总目录
各部分的解释已经以注释形式写于代码中。
1.基本操作
1.1 结构体定义
// 带头结点
typedef struct LNode { // 定义单链表结点类型
int data; // 数据域
struct LNode *next; // 指针域
} LNode, *LinkList;
1.2 初始化
// 初始化一个单链表
bool InitList(LinkList &L) {
L = (LNode *)malloc(sizeof(LNode)); // 分配一个结点的空间,当作头结点
// 内存分配失败得到情况
if(L == NULL) {
return false;
}
// 将头结点指针域设为NULL,表示头结点之后暂时还没有结点
L->next = NULL;
return true;
}
1.3 判空
// 判断单链表是否为空
bool Empty(LinkList L) {
// 有头结点,那么头结点指针域指向NULL,单链表即为空
if(L->next == NULL) {
return true;
} else {
return false;
}
}
1.4 按位序插入
// 在第i个位置插入元素e
bool ListInsert(LinkList &L, int i, int e) {
// 判断插入位序是否存在问题
if(i < 1)
return false;
LNode *p; // 指针p指向当前扫描到的结点
int j = 0; // 当前p指向的是第几个结点
p = L; // 初始令p指向头结点
// 通过循环,找到第i-1个结点
// 如果i大于链表长度,则不可插入,此时p指向最后结点的指针域,即NULL
while(p != NULL && j < i - 1) {
p = p->next;
j++;
}
// p值为NULL说明遍历完成后仍未为找到位序为i的结点,说明i大于链表长度,i不合法
if (p == NULL) {
return false;
}
// 在第i-1个结点后插入新结点
LNode *s = (LNode *)malloc(sizeof(LNode));
// 注意顺序,应该先让要插入结点的指针域指向后一结点
// 之后再断开前一结点与后一结点的指针,使前一结点指向要插入结点
s->data = e;
s->next = p->next;
//将结点s连到p后
p->next = s;
return true;
}
1.5 指定结点后插操作
// 指定结点后插操作:在p结点之后插入元素e
// LNode强调为结点
bool InsertNextNode(LNode *p, int e) {
// p不合理的情况
if(p == NULL) {
return false;
}
LNode *s = (LNode *)malloc(sizeof(LNode));
// 内存分配失败的情况
if(s == NULL) {
return false;
}
// 此处先将要插入结点的指针域指向前一个结点的指针域,即后一个结点的地址
// 之后再令前一个结点的指针域指向要插入结点
// 顺序不可颠倒,否则可能出现找不到之后结点的情况
s->data = e;
s->next = p->next;
p->next = s;
return true;
}
1.6 指定结点前插操作
// 指定结点前插操作:在p结点之前
// 此处可以通过一种特殊方法完成前插
// 本质上还是后插操作
bool InsertPriorNode(LNode *p, int e) {
// p不合理的情况
if(p == NULL) {
return false;
}
LNode *s = (LNode *)malloc(sizeof(LNode));
// 内存分配失败的情况
if(s == NULL) {
return false;
}
// 插入操作
// 通过将s插入p结点之后,然后将s结点与p结点的数据域进行互换
// 可以视作完成了前插操作
s->next = p->next;
p->next = s;
s->data = p->data;
p->data =e;
return true;
}
1.7 按位序删除
// 按位序删除
bool ListDelete(LinkList &L, int i, int &e) {
// i不合理的情况
if(i < 1) {
return false;
}
LNode *p; // 指针p指向当前扫描到的结点
int j = 0; // 当前p指向的是第几个结点
// 初始令p指向头结点,即第0个结点
p = L;
// 通过遍历找到第i - 1个结点,即要删除结点的前驱结点
while(p != NULL && j < i - 1) {
p = p->next;
j++;
}
// 若p等于NULL,则要么此链表为空,要么i值大于链表长度,显然不合理
if(p == NULL) {
return false;
}
// p->next为空表示第i-1个结点之后已经没有其他结点了,无法进行删除操作
if(p->next == NULL) {
return false;
}
// 删除操作
// 就是将前驱结点指针域指向后继结点
LNode *q = p->next;
e = q->data;
p->next = q->next;
// 不要忘记释放空间!!!
free(q);
return true;
}
1.8 按位查找
// 按位查找,返回第i个元素
// 之前操作部分按位查找部分可以以此部分代码代替,提高代码复用性(封装)
LNode* GetElem(LinkList L, int i) {
// 判断插入位序是否存在问题
// 由于此是带头结点的情况,而头结点可以视作是第0个结点
// 所以与之前遍历情况不同
if(i < 0)
return NULL;
LNode *p; // 指针p指向当前扫描到的结点
int j = 0; // 当前p指向的是第几个结点
p = L; // 初始令p指向头结点
// 通过循环,找到第i个结点
// 如果i大于链表长度,则找不到此节点,此时p指向最后结点的指针域,即NULL
// 如果i初始为0,会直接返回头结点地址
while(p != NULL && j < i) {
p = p->next;
j++;
}
return p;
}
1.9 按值查找
// 按值查找,找到数据域等于e的结点
LNode* LocateElem(LinkList L, int e) {
LNode* p = L->next;
// 从第一个结点开始查找数据域为e的结点
// 找不到,则会在遍历后指向NULL
while (p != NULL && p->data != e) {
p = p->next;
}
return p;
}
1.10 表的长度
// 求表的长度
// 就是通过遍历所有结点,然后通过计数器来累加得到长度
int Length(LinkList L) {
int len = 0;
LNode* p = L;
while(p->next != NULL) {
p = p->next;
len++;
}
return len;
}
1.11 单链表建立(尾插法)
// 尾插法
// 通过尾插法建立的链表,顺序为插入时元素的顺序
LinkList TailInsert(LinkList &L) {
// 设置ElemType为整型
int x;
// 建立头结点(申请的空间为一个结点大小的空间)
L = (LinkList)malloc(sizeof(LNode));
// 初始化为空链表
// 由于L在分配空间后,头指针可能并非指向NULL,而是其他任意区域,这可能导致问题发生
// 动态分配的空间之前可能存在脏数据
L->next = NULL;
// 定义表尾指针
// 对于尾插法,如果只通过头结点遍历的话
// 每次插入时都要先遍历到表尾,时间复杂度为O(1+2+...+n-1)=O(n^2)
// 所以选择增加一个尾指针,来避免遍历
// s为要插入的结点,r为表尾指针
LNode *s, *r = L;
// 输入结点的值
scanf("%d", &x);
// 表示键入9999后建表结束
while(x != 9999) {
s = (LNode*)malloc(sizeof(LNode));
s->data = x;
r->next = s;
// r指向新的表尾结点
r = s;
// 继续输入下一个结点的值,直至输入9999结束
scanf("%d", &x);
}
// 尾指针置空
r->next = NULL;
return L;
}
1.12 单链表建立(头插法)
// 头插法
// 通过头插法建立的链表,顺序为插入时元素的逆序
LinkList HeadInsert(LinkList &L) {
// 设置ElemType为整型
int x;
// 建立头结点(申请的空间为一个结点大小的空间)
L = (LinkList)malloc(sizeof(LNode));
// 初始化为空链表
// 由于L在分配空间后,头指针可能并非指向NULL,而是其他任意区域,这可能导致问题发生
// 动态分配的空间之前可能存在脏数据
L->next = NULL;
// 不同于尾插法,头插法无需定义更多指针
LNode* s;
// 输入结点的值
scanf("%d", &x);
// 表示键入9999后建表结束
while(x != 9999) {
s = (LNode*)malloc(sizeof(LNode));
s->data = x;
s->next = L->next;
L->next = s;
// 继续输入下一个结点的值,直至输入9999结束
scanf("%d", &x);
}
}
1.13 输出所有链表元素
// 输出所有链表元素
void PrintList(LinkList L) {
if(Empty(L)) {
printf("the list is empty");
}
LNode* p = L;
while(p != NULL) {
printf("%d ", p->data);
p = p->next;
}
}
2.完整代码
#include<stdio.h>
#include<stdlib.h>
// 带头结点
typedef struct LNode { // 定义单链表结点类型
int data; // 数据域
struct LNode *next; // 指针域
} LNode, *LinkList;
// 初始化一个单链表
bool InitList(LinkList &L) {
L = (LNode *)malloc(sizeof(LNode)); // 分配一个结点的空间,当作头结点
// 内存分配失败得到情况
if(L == NULL) {
return false;
}
// 将头结点指针域设为NULL,表示头结点之后暂时还没有结点
L->next = NULL;
return true;
}
// 判断单链表是否为空
bool Empty(LinkList L) {
// 有头结点,那么头结点指针域指向NULL,单链表即为空
if(L->next == NULL) {
return true;
} else {
return false;
}
}
// 在第i个位置插入元素e
bool ListInsert(LinkList &L, int i, int e) {
// 判断插入位序是否存在问题
if(i < 1)
return false;
LNode *p; // 指针p指向当前扫描到的结点
int j = 0; // 当前p指向的是第几个结点
p = L; // 初始令p指向头结点
// 通过循环,找到第i-1个结点
// 如果i大于链表长度,则不可插入,此时p指向最后结点的指针域,即NULL
while(p != NULL && j < i - 1) {
p = p->next;
j++;
}
// p值为NULL说明遍历完成后仍未为找到位序为i的结点,说明i大于链表长度,i不合法
if (p == NULL) {
return false;
}
// 在第i-1个结点后插入新结点
LNode *s = (LNode *)malloc(sizeof(LNode));
// 注意顺序,应该先让要插入结点的指针域指向后一结点
// 之后再断开前一结点与后一结点的指针,使前一结点指向要插入结点
s->data = e;
s->next = p->next;
//将结点s连到p后
p->next = s;
return true;
}
// 指定结点后插操作:在p结点之后插入元素e
// LNode强调为结点
bool InsertNextNode(LNode *p, int e) {
// p不合理的情况
if(p == NULL) {
return false;
}
LNode *s = (LNode *)malloc(sizeof(LNode));
// 内存分配失败的情况
if(s == NULL) {
return false;
}
// 此处先将要插入结点的指针域指向前一个结点的指针域,即后一个结点的地址
// 之后再令前一个结点的指针域指向要插入结点
// 顺序不可颠倒,否则可能出现找不到之后结点的情况
s->data = e;
s->next = p->next;
p->next = s;
return true;
}
// 指定结点前插操作:在p结点之前
// 此处可以通过一种特殊方法完成前插
// 本质上还是后插操作
bool InsertPriorNode(LNode *p, int e) {
// p不合理的情况
if(p == NULL) {
return false;
}
LNode *s = (LNode *)malloc(sizeof(LNode));
// 内存分配失败的情况
if(s == NULL) {
return false;
}
// 插入操作
// 通过将s插入p结点之后,然后将s结点与p结点的数据域进行互换
// 可以视作完成了前插操作
s->next = p->next;
p->next = s;
s->data = p->data;
p->data =e;
return true;
}
// 按位序删除
bool ListDelete(LinkList &L, int i, int &e) {
// i不合理的情况
if(i < 1) {
return false;
}
LNode *p; // 指针p指向当前扫描到的结点
int j = 0; // 当前p指向的是第几个结点
// 初始令p指向头结点,即第0个结点
p = L;
// 通过遍历找到第i - 1个结点,即要删除结点的前驱结点
while(p != NULL && j < i - 1) {
p = p->next;
j++;
}
// 若p等于NULL,则要么此链表为空,要么i值大于链表长度,显然不合理
if(p == NULL) {
return false;
}
// p->next为空表示第i-1个结点之后已经没有其他结点了,无法进行删除操作
if(p->next == NULL) {
return false;
}
// 删除操作
// 就是将前驱结点指针域指向后继结点
LNode *q = p->next;
e = q->data;
p->next = q->next;
// 不要忘记释放空间!!!
free(q);
return true;
}
// 删除指定节点
// 类似于之前前插操作,一般情况下,显然必须先遍历找到前驱结点
// 或者类似于之前前插的第二种方法,来规避遍历
bool DeleteNode(LNode *p) {
// p不合理的情况
if(p == NULL) {
return false;
}
// 此操作可以理解为将p节点与其后继结点进行数据域交换
// 之后再删除其后继结点,可以视作完成了删除,且避免了寻找前驱结点的遍历操作
// 注意:如果p是最后一个结点则会报错,因为p->next即是NULL,不能从NULL获取数据域
// 此种情况,只能通过之前的遍历寻找前驱结点来完成删除操作
// 类似于之前插入,在找到前驱结点后,删除操作与按位序删除相同
LNode *q = p->next;
p->data = p->next->data;
p->next = q->next;
free(q);
return true;
}
// 按位查找,返回第i个元素
// 之前操作部分按位查找部分可以以此部分代码代替,提高代码复用性(封装)
LNode* GetElem(LinkList L, int i) {
// 判断插入位序是否存在问题
// 由于此是带头结点的情况,而头结点可以视作是第0个结点
// 所以与之前遍历情况不同
if(i < 0)
return NULL;
LNode *p; // 指针p指向当前扫描到的结点
int j = 0; // 当前p指向的是第几个结点
p = L; // 初始令p指向头结点
// 通过循环,找到第i个结点
// 如果i大于链表长度,则找不到此节点,此时p指向最后结点的指针域,即NULL
// 如果i初始为0,会直接返回头结点地址
while(p != NULL && j < i) {
p = p->next;
j++;
}
return p;
}
// 按值查找,找到数据域等于e的结点
LNode* LocateElem(LinkList L, int e) {
LNode* p = L->next;
// 从第一个结点开始查找数据域为e的结点
// 找不到,则会在遍历后指向NULL
while (p != NULL && p->data != e) {
p = p->next;
}
return p;
}
// 求表的长度
// 就是通过遍历所有结点,然后通过计数器来累加得到长度
int Length(LinkList L) {
int len = 0;
LNode* p = L;
while(p->next != NULL) {
p = p->next;
len++;
}
return len;
}
// 尾插法
// 通过尾插法建立的链表,顺序为插入时元素的顺序
LinkList TailInsert(LinkList &L) {
// 设置ElemType为整型
int x;
// 建立头结点(申请的空间为一个结点大小的空间)
L = (LinkList)malloc(sizeof(LNode));
// 初始化为空链表
// 由于L在分配空间后,头指针可能并非指向NULL,而是其他任意区域,这可能导致问题发生
// 动态分配的空间之前可能存在脏数据
L->next = NULL;
// 定义表尾指针
// 对于尾插法,如果只通过头结点遍历的话
// 每次插入时都要先遍历到表尾,时间复杂度为O(1+2+...+n-1)=O(n^2)
// 所以选择增加一个尾指针,来避免遍历
// s为要插入的结点,r为表尾指针
LNode *s, *r = L;
// 输入结点的值
scanf("%d", &x);
// 表示键入9999后建表结束
while(x != 9999) {
s = (LNode*)malloc(sizeof(LNode));
s->data = x;
r->next = s;
// r指向新的表尾结点
r = s;
// 继续输入下一个结点的值,直至输入9999结束
scanf("%d", &x);
}
// 尾指针置空
r->next = NULL;
return L;
}
// 头插法
// 通过头插法建立的链表,顺序为插入时元素的逆序
LinkList HeadInsert(LinkList &L) {
// 设置ElemType为整型
int x;
// 建立头结点(申请的空间为一个结点大小的空间)
L = (LinkList)malloc(sizeof(LNode));
// 初始化为空链表
// 由于L在分配空间后,头指针可能并非指向NULL,而是其他任意区域,这可能导致问题发生
// 动态分配的空间之前可能存在脏数据
L->next = NULL;
// 不同于尾插法,头插法无需定义更多指针
LNode* s;
// 输入结点的值
scanf("%d", &x);
// 表示键入9999后建表结束
while(x != 9999) {
s = (LNode*)malloc(sizeof(LNode));
s->data = x;
s->next = L->next;
L->next = s;
// 继续输入下一个结点的值,直至输入9999结束
scanf("%d", &x);
}
return L;
}
// 输出所有链表元素
void PrintList(LinkList L) {
if(Empty(L)) {
printf("the list is empty");
}
LNode* p = L->next;
while(p != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
int main() {
LinkList L;
InitList(L);
TailInsert(L);
PrintList(L);
printf("get_2:%d\n", GetElem(L, 2)->data);
printf("locate_5:%d\n", LocateElem(L, 5)->data);
printf("length:%d\n", Length(L));
InsertPriorNode(GetElem(L, 2), 7);
PrintList(L);
InsertNextNode(GetElem(L, 2), 5);
PrintList(L);
ListInsert(L, 3, 3);
PrintList(L);
int e;
ListDelete(L, 3, e);
PrintList(L);
printf("e:%d\n", e);
}
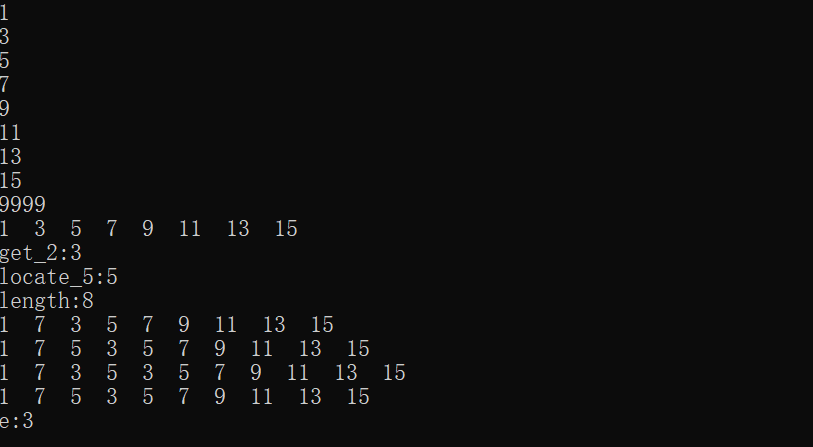
3.运行截图