深度强化学习实验室
官网:http://www.neurondance.com/
论坛:http://deeprl.neurondance.com/
作者:深度强化学习实验室
来源:整理自https://icml.cc/
ICML 是机器学习领域最重要的会议之一,在该会议上发表论文的研究者也会备受关注。近年来,ICML会议的投稿数量一直增长:ICML 2020 投稿量为4990篇,ICML 2021的投稿量5513, 在一个月之前,ICML 2021的论文接收结果已经公布,其中1184篇论文被接收,接收率为 21.5% 。
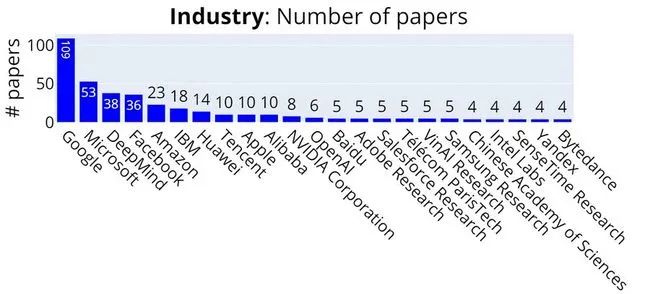
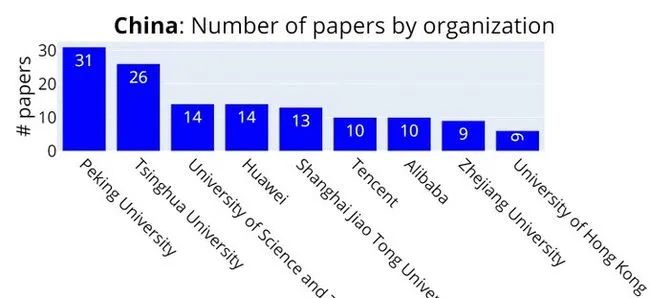
(注:图片参考自AI科技评论)
而就在近日,ICML 2021的论文接收列表也终于放了出来,本文整理强化学习领域大约163篇文章,具体列表如下:(也可访问实验室论坛参与讨论)
[1]. Revisiting Rainbow: Promoting more insightful and inclusive deep reinforcement learning research
作者: Johan Obando Ceron (UAO) · Pablo Samuel Castro (Google Brain)
[2]. First-Order Methods for Wasserstein Distributionally Robust MDP
作者: Julien Grand-Clement (IEOR Department, Columbia University) · Christian Kroer (Columbia University)
[3]. REPAINT: Knowledge Transfer in Deep Reinforcement Learning
作者: Yunzhe Tao (ByteDance) · Sahika Genc (Amazon AI) · Jonathan Chung (AWS) · TAO SUN (Amazon.com) · Sunil Mallya (Amazon AWS)
[4]. Uncertainty Weighted Actor-Critic for Offline Reinforcement Learning
作者: Yue Wu (Carnegie Mellon University) · Shuangfei Zhai (Apple) · Nitish Srivastava (Apple) · Joshua Susskind (Apple, Inc.) · Jian Zhang (Apple Inc.) · Ruslan Salakhutdinov (Carnegie Mellen University) · Hanlin Goh (Apple)
[5]. Detecting Rewards Deterioration in Episodic Reinforcement Learning
作者: Ido Greenberg (Technion) · Shie Mannor (Technion)
[6]. Model-Free Reinforcement Learning: from Clipped Pseudo-Regret to Sample Complexity
作者: Zhang Zihan (Tsinghua University) · Yuan Zhou (UIUC) · Xiangyang Ji (Tsinghua University)
[7]. Near Optimal Reward-Free Reinforcement Learning
作者: Zhang Zihan (Tsinghua University) · Simon Du (University of Washington) · Xiangyang Ji (Tsinghua University)
[8]. On Reinforcement Learning with Adversarial Corruption and Its Application to Block MDP
作者: Tianhao Wu (Peking University) · Yunchang Yang (Center for Data Science, Peking University) · Simon Du (University of Washington) · Liwei Wang (Peking University)
[9]. Average-Reward Off-Policy Policy Evaluation with Function Approximation
作者: Shangtong Zhang (University of Oxford) · Yi Wan (University of Alberta) · Richard Sutton (DeepMind / Univ Alberta) · Shimon Whiteson (University of Oxford)
[10]. Exponential Lower Bounds for Batch Reinforcement Learning: Batch RL can be Exponentially Harder than Online RL
作者: Andrea Zanette (Stanford University)
[11]. Is Model-Free Learning Nearly Optimal for Non-Stationary RL?
作者: Weichao Mao (University of Illinois at Urbana-Champaign) · Kaiqing Zhang (University of Illinois at Urbana-Champaign/MIT) · Ruihao Zhu (MIT) · David Simchi-Levi (MIT) · Tamer Basar (University of Illinois at Urbana-Champaign)
[12]. DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
作者: Daochen Zha (Texas A&M University) · Jingru Xie (Kwai Inc.) · Wenye Ma (Kuaishou) · Sheng Zhang (Georgia Institute of Technology) · Xiangru Lian (Kwai Inc.) · Xia Hu (Texas A&M University) · Ji Liu (Kwai Seattle AI lab, University of Rochester)
[13]. Accelerating Safe Reinforcement Learning with Constraint-mismatched Baseline Policies
作者: Jimmy (Tsung-Yen) Yang (Princeton University) · Justinian Rosca (Siemens Corp.) · Karthik Narasimhan (Princeton) · Peter Ramadge (Princeton)
[14]. Revisiting Peng's Q($\lambda$) for Modern Reinforcement Learning
作者: Tadashi Kozuno (University of Alberta) · Yunhao Tang (Columbia University) · Mark Rowland (DeepMind) · Remi Munos (DeepMind) · Steven Kapturowski (Deepmind) · Will Dabney (DeepMind) · Michal Valko (DeepMind / Inria / ENS Paris-Saclay) · David Abel (DeepMind)
[15]. Ensemble Bootstrapping for Q-Learning
作者: Oren Peer (Technion) · Chen Tessler (Technion) · Nadav Merlis (Technion) · Ron Meir (Technion Israeli Institute of Technology)
[16]. Phasic Policy Gradient
作者: Karl Cobbe (OpenAI) · Jacob Hilton (OpenAI) · Oleg Klimov (OpenAI) · John Schulman (OpenAI)
[17]. Optimal Off-Policy Evaluation from Multiple Logging Policies
作者: Nathan Kallus (Cornell University) · Yuta Saito (Tokyo Institute of Technology.) · Masatoshi Uehara (Cornell University)
[18]. Risk Bounds and Rademacher Complexity in Batch Reinforcement Learning
作者: Yaqi Duan (Princeton University) · Chi Jin (Princeton University) · Zhiyuan Li (Princeton University)
[19]. Finite-Sample Analysis of Off-Policy Natural Actor-Critic Algorithm
作者: sajad khodadadian (georgia institute of technology) · Zaiwei Chen (Georgia Institute of Technology) · Siva Maguluri (Georgia Tech)
[20]. SUNRISE: A Simple Unified Framework for Ensemble Learning in Deep Reinforcement Learning
作者: Kimin Lee (UC Berkeley) · Michael Laskin (UC Berkeley) · Aravind Srinivas (UC Berkeley) · Pieter Abbeel (UC Berkeley & Covariant)
[21]. Reinforcement Learning with Prototypical Representations
作者: Denis Yarats (New York University) · Rob Fergus (Facebook / NYU) · Alessandro Lazaric (Facebook AI Research) · Lerrel Pinto (NYU/Berkeley)
[22]. Evaluating the Implicit Midpoint Integrator for Riemannian Hamiltonian Monte Carlo
作者: James Brofos (Yale University) · Roy Lederman (Yale University)
[23]. Deep Reinforcement Learning amidst Continual Structured Non-Stationarity
作者: Annie Xie (Stanford University) · James Harrison (Stanford University) · Chelsea Finn (Stanford)
[24]. Off-Policy Confidence Sequences
作者: Nikos Karampatziakis (Microsoft) · Paul Mineiro (Microsoft) · Aaditya Ramdas (Carnegie Mellon University)
[25]. Deeply-Debiased Off-Policy Interval Estimation
作者: Chengchun Shi (London School of Economics and Political Science) · Runzhe Wan (North Carolina State University) · Victor Chernozhukov (MIT) · Rui Song (North Carolina State University)
[26]. Improving Lossless Compression Rates via Monte Carlo Bits-Back Coding
作者: Yangjun Ruan (University of Toronto) · Karen Ullrich (FAIR) · Daniel Severo (University of Toronto) · James Townsend () · Ashish Khisti (Univ. of Toronto) · Arnaud Doucet (Oxford University) · Alireza Makhzani (University of Toronto) · Chris Maddison (University of Toronto)
[27]. Logarithmic Regret for Reinforcement Learning with Linear Function Approximation
作者: Jiafan He (University of California, Los Angeles) · Dongruo Zhou (UCLA) · Quanquan Gu (University of California, Los Angeles)
[28]. Randomized Entity-wise Factorization for Multi-Agent Reinforcement Learning
作者: Shariq Iqbal (University of Southern California) · Christian Schroeder (University of Oxford) · Bei Peng (University of Oxford) · Wendelin Boehmer (Delft University of Technology) · Shimon Whiteson (University of Oxford) · Fei Sha (Google Research)
[29]. Monotonic Robust Policy Optimization with Model Discrepancy
作者: yuankun jiang (Shanghai Jiao Tong University) · Chenglin Li (Shanghai Jiao Tong University) · Wenrui Dai (Shanghai Jiao Tong University) · Junni Zou (Shanghai Jiao Tong University) · Hongkai Xiong (Shanghai Jiao Tong University)
[30]. Guided Exploration with Proximal Policy Optimization using a Single Demonstration
作者: Gabriele Libardi (Pompeu Fabra University) · Gianni De Fabritiis (Universitat Pompeu Fabra) · Sebastian Dittert (Universitat Pompeu Fabra)
[31]. Diversity Actor-Critic: Sample-Aware Entropy Regularization for Sample-Efficient Exploration
作者: Seungyul Han (KAIST) · Youngchul Sung (KAIST)
[32]. On-Policy Reinforcement Learning for the Average-Reward Criterion
作者: Yiming Zhang (New York University) · Keith Ross (New York University Shanghai)
[33]. UneVEn: Universal Value Exploration for Multi-Agent Reinforcement Learning
作者: Tarun Gupta (University of Oxford) · Anuj Mahajan (Dept. of Computer Science, University of Oxford) · Bei Peng (University of Oxford) · Wendelin Boehmer (Delft University of Technology) · Shimon Whiteson (University of Oxford)
[34]. Demonstration-Conditioned Reinforcement Learning for Few-Shot Imitation
作者: Christopher Dance (NAVER LABS Europe) · Perez Julien (Naver Labs Europe) · Théo Cachet (Naver Labs Europe)
[35]. Feature Clustering for Support Identification in Extreme Regions
作者: Hamid Jalalzai (Inria) · Rémi Leluc (Télécom Paris)
[36]. Multi-Task Reinforcement Learning with Context-based Representations
作者: Shagun Sodhani (Facebook AI Research) · Amy Zhang (FAIR / McGill) · Joelle Pineau (McGill, Facebook)
[37]. Online Policy Gradient for Model Free Learning of Linear Quadratic Regulators with √T Regret
作者: Asaf Cassel (Tel Aviv University) · Tomer Koren (Tel Aviv University and Google)
[38]. Learning and Planning in Average-Reward Markov Decision Processes
作者: Yi Wan (University of Alberta) · Abhishek Naik (University of Alberta) · Richard Sutton (DeepMind / Univ Alberta)
[39]. MetaCURE: Meta Reinforcement Learning with Empowerment-Driven Exploration
作者: Jin Zhang (Tsinghua University) · Jianhao Wang (Tsinghua University) · Hao Hu (Tsinghua University) · Tong Chen (Tsinghua University) · Yingfeng Chen (NetEase Fuxi AI Lab) · Changjie Fan (NetEase Fuxi AI Lab) · Chongjie Zhang (Tsinghua University)
[40]. A Lower Bound for the Sample Complexity of Inverse Reinforcement Learning
作者: Abi Komanduru (Purdue University) · Jean Honorio (Purdue University)
[41]. Safe Reinforcement Learning with Linear Function Approximation
作者: Sanae Amani (University of California, Los Angeles) · Christos Thrampoulidis (University of British Columbia) · Lin Yang (UCLA)
[42]. Combining Pessimism with Optimism for Robust and Efficient Model-Based Deep Reinforcement Learning
作者: Sebastian Curi (ETH) · Ilija Bogunovic (ETH Zurich) · Andreas Krause (ETH Zurich)
[43]. A Precise Performance Analysis of Support Vector Regression
作者: Houssem Sifaou (King Abdullah University of Science and Technology (KAUST)) · Abla Kammoun (KAUST) · Mohamed-Slim Alouini (King Abdullah University of Science and Technology )
[44]. Generalizable Episodic Memory for Deep Reinforcement Learning
作者: Hao Hu (Tsinghua University) · Jianing Ye (Peking University) · Guangxiang Zhu (Tsinghua University) · Zhizhou Ren (University of Illinois at Urbana-Champaign) · Chongjie Zhang (Tsinghua University)
[45]. Provably Efficient Reinforcement Learning for Discounted MDPs with Feature Mapping
作者: Dongruo Zhou (UCLA) · Jiafan He (University of California, Los Angeles) · Quanquan Gu (University of California, Los Angeles)
[46]. Decentralized Single-Timescale Actor-Critic on Zero-Sum Two-Player Stochastic Games
作者: Hongyi Guo (Northwestern University) · Zuyue Fu (Northwestern) · Zhuoran Yang (Princeton) · Zhaoran Wang (Northwestern U)
[47]. Adaptive Sampling for Best Policy Identification in Markov Decision Processes
作者: Aymen Al Marjani (ENS Lyon) · Alexandre Proutiere (KTH Royal Institute of Technology)
[48]. Inverse Constrained Reinforcement Learning
作者: Shehryar Malik (Information Technology University) · Usman Anwar (Information Technlogy University, Lahore.) · Alireza Aghasi (Georgia State University) · Ali Ahmed (Information Technology University)
[49]. Self-Paced Context Evaluation for Contextual Reinforcement Learning
作者: Theresa Eimer (Leibniz Universität Hannover) · André Biedenkapp (University of Freiburg) · Frank Hutter (University of Freiburg and Bosch Center for Artificial Intelligence) · Marius Lindauer (Leibniz University Hannover)
[50]. On the Convergence of Hamiltonian Monte Carlo with Stochastic Gradients
作者: Difan Zou (UCLA) · Quanquan Gu (University of California, Los Angeles)
[51]. DG-LMC: A Turn-key and Scalable Synchronous Distributed MCMC Algorithm via Langevin Monte Carlo within Gibbs
作者: Vincent Plassier (Huawei) · Maxime Vono (Lagrange Mathematics and Computing Research Center) · Alain Durmus (ENS Paris Saclay) · Eric Moulines (Ecole Polytechnique)
[52]. Meta Learning for Support Recovery in High-dimensional Precision Matrix Estimation
作者: Qian Zhang (Purdue University) · Yilin Zheng (Purdue university) · Jean Honorio (Purdue University)
[53]. Optimal Thompson Sampling strategies for support-aware CVaR bandits
作者: Dorian Baudry (CNRS/INRIA) · Romain Gautron (CIRAD - CGIAR) · Emilie Kaufmann (CNRS, Univ. Lille) · Odalric-Ambrym Maillard (Inria Lille - Nord Europe)
[54]. High Confidence Generalization for Reinforcement Learning
作者: James Kostas (University of Massachusetts Amherst) · Yash Chandak (University of Massachusetts Amherst) · Scott M Jordan (University of Massachusetts) · Georgios Theocharous (Adobe Research) · Philip Thomas (University of Massachusetts Amherst)
[55]. Robust Asymmetric Learning in POMDPs
作者: Andrew Warrington (University of Oxford) · Jonathan Lavington (University of British Columbia) · Adam Scibior (University of British Columbia) · Mark Schmidt (University of British Columbia) · Frank Wood (University of British Columbia)
[56]. Risk-Sensitive Reinforcement Learning with Function Approximation: A Debiasing Approach
作者: Yingjie Fei (Cornell University) · Zhuoran Yang (Princeton University) · Zhaoran Wang (Northwestern U)
[57]. Decoupling Value and Policy for Generalization in Reinforcement Learning
作者: Roberta Raileanu (NYU) · Rob Fergus (Facebook / NYU)
[58]. Learning Routines for Effective Off-Policy Reinforcement Learning
作者: Edoardo Cetin (King's College London) · Oya Celiktutan (King's College London)
[59]. Emergent Social Learning via Multi-agent Reinforcement Learning
作者: Kamal Ndousse (OpenAI) · Douglas Eck (Google Brain) · Sergey Levine (UC Berkeley) · Natasha Jaques (Google Brain, UC Berkeley)
[60]. DFAC Framework: Factorizing the Value Function via Quantile Mixture for Multi-Agent Distributional Q-Learning
作者: Wei-Fang Sun (National Tsing Hua University) · Cheng-Kuang Lee (NVIDIA Corporation) · Chun-Yi Lee (National Tsing Hua University)
[61]. Shortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
作者: Sungryull Sohn (University of Michigan) · Sungtae Lee (Yonsei University) · Jongwook Choi (University of Michigan) · Harm van Seijen (Microsoft Research) · Mehdi Fatemi (Microsoft Research) · Honglak Lee (Google / U. Michigan)
[62]. What Structural Conditions Permit Generalization in Reinforcement Learning?
作者: Simon Du (University of Washington) · Sham Kakade (University of Washington) · Jason Lee (Princeton) · Shachar Lovett (University of California San Diego) · Gaurav Mahajan (UCSD) · Wen Sun (Cornell University) · Ruosong Wang (Carnegie Mellon University)
[63]. On Proximal Policy Optimization's Heavy-tailed Gradients
作者: Saurabh Garg (Carnegie Mellon University) · Joshua Zhanson (Carnegie Mellon University) · Emilio Parisotto (Carnegie Mellon University) · Adarsh Prasad (Carnegie Mellon University) · Zico Kolter (Carnegie Mellon University / Bosch Center for AI) · Sivaraman Balakrishnan (CMU) · Zachary Lipton (Carnegie Mellon University) · Ruslan Salakhutdinov (Carnegie Mellen University) · Pradeep Ravikumar (Carnegie Mellon University)
[64]. The Symmetry between Arms and Knapsacks: A Primal-Dual Approach for Bandits with Knapsacks
作者: Xiaocheng Li (Imperial College London) · Chunlin Sun (Stanford University) · Yinyu Ye (Standord)
[65]. Sample Efficient Reinforcement Learning In Continuous State Spaces: A Perspective Beyond Linearity
作者: Dhruv Malik (Carnegie Mellon University) · Aldo Pacchiano (UC Berkeley) · Vishwak Srinivasan (Carnegie Mellon University) · Yuanzhi Li (CMU)
[66]. Improved Regret Bound and Experience Replay in Regularized Policy Iteration
作者: Nevena Lazic (DeepMind) · Dong Yin (DeepMind) · Yasin Abbasi-Yadkori (Adobe Research) · Csaba Szepesvari (DeepMind/University of Alberta)
[67]. Tightening the Dependence on Horizon in the Sample Complexity of Q-Learning
作者: Gen Li (Tsinghua University, China) · Changxiao Cai (Princeton University) · Yuxin Chen (Princeton University) · Yuantao Gu (Tsinghua University) · Yuting Wei (Carnegie Mellon University) · Yuejie Chi (CMU)
[68]. The Emergence of Individuality in Multi-Agent Reinforcement Learning
作者: Jiechuan Jiang (Peking University) · Zongqing Lu (Peking University)
[69]. MURAL: Meta-Learning Uncertainty-Aware Rewards for Outcome-Driven Reinforcement Learning
作者: Kevin Li (UC Berkeley) · Abhishek Gupta (UC Berkeley) · Ashwin D Reddy (UC Berkeley) · Vitchyr Pong (UC Berkeley) · Aurick Zhou (UC Berkeley) · Justin Yu (Berkeley) · Sergey Levine (UC Berkeley)
[70]. Cooperative Exploration for Multi-Agent Deep Reinforcement Learning
作者: Iou-Jen Liu (University of Illinois at Urbana-Champaign) · Unnat Jain (UIUC) · Raymond Yeh (University of Illinois at Urbana–Champaign) · Alexander Schwing (UIUC)
[71]. Global Convergence of Policy Gradient for Linear-Quadratic Mean-Field Control/Game in Continuous Time
作者: Weichen Wang (Two Sigma Investments, LP) · Jiequn Han (Princeton University) · Zhuoran Yang (Princeton University) · Zhaoran Wang (Northwestern)
[72]. Towards Better Laplacian Representation in Reinforcement Learning with Generalized Graph Drawing
作者: Kaixin Wang (National University of Singapore) · Kuangqi Zhou (National University of Singapore) · Qixin Zhang (city university of hong kong) · Jie Shao (Fudan University) · Bryan Hooi (National University of Singapore) · Jiashi Feng (National University of Singapore)
[73]. Model-Free and Model-Based Policy Evaluation when Causality is Uncertain
作者: David Bruns-Smith (UC Berkeley)
[74]. GMAC: A Distributional Perspective on Actor-Critic Framework
作者: Daniel Nam (KC Machine Learning Lab) · Younghoon Kim (KC-ML2) · Chan Youn Park (KC ML2)
[75]. Offline Reinforcement Learning with Fisher Divergence Critic Regularization
作者: Ilya Kostrikov (Google/New York University) · Rob Fergus (DeepMind) · Jonathan Tompson (Google Brain) · Ofir Nachum (Google Brain)
[76]. A Sharp Analysis of Model-based Reinforcement Learning with Self-Play
作者: Qinghua Liu (Princeton University) · Tiancheng Yu (MIT) · Yu Bai (Salesforce Research) · Chi Jin (Princeton University)
[77]. Density Constrained Reinforcement Learning
作者: Zengyi Qin (MIT) · Yuxiao Chen (California Institute of Technology) · Chuchu Fan (MIT)
[78]. Decoupling Exploration and Exploitation for Meta-Reinforcement Learning without Sacrifices
作者: Evan Liu (Stanford University) · Aditi Raghunathan (Stanford) · Percy Liang (Stanford University) · Chelsea Finn (Stanford)
[79]. CRPO: A New Approach for Safe Reinforcement Learning with Convergence Guarantee
作者: Tengyu Xu (The Ohio State University) · Yingbin LIANG (The Ohio State University) · Guanghui Lan (Georgia Institute of Technology)
[80]. Large-Scale Multi-Agent Deep FBSDEs
作者: Tianrong Chen (Georgia Institute of Technology) · Ziyi Wang (Georgia Institute of Technology) · Ioannis Exarchos (Stanford University) · Evangelos Theodorou (Georgia Tech)
[81]. Model-based Reinforcement Learning for Continuous Control with Posterior Sampling
作者: Ying Fan (University of Wisconsin-Madison) · Yifei Ming (University of Wisconsin-Madison)
[82]. SAINT-ACC: Safety-Aware Intelligent Adaptive Cruise Control for Autonomous Vehicles Using Deep Reinforcement Learning
作者: Lokesh Chandra Das (The University of Memphis) · Myounggyu Won (University of Memphis)
[83]. Robust Reinforcement Learning using Least Squares Policy Iteration with Provable Performance Guarantees
作者: Kishan Panaganti (TAMU) · Dileep Kalathil (TAMU)
[84]. Modularity in Reinforcement Learning via Algorithmic Independence in Credit Assignment
作者: Michael Chang (UC Berkeley) · Sid Kaushik (UCB) · Sergey Levine (UC Berkeley) · Thomas Griffiths (Princeton University)
[85]. Doubly Robust Off-Policy Actor-Critic: Convergence and Optimality
作者: Tengyu Xu (The Ohio State University) · Zhuoran Yang (Princeton University) · Zhaoran Wang (Northwestern U) · Yingbin LIANG (The Ohio State University)
[86]. Matrix Completion with Model-free Weighting
作者: Jiayi Wang (Texas A&M University) · Raymond K. W. Wong (Texas A&M University) · Xiaojun Mao (Fudan University) · Kwun Chuen Gary Chan (University of Washington)
[87]. Improved Corruption Robust Algorithms for Episodic Reinforcement Learning
作者: Yifang Chen (University of Washington) · Simon Du (University of Washington) · Kevin Jamieson (University of Washington)
[88]. Offline Meta-Reinforcement Learning with Advantage Weighting
作者: Eric Mitchell (Stanford) · Rafael Rafailov (Stanford University) · Xue Bin Peng (UC Berkeley) · Sergey Levine (University of California, Berkeley) · Chelsea Finn (Stanford)
[89]. Tesseract: Tensorised Actors for Multi-Agent Reinforcement Learning
作者: Anuj Mahajan (Dept. of Computer Science, University of Oxford) · Mikayel Samvelyan (University College London) · Lei Mao (NVIDIA) · Viktor Makoviychuk (NVIDIA) · Animesh Garg (University of Toronto, Vector Institute, Nvidia) · Jean Kossaifi (NVIDIA) · Shimon Whiteson (University of Oxford) · Yuke Zhu (University of Texas - Austin) · Anima Anandkumar (Caltech and NVIDIA)
[90]. Automatic RNN Repair via Model-based Analysis
作者: Xiaofei Xie (Nanyang Technological University) · Wenbo Guo (Pennsylvania State University) · Lei Ma (University of Alberta) · Wei Le (Iowa State University ) · Jian Wang (Nanyang Technological University) · Lingjun Zhou (College of Intelligence and Computing,Tianjin University) · Yang Liu (Nanyang Technology University, Singapore) · Xinyu Xing (The Pennsylvania State University)
[91]. PEBBLE: Feedback-Efficient Interactive Reinforcement Learning via Relabeling Experience and Unsupervised Pre-training
作者: Kimin Lee (UC Berkeley) · Laura Smith (UC Berkeley) · Pieter Abbeel (UC Berkeley & Covariant)
[92]. Recomposing the Reinforcement Learning Building Blocks with Hypernetworks
作者: shai keynan (Bar Ilan University) · Elad Sarafian (Bar-Ilan University) · Sarit Kraus (Bar-Ilan University)
[93]. PODS: Policy Optimization via Differentiable Simulation
作者: Miguel Angel Zamora Mora (ETH Zurich) · Momchil Peychev (ETH Zurich) · Sehoon Ha (Georgia Institute of Technology) · Martin Vechev (ETH Zurich) · Stelian Coros (ETH Zurich)
[94]. Bootstrapping Fitted Q-Evaluation for Off-Policy Inference
作者: Botao Hao (Princeton University) · Xiang Ji (Princeton University) · Yaqi Duan (Princeton University) · Hao Lu (Princeton University) · Csaba Szepesvari (DeepMind/University of Alberta) · Mengdi Wang (Princeton University)
[95]. Sparse Feature Selection Makes Batch Reinforcement Learning More Sample Efficient
作者: Botao Hao (Princeton University) · Yaqi Duan (Princeton University) · Tor Lattimore (DeepMind) · Csaba Szepesvari (DeepMind/University of Alberta) · Mengdi Wang (Princeton University)
[96]. Solving Challenging Dexterous Manipulation Tasks With Trajectory Optimisation and Reinforcement Learning
作者: Henry Charlesworth (University of Warwick) · Giovanni Montana (University of Warwick)
[97]. Monte Carlo Variational Auto-Encoders
作者: Achille Thin (Ecole polytechnique) · Nikita Kotelevskii (Skolkovo Institute of Science and Technology) · Arnaud Doucet (Oxford University) · Alain Durmus (ENS Paris Saclay) · Eric Moulines (Ecole Polytechnique) · Maxim Panov (Skolkovo Institute of Science and Technology)
[98]. Fast active learning for pure exploration in reinforcement learning
作者: Pierre MENARD (Inria) · Omar Darwiche Domingues (Inria) · Anders Jonsson (Universitat Pompeu Fabra) · Emilie Kaufmann (CNRS, Univ. Lille) · Edouard Leurent () · Michal Valko (DeepMind / Inria / ENS Paris-Saclay)
[99]. UCB Momentum Q-learning: Correcting the bias without forgetting
作者: Pierre MENARD (Inria) · Omar Darwiche Domingues (Inria) · Xuedong Shang (Inria) · Michal Valko (DeepMind / Inria / ENS Paris-Saclay)
[100]. Continuous-time Model-based Reinforcement Learning
作者: Cagatay Yildiz (Aalto University) · Markus Heinonen (Aalto University) · Harri Lähdesmäki (Aalto University)
[101]. Policy Information Capacity: Information-Theoretic Measure for Task Complexity in Deep Reinforcement Learning
作者: Hiroki Furuta (The University of Tokyo) · Tatsuya Matsushima (The University of Tokyo) · Tadashi Kozuno (University of Alberta) · Yutaka Matsuo (University of Tokyo) · Sergey Levine (UC Berkeley) · Ofir Nachum (Google Brain) · Shixiang Gu (Google)
[102]. Kernel-Based Reinforcement Learning: Finite-Time Analysis for a Practical Algorithm
作者: Omar Darwiche Domingues (Inria) · Pierre Menard (Inria) · Matteo Pirotta (Facebook AI Research) · Emilie Kaufmann (CNRS, Univ. Lille) · Michal Valko (DeepMind / Inria / ENS Paris-Saclay)
[103]. Scaling Multi-Agent Reinforcement Learning with Selective Parameter Sharing
作者: Filippos Christianos (University of Edinburgh) · Georgios Papoudakis (The University of Edinburgh) · Muhammad Arrasy Rahman (The University of Edinburgh) · Stefano Albrecht (University of Edinburgh)
[104]. A Novel Method to Solve Neural Knapsack Problems
作者: Duanshun Li (University of Alberta) · Jing Liu (Walmart Research Lab.) · Dongeun Lee (Texas A&M University-Commerce) · Ali Seyedmazloom (George Mason Univeristy) · Giridhar Kaushik (George Mason Univeristy) · Kookjin Lee (Sandia National Laboratories) · Noseong Park (Yonsei University, Korea)
[105]. Data-efficient Hindsight Off-policy Option Learning
作者: Markus Wulfmeier (DeepMind) · Dushyant Rao (DeepMind) · Roland Hafner (DeepMind) · Thomas Lampe (DeepMind) · Abbas Abdolmaleki (DeepMind) · Tim Hertweck (DeepMind) · Michael Neunert (Google DeepMind) · Dhruva Tirumala Bukkapatnam (DeepMind) · Noah Siegel (DeepMind) · Nicolas Heess (DeepMind) · Martin Riedmiller (DeepMind)
[106]. A Gradient Based Strategy for Hamiltonian Monte Carlo Hyperparameter Optimization
作者: Andrew Campbell (University of Oxford) · Wenlong Chen (University of Cambridge) · Vincent Stimper (University of Cambridge) · Jose Miguel Hernandez-Lobato (University of Cambridge) · Yichuan Zhang (Boltzbit Limited)
[107]. Muesli: Combining Improvements in Policy Optimization
作者: Matteo Hessel (Deep Mind) · Ivo Danihelka (DeepMind) · Fabio Viola (DeepMind) · Arthur Guez (Google DeepMind) · Simon Schmitt (DeepMind) · Laurent Sifre (DeepMind) · Theophane Weber (DeepMind) · David Silver (Google DeepMind) · Hado van Hasselt (DeepMind)
[108]. Annealed Flow Transport Monte Carlo
作者: Michael Arbel (University College London) · Alexander Matthews (DeepMind) · Arnaud Doucet (Google DeepMind)
[109]. Parallel Droplet Control in MEDA Biochips using Multi-Agent Reinforcement Learning
作者: Tung-Che Liang (Duke University) · Jin Zhou (Duke University) · Yun-Sheng Chan (National Chiao Tung University) · Tsung-Yi Ho (National Tsing Hua University) · Krishnendu Chakrabarty (Duke University) · Cy Lee (National Chiao Tung University)
[110]. Submodular Maximization subject to a Knapsack Constraint: Combinatorial Algorithms with Near-optimal Adaptive Complexity
作者: Georgios Amanatidis (University of Essex) · Federico Fusco (Sapienza University of Rome) · Philip Lazos (Sapienza University of Rome) · Stefano Leonardi (Sapienza University of Rome) · Alberto Marchetti-Spaccamela (Sapienza University of Rome) · Rebecca Reiffenhäuser (Sapienza University of Rome)
[111]. Reinforcement Learning for Cost-Aware Markov Decision Processes
作者: Wesley Suttle (Stony Brook University) · Kaiqing Zhang (University of Illinois at Urbana-Champaign/MIT) · Zhuoran Yang (Princeton University) · Ji Liu (Stony Brook University) · David N Kraemer (Stony Brook University)
[112]. Low-Precision Reinforcement Learning: Running Soft Actor-Critic in Half Precision
作者: Johan Björck (Cornell) · Xiangyu Chen (Cornell University) · Christopher De Sa (Cornell) · Carla Gomes (Cornell University) · Kilian Weinberger (Cornell University)
[113]. Reward Identification in Inverse Reinforcement Learning
作者: Kuno Kim (Stanford University) · Shivam Garg (Stanford University) · Kirankumar Shiragur (Stanford University) · Stefano Ermon (Stanford University)
[114]. Offline Reinforcement Learning with Pseudometric Learning
作者: Robert Dadashi (Google AI Residency Program) · Shideh Rezaeifar (University of Geneva) · Nino Vieillard (Google Brain) · Léonard Hussenot (Google Research, Brain Team) · Olivier Pietquin (GOOGLE BRAIN) · Matthieu Geist (Google)
[115]. Variational Empowerment as Representation Learning for Goal-Conditioned Reinforcement Learning
作者: Jongwook Choi (University of Michigan) · Archit Sharma () · Honglak Lee (Google / U. Michigan) · Sergey Levine (Google) · Shixiang Gu (Google)
[116]. Exploration in Approximate Hyper-State Space for Meta Reinforcement Learning
作者: Luisa Zintgraf (University of Oxford) · Leo Feng (Mila) · Cong Lu (University of Oxford) · Maximilian Igl (University of Oxford) · Kristian Hartikainen (UC Berkeley) · Katja Hofmann (Microsoft) · Shimon Whiteson (University of Oxford)
[117]. PsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
作者: Angelos Filos (University of Oxford) · Clare Lyle (University of Oxford) · Yarin Gal (University of Oxford) · Sergey Levine (UC Berkeley) · Natasha Jaques (Google Brain, UC Berkeley) · Gregory Farquhar (University of Oxford)
[118]. Safe Reinforcement Learning Using Advantage-Based Intervention
作者: Nolan Wagener (Georgia Tech) · Ching-An Cheng (Microsoft Research) · Byron Boots (University of Washington)
[119]. Decoupling Representation Learning from Reinforcement Learning
作者: Adam Stooke (UC Berkeley) · Kimin Lee (UC Berkeley) · Pieter Abbeel (UC Berkeley & Covariant) · Michael Laskin (UC Berkeley)
[120]. Goal-Conditioned Reinforcement Learning with Imagined Subgoals
作者: Elliot Chane-Sane (INRIA Paris) · Cordelia Schmid (Inria/Google) · Ivan Laptev (INRIA Paris)
[121]. A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
作者: Dong Ki Kim (MIT) · Miao Liu (IBM) · Matthew Riemer (IBM Research) · Chuangchuang Sun (MIT) · Marwa Abdulhai (MIT) · Golnaz Habibi (MIT) · Sebastian Lopez-Cot (MIT) · Gerald Tesauro (IBM Research) · Jonathan How (MIT)
[122]. Massively Parallel and Asynchronous Tsetlin Machine Architecture Supporting Almost Constant-Time Scaling
作者: Ole-Christoffer Granmo (University of Agder) · Rohan Kumar Yadav (University of Agder) · Kuruge Darshana Abeyrathna (University of Agder, Norway) · Lei Jiao (University of Agder) · Rupsa Saha (University of Agder) · Bimal Bhattarai (University of Agder) · Saeed Rahimi Gorji (University of Agder) · Morten Goodwin (University of Agder)
[123]. RRL: Resnet as representation for Reinforcement Learning
作者: Rutav M Shah (Indian Institute of Technology, Kharagpur) · Vikash Kumar (Univ. Of Washington)
[124]. Model-Based Reinforcement Learning via Latent-Space Collocation
作者: Oleh Rybkin (University of Pennsylvania) · Chuning Zhu (University of Pennsylvania) · Anusha Nagabandi (UC Berkeley) · Kostas Daniilidis (University of Pennsylvania) · Igor Mordatch (Google Brain) · Sergey Levine (UC Berkeley)
[125]. Robust Policy Gradient against Strong Data Corruption
作者: Xuezhou Zhang (UW-Madison) · Yiding Chen (University of Wisconsin-Madison) · Jerry Zhu (University of Wisconsin-Madison) · Wen Sun (Cornell University)
[126]. OptiDICE: Offline Policy Optimization via Stationary Distribution Correction Estimation
作者: Jongmin Lee (KAIST) · Wonseok Jeon (MILA, McGill University) · Byung-Jun Lee (KAIST) · Joelle Pineau (McGill University / Facebook) · Kee-Eung Kim (KAIST)
[127]. Quantum algorithms for reinforcement learning with a generative model
作者: Ashish Kapoor (Microsoft Research) · Robin Kothari (Microsoft) · Martin Roetteler (Microsoft) · Aarthi Sundaram (Microsoft) · Daochen Wang (University of Maryland)
[128]. Efficient Performance Bounds for Primal-Dual Reinforcement Learning from Demonstrations
作者: Angeliki Kamoutsi (ETH Zurich) · Goran Banjac (ETH Zurich) · John Lygeros (ETH Zürich)
[129]. Controlling Graph Dynamics with Reinforcement Learning and Graph Neural Networks
作者: Eli Meirom (NVIDIA Research) · Haggai Maron (NVIDIA Research) · Shie Mannor (Technion) · Gal Chechik (NVIDIA / Bar-Ilan University)
[130]. Emphatic Algorithms for Deep Reinforcement Learning
作者: Tian Jiang (Facebook) · Tom Zahavy (DeepMind) · Zhongwen Xu (DeepMind) · Adam White (Deepmind, University of Alberta) · Matteo Hessel (Deep Mind) · Charles Blundell (DeepMind) · Hado van Hasselt (DeepMind)
[131]. Learning node representations using stationary flow prediction on large payment and cash transaction networks
作者: Ciwan Ceylan (KTH Royal Institute of Technology & SEB) · Salla Franzén (SEB AB) · Florian T. Pokorny (KTH Royal Institute of Technology)
[132]. Scalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
作者: Joel Z Leibo (DeepMind) · Edgar Duenez-Guzman (DeepMind) · Alexander Vezhnevets (DeepMind) · John Agapiou (DeepMind) · Peter Sunehag () · Raphael Koster (DeepMind) · Jayd Matyas (DeepMind) · Charles Beattie (DeepMind Technologies Limited) · Igor Mordatch (Google Brain) · Thore Graepel (DeepMind)
[133]. Grounding Language to Entities and Dynamics for Generalization in Reinforcement Learning
作者: Austin W. Hanjie (Princeton University) · Victor Zhong (University of Washington) · Karthik Narasimhan (Princeton)
[134]. Discovering symbolic policies with deep reinforcement learning
作者: Sookyung Kim (Lawrence Livermore National Laboratory) · Mikel Landajuela (Lawrence Livermore National Laboroatory) · Brenden Petersen (Lawrence Livermore National Laboratory) · Claudio Santiago (LLNL) · Ruben Glatt (LLNL) · Nathan Mundhenk (Lawrence Livermore National Labs) · Jacob Pettit (Lawrence Livermore National Laboratory) · Daniel Faissol (Lawrence Livermore National Laboratory)
[135]. A Deep Reinforcement Learning Approach to Marginalized Importance Sampling with the Successor Representation
作者: Scott Fujimoto (McGill University) · David Meger (McGill University) · Doina Precup (McGill University / DeepMind)
[136]. Multi-Agent Training beyond Zero-Sum with Correlated Equilibrium Meta-Solvers
作者: Luke Marris (DeepMind) · Paul Muller (DeepMind) · Marc Lanctot (DeepMind) · Karl Tuyls (DeepMind) · Thore Graepel (DeepMind)
[137]. PC-MLP: Model-based Reinforcement Learning with Policy Cover Guided Exploration
作者: Yuda Song (University of California, San Diego) · Wen Sun (Cornell University)
[138]. Characterizing the Gap Between Actor-Critic and Policy Gradient
作者: Junfeng Wen (University of Alberta) · Saurabh Kumar (Stanford) · Ramki Gummadi (Google Brain) · Dale Schuurmans (University of Alberta)
[139]. Coach-Player Multi-agent Reinforcement Learning for Dynamic Team Composition
作者: Bo Liu (University of Texas, Austin) · Qiang Liu (UT Austin) · Peter Stone (University of Texas at Austin) · Animesh Garg (University of Toronto, Vector Institute, Nvidia) · Yuke Zhu (University of Texas - Austin) · Anima Anandkumar (California Institute of Technology)
[140]. Spectral Normalisation for Deep Reinforcement Learning: An Optimisation Perspective
作者: Florin Gogianu (Bitdefender) · Tudor Berariu (Imperial College London) · Mihaela Rosca (DeepMind) · Claudia Clopath (Imperial College London) · Lucian Busoniu (Technical University of Cluj-Napoca) · Razvan Pascanu (DeepMind)
[141]. Actionable Models: Unsupervised Offline Reinforcement Learning of Robotic Skills
作者: Yevgen Chebotar (Google) · Karol Hausman (Google Brain) · Yao Lu (Google Research) · Ted Xiao (Google) · Dmitry Kalashnikov (Google Inc.) · Jacob Varley (Google) · Alexander Irpan (Google) · Benjamin Eysenbach (CMU, Google Brain) · Ryan Julian (Google) · Chelsea Finn (Google Brain) · Sergey Levine (Google)
[142]. When is Pessimism Warranted in Batch Policy Optimization?
作者: Chenjun Xiao (Google / University of Alberta) · Yifan Wu (Carnegie Mellon University) · Jincheng Mei (University of Alberta / Google Brain) · Bo Dai (Google Brain) · Tor Lattimore (DeepMind) · Lihong Li (Google Research) · Csaba Szepesvari (DeepMind/University of Alberta) · Dale Schuurmans (Google / University of Alberta)
[143]. Beyond Variance Reduction: Understanding the True Impact of Baselines on Policy Optimization
作者: Wesley Chung (Mila / McGill University) · Valentin Thomas (MILA) · Marlos C. Machado (Google Brain) · Nicolas Le Roux (Google)
[144]. Towards Tight Bounds on the Sample Complexity of Average-reward MDPs
作者: Yujia Jin (Stanford University) · Aaron Sidford (Stanford)
[145]. Posterior Value Functions: Hindsight Baselines for Policy Gradient Methods
作者: Chris Nota (University of Massachusetts Amherst) · Philip Thomas (University of Massachusetts Amherst) · Bruno C. da Silva (University of Massachusetts)
[146]. Counterfactual Credit Assignment in Model-Free Reinforcement Learning
作者: Thomas Mesnard (DeepMind) · Theophane Weber (DeepMind) · Fabio Viola (DeepMind) · Shantanu Thakoor (DeepMind) · Alaa Saade (DeepMind) · Anna Harutyunyan (DeepMind) · Will Dabney (DeepMind) · Thomas Stepleton (DeepMind) · Nicolas Heess (DeepMind) · Arthur Guez (Google DeepMind) · Eric Moulines (Ecole Polytechnique) · Marcus Hutter (DeepMind) · Lars Buesing (Deepmind) · Remi Munos (DeepMind)
[147]. Randomized Exploration in Reinforcement Learning with General Value Function Approximation
作者: Haque Ishfaq (MILA / McGill University) · Qiwen Cui (Peking University) · Alex Ayoub (University of Alberta) · Viet Nguyen (McGill, Mila) · Zhuoran Yang (Princeton University) · Zhaoran Wang (Northwestern U) · Doina Precup (McGill University / DeepMind) · Lin Yang (UCLA)
[148]. Structured World Belief for Reinforcement Learning in POMDP
作者: Gautam Singh (Rutgers University) · Skand Peri (Rutgers University, New Jersey) · Junghyun Kim (Rutgers University) · Hyunseok Kim (Electronics and Telecommunications Research Institute (ETRI), Korea) · Sungjin Ahn (Rutgers University)
[149]. EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL
作者: Seyed Kamyar Seyed Ghasemipour (University of Toronto) · Dale Schuurmans (Google / University of Alberta) · Shixiang Gu (Google)
[150]. Policy Gradient Bayesian Robust Optimization for Imitation Learning
作者: Daniel Brown (University of Texas at Austin) · Ashwin Balakrishna (University of California, Berkeley) · Zaynah Javed (UC Berkeley) · Satvik Sharma (UC Berkeley) · Jerry Zhu (UC Berkeley) · Marek Petrik (University of New Hampshire) · Anca Dragan (University of California, Berkeley) · Ken Goldberg (UC Berkeley)
[151]. Reinforcement Learning of Implicit and Explicit Control Flow Instructions
作者: Ethan Brooks (University of Michigan) · Janarthanan Rajendran (University of Michigan) · Richard Lewis (University of Michigan) · Satinder Singh (University of Michigan)
[152]. SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II
作者: Xiangjun Wang (inspir.ai) · Junxiao SONG (inspir.ai) · Penghui Qi (InspirAI) · Peng Peng (inspir.ai) · Zhenkun Tang (inspir.ai) · Wei Zhang (inspir.ai) · Weimin Li (inspir.ai) · Xiongjun Pi (inspir.ai) · Jujie He (inspir.ai) · Chao Gao (inspir.ai) · Haitao Long (inspir.ai) · Quan Yuan (inspir.ai)
[153]. Reinforcement Learning Under Moral Uncertainty
作者: Adrien Ecoffet (OpenAI) · Joel Lehman ()
[154]. Locally Persistent Exploration in Continuous Control Tasks with Sparse Rewards
作者: Susan Amin (McGill University) · Maziar Gomrokchi (McGill University) · Hossein Aboutalebi (University of Waterloo) · Harsh Satija (McGill University) · Doina Precup (McGill University / DeepMind)
[155]. Conservative Objective Models for Effective Offline Model-Based Optimization
作者: Brandon L Trabucco (UC Berkeley) · Aviral Kumar (UC Berkeley) · Xinyang Geng (UC Berkeley) · Sergey Levine (UC Berkeley)
[156]. State Relevance for Off-Policy Evaluation
作者: Simon Shen (Harvard University) · Yecheng Ma (University of Pennsylvania) · Omer Gottesman (Harvard University) · Finale Doshi-Velez (Harvard University)
[157]. Failure Modes and Opportunities in Out-of-distribution Detection with Deep Generative Models
作者: Lily Zhang (New York University) · Mark Goldstein (New York University) · Rajesh Ranganath (New York University)
[158]. Temporal Predictive Coding For Model-Based Planning In Latent Space
作者: Tung Nguyen (VinAI Research, Vietnam) · Rui Shu (Stanford University) · Tuan Pham (VinAI Research) · Hung Bui (VinAI Research) · Stefano Ermon (Stanford University)
[159]. Learning Fair Policies in Decentralized Cooperative Multi-Agent Reinforcement Learning
作者: Matthieu Zimmer (Shanghai Jiao Tong University) · Claire Glanois (Shanghai Jiao Tong University) · Umer Siddique (Shanghai Jiao Tong University) · Paul Weng (Shanghai Jiao Tong University)
[160]. FOP: Factorizing Optimal Joint Policy of Maximum-Entropy Multi-Agent Reinforcement Learning
作者: Tianhao Zhang (Peking University) · yueheng li (Peking university) · Chen Wang (Peking University) · Zongqing Lu (Peking University) · Guangming Xie (1. State Key Laboratory for Turbulence and Complex Systems, College of Engineering, Peking University; 2. Institute of Ocean Research, Peking University)
[161]. Provably Efficient Fictitious Play Policy Optimization for Zero-Sum Markov Games with Structured Transitions
作者: Shuang Qiu (University of Michigan) · Zhuoran Yang (Princeton University) · Xiaohan Wei (Facebook) · Jieping Ye (University of Michigan) · Zhaoran Wang (Northwestern U)
[162]. On Reward-Free RL with Kernel and Neural Function Approximations: Single-Agent MDP and Markov Game
作者: Shuang Qiu (University of Michigan) · Zhuoran Yang (Princeton University) · Jieping Ye (University of Michigan) · Zhaoran Wang (Northwestern U)
[163]. Nonparametric Hamiltonian Monte Carlo
作者: Carol Mak (University of Oxford) · Fabian Zaiser (University of Oxford) · Luke Ong (University of Oxford)
更多请访问论坛(点击阅读原文)
http://deeprl.neurondance.com/d/305-163icml-202120210607
完
总结1:周志华 || AI领域如何做研究-写高水平论文
总结2:全网首发最全深度强化学习资料(永更)
总结3: 《强化学习导论》代码/习题答案大全
总结4:30+个必知的《人工智能》会议清单
总结5:2019年-57篇深度强化学习文章汇总
总结6: 万字总结 || 强化学习之路
总结7:万字总结 || 多智能体强化学习(MARL)大总结
总结8:深度强化学习理论、模型及编码调参技巧
完
第106篇:奖励机制不合理:内卷,如何解决?
第105篇:FinRL: 一个量化金融自动交易RL库
第104篇:RPG: 通过奖励发现多智能体多样性策略
第103篇:解决MAPPO(Multi-Agent PPO)技巧
第102篇:82篇AAAI2021强化学习论文接收列表
第101篇:OpenAI科学家提出全新强化学习算法
第100篇:Alchemy: 元强化学习(meta-RL)基准环境
第99篇:NeoRL:接近真实世界的离线强化学习基准
第98篇:全面总结(值函数与优势函数)的估计方法
第97篇:MuZero算法过程详细解读
第96篇: 值分布强化学习(Distributional RL)总结
第95篇:如何提高"强化学习算法模型"的泛化能力?
第94篇:多智能体强化学习《星际争霸II》研究
第93篇:MuZero在Atari基准上取得了新SOTA效果
第92篇:谷歌AI掌门人Jeff Dean获冯诺依曼奖
第91篇:详解用TD3算法通关BipedalWalker环境
第90篇:Top-K Off-Policy RL论文复现
第89篇:腾讯开源分布式多智能TLeague框架
第88篇:分层强化学习(HRL)全面总结
第87篇:165篇CoRL2020 accept论文汇总
第86篇:287篇ICLR2021深度强化学习论文汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第82篇:强化学习需要批归一化(Batch Norm)吗?
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第78篇:强化学习如何tradeoff"探索"和"利用"?
第77篇:深度强化学习工程师/研究员面试指南
第76篇:DAI2020 自动驾驶挑战赛(强化学习)
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第69篇:深度强化学习【Seaborn】绘图方法
第68篇:【DeepMind】多智能体学习231页PPT
第67篇:126篇ICML2020会议"强化学习"论文汇总
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第63篇:华为诺亚方舟招聘 || 强化学习研究实习生
第62篇:ICLR2020- 106篇深度强化学习顶会论文
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第60篇:滴滴主办强化学习挑战赛:KDD Cup-2020
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第56篇:RL教父Sutton实现强人工智能算法的难易
第55篇:内推 || 阿里2020年强化学习实习生招聘
第54篇:顶会 || 65篇"IJCAI"深度强化学习论文
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第46篇:DQN系列(2): Double DQN 算法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第43篇:起死回生|| 如何rebuttal顶会学术论文?
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第38篇:AAAI-2020 || 52篇深度强化学习论文
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第33篇:DeepMind-102页深度强化学习PPT
第32篇:腾讯AI Lab强化学习招聘(正式/实习)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第18篇:"DeepRacer" —顶级深度强化学习挑战赛
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第14篇:61篇NIPS2019DeepRL论文及部分解读
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第12篇:模块化和快速原型设计Huskarl DRL框架
第11篇:DRL在Unity自行车环境中配置与实践
第10篇:解读72篇DeepMind深度强化学习论文
第9篇:《AutoML》:一份自动化调参的指导
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第7篇:10年NIPS顶会DRL论文(100多篇)汇总
第6篇:ICML2019-深度强化学习文章汇总
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第3篇:“超参数”自动化设置方法---DeepHyper
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
