目录
前言
Work queues工作模式介绍
消息模型
适用场景
消费策略(重要)
消费策略选择
消费策略代码示例
轮询分发
(1)定义生产者和消费者
(2)运行程序
(3)结果分析
公平分发
(1)定义生产者和消费者
(2)运行程序
(3)结果分析
总结
前言
将‘work queues工作队列模式’单独抽出来细讲,目的是借助这个模式好好讲一下rabbitmq的‘轮询分发’和‘公平分配’。
Work queues工作模式介绍
rabbitmq六大工作模式架构图:

消息模型
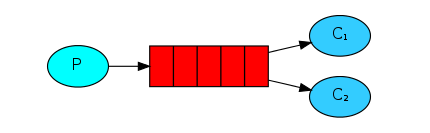
1、竞争式消费消息。与‘广播模式’区分开,同一个队列中的消息只能被一个消费者进行消费。该消息模型有一个生产者和 多个消费者,多个消费者可以 同时消费 同一个队列消息;
- 比如生产者可将5000条数据放到「队列 」中,然后可以启动5个消费者,在默认策略下(默认是轮询分发消息),平均每个消费者消费1000条来分担压力;
2、如何让程序有 多个消费者同时消费同一个队列消息呢?
- 在程序中,自己手动创建多个消费者;(我个人认为除了写测试case,在实际生产中应该没有人这么干);
- 实际生产中,集群部署程序;那么一台机器就有一个消费者,多台机器就有多个消费者;
- rabbitmq中,提供了一个参数,可以配置 一台机器 消费者实例个数;
适用场景
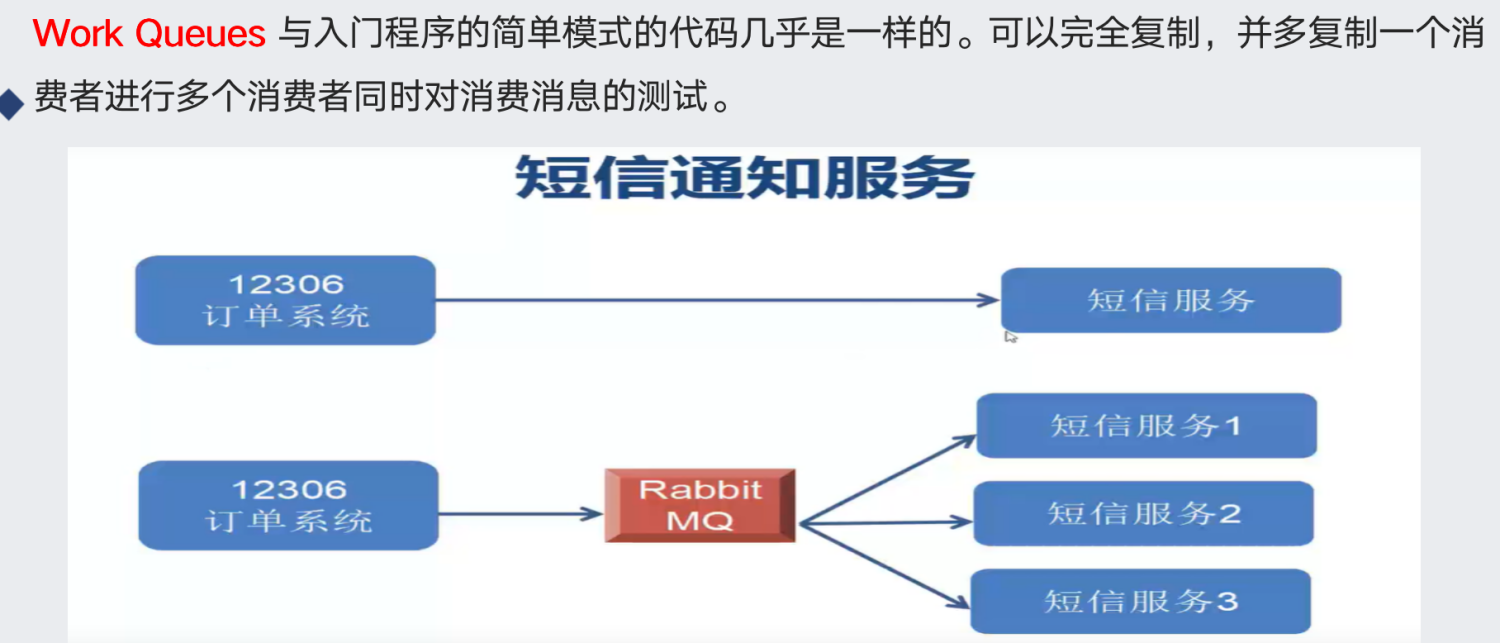
Work Queues 对于任务过重或任务较多情况使用工作队列可以提高任务处理的速度。
例如:短信服务部署多个,只需要有一个节点成功发送即可。
消费策略(重要)
这个消息模型对应着前面说过的轮寻分发 和公平分发, 默认是轮训分发。
1、轮询分发(自动ack)-不推荐
- 轮询分发采用 自动ack机制;
-
默认是轮询分发(即平均分发消息给消费者不考虑消费者的性能差异 和处理消息的能力);
-
不推荐使用轮询分发,因为轮询分发不考虑消费者性能差异,追求 平均分配;
2、公平分发(手动ack)-推荐
消费策略选择
轮询模式下,Work Queue是将生产者生产的消息一次性平均分配给消费者,当分配完消息后,它的自动确认机制会一次性全部确认,在官方文档中有这么一段解释:
Message acknowledgment
Doing a task can take a few seconds. You may wonder what happens if one of the consumers starts a long task and dies with it only partly done. With our current code once RabbitMQ delivers message to the consumer it immediately marks it for deletion. In this case, if you kill a worker we will lose the message it was just processing. We’ll also lose all the messages that were dispatched to this particular worker but were not yet handled.
But we don’t want to lose any tasks. If a worker dies, we’d like the task to be delivered to another worker.
当生产者生产了10个消息,2个消费者平均分到了5个消息,当消费者一消费完3个消息时不明原因宕机了,剩余的2个消息则会丢失,而我们希望由其他的消费者来对这些剩余的消息消费,要是在业务中出现消息丢失可能会造成很严重的后果,所以官方不推荐使用自动消息确认。下面我们通过代码的形式,分别来测试轮询分发(自动签收消息)和 公平分配(手动消息确认)。
消费策略代码示例
基于maven采用java原生写法。不需要写properties或者yml配置文件:
pom依赖:
<dependencies>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
</dependencies>
rabbitutils工具类:
package com.baiqi.rabbitmq.utils;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class RabbitUtils {
private static ConnectionFactory connectionFactory = new ConnectionFactory();
static {
connectionFactory.setHost("127.0.0.1");
//5672是RabbitMQ的默认端口号
connectionFactory.setPort(5672);
connectionFactory.setUsername("cms");
connectionFactory.setPassword("cms");
//相当于表
connectionFactory.setVirtualHost("/cms_vm");
}
public static Connection getConnection(){
Connection conn = null;
try {
// TCP的长连接
conn = connectionFactory.newConnection();
return conn;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
轮询分发
(1)定义生产者和消费者
生产者:
public class Provider {
@Test
public void test() throws IOException, InterruptedException {
Connection connection = RabbitMqUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("work",true,false,false,null);
for(int i=0;i<10;i++){
channel.basicPublish("","work", MessageProperties.PERSISTENT_TEXT_PLAIN,(i+1+": hello workqueues").getBytes());
}
RabbitMqUtil.close(channel,connection);
}
}
消费者1:
public class Customer1 {
public static void main(String[] args) throws IOException {
Connection connection = RabbitMqUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("work",true,false,false,null);
channel.basicConsume("work",true,new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("Customer1消费消息:"+new String(body));
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
消费者2:
public class Customer2 {
public static void main(String[] args) throws IOException {
Connection connection = RabbitMqUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("work",true,false,false,null);
channel.basicConsume("work",true,new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("Customer2消费消息:"+new String(body));
}
});
}
}
(2)运行程序
先对两个消费者进行开启,进入异步监听模式,然后让生产者生产10条消息,将消费者一线程休眠2秒,模拟该业务慢的情况。
消费者1:

消费者2:
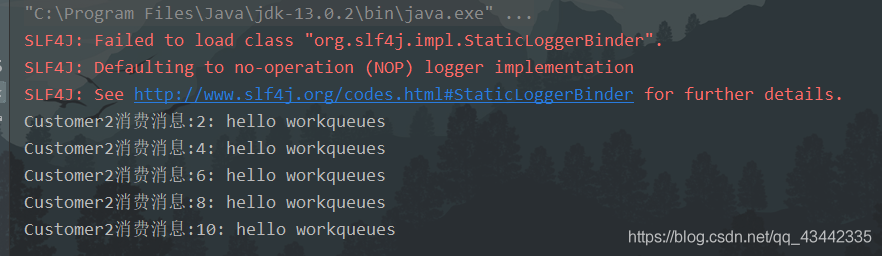
(3)结果分析
无论是否当某个消费者处理缓慢时,还是一样地平均消费。
刚才的实现有以下问题:
-
消费者1比消费者2的效率要低,一次任务的耗时较长
-
然而两人最终消费的消息数量是一样的
-
消费者2大量时间处于空闲状态,消费者1一直忙碌
现在的状态属于是把任务平均分配,正确的做法应该是消费越快的人,消费的越多。
怎么实现呢?
通过 BasicQos 方法设置prefetchCount = 1。这样RabbitMQ就会使得每个Consumer在同一个时间点最多处理1个Message。换句话说,在接收到该Consumer的ack前,他它不会将新的Message分发给它。相反,它会将其分派给不是仍然忙碌的下一个Consumer。
值得注意的是:prefetchCount在手动ack的情况下才生效,自动ack不生效。
公平分发
(1)定义生产者和消费者
生产者:
public class Provider {
@Test
public void test() throws IOException, InterruptedException {
Connection connection = RabbitMqUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("work",true,false,false,null);
for(int i=0;i<10;i++){
channel.basicPublish("","work", MessageProperties.PERSISTENT_TEXT_PLAIN,(i+1+": hello workqueues").getBytes());
}
RabbitMqUtil.close(channel,connection);
}
}
消费者1:
public class Customer1 {
public static void main(String[] args) throws IOException {
Connection connection = RabbitMqUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("work",true,false,false,null);
//每次只确认一条消息
channel.basicQos(1);
channel.basicConsume("work",false,new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("Customer1消费消息:"+new String(body));
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
channel.basicAck(envelope.getDeliveryTag(),false);
}
});
}
}
消费者一通过线程进行了2秒的休眠,模拟处理业务慢的情况。
消费者2:
public class Customer2 {
public static void main(String[] args) throws IOException {
Connection connection = RabbitMqUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("work",true,false,false,null);
channel.basicQos(1);
channel.basicConsume("work",false,new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("Customer2消费消息:"+new String(body));
channel.basicAck(envelope.getDeliveryTag(),false);
}
});
}
}
这里我们通过basicQos()设置了每次拉取一条消息;
消息被消费完后通过basicAck()手动确认,第一个参数为消息的标识,用来标识信道中投递的消息,RabbitMQ 推送消息给消费者时,会附带一个 Delivery Tag,以便 消费者可以在消息确认时告诉RabbitMQ到底是哪条消息被确认了;第二个参数为是否多消息确认;
当某个消费者宕机了,也不会丢失消息,剩余的则分担到其他的消费者身上,这样的设置可以防止消息的丢失,保证了数据的完整性。
(2)运行程序
消费者1:
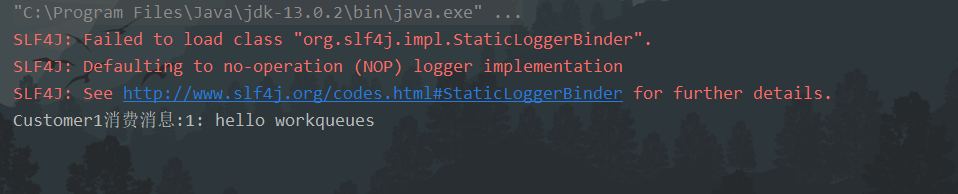
消费者2:

(3)结果分析
体现了能者多劳,处理效率快的消费者可以处理较多的消息;
并且,如果当消费者1宕机了(其实宕机也可以认为是处理效率慢的一种,只不过有点极端),其余的消息也可以被消费者2消费;
总结
work queues是竞争式消费;
消费策略:轮询分发、公平分发;前者是自动ack,后者是手动ack。
prefetchCount在手动ack的情况下才生效,自动ack不生效。