-* /data/save
上面的那种方法,我们是把处理结果转化为RDD的形式,进行的存储,我们也可以直接使用DStream调用saveAsTextFiles算子。
val words2: DStream[(String, Int)] = kafkaMsg.flatMap(_.value().toString.split("\\s+")).map((_,1)).reduceByKey(_+_)
words2.saveAsTextFiles("data/save2")
这样的做法是比上述的运算过程要快,但是在保存文件的时候,会随着采集时间,产生很多的文件,每个采集时间生成一个文件,所以和前面的方法相比,它并不会直接覆盖原先的文件,但是,弊端就是产生了过多的文件。
foreachRDD的设计模式
DStream.foreachRDD是一个非常强大的原生工具函数,用户可以基于此RDD将DStream数据推送到外部系统中。但是在使用中,我们还是需要注意一些问题,以便更高效的使用这个工具。
下面列举一些常见的错误。
通常,对外部系统写入数据需要一些连接对象,以便发送数据给远程系统。因此,开发人员可能会不经意的仔Spark驱动(Driver)进程中创建一个连接对象,然后又试图在Spark Worker节点上使用这个连接,例如:
scala版:
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // 这行在驱动器(driver)进程执行
rdd.foreach { record =>
connection.send(record) // 而这行将在worker节点上执行
}
}
java版:
dstream.foreachRDD(rdd -> {
Connection connection = createNewConnection(); // executed at the driver
rdd.foreach(record -> {
connection.send(record); // executed at the worker
});
});
这段代码是错误的。因为它需要把连接对象序列化,再从驱动器节点发送到worker节点。而这些连接对象通常都是不能跨节点(机器)传递的。比如,连接对象通常都不能序列化,或者在另一个进程中反序列化后再次初始化(连接对象通常都需要初始化,因此从驱动节点发到worker节点后可能需要重新初始化)等。解决此类错误的办法就是在worker节点上创建连接对象。然而,还有可能出现另一种错误:
Scala版:
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
java版:
dstream.foreachRDD(rdd -> {
rdd.foreach(record -> {
Connection connection = createNewConnection();
connection.send(record);
connection.close();
});
});
一般来说,连接对象是有时间和资源开销限制的。因此,对每条记录都进行一次连接对象的创建和销毁会增加很多不必要的开销,同时也大大减小了系统的吞吐量。一个比较好的解决方案是使用 rdd.foreachPartition – 为RDD的每个分区创建一个单独的连接对象,示例如下:
Scala版:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
java版:
dstream.foreachRDD(rdd -> {
rdd.foreachPartition(partitionOfRecords -> {
Connection connection = createNewConnection();
while (partitionOfRecords.hasNext()) {
connection.send(partitionOfRecords.next());
}
connection.close();
});
});
这样一来,连接对象的创建开销就摊到很多条记录上了。
最后,还有一个更优化的办法,就是在多个RDD批次之间复用连接对象。开发者可以维护一个静态连接池来保存连接对象,以便在不同批次的多个RDD之间共享同一组连接对象,示例如下:
Scala版:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool 是一个静态的、懒惰初始化的连接池
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // 将连接返还给连接池,以便后续复用之
}
}
java版:
dstream.foreachRDD(rdd -> {
rdd.foreachPartition(partitionOfRecords -> {
// ConnectionPool is a static, lazily initialized pool of connections
Connection connection = ConnectionPool.getConnection();
while (partitionOfRecords.hasNext()) {
connection.send(partitionOfRecords.next());
}
ConnectionPool.returnConnection(connection); // return to the pool for future reuse
});
});
注意,连接池中的连接应该是懒惰创建的,并且有确定的超时时间,超时后自动销毁。这个实现应该是目前发送数据最高效的实现方式。
其他要点:
- DStream的转化执行也是惰性的,需要输出算子来触发,类似于RDD的action算子。DStream输出算子中包含RDD action算子会强制触发对所接收数据的处理。因此,如果在Streaming应用中没有输出算子,或者用了DStream.foreachRDD(func)却没有在func中调用RDD action算子,那么这个应用只会接收数据,而不会处理数据,接收到数据最后只是被简单的丢弃了。
- 默认的,输出算子只能执行一个,且按照它们在应用程序代码中定义的顺序执行。
九、累加器和广播变量
首先需要注意的是,累加器(Accumulators)和广播变量(Broadcast variables)是无法从Spark Streaming的检查点中恢复回来的。所以如果你开启了检查点功能,并同时在使用累加器和广播变量,那么你最好是使用懒惰实例化的单例模式,因为这样累加器和广播变量才能在驱动器(driver)故障恢复后重新实例化。代码示例如下:
Scala版:
import java.text.SimpleDateFormat
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.util.LongAccumulator
object WordExcludeList {
//广播变量
@volatile private var instance:Broadcast[Seq[String]]=null
def getInstance(sc:SparkContext): Broadcast[Seq[String]]={
if(instance==null) {
synchronized{
if (instance==null) {
val wordExcludeList=Seq("a","b","c")
instance= sc.broadcast(wordExcludeList)
}
}
}
instance
}
}
object DroppedWordsCounter{
//累加器
@volatile private var instance:LongAccumulator=null
def getInstanec(sc:SparkContext): LongAccumulator={
if (instance==null) {
synchronized{
if (instance==null) {
instance=sc.longAccumulator("DroppedWordsCounter")
}
}
}
instance
}
}
object wordCount{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("wordCount")
val ssc = new StreamingContext(conf,Seconds(4))
ssc.checkpoint("check")
val lines = ssc.socketTextStream("hadoop01",9999)
val wordsCount = lines.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)
wordsCount.foreachRDD((rdd,timestamp)=>{
val format = new SimpleDateFormat("yyyyMMdd HH:mm:ss")
val time = format.format(timestamp.milliseconds)
//获取广播变量
val exclude = WordExcludeList.getInstance(rdd.sparkContext)
//获取累加器
val accumulator = DroppedWordsCounter.getInstanec(rdd.sparkContext)
//用exclude过滤单词,并把过滤掉的单词累加到accumulator中
val counts = rdd.filter {
case (word, count) => {
if (exclude.value.contains(word)) {
accumulator.add(count)
false
} else (true)
}
}.collect().mkString("[", ",", "]")
println(time + ":"+counts)
})
ssc.start()
ssc.awaitTermination()
}
}
这是我执行的结果:

十、DataFrame 和SQL
在Streaming应用中,我们可以调用DataFrames and SQL来处理流式数据。开发者可以用通过StreamingContext中的SparkContext对象来创建一个SQLContext,并且,开发者需要确保一旦驱动器(driver)故障恢复后,该SQLContext对象能重新创建出来。同样,你还是可以使用懒惰创建的单例模式来实例化SQLContext
val conf = new SparkConf().setMaster("local[2]").setAppName("demo6")
val ssc = new StreamingContext(conf,Seconds(2))
ssc.checkpoint("data")
val kafkaStream:Map[String,String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.10:9092"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG,"windo5")
)
val kafkaMsg:InputDStream[ConsumerRecord[String,String]] =
KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkDemo"),kafkaStream)
)
val wordcount = kafkaMsg.transform(rdd=>{
//获得SQLContext单例
val spark = SQLContextSinleton.getInstance(rdd.sparkContext)
import spark.implicits._
val value = rdd.flatMap(x=>x.value().toString.split("\\s+")).map((_,1))
//将RDD转为DataFrame,并注册为临时表
value.toDF("name","cn").createOrReplaceTempView("tbword")
//用SQL语句进行运算
val frame = spark.sql("select name,count(cn) from tbword group by name")
frame.rdd
})
wordcount.print()
ssc.start()
ssc.awaitTermination()
object SQLContextSinleton{
@transient private var instance:SQLContext=_
def getInstance(sc:SparkContext):SQLContext={
synchronized(
if(instance == null){
instance = new SQLContext(sc)
}
)
instance
}
}
也可以在其他线程里执行SQL查询(异步查询,即:执行SQL查询的线程和运行StreamingContext的线程不同)。不过这种情况下,你需要确保查询的时候 StreamingContext 没有把所需的数据丢弃掉,否则StreamingContext有可能已将老的RDD数据丢弃掉了,那么异步查询的SQL语句也可能无法得到查询结果。举个栗子,如果你需要查询上一个批次的数据,但是你的SQL查询可能要执行5分钟,那么你就需要StreamingContext至少保留最近5分钟的数据:streamingContext.remember(Minutes(5)) (这是Scala为例,其他语言差不多)
如果想了解更多关于DataFrame 和SQL,可以点这里:DataFrames and SQL