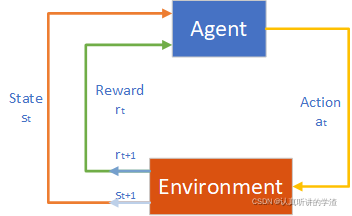
根据维基百科对强化学习的定义:Reinforcement learning (RL) is an area of machine learning inspired by behaviorist psychology, concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward. (强化学习是机器学习领域之一,受到行为心理学的启发,主要关注智能体如何在环境中采取不同的行动,以最大限度地提高累积奖励。)
状态集合:
S
=
{
s
1
,
s
2
,
s
3
,
…
,
s
m
}
S =\lbrace s_1,s_2,s_3,\text{\textellipsis},s_m \rbrace
S={s1,s2,s3,…,sm} 为了区分表述:
s
i
,
i
=
1
,
2
,
3
,
…
,
m
s_i,i=1,2,3,\text{\textellipsis},m
si,i=1,2,3,…,m(这里的
s
i
s_i
si指的是状态集合中任意一个状态)
s
t
,
t
=
1
,
2
,
3
,
…
,
T
s_t,t=1,2,3,\text{\textellipsis},T
st,t=1,2,3,…,T(这里的
t
t
t指的时间序列,
s
t
s_t
st指的是
t
t
t时刻的状态)
动作集合:
A
=
{
a
1
,
a
2
,
a
3
,
…
,
a
n
}
A =\lbrace a_1,a_2,a_3,\text{\textellipsis},a_n \rbrace
A={a1,a2,a3,…,an} 表述方式同上
(
A
∣
s
i
)
(A|s_i)
(A∣si)表示状态
s
i
s_i
si下所有合法的动作
a
a
a的集合
状态转移概率:
P
s
a
(
s
′
)
Psa(s\\')
Psa(s′),状态在
s
s
s下采取动作
a
a
a,状态转移到
s
′
s\\'
s′的概率
P
s
a
:
S
∗
A
∗
S
→
[
0
,
1
]
Psa:S*A*S\rightarrow[0,1]
Psa:S∗A∗S→[0,1]
奖励函数:
R
s
a
:
S
∗
A
→
R
(
实数
)
Rsa:S*A\rightarrow R(实数)
Rsa:S∗A→R(实数),
R
s
a
(
s
,
a
)
Rsa(s,a)
Rsa(s,a)在状态
s
s
s下执行动作
a
a
a得到的奖励
R
s
a
s
:
S
∗
A
∗
S
→
R
(
实数
)
Rsas:S*A*S\rightarrow R(实数)
Rsas:S∗A∗S→R(实数),
R
s
a
s
(
s
,
a
,
s
′
)
Rsas(s,a,s\\')
Rsas(s,a,s′)在状态
s
s
s下执行动作
a
a
a转移到状态
s
′
s\\'
s′时得到的奖励
策略函数:
π
:
S
∗
A
→
[
0
,
1
]
\pi:S*A\rightarrow[0,1]
π:S∗A→[0,1],
π
(
a
∣
s
)
\pi(a|s)
π(a∣s):在状态
s
s
s的前提下,执行动作
a
a
a的概率
π
(
a
∣
s
)
=
{
1
或
0
确定性策略
[
0
,
1
]
随机性策略
\pi(a|s)=\begin{cases} 1 或 0 &\text{确定性策略 } \\ [0,1] &\text{随机性策略} \end{cases}
π(a∣s)={1或0[0,1]确定性策略随机性策略
马尔科夫决策过程可以用一个五元组来表示:
M
D
P
(
S
,
A
,
P
s
a
,
R
s
a
,
γ
)
MDP(S,A,Psa,Rsa,\gamma)
MDP(S,A,Psa,Rsa,γ)
3.MDP的基本流程
产生一个状态-动作-奖励序列:
s
0
,
a
0
,
r
1
→
s
1
,
a
1
,
r
2
→
s
2
,
a
2
,
r
3
→
s
3
,
a
3
,
r
4
…
s
t
,
a
t
,
r
t
+
1
→
…
s
T
−
1
,
a
T
−
1
,
r
T
→
s
T
(
终止状态
)
s_0,a_0,r_1 \rightarrow s_1,a_1,r_2 \rightarrow s_2,a_2,r_3 \rightarrow s_3,a_3,r_4 \dots s_t,a_t,r_{t+1}\rightarrow\dots s_{T-1},a_{T-1},r_T\rightarrow s_T(终止状态)
s0,a0,r1→s1,a1,r2→s2,a2,r3→s3,a3,r4…st,at,rt+1→…sT−1,aT−1,rT→sT(终止状态) 当我们要解决的问题符合马尔科夫假设(状态的转移只与上一步执行的动作有关),那么强化学习的训练过程就可以用MDP决策过程来表述,一次完整的训练过程就可以形成一个完整的MDP序列(达到终止状态)。 策略就是从大量的完整MDP序列中学习(优化)到的 在这里我们重新回到强化学习的目标:自动寻找在连续时间序列里的最优策略,这里的最优策略通常指使得长期累计奖励最大化的策略。换句话说,策略是由长期累计奖励来判断好坏的。 累计奖励(Total Payoff):
G
t
=
r
t
+
1
+
γ
r
t
+
2
+
γ
2
r
r
+
3
+
⋯
+
γ
T
−
t
−
1
r
T
G_t=r_{t+1}+\gamma r_{t+2}+\mathop{\gamma}^2r_{r+3}+\dots+\mathop{\gamma}^{T-t-1}r_T
Gt=rt+1+γrt+2+γ2rr+3+⋯+γT−t−1rT
现在我们可以简单理解MDP流程:先初始化策略函数,一般是随机生成
π
0
\pi_0
π0,并且随机初始状态
s
0
s_0
s0,通过
π
0
\pi_0
π0来选择相应的动作
a
0
a_0
a0,这样不断执行得到一条完整的马尔科夫链(
s
0
,
a
0
,
r
1
→
s
1
,
a
1
,
r
2
→
s
2
,
a
2
,
r
3
→
s
3
,
a
3
,
r
4
…
s
t
,
a
t
,
r
t
+
1
→
…
s
T
−
1
,
a
T
−
1
,
r
T
→
s
T
(
终止状态
)
s_0,a_0,r_1 \rightarrow s_1,a_1,r_2 \rightarrow s_2,a_2,r_3 \rightarrow s_3,a_3,r_4 \dots s_t,a_t,r_{t+1}\rightarrow\dots s_{T-1},a_{T-1},r_T\rightarrow s_T(终止状态)
s0,a0,r1→s1,a1,r2→s2,a2,r3→s3,a3,r4…st,at,rt+1→…sT−1,aT−1,rT→sT(终止状态))通过这个序列我们就可以计算出在状态
s
0
s_0
s0下选择动作
a
0
a_0
a0转移到
s
1
s_1
s1这个策略产生的累计奖励
G
G
G,通过这个G就可以评价这个策略的好坏,然后更新策略,至于具体如何评价策略,如何更新策略,在下一篇博客继续。
四、基于模型和免模型的强化学习
1.模型
模型是指对环境建模,具体指状态转移概率函数和奖励函数
2.基于模型的强化学习(Model-Based)
智能体知道在任何状态下执行任何动作所获得的回报,即
R
(
s
,
a
)
R(s,a)
R(s,a)已知。可以直接使用动态规划法来求解最优策略,这种采取对环境进行建模的强化学习方法就是Model-Based强化学习。 若奖励函数和状态转移函数未知,我们就可以用特定的方法(比如神经网络或者物理机理)对它们进行模拟建模。