The content comes from teacher courseware.
第一章 信息系统与java企业级规范
一、信息系统的类型
1.单机系统
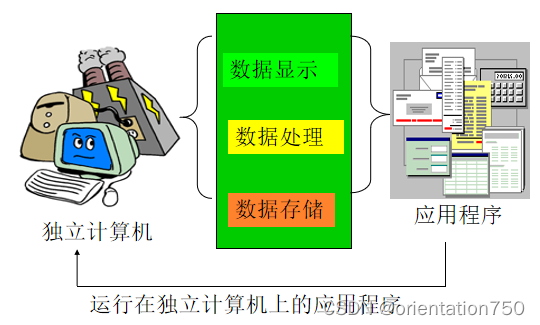
单机系统的特点:
- 数据显示、数据处理、数据存储在同一台计算机上进行
- 数据显示一般为图形界面
- 数据处理和数据显示往往在同一应用程序中进行
- 数据存储方式:
- 应用程序自行处理(文件形式)
- 采用数据库管理系统(DBMS) 应用系统在使用前需要利用独立的安装程序进行安装
单机系统应用的优点:
- 系统安装与部署 相对简单
- 程序设计技术涉及的知识领域少,易于专业人员的学习
- 应用系统的设计工具比较完善,可将复杂的底层工作交给工具去做
- 由于系统在单个计算机上运行,所以不容易受到网络环境问题的影响,如网络安全问题、保密问题
单机系统应用的缺点:
- 系统升级困难
- 用户需为系统升级支付不必要的升级费用
- 由于数据的显示、数据的处理在同一应用程序中,一但数据的处理发生改变,开发人员需对整个系统进行修改
- 每一次升级都要重新安装应用系统
- 不能跨平台
- 由于数据显示和数据处理在同一应用程序中,用户必须在不同的平台下使用不同版本的程序
- 难于信息共享
- 数据显示、数据处理及数据存储在同一台计算机上进行,不能做到数据的实时共享
2.客户机-服务器应用系统(Client-Server)
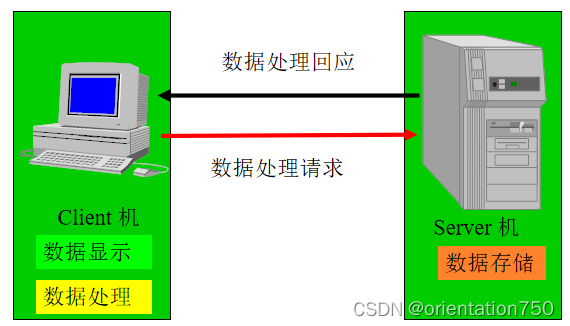
C/S系统特点:
- 数据显示、数据处理、数据存储在不同的计算机上进行
- 应用系统分成两个部分:客户机和服务器
- 客户机主要负责数据的显示及数据的处理,数据显示一般为图形界面
- 服务器主要负责数据的存储,一般用网络数据库系统进行数据的存储
- 客户机与服务器相互通信一般采用专用的通信协议,如Socket、DCOM、CORBA、RMI
C/S系统的优点:
- 用户可通过多台客户机,访问同一台数据存储服务器,实现了信息共享
- 用户可通过网络在客户端对服务器端的数据进行修改,实现了数据的远程控制,便于用户对系统进行管理
- 数据的显示、处理和数据的存储相分离,有利于系统功能的合理划分,可实现服务器端或客户端软件的单独升级
- 客户机与服务器可安装不同的操作系统,可实现跨平台的访问
C/S系统的缺点:
- 系统安装及部署较为复杂
- 用户要访问系统,必须安装在客户上安装相应的客户端软件
- 数据的显示和数据的处理没有分离,一但数据处理的流程或方式发生改变,整个客户端软件都要重新改写。在大用户量的情况下,客户端软件的更新比较困难
- 在大量客户端同时访问服务器的情况下,服务器的数据库将产生大量的数据库连接,服务器端缺乏负载平衡的手段
3.多层应用系统
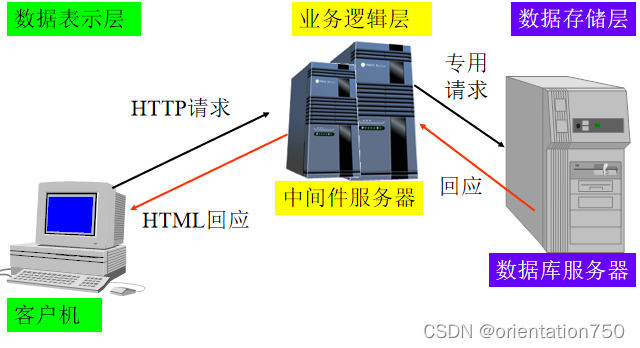
多层应用系统特点:
- 将系统分为数据表示层、业务逻辑层、数据存储层
- 客户端一般只负责数据的显示,且绝大多数系统采用浏览器(Browser)进行数据的显示
- 中间件服务器负责数据的处理,一般分成WEB服务器和应用程序服务器两部分:
- WEB服务器用来和浏览器之间进行交互,并将相应的用户请求转交给应用程序服务器
- 应用程序服务器对数据进行处理,再将处理过后的数据交给数据库服务器
- 数据库服务器负责数据的存储
多层应用系统的优点:
- 系统的各个部分可独立升级
- 客户端“零配置”
- 大都采用浏览器作为客户端,目前的操作系统都内置了浏览器,所以用户在访问系统时就无需安装其他软件
- 数据处理的流程或方式改变时,不用更新客户端软件
- 中间件可对用户的访问进行智能“调配”,实现负载平衡,适用于大用户系统(可支持上万人的同时访问)
- 客户端、中间件、数据库可采用不同的平台,不同的开发工具
- 可对系统的安全进行配置,使不同的用户具有不同的访问权限, 使企业能够真正面向互联网进行商务活动
- 便于系统的扩展,并且可以通过应用程序服务器将企业原有的MIS系统包含进来
多层应用系统的缺点:
- 对开发人员要求高
- 浏览器的界面设计技能及编程技术
- WEB服务器编程技术
- 应用程序服务器编程技术
- 跨平台的系统间相互通信
- 不同平台上的系统整合
- 系统安装及部署较为复杂
- 系统的初期投入高
- 商业化的应用服务器软件价格昂贵
- 需要增加比两层(C/S)结构更多的硬件
- 系统维护的成本较高
4.微服务系统
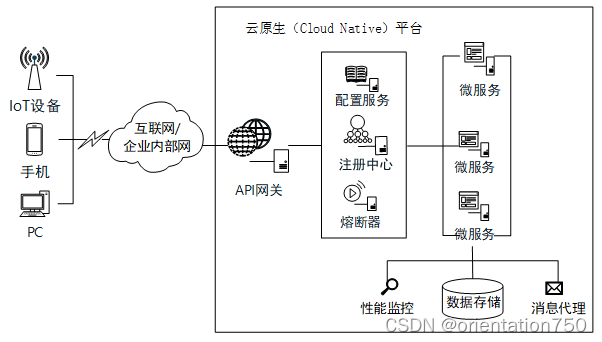
微服务系统的优点:
- 原应用程序服务器中执行的业务数据处理部分进一步分割为粒度更小,独立运行的子系统,区别于多层系统架构的单体架构(Monolithic Architecture)
- 提供了对这些独立运行的子系统的整体管理机制的平台被称为“云原生”(Cloud Native)平台
- 微服务注册与发现
- 故障管理
- 配置管理
- 资源调配管理
- 具有不间断的服务提供能力,即CI/CD特性(Continuous Integration/ Continuous Delivery,持续集成和发布)
微服务系统的缺点:
- 进一步的服务化分割提升了整个系统开发和运维的复杂度
- 将服务分布到更多的不同的计算机上增加了系统部署的成本。
- 不同的微服务之间相互调用不可避免带来了额外的网络访问和系统对接开销,使得微服务的整体执行效率相对于单体结构有所降低。
- 微服务运行所需的云原生平台对操作系统有着一定的要求,这使得企业原有的一些系统在进行微服务改造时存在着迁移困难。
5.小结
- 在当前的互联网环境下,多层应用系统、微服务已经成为企业在建设信息系统时的主要选择,它可以满足企业在面临互联网用户访问时的系统建设需求,有利于系统的扩充升级,保护已有投资,并且便于划分用户,以实现企业业务的安全方面的需求。
- 多层应用和微服务系统并不排斥单机及两层(C/S)应用系统。多层应用系统中许多功能是依靠两层或单机系统来完成的,这几种系统是相辅相成的。
二、Java对多层系统的支持
1、Java的跨平台特性提供了对多层系统的天然支持
- 由于多层系统中数据表示层、业务逻辑层、数据存储层可以构建在不同的平台上,而Java可以运行在不同的平台上,从而使得Java成为构建多层系统的理想语言
2、Java的稳定性有利于多层系统的关键业务的实现
- Java语言消除了容易出错的指针,并且对系统的内存进行自动回收,这使得语言本身具有较强的鲁棒性(Robust),而企业的关键业务要求系统提供7 Χ 24小时的不间断服务,Java语言可以提供这种需求。
3、Java为多层系统提供了标准化的支持
- 为了满足企业对多层系统的构建需求,相关国际标准化组织提供了Java企业平台标准(JavaEE,简称为JEE,以前也称J2EE),将多层系统的结构标准化,为企业系统的构建提供了可供参考的模型。
- JavaEE标准由Java社区标准化组织JCP负责制定,由一系列的JSR子标准组成。随着云计算技术的发展和演进,JavaEE在8.0之后的版本被重新命名为JakartaEE,控制权由JCP移交给了Eclipse开源组织,将侧重于发展在云计算技术中Java的应用。
(1)JavaEE(J2EE)系统结构图

(2)JavaEE中的客户端表示层
- 胖客户 :胖客户是指在客户端需要安装的图形界面应用程序,在JavaEE中,胖客户可以是以下两种:
- Java应用程序 在JavaEE中,此种应用程序类型较少,主要原因是JAVA的图形界面运行较为缓慢
- 非Java的图形界面应用程序 此种应用程序目前较多,主要用于和企业的应用服务器通信,向用户提供操作界面
- 瘦客户 :瘦客户是指无须安装特定的客户端程序就可以使用该系统提供的服务,这种瘦客户程序一般采用浏览器。
- HTML客户 :一般是由Servlet/JSP在WEB服务端生成相应网页,传送给浏览器进行显示,多应用于企业内部网及互联网。
- Applet客户 :Applet客户运行在浏览器中,可利用Java的AWT或Swing提供图形用户界面。但由于Applet需要JAVA虚拟机支持,并且客户端下载量较大,所以Applet较少应用互联网。
(3)JavaEE中服务器端表示层
- Servlet :运行在WEB服务端的小程序,可控制WEB应用程序的执行流程,响应用户的请求,执行相应的业务逻辑,依据用户的需求动态生成所需的HTML文件。
- JSP: 是简化的Servlet程序,主要用于生成在浏览器端显示的HTML文件。
(4)JavaEE中的业务逻辑层
- 所谓业务逻辑主要是指数据处理过程,主要包括:
- JavaBeans
- 相对独立的Java功能模块,相当于Windows系统提供的控件,可用于执行一些的业务逻辑,如购物车中商品信息的存储、和数据库进行连接等任务,在JavaBeans中还可以对EJB进行调用,以完成更为复杂的应用。
- Enterprise JavaBeans(EJB)
- EJB是JAVA企业级应用的重要组成部分,可应用于企业的关键业务,如客户的订单处理、系统的安全保证、与银行联网业务,是一种可以支持分布式系统的组件模型。
(5)JavaEE中的数据存储层
- 一般采用关系数据库(RDBMS),如ORACLE、DB2、SQL Server、Sybase
(6)JavaEE中的应用程序部署
- 部署(Deployment)是指将开发完成后的应用程序通过特定的方式拷贝到最终用户使用所需的相关计算机中,并保证应用程序能够正常执行的过程。
- 在多层系统架构中,应用程序部署通常涉及到客户端、中间件及数据存储端等多台计算机的文件拷贝和配置工作。为了便于系统管理人员部署多层系统,JavaEE规范定义了多层系统的功能模块,模块中即包含有应用程序的二进制运行代码,也包括说明这些模块的运行和配置信息,用于简化应用系统的部署过程。
(7)JavaEE中的部署功能模块
- JavaEE规范中多层系统的部署功能模块主要包括:
- WEB模块
- 主要包括JSP/Servlet,在部署时通常被打包成一个扩展名为.WAR的文件(WAR是Web Application Archive的简写,采用ZIP压缩算法打包)。
- EJB模块
- 主要包括EJB等业务逻辑组件,在部署时打包为JAR文件。
- EAR模块
- 包含了EJB模块和WEB模块,这两者被打包在一起,形成扩展名为.EAR的文件(打包压缩算法为ZIP)。
(8)JavaEE和Servlet/JSP规范号
- Servlet/JSP是JavaEE体系结构中的一部分,JavaEE发展经历了几个重要阶段,分别包括了不同阶段的Servlet/JSP版本号:
- J2EE 1.3-包含了Servlet2.3/JSP1.2规范
- J2EE 1.4- 包含了Servlet2.4/JSP2.0规范
- Java EE 5.0 -包含了Servlet2.5/JSP2.1规范
- JavaEE 6.0-包含了Servlet3.0/JSP2.2规范
- JavaEE7.0-包含了Servlet3.1/JSP2.3规范
- JavaEE8.0-包含了Servlet4.0/JSP2.3规范
- JavaEE规范高版本兼容低版本
(9)Servlet和JSP规范
- 为了使开发者开发的Servlet/JSP代码能在各种Servlet/JSP容器中不加修改即可运行,JavaEE标准中包含了容器必须遵守的Servlet和JSP加载及运行规则,同时也包括了对应的开发规则,这就是Servlet和JSP规范。
- 早期的Servlet和JSP规范都是一起匹配演进,但后期Servlet和JSP规范都已独立发展。目前最新规范是Servlet5.0和JSP3.0。
- Servlet4.0和JSP2.3及之前的规范均属于JavaEE中的子规范,但后续的Servlet5.0和JSP3.0及以后的规范已是JakartaEE中的子规范。
Web模块/应用/WAR文件结构图示:
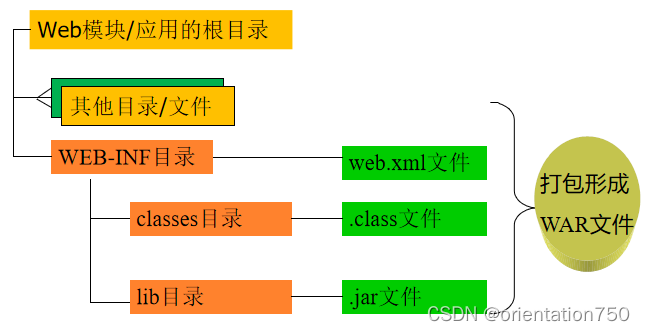
Web模块/WAR文件的目录结构:
- 按Servlet规范,Servlet在部署时需位于包含特定目录结构的Web模块,该模块具体文件及目录组成如下:
- Servlet及其他Java类的字节文件(可选)
- 必须位于模块所在目录的/WEB-INF/classes/文件夹
- 部署描述符文件web.xml(可选)
- 类库文件(可选)
- 必须位于指定目录中的/WEB-INF/lib/文件夹中
- 为了便于部署,也可将Web模块中的所有文件和目录打包成一个WAR文件。
三、Servlet的执行环境
Web服务器可以采用两种形式运行Servlet程序:
- 利用专门的插件技术执行Servlet代码,多见于支持多种服务器端技术的Web服务器,如Apache的 HTTP Server和微软的IIS(Internet Information Server)。
- 整个服务器软件专用于执行Servlet代码,这种Web服务器软件又被称为Servlet/JSP引擎(Engine)或容器(Container),是Servlet主要的运行方式。Servlet引擎一般也会提供Apache或者IIS的Servlet支持插件。
常用的Servlet/JSP容器:
- IBM公司的Websphere
- BEA公司(现被Oracle收购)的WebLogic
- 系统要求小,运行速度快,曾经是市场占有率最高的产品
- Redhat公司的JBoss Server
- Oracle公司的GlassFish
- 前身是网景公司的NetScape Enterprise Server(NES),被SUN收购后,成为开源产品,现为JavaEE规范的参考实现,并可获得Oracle的商业技术服务支持。但在2013年后,Oracle停止了对GlassFish的商业技术支持服务。
- Payara Server
- 是GlassFish项目的一个开源分支,和GlassFish不同之处在于,Payara的使用者可以订阅专业的商业技术支持服务。
- Apache组织的TOMCAT
第二章 Web技术和Tomcat
一、Web技术概述
1.互联网和Web技术
- 采用TCP/IP作为网络通讯协议,通过各种网络设备和操作系统,使得全世界的各种计算机连为一体。
- TCP/IP实际上是一组协议,这些协议按不同的功能分层组织,Web技术主要使用应用层的HTTP协议。
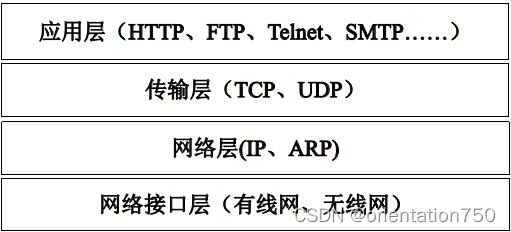
2.Web技术组成
Web技术主要有两部分组成:
- HTML文件(Hyper Text Markup Language)
- 存放于服务器中的文本文件,扩展名为htm或html,它利用特定的“标记”来描述文件携带的文字、图形、声音等信息,主要由浏览器进行读取和显示。
- HTTP协议(Hyper Text Transfer Protocol)
- 用来在网络中传输HTML文件。HTTPS是其加密版,它采用安全套结层协议SSL对传输数据进行加密传输,保护数据安全。
3.Web的工作方式
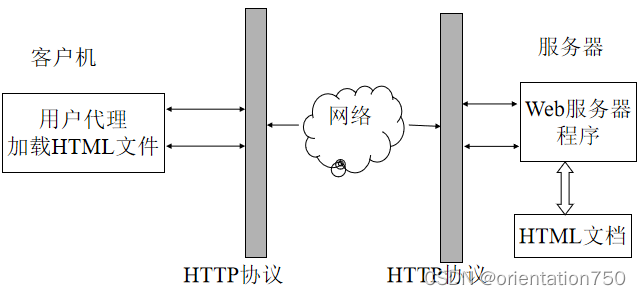
(1)浏览器和用户代理
- 浏览器通过加载服务器中的HTML文档,构成了客户端人机交互界面,它提供丰富的用户界面元素,同时简化了用户的操作过程,是Web技术中最为核心的客户端程序。
- 由于浏览器的重要性,现代操作系统都内置安装有特定的浏览器软件,如微软公司的Windows视窗系统中内置了Internet Explorer/Edge,Linux发行版一般都会内置开源浏览器Firefox,智能手机操作系统也内置安装了不同的浏览器App。
- 在Web技术的术语中,凡是使用HTTP协议进行客户端数据处理的应用,包括浏览器在内,都将之称为用户代理应用(User Agent Application),简称为UA。
(2)Web服务器程序
- 用户代理通过HTTP协议连接服务器计算机时,服务器计算机中必须安装有能够接受用户代理发过来的请求,并可以向用户代理传输生成的HTML数据的特定软件,这种软件就是Web服务器程序。
- 常用的Web服务器程序包括前述的IIS、Apache HTTP Server,也包括Servlet/JSP引擎/容器和其他一些服务器软件,例如Apache Tomcat、GlassFish、Nginx等。
(3)服务器资源
- Web服务器程序一般可以直接将存储在服务器中的HTML文件传输给客户端的用户代理程序,也可以调用类似Servlet之类的服务器端应用生成用户代理所需的HTML标记或者其他相关的一些数据。
- 由Web服务器传输的这些供客户端读取和处理的HTML文件以及数据,都被称为服务器资源,也可以简称为资源(Resource)。
二、HTTP协议
1.HTTP的工作方式
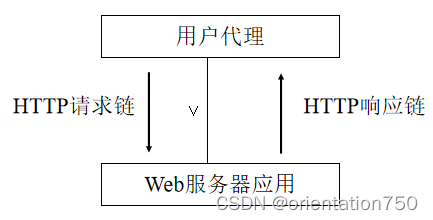
- 由客户机的用户代理提出请求,服务器的Web服务器程序做出响应,双方建立HTTP连接,传递数据,这种方式称之为HTTP的请求-响应模式。
Web服务器程序的运行方式:
- 在请求-响应的工作方式中,由于服务器端不能预先确定客户端请求的到达时间,所以即便没有客户端的请求,Web服务器程序也要一直处于运行状态,需要长时间占用系统的资源。
- 为了尽量减少对服务器资源的占用,操作系统一般都会提供后台执行的方式运行Web服务器程序。例如,Windows可以将应用程序设置为“服务”,以不可见的方式在后台执行Web服务器程序,避免其运行在窗口状态造成的额外资源占用。
2.HTTP连接的特点
- 连接服务器的客户机可能会很多,为了节约服务器资源,HTTP连接被设计成无状态的连接模式
- 在无状态的连接模式下,客户机和服务器在建立连接后,如用户代理下载完成了所需要的数据,当前的连接就会立刻自动被断开,服务器将等待下一次客户机的连接请求。如果下一个客户连接还是同一个客户机中相同的用户代理程序,服务器不会记得该用户代理刚刚和自己做过一次连接。
- HTTP的无状态连接方式使得服务器不必保留每次连接的信息,从而使得服务器可以服务于更多的客户机,非常适合Internet这种具有大量客户机连接的环境
3.协议的端口号
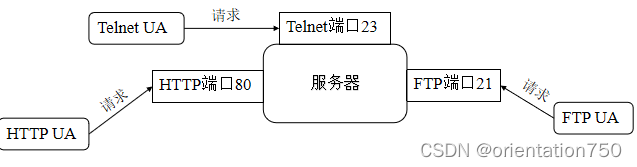
- 端口号是一个大于0的整数,可由服务器中特定的协议处理程序进行指定,操作系统会利用端口号将客户端发来的基于该协议的请求交给服务器中的对应协议处理程序。
- 端口号可以让服务器同时处理来自客户端的基于不同协议的请求。在同一服务器中,每种协议的端口号都应互不相同。
默认端口号:
- 由于服务器程序需要随时监控客户端的请求,所以其处理协议的端口也被称为监听端口。大部分服务器程序都提供了可以定制其监听端口号的功能,使用者可为其选择任意未被使用的监听端口。
- 为了协调和简化各种服务器程序的端口监听工作,国际化组织为各种常见的协议都规定了一个默认的处理端口号,常见的协议的默认端口号:
- HTTP协议默认的端口号是80。
- FTP,文件传输服务,默认端口号为21
- Telnet,远程登录服务,默认的端口号是23
- 需要注意,出于安全性考虑,有些操作系统中只有系统管理员才有权限运行使用1024端口以下的服务器程序。
4.URL和URI
- 客户机要和服务器建立HTTP连接时必须提供如下信息:
- 服务器在网络中的位置信息,在互联网中,位置信息通常用域名或IP地址表示,在局域网络中,通常用机器的网络标示名或IP地址表示
- 服务器的Web服务器程序处理HTTP协议的端口号
- 服务器资源的具体位置
- URL是表示上述连接信息的一种标准化的资源位置表示法,由以下格式的字符组成:
- 协议名://服务器网络标识:协议端口号/资源在服务器中的位置标识
- URL一般由客户端UA处理,在Web技术中用于向服务器提交HTTP请求。
URL示例和URI:
- URL例:http://202.204.79.40:80/jiangyi/java/index.htm 此URL表示通过HTTP协议,获取网络中IP地址为202.204.79.40主机上的index.htm文件,该文件在服务器中的位置标识为/jiangyi/java/。如果服务器端的协议处理程序使用的是默认的端口号,则可以省略URL中的端口号。如本例中,Web服务器程序处理的HTTP协议的端口号为默认的80,则此URL可以简化为: http://202.204.79.40/jiangyi/java/index.htm
- URI是去掉了协议名、服务器位置标识和端口号的URL,可以用于表示资源在服务器中的位置信息。例如,上例中,/jiangyi/java/index.htm就是服务器资源的URI。
5.localhost和127.0.0.1
- 一般而言,在网络中,客户机和服务器都是不同的计算机。但也容许客户机和服务器是同一台计算机,这种情况多见于Web开发工作,程序员在自己的计算机中开发并测试Web应用,此时客户机和服务器就是同一台计算机
- 如果客户机和服务器是同一台计算机,那么在连接服务器的时候,URL中的服务器网络标识就可以用localhost或127.0.0.1代替,代表客户机连接的服务器就是客户机本身,这种表示方法经常用于Web应用程序的开发和测试中
6.HTTP协议的版本号
- HTTP协议经历了一系列的发展历程,目前最新的版本号为2.0。
- HTTP协议是一个国际标准化组织制定的规范,Web服务器软件和用户代理软件之间的通信都是按照这一规范的约定进行。但由于每种服务器软件和用户代理软件编写的时间不同,所以早期的一些软件可能仅支持HTTP的早期规范版本1.0,但目前经常使用的浏览器和Web服务器软件都已经支持1.1版本和2.0版本。
7.HTTP的请求和响应
- http请求协议主要由三部分组成:请求行、请求头和数据实体。
- 请求行:包括http方法(post、get、delete等方法)、http请求文档的URL地址、http的版本号等信息
- 请求头:包括客户机的相关信息及响应中接收的文档类型的具体类型
- 数据实体:客户机向服务器传送的一些附加的数据信息,如在post请求中,html表单中各控件的名称及相应的数据
HTTP请求协议示例:

8.HTTP请求的方式
- HTTP是以请求-响应为工作模式,即由用户代理软件向服务器通过URL的方式提出请求,Web服务器软件做出相应的回应。经常使用的请求方式有以下两种:
- 在HTTP协议的1.0版本中,除去支持这两种请求方式之外,还支持HEAD请求;在HTTP1.1版本中,又增加了5种请求方式,包括PUT、DELETE、OPTIONS、CONNECT、TRACE。本课程只讨论GET和POST请求。
GET请求
- GET请求的数据实体部分为空,它可以在URL 后面加入额外的参数数据,以便向服务器传递客户端中特定的数据。查询字符串的组成如下:
- 第一个字母必须是“?” ,作为查询字符串的引导字符
- 查询字符串中的参数数据由各个参数项组成,每个参数项之间必须用(&)号分开
- 每个参数项都用“参数名=参数值”来表示
- 若参数项中包含有?、=、&等分隔字符或空格,则采用这些字符的16进制字符编码表示,空格也可以用“+”表示
- GET请求示例:
- http://202.204.79.40/index.htm?n=wang&k=java
- 该URL中加入了两个参数:n,数值为wang;k,数值为java
POST请求
- GET请求将参数附加在URL的后面,虽然很方便,但传递的参数数据可以通过观察用户代理向服务器发送URL直接获得,这带来了一定的安全隐患;同时,如果参数数据很多,会造成URL过长,一般的UA和HTTP服务器处理应用都对URL总长有一定的限制,所以GET请求不太适合发送数据量较大的参数。
- POST请求可以让用户代理在保持URL不变的情况下,向服务器发送参数数据,这时参数数据被放入请求的数据实体中传递给服务器,这种方式可以用于传递较大的参数数据。要注意,HTTP协议要求请求头和数据实体之间应留一个空行。
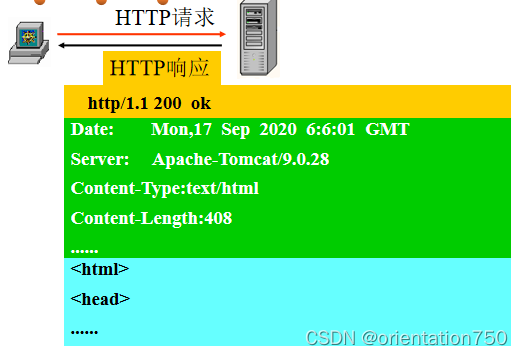
9.HTTP响应
- 服务器接到客户端的请求后,将检查请求的第一行,确定是否可以处理该请求。随后,服务器产生请求的回应信息,即http响应信息。http的响应信息由如下三个部分组成:
- 响应行:包括可以响应的http的版本号及响应的状态码(是否成功响应了客户端的请求)
- 响应头:包括服务器的相关配置及回应的文档类型、数据长度等信息
- 数据实体:包括服务器回应的具体数据,如相应的html的源文件代码等信息
HTTP响应实例
三、HTML基础
- HTML文档是由W3C组织制定一种标准化文本文件,可以在该组织的官网http://www.w3c.org/html中找到HTML标准描述。HTML文档由元素定义组成,元素定义包含一对开始和结束标记,单个标记也可以组成元素定义,具体的格式为:
- HTML元素不区分大小写,成对标记构成的元素中还可以包含子元素定义。有些元素可以只有开始而没有结束标记,单个标记组成的元素也可以省略结束小于号前的"/"符号。例如,以下标记都能构成HTML中合法的元素: <h1> <br> <p>
1.HTML基本元素
- HTML基本元素均为成对标记构成,并且只能在html文件中出现一次,主要包括:
- html元素:html文件的起始根元素。
- head元素:头元素,用于标识HTML文件的一些属性。
- title元素:是head元素中的子元素,用于定义文档的显示标题。
- body元素:用于包含显示内容的元素。
2.元素的属性定义
- 元素可以在其开始标记中定义一些属性取值,指定自身的显示或者一些其他的特性。属性定义的形式为“属性名=属性值”,一个元素可以定义多个属性,具体的语法格式如下:
<元素名 属性名1="属性值1"
属性名2="属性值2"
…
> … </元素名>
- 属性定义必须写在元素开始标记中,当在一行中书写时,每个定义之间用至少一个空格进行分隔。属性值两侧的双引号可以使用单引号代替,也可以省略。
3.HTML注释
- 可以通过注释对HTML中的元素定义进行说明,这些注释不会参与到HTML元素的解析过程。注释的语法格式如下:
<!--
注释说明文字
-->
- 注释可以在一行中书写,也可以在开始和结束之间,采用多行文字说明。
- 注释可以写在HTML文档中的任何位置,也可以在把一些HTML元素嵌入到注释中,以使其失去作用。
4.HTML中的主要元素
除去前述的HTML基本元素之外,HTML中的元素按其功能主要可以分为文档设定元素、显示元素和数据元素:
- 文档设定元素 这类元素一般都是head的子元素,用于设定文档的字符编码、加载特性、刷新时间等特性。
- 显示元素 这类元素很多都是body的子元素,负责构造HTML文档在浏览器中的显示内容。
- 数据元素 用于指定或存储页面中特定的数据,以及向其他应用传递数据。
(1)meta元素
- meta是head的子元素,它通过定义一些属性,设定文档的文本编码、装载特性以及刷新间隔等性质,主要属性包括:
- http-equiv:指定一些文档特定性质的属性名。
- content:指定文档的特定属性的具体取值
<!--其他标记此处从略,在此通过meta指定文档类型和文字存储编码,以避免中文显示乱码-->
<head> <meta http-equiv="content-type" content="text/html;charset=gbk"/>
</head>
(2)p/h/br/hr/pre元素
- p和h1-h6以及br、hr、pre都是body元素的子元素,用于设置文本分行的显示标记:
- P元素:用于将元素中的文字进行分段显示。
- H1/H2/H3/H4/H5/H6元素:类似于P元素,同时将文字设置为特定大小的黑体字,H后面的数字越大,字体就越小。
- BR元素:为单标记元素,可写成<br>,文字换行标记。
- HR元素:类似BR,可写成<hr>,用于生成分隔的水平线。
- PRE元素:PRE元素中包含的文字在浏览器中显示时,将保留其中的空格和换行符号构成的显示效果,同时,文字按照电报类型字体,即等宽字体进行显示。
(3)div/span元素和样式单
- DIV和SPAN元素也为body元素的子元素,主要用于结合样式单设置文本的显示方式。
- DIV元素:类似于P元素,可以将元素中的文字进行分段显示,但默认的段落间距要小于P元素。
- SPAN元素:该元素中的文字会和元素外的文字在同一行中显示,通过设置该元素的样式单属性,可以设置同行文字中不同部分的显示特性。
<div style="color:red">Wrong Input!</div>
Please notice the <span style="color:blue">blue</span> fonts.
(4)图像显示元素img
- img元素用于网页中的图像显示,其src属性值为要显示的图片的URI/URL,title属性用于指定鼠标移动到该图片上时的文字提示,具体的语法如下:
- <img src="图片的URI/URL" title="图片的文字提示"/>
- 当指定的图片位于当前页面所在本地文件夹中时,可以使用URI进行图片位置的指定,如果图片和当前页面位于同一个目录中,可以直接指定图片名称,还可以采用如下符号:
- . 代表当前的目录
- .. 代表上一级的目录
- / 用于分隔上下级目录或者目录和文件
img元素示例:

如上图所示,在index.html文件中,显示p.jpg和g.png的标记分别为:
<img src="../img/p.jpg">和<img src="phone/g.png">
(5)表格元素table
table元素用于建立网页中的表格,它和thead、th、tbody以及tr、td等子元素一起组成表格,具体的语法如下:
<table border="n">
<thead><th>表头1</th> <th>表头2</th>… </thead>
<tbody> <tr><td>列1</td><td>列2</td>…</tr>
<tr><td>列1</td><td>列2</td>…</tr>
……
</tbody>
</table>
(6)超链元素a
- a元素可在浏览器中显示点击可转入其他文档的链接文本,其href属性值用于指定要链接文档的URI/URL,具体的语法如下:
- <a href="链接文档的URI/URL">链接文本</a>
- a元素的href属性取值类似于img元素的src属性,可以指向本机中的文档或者其他服务器中的资源。当用户点击链接文本时,浏览器会按照GET方式向href属性指向的URL对应的服务器提交HTTP请求,之后浏览器将显示服务器回应的页面。超链经常用于HTML页面之间的导航,以及发出对Servlet/JSP的GET请求。
- 默认情况下,超链转入的页面会替代当前页面。如需在新的浏览器窗口打开链接页面,可以添加属性取值target="blank"。
(7)表单元素form
- form元素的功能类似于超链元素a,可用于浏览器中页面之间的导航或对Servlet发出请求。该元素的action属性用于指定发出请求的URI/URL,具体的语法如下:
<form action="请求URI/URL" method="post/get">
……
</form>
- form可通过method属性指定发出的请求为GET还是POST方式。
- 如果省略action属性,则表单发送的请求URL为其所在的页面。
- 和超链类似,form元素也可以指定target="blank"的属性取值。
通过input元素发送form请求:
- 通过form元素发出HTTP请求时,需要为其定义用于发送请求的input子元素。将input子元素指定为提交按钮类型,如下所示,用户才可以在浏览器中通过点击该按钮,发送form指定的HTTP请求:
<form action="someurl">
……
<input type="submit" value="确定"/>
</form>
- 由于form利用提交按钮发送HTTP请求,所以form发送HTTP请求也被称为向服务端提交请求。
构造表单交互组件及名-值数据对
- input还可为表单构造包含需提交的名-值对的其他一些交互组件:
<input type="text" name="n" value="v"/> 设置文本输入框。
<input type="radio|checkbox" name="n" value="v"/> 设置单选或多选钮,处于选中状态时名-值才会被提交。
<input type="button|reset" name="n" value="v"/> 设置普通或重置按钮,重置按钮用于恢复表单中交互组件的初值。
<input type="hidden" name="n" value="v"/> 多用于表单中需提交的无显示关键名-值数据的存储。
构造表单中的下拉列表
- select也是form元素的子元素,它和option可以为表单构造下拉列表或者菜单,基本语法如下:
<select name="n" multiple size="n">
<option value="v1">selectText1</option>
<option value="v2">selectText2</option>
……
</select>
- 如果设置了select元素的multiple属性,则此下拉列表就可以在点击选项时按住ctrl键被选中多项,或者通过按住shift键选中连续的多项。
构造表单中的多行文本输入框
- Form元素的子元素textarea可以用来构造多行文本输入框,基本语法如下:
<textarea name="n"
rows="n"
cols="m">初始文本</textarea>
构造表单中的文件上传组件
- 除去向服务器提交文本类型的名-值对数据之外,表单也可通过input元素构造文件上传组件,上传任意类型的文件。此时form也需要设置一些相关的属性,才能保证数据上传的正确性:
<form method="post" enctype="multipart/form-data">
<input type="file" name="n1" /> <input type="submit">
<!– 注意此处表单的提交方式必须设置为post,且必须设置 enctype属性为“multipart/form-data”。一个表单中可以出现多个文件上传组件,也可以包含任意其他包含普通名-值数据的交互组件定义。-->
</form>
四、Tomcat基础
- Tomcat的前身是原美国SUN公司(现已被美国Oracle公司收购)开发的Java WebServer和JSWDK,后期SUN公司将这两个项目都移交给了Apache组织进行管理和开发,Apache将其列入到当时Jakarta大项目中的一个名为Tomcat的子项目,现在Tomcat已经成为Apache的顶级项目。
- 可以从https://tomcat.apache.org下载所需的版本,Tomcat采用纯Java语言编写实现,所以在运行时需要JRE或者JDK的支持。
1.Tomcat的版本号和Servlet标准
- Tomcat4.x版本实现的Servlet2.3及JSP1.2标准
- Tomcat5.x版本实现了Servlet2.4和JSP2.0标准
- Tomcat6.x版本实现了Servlet2.5和JSP2.1标准
- Tomcat7.x版本实现了Servlet3.0和JSP2.2标准
- Tomcat8.x版本实现了Servlet3.1和JSP2.3标准
- Tomcat9.x版本实现了Servlet4.0和JSP2.3标准
- Tomcat10.x版本实现了Servlet5.0和JSP3.0标准
2.Tomcat的目录结构

(1)bin目录
- bin目录用于存放Tomcat的启动和停止文件:
- startup.bat和startup.sh分别是windows和unix(linux)平台下的启动脚本文件
- shutdown.bat和shutdown.sh分别是windows和unix(linux)下的终止Tomcat服务的脚本文件
(2)lib目录
- lib目录主要存放了Tomcat和运行及管理工具用到的库文件(.jar)文件
- Web应用程序也可以使用此目录中的库文件。
(3)conf目录
- conf目录是tomcat的配置文件的存放目录,tomcat启动时,将利用这些配置文件进行系统的设置
(4)webapps目录
- webapps目录负责存放tomcat自带的一些web应用程序,如tomcat的文档、示例等。
- 用户编制的web应用程序可直接拷贝到此目录下,tomcat将会自动识别并部署这些web应用程序而无需重新启动tomcat服务器程序。如果用户拷贝的是.war文件,tomcat还会将.war文件自动解压到同名的文件夹中(不包含.war扩展名)。
(5)work目录
- work目录是tomcat在运行时自动创建的文件夹。
- work/standalone子目录:如果Tomcat以独立服务器模式运行,那么Work目录中将包含一个standalone文件夹,此文件夹中包含了Tomcat中虚拟主机名的相应目录。
- work/standalone/localhost子目录:如果Tomcat中并没有设置虚拟主机,那么在standalone文件夹中将只包含一个名为localhost的子文件夹,此文件夹中复制了当前Tomcat中安装的web应用程序的相应目录
(6)temp和logs目录
- temp目录是Tomcat在运行时自动产生的一些临时文件存储所在的文件夹。
- logs目录是Tomcat在运行时自动创建的日志文件所在文件夹,可以在此目录中查看Web程序在Tomcat中运行时的产生的运行诊断信息,也可以查看Tomcat自身的一些运行及错误信息。
3.Tomcat的配置文件
- Tomcat的配置信息主要采用xml格式进行存储,这种文件类似html文档,也是由元素组成的文本文件,使用相同的注释形式。但xml文件在格式上更为严谨,元素的开始标记必须和结束标记相互匹配,正确结束,且区分元素名称中的大小写字母。
- Tomcat的配置文件一般都存放在安装目录的conf子文件夹中。它们在tomcat运行将被系统自动读取,控制着Tomcat的运行方式及运行中的管理工作。
(1)server.xml
- server.xml是Tomcat的核心控制文件,此文件的内容改变只有在重新启动Tomcat后才能起作用,建议在修改前备份原有的文件,以防因为修改中的错误造成Tomcat不能正常启动。
- 使用server.xml文件进行的常见设定工作包括:
- Tomcat默认的HTTP协议处理端口号
- Web应用程序部署位置
- Tomcat处理特定HTTP请求方法的方式
例:修改server.xml中HTTP端口号以及get方法处理编码
<Server port="8005" shutdown="SHUTDOWN">
<!– 其他配置定义省略-->
<Service name="Catalina">
<!--红色文字部分为修改或添加项-->
<Connector port="80" protocol="HTTP/1.1"
connectionTimeout="20000"
URIEncoding="utf-8"
redirectPort="8443" />
</Connector>
<!--其他配置定义省略-->
</Service>
(2)tomcat-users.xml
- Manager是Tomcat自带的Web应用管理程序,设Tomcat监听HTTP协议的端口是8080,则本机中访问该程序的URL是: http://localhost:8080/manager/html
- Manager在访问时,会通过conf目录中tomcat-users.xml文件验证用户的认证信息和权限,该文件中的根元素必须为tomcat-users,根元素中通过如下子元素定义用户信息:
- role:role元素及其rolename属性定义角色名称,从而确定用户的权限。
- user:user元素及其username、password和roles属性定义用户的认证信息和对应的角色。
tomcat-users.xml中添加manager的用户信息和权限
- Manager程序既可以通过上述URL访问其Web页面,也可以通过访问其提供的API接口,直接对其功能进调用,不同的方式需要提供使用不同权限的用户名和口令进行认证。
- Manager程序的Web页面访问权限的角色名为manager-gui,具有API接口访问权限的角色名为manager-script。
- 解压缩版本的Tomcat的tomcat-users.xml文件中没有定义任何用户和角色,需要在其中加入manager-gui权限的用户定义,才能使用Manager程序的Web页面管理Web应用程序。
具有manager的Web和API权限的用户定义tomcat-users.xml示例
<?xml version="1.0" encoding="utf-8" ?>
<tomcat-users>
<user username="admin" 指定用户账号
password="admin123765" 指定用户密码
roles="manager-gui,manager-script"/> 此处的admin用户具有Web页面及API接口权限,需要两个角色,用逗号分隔这些角色
</tomcat-users>
tomcat-users.xml的注意事项
- 一旦tomcat-users.xml文件进行了修改,必须要重启Tomcat才能使之生效。
- tomcat-user.xml是以明文的形式存放用户名和口令,这是非常不安全的。可以利用操作系统的用户管理或数据库用户表来代替tomcat-user.xml,具体步骤可以参考Tomcat的在线文档,此处不再进行说明,
(3)web.xml
- web.xml是Tomcat在部署Web应用时默认的配置文件,其中包含Web应用的欢迎页面、遵循的Servlet标准等配置信息。
- 按照Servlet规范,每个Web应用程序都可以在其部署的目录中,通过WEB-INF/web.xml文件指定属于自身的配置信息。当Web应用没有该web.xml时,Tomcat将使用自身安装目录中此conf文件夹中的web.xml中的配置作为当前Web应用的配置信息。
4.设定Tomcat多实例配置文件
- Tomcat支持在一台计算机中通过一份安装,运行多个不同配置的实例,每个实例在运行时都使用自己的配置文件。
- 在运行某个Tomcat的实例时,需要设置CATALINA_HOME和CATALINA_BASE两个环境变量值,分别指向Tomcat的原始安装目录和当前需运行的Tomcat实例所在的配置文件夹。
-
可以在NetBeans中集成Tomcat,从而简化Tomcat多实例运行方式下的配置和运行工作:
- 在NetBeans的服务视图中右键点击“服务器”结点,选择添加Tomcat服务器所在的安装目录。
- 然后再指定需运行的实例对应的一个空私有文件夹即可。
第三章 Servlet编写和运行
一、Servlet源代码的编写
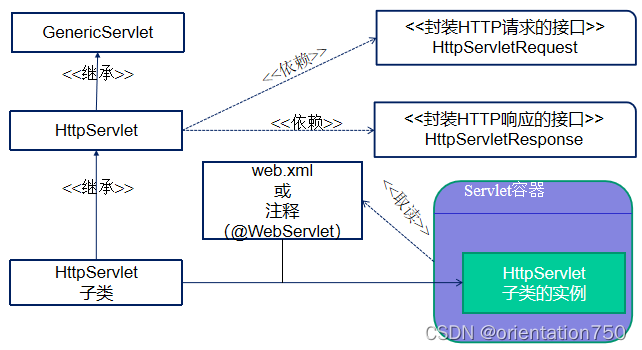
1、用于Servlet的java包和类
- javax.servlet:包含用于一般性Servlet程序设计的基础类,GenericServlet位于此包
- javax.servlet.http:包含专用于处理HTTP协议的相关类
- java.io:包含协助Servlet完成流处理、日志记录等工作的输入输出类
- javax.servlet.http.HttpServlet类:基于HTTP协议的Servlet程序设计就是通过继承此类,重载该类中相应的方法来完成的。
Servlet类的依赖继承图
2.Servlet类定义
- 当客户端特定的HTTP请求到达时,容器将建立HttpServlet类型的Servlet实例,调用其中的处理方法;因此,Servlet类的编写都要直接或间接继承HttpServlet,然后对该父类中的方法进行改写,以便处理对应的HTTP请求。
- Servlet类采用public进行定义,一般直接继承HttpServlet:
public class Servlet类名 extends HttpServlet{
/*多是改写doGet、doPost以处理GET、POST请求,为保证正确,最好在改写的方法前面加入@Override注解*/ }
Servlet类定义示例
import javax.servlet.http.*;
import javax.servlet.annotation.WebServlet;
import java.io.Exception;
public class HelloServlet extends HttpServlet{
@Override
public void doGet(HttpServletRequest request,
HttpServlet Response response)
throws javax.servlet.ServletException,IOException{
//处理GET请求代码
}
}
HTTP请求和Servlet实例示意图
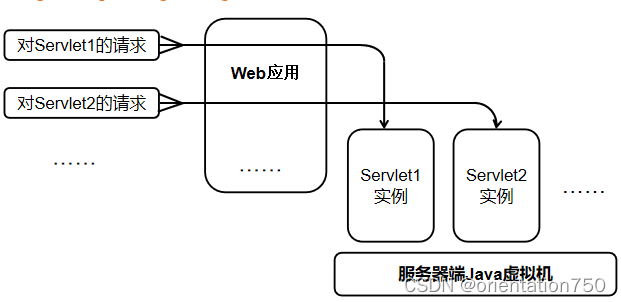
3.Servlet生命周期方法的改写
- 当客户端通过特定的URL,对指定的Servlet发出HTTP请求时,容器将建立对应Servlet类的实例以响应用户的请求。Servlet实例的建立和销毁均由容器进行控制,这一机制被称为容器对Servlet的生命周期管理。
- 由于Servlet类都继承自HttpServlet,按照Java语言中OO多态的语法特性,Servlet容器在建立对应和销毁Servlet实例、处理HTTP请求时,调用的都是HttpServlet及其父类中对应的生命周期方法,这些方法均可由开发者在Servlet自身的类定义中进行改写,以控制容器对Servlet实例的管理以及处理请求。
Servlet的生命周期方法

(1)init的方法
public void init() throws java.servlet.ServletException;
- init方法当Servlet被实例化时执行,在Servlet生命周期中只被执行一次。
- 改写此方法以执行整个Servlet程序的初始化工作,如建立用户访问页数次数的计数器,初始化数据库连接等等工作。
- init实际是HttpServlet的父类GenericServlet中定义的方法。
(2)service方法
protected void service( HttpServletRequest req, HttpServletResponse resp)
throws ServletException, java.io.IOException;
- 该方法在HttpServlet中被实现为根据HTTP请求的请求方式,调用doGet、doPost、doPut等方法。虽然改写该方法可以处理通用的HTTP请求,但一般不建议在Servlet类定义中改写此方法。
(3)doGet方法
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, java.io.IOException;
- doGet方法用于对HTTP中的GET请求处理工作。该方法的request和response参数分别封装了HTTP的请求和响应。
doGet方法改写示例
@Override
protected void doGet( HttpServletRequest request, HttpServletResponse response)
throws javax.servlet.ServletException, java.io.IOException{ response.setContentType("text/html;chartset=GBK");
try(java.io.PrintWriter out = response.getWriter()){
out.println("<html><head>");
out.println("<title>Servlet</title>");
out.println("</head>");
out.println("<body>");
out.println("<h3>hello,world</h3>");
out.println("</body></html>
(4)doPost方法
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, java.io.IOException;
- doPost方法参数类型和数目和doGet方法完全相同,用于处理HTTP的POST请求。
- 一般而言,通过浏览器调用Servlet的doPost方法时,需要借助HTML页面中的表单标记。
二、Servlet的编译和部署
- 编译Servlet源文件时,需要保证以下条件:
- 编译时的类路径包含Servlet规范类库,该类库名称一般是servlet-api.jar,Servlet服务器中都会包含该类库,例如Tomcat中的servlet-api.jar文件位于其lib目录
- 保证其他一些依赖类文件和类库文件位于编译类路径
- 编译成功后的类文件和其他需部署的文件在编译后能够正确组成Web应用程序所需的目录和文件。
- 由于Servlet的编译工作需要很多步骤,所以,实际工作中,经常采用一些集成化的项目构建工具,以简化编译、部署的过程。
1.常用的项目构建工具
- Apache Ant
- Ant采用xml文件组织编译,它默认在名为build.xml的文件中设定编译任务,还可通过属性文件修改部分的编译设定。NetBeans集成了Ant,将其用于各种项目的编译、部署和运行。
- Apache Maven
- Maven使用pom.xml组织编译工作,能解决编译中类库版本的依赖问题,在默认情况下Maven需要访问互联网以下载必要的文件来完成编译任务。NetBeans中集成了对Maven的支持。
- Gradle
- 功能上类似于Maven,但Gradle使用一些动态语言替代了XML,使得其中的编译组织工作比Maven更为简单。NetBeans从9.0版本开始支持Gradle。
2.NetBeans的Ant Web项目目录
- NetBeans中通过Java Web项目支持Servlet的编译和部署,当选择Ant为构建工具时,项目的主要目录及文件如下所示:
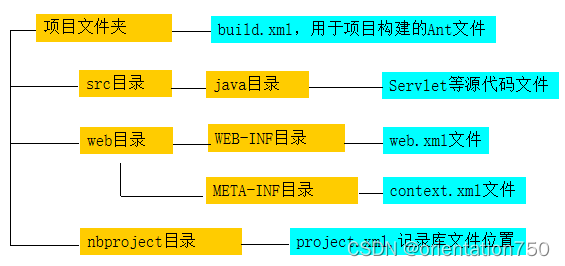
(1)src/java目录
- src目录下实际包含有两个子文件夹,分别是java和conf:
- java目录是项目中所有Java源代码的存储位置。此目录中的源代码编译成的类文件将进入项目生成的Web应用程序的WEB-INF/classes目录。
- conf目录用来存放项目的一些和需要和编译后的类文件一起发布的相关的配置文件,例如类文件打包后的清单文件MANIFEST.MF和其他一些描述类信息的相关文件。

(2)web目录
- web目录在部署后会成为Web应用的根文件夹,该目录下的文件和文件夹将构成Web应用的整体文件和目录结构:
- 需要发布的HTML及其相关文件夹,例如,存放页面图片的pics、页面脚本文件夹js,都要在位于此目录。
- WEB-INF子目录中的web.xml是设置Servlet运行URL的主要文件,也是整个Web应用的核心设置文件。
- META-INF子目录中的context.xml可以用来设置Web应用部署的上下文路径(Context Path)。

(3)nbproject目录
- nbproject目录中由NetBeans自动维护,其中包含项目一系列以project为名的设置文件,一般无需开发者对其处理。
- nbproject是项目文件夹的重要标记,此文件夹一旦被删除,或者修改了其中的文件,有可能导致整个项目不能被NetBeans读取和打开。
- 如果遇到了这种情况,可以新建一个项目,然后将不能读取的项目文件夹中的web和src目录拷贝至新项目,替换项目中同名的文件夹即可。
3.设置Web应用程序资源
- 在Servlet部署之前,应对其所在的Web应用程序完成以下工作:
- 设置Web应用程序的部署标识,即上下文路径
- 规划可访问页面及其所在目录
- 设置Web应用程序的欢迎页面
(1)Web应用程序的上下文路径
- Web应用程序在容器中部署,就是为应用程序中的资源建立以HTTP作为协议,可供客户端UA访问的URL。Web应用程序中资源的URL形式如下所示: http://主机名:端口号/Web应用程序标识/资源标识
- 在上述URL中,"/Web应用程序标识"即为该Web应用程序的上下文路径(Context Path),需要注意,上下文路径以“/”为开始字符,并且区分大小写。
- 上下文路径实际上就是资源的服务端URI的开始部分,容器通过URL中的上下文路径识别客户端需要请求的Web程序。
(2)规划各类页面
- 在部署前应对各类页面及其所在目录进行规划,需要直接提供给客户端访问的页面,应保证其不位于/WEB-INF目录,客户端均可通过如下URL访问这些页面:
- http://主机位置:端口号/Web程序标识/文件路径/文件名
- 对于一些特殊的文件和页面,例如,web.xml文件、需要特殊权限才能访问的页面,应将其放入Web程序的/WEB-INF及其子目录进行保护,按照Servlet规范要求,客户端UA不能直接通过该目录中文件所在的位置对其进行访问。
(3)通过web.xml设置欢迎页面
- 欢迎页面是指在请求URL中仅给出Web程序的上下文路径时,程序回应的页面。欢迎页面可以通过web.xml进行指定。
- web.xml文件是一种xml类型的文件,此文件必须位于Web程序的/WEB-INF目录。除去设置欢迎页面之外,还利用该文件可以指定Web应用程序如下特性:
- 设置Servlet的URL
- 对Servlet完成的功能进行说明
- 指定Servlet被引擎装载时的运行参数
- 指定Servlet可以使用的Java EE资源
- 定义其他一些Web组件,例如过滤器、监听器等
Servlet2.3中的web.xml文件头
- 在Servlet2.3规范中,web.xml文件利用DTD进行XML文件合法性约束,因此,在web.xml文件的开头必须声明XML文件的版本号和编码格式,并且还要声明相关的DTD约束。实际上,符合Servlet2.3规范的web.xml的开头格式都是固定的,其内容如下所示:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web
Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
Servlet2.4中的web.xml文件头
- 从Servlet2.4规范开始,web.xml文件改为使用模式(Schema)进行XML文件合法性约束,在web.xml文件的开头格式有所变化,其内容如下所示:
<?xml version="1.0" encoding="utf-8"?>
<web-app version="2.4" 此处为Servlet规范版本号
xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_2_4.xsd"> 此处为Servlet规范文件名,按照规范的编号取相应的*_*,比如此处的2_4,代表2.4规范。
<!--其他元素声明-->
</web-app>
welcome-file-list元素
- 在web.xml文件头之后,可以使用welcome-file-list元素设置欢迎页面:
<welcome-file-list>
<welcome-file>欢迎页面的URI</welcome-file>
</welcome-file-list>
- <welcome-file-list>标记中可含多个welcome-file子元素,用于规定多个欢迎页面的URI。这些页面可以在Web程序中存在,也可以不存在。Web容器按照由上至下的次序根据URI查找这些页面,将第一个找到的实际存在的页面作为欢迎页面回传给客户端。
欢迎页面设置的web.xml文件示例
<web-app version="2.5" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_2_5.xsd">
<!—以下设置了3个欢迎页面的URI,以第一个真实存在页面为实际的欢迎页面-->
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>index/default.jsp</welcome-file>
</welcome-file-list>
</web-app>
4.通过web.xml设置Servlet的URL
- Servlet属于Web程序中的执行资源,类似于其他资源,也需要设置其访问URL以供客户端进行请求。
- Servlet的URL可通过web.xml中的servlet和servlet-mapping两个元素进行设置:
- servlet元素用于定义供容器读取的Servlet的类信息,它主要包括servlet-name和servlet-class两个子元素,用于定义容器实例化Servlet时的类型信息和实例名称。
- servlet-mapping元素包含servlet-name和url-pattern两个子元素,用于定义servlet元素中定义的Servlet实例对应的服务端URI。
servlet和servlet-mapping元素
- 在web.xml文件中,servlet和servlet-mapping元素必须一起配合使用,定义某一个Servlet的请求URI,具体的格式如下:
<servlet>
<servlet-class>Servlet类的全名</servlet-class>
<servlet-name>Servlet名1</servlet-name>
</servlet>
<servlet-mapping>
<servlet-name>Servlet名1</servlet-name>
<url-pattern>Servlet的URI</url-pattern>
</servlet-mapping >
web.xml中定义Servlet的URI示例
<web-app version="2.5" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_2_5.xsd">
<servlet>
<servlet-name>HelloServlet</servlet-name>
<servlet-class>web.HelloServlets</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloServlet</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>
</web-app>
Servlet请求URL的解析过程

Servlet请求URI的格式组成
- 一般情况下,url-pattern元素定义Servlet请求URI的格式是"/标识符",开始符号"/"代表Web程序的根目录,这种格式会将该Servlet的URI映射为Web应用程序根目录中的资源标识,而根目录符号后面的标识符一般由26个英文字母、数字组成。注意,此处的定义的标识符区分大小写。
- 也可以将请求URI中的标识符定义为类似于文件名的格式,即"/文件名.扩展名",比如"/index.htm",这样可以使得Servlet和其他页面资源的命名相统一,体现其资源的特性。
- 为了便于Servlet处理来源于客户端UA的请求,Servlet规范还允许通过url-pattern元素定义更为通用的资源标识。
(1)/<path>/
- 这种映射定义将所有包含/<path>/路径的请求都归并到某一Servlet来处理。例:
<servlet>
<servlet-name>MyServlet</servletname>
<servlet-class>web.MyServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>/myservlet/*</url-pattern>
</servlet-mapping>
(2)*.<ext>
- 这种映射以通配符号"*"开头,可以将所有以.<ext>为扩展名的请求交给定义的Servlet处理。例:
<servlet>
<servlet-name>MyServlet</servletname>
<servlet-class>web.MyServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
(3)/或/*
- 这种映射将使得所有的请求均由定义的Servlet处理,其中"/*"的优先级别比"/"更高。但"/*"的形式有可能会引发一定的处理问题,所以不建议采用这种方式。例:
<servlet>
<servlet-name>MyServlet</servletname>
<servlet-class>web.MyServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
5.通过注解设置Servlet的URL
- 从Servlet3.0规范开始,可以在Servlet源代码中使用@WebServlet注解代替web.xml文件对Servlet进行映射。
- 注解(Annotation)在JDK1.5中引入,是源代码中以"@"开头的一种特殊的注释,可被编译器或其他Java程序读取,用来对源文件的编译或字节码的运行进行定制。
- 例如,@Override注解写在方法定义的前面,规定编译器在编译时,一定要检查该方法是否改写了父类对应的方法,如果没有,则编译报错,防止程序在运行时出现问题。
@WebServlet注解
- @WebServlet只能出现在Servlet类定义的前面,全名为@javax.servlet.annotation.WebServlet,可以使用import语句导入其全名,从而直接使用@WebServlet。
- @WebServlet注解有name和urlPatterns两个参数,分别用来规定Servlet的名称和映射模式。
@WebServlet(name="servlet名称",
urlPatterns={"/映射1",
"/映射2",
...
})
@WebServlet注解示例
import javax.servlet.http.*;
import javax.servlet.*;
import javax.servlet.annotaion.WebServlet
@WebServlet( name="helloServlet", urlPatterns={"/hello", "*.hello"} )
public class HelloSerlvet extends HttpServlet{
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException,java.io.Exception{
//处理GET请求代码
}
}
@WebServlet和web.xml的优先级
- 从Servlet3.0规范开始,Servlet所属的Web程序既可以包含web.xml,也可以不包含web.xml。
- 如果一个Web程序中包含了web.xml文件,而Servlet既使用了@WebServlet注解规定其映射,又在web.xml文件中规定了其映射,这时web.xml中的映射将优先被容器读取采用。
6.Servlet的部署
- 按照Servlet规范,Servlet类文件必须位于Web应用程序的WEB-INF/classes目录,随同Web应用程序在容器中部署。
- 不同的Web容器,部署Web应用程序的方式可能不尽相同。大部分容器都提供了两种部署方法:
- 文件拷贝法 将WAR文件或Web应用的根目录拷贝到容器的特定目录下即可完成部署。Tomcat中的此目录是位于安装目录下的webapps。
- 部署工具 通过特定的应用部署WAR文件或Web应用的根目录。Tomcat自带的部署工具是Manager,NetBeans集成Tomcat后,也是通过该工具部署Web项目中生成的build/web文件夹。
(1)WAR文件的部署处理
- 当以WAR方式部署Web程序时,容器可采用两种处理模式:
- 解压缩模式 这种模式下,容器会自动将WAR文件解压缩成文件夹,以后对该WAR文件的访问,都将视为对解压缩之后的Web程序目录的访问。例如,拷贝到Tomcat的webapps目录的WAR文件,默认都会被解压成同名的文件夹。
- 非解压模式 容器不解压缩WAR文件,这种部署模式便于容器管理其中的Web程序,但会导致Web程序不能动态存储生成的文件,同时也会带来一些资源获取问题,所以这种模式较少被采用。
(2)根Web应用程序的部署
- 根Web应用程序也称默认Web应用程序,是指其上下文路径中Web应用程序标识为空。
- 如果在Tomcat中通过文件拷贝法部署根Web应用程序,应该将Web应用程序在webapps中设置为ROOT。

(3)使用部署管理工具
- 很多容器都提供了便于Web应用程序部署的管理工具,这种工具有的是一些命令行工具,也有的是以容器中部署的Web应用程序的形式提供。
- 前面章节介绍了Tomcat服务器中的部署工具Manager,实际上,在NetBeans IDE中集成Tomcat之后,NetBeans也是通过Manager对其中的Java Web项目进行部署管理的。
- 需要注意的是,如果在开发过程中重新编译了Servlet及其他类文件,一般都需要重新加载部署的Web应用程序,才能使修改生效。在NetBeans,点击工具栏中的保存按钮,IDE会自动重新加载部署的Web项目,使项目中的修改生效。
7.Web程序页面中的Servlet请求
- Web程序一般以HTML文档作为用户操作界面,其中超链和表单两个元素经常用于处理用户的操作,将数据发送给Servlet。
- 程序中的HTML页面和Servlet所处的目录结构一般如下所示:
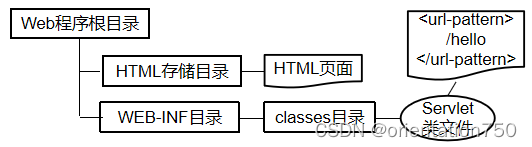
- Servlet通过其url模式的设定,也可以看成是一种页面。Web程序中的表单和超链可以用相对URI或绝对URL请求Servlet。
(1)绝对URL
- 绝对URL就是指完整的URL,例如,以下超级链接中的href属性取值即为绝对URL: <a href="http://localhost:8080/wa/hello">absoulte</a>
- 当同一个Web程序部署在不同的IP地址或域名的服务器中时,对程序内部的Servlet请求的绝对URL都需要改变,所以这种URL会极大地降低Web程序的可部署性。含绝对URL的超级链接或者表单多用于不同网站之间的资源获取,而在同一Web程序内部的页面和Servlet之间的请求很少采用这种形式。
(2)相对主机的URI
<a href=“/wa/hello”>hostbase</a>
- 如果Web程序被部署到本地主机中,服务器监听8080端口,则当该超链在页面被用户点击时,会被浏览器自动添加上相关前缀,形成以下url:http://localhost:8080/wa/hello
- 这种URI在处理时,会直接在之前添加主机的位置信息,所以要在起始“/”之后保证是Web程序部署的上下文路径。但是,同一个Web程序部署的上下文路径也可能会不同,因此,在使用这种URI时应注意尽量用Servlet中相关的API动态获取Web程序部署的上下文路径。
(3)相对Web程序上下文路径的URI
- 这种URI不以"/"开头,例如,以下的超级连接的标记代码:
<a href="hello">contextbase</a>
- 如果Web程序被部署到本地主机中,服务器监听端口8080,部署的上下文路径为wa,则当该超链在页面中被用户点击时,会被浏览器自动添加相关前缀,形成以下URL: http://localhost:8080/wa/hello
- 当这种URI在不同的页面中出现时,浏览器会根据其所在页面形成不同的URL,所以在使用时要注意其相对性。有时,由于Web程序中会采用不同的方式访问该页面,所以可能会出现最终形成的URL失效的现象。
三、Servlet的运行
- Servlet类的实例化是由Web容器控制的。当多个用户同时访问同一Servlet时,Web容器有两种模式对Servlet进行实例化,以响应用户的请求:
1.多线程模式
- 多线程是Servlet最为常用的运行模式。在这种模式中,Servlet容器只实例化一个Servlet类,用这一个类实例服务所有的对该Servlet的请求。此时,该类中定义的service、doGet、doPost等方法都是多线程的,而init、destroy不是多线程的。
多线程模式示意图
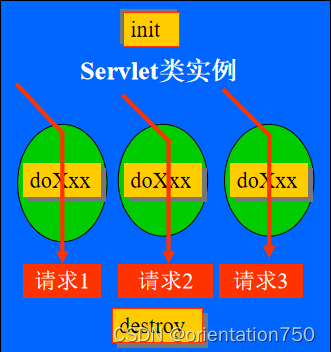
多线程模式注意事项:
- 在多线程模式中,由于在同一时刻会产生几个对service或doXxx调用,而Servlet类的实例只有一个,所以,如果在service或doXxx方法中对类中声明的属性(即实例变量)或类中的静态变量(即类变量)进行访问,应注意变量的并发访问问题
2.单线程模式
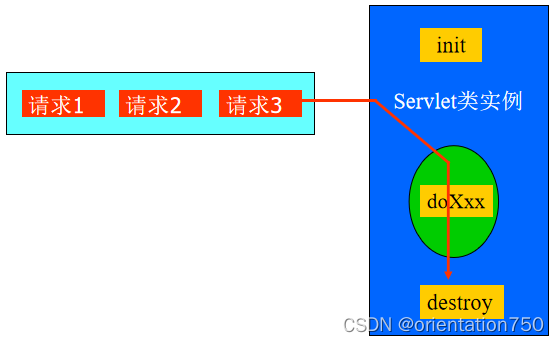
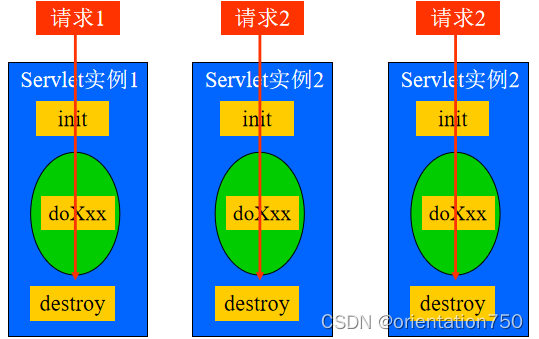
- 单线程模式是指Servlet类中声明的service方法、doGet、doPost等方法都是单线程的,不用考虑线程中的同步问题。在此种模式下,如果有多个请求同时要求调用service或doGet等方法,则容器将以一定的方式保证在同一时刻只有一个请求被相应的方法处理。
方式1:排队方式
方式2:多实例模式
单线程模式的说明
- 实现单线程模式运行的Servlet需要实现SingleThreadModel接口
- 不同的Servlet/JSP引擎在单线程模式下采取的具体实现方式(排队或多实例)有所不同
- 一般情况下,不提倡使用单线程模式,因为这样有可能降低Servlet处理请求的效率(在排队模式下),且并不能完全避免多线程中变量的同步访问问题。在Servlet2.4及后续规范中,已经废弃了单线程模式
第四章 Servlet基本应用
一、HTTP协议的封装
- 当HTTP请求到达Servlet时,Web容器将HTTP响应和请求利用以下两个接口进行封装:
- javax.servlet.http.HttpServletResponse
- javax.servlet.http.HttpServletRequest
- 这两个接口均作为HttpServlet类的service、doGet、doPost等方法中的参数,供编程者在对应的方法进行调用。
- 封装HTTP响应和请求的接口都通过继承通用父接口的方式,提供接口在使用时的通用性。
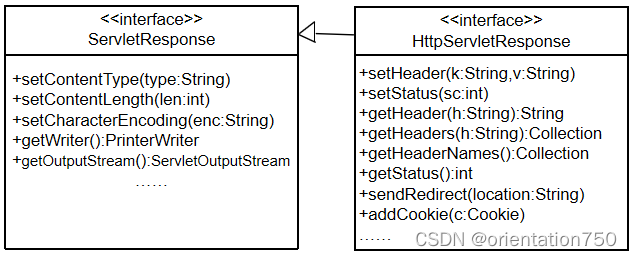
1.HttpServletResponse接口
- HttpServletResponse继承了ServletResponse通用接口,用于封装HTTP协议的响应处理。此接口中的方法用于向HTTP客户端UA设置和传输所需的数据流。
(1)Servlet的数据输出特点
- 和Java应用程序的本地输出不同,Servlet一般要通过网络将服务器端数据向客户端UA进行输出,其输出具有以下特点:
- 由于客户机中的UA一般是浏览器,所以Servlet的输出往往是HTML格式的文本数据流。
- Servlet在输出文本时,一般不使用System.out对象,该对象的输出方法只能在服务器端的控制台窗口输出文本,这些文本不能传输到网络中的客户机。
- Servlet在向客户机UA进行数据输出之前,一般都要先设定数据的类型说明,以便UA能够根据类型进行数据处理。
- 对于非文本数据,Servlet采用二进制流进行传输。
响应流
- Servlet采用输出流(Writer或OutputStream抽象类的子类)封装对于客户端UA的数据输出,这种输出流即为响应流:
- 文本流的类型为java.io.PrintWriter,其print或println方法用于输出具体的文本。
- 二进制流的类型为java.servlet.ServletOutputStream,其write方法用于输出具体的字节数据。

(2)接口中和响应流相关的方法
- ServletResponse接口中提供了以下方法获取和设置响应流:
- PrintWriter getWriter():获得向客户端输出的文本流
- ServletOutputStream getOutputStream(): 获得向客户端输出的二进制流
- void setContentLength(int len):设置响应数据的长度
- void setContentType(String type):向客户端输出数据之前应先调用此方法设置响应流中的数据类型,然后才能调用getWriter或getOutputStream方法获取响应流
- void setCharacterEncoding(String enc):设置响应流中的字符编码
setContentType方法的参数值
- setContentType方法的type参数是一个MIME格式的字串,用于设定响应的数据类型为文本、图像、应用程序等类型。MIME格式串由"类型/子类"组成,对于响应的类型,常见的MIME取值如下:
- text/html[;charset=charEncoding]
- 向客户端回应的是HTML文档,其编码由charset参数指定。如果省略charset指定,将采用默认的编码。
- 说明:如果客户端回应的内容含有中文,且采用JDK自带的编译器进行编译(编译时不指定编码类型),则需要利用charset参数指定文本编码类型为GBK或GB2312,或UTF-8,这些编码将在后续论述。
-
image/<img_type>
-
向客户端返回图片,其中<img_type>指定图片的类型。例:
- image/jpeg:图片类型为jpeg类型
- image/gif:图片类型为gif类型
-
application/<application_type>
-
向客户端返回相应的程序文档,其中<application_type>指定程序文档的类型。例:
- application/msword:word文档类型
- application/vnd.ms-excel:excel文档类型
(3)设置响应流的文本数据编码
- ServletResponse接口提供了以下方法用于设置响应流中的文本编码,主要用于解决中输出文本的中文问题: void setCharacterEncoding(String enc);
- 此方法类似于setContentType,也应在获取响应流之前调用;也可以仅调用setContentType方法,将其type参数的实参设置为"text/html;charset=具体文本编码",代替该方法的调用。
setCharacterCoding支持的编码
-
setCharacterEncoding方法的enc参数设置不正确,将会导致输出到浏览器等客户端UA的响应流中的文本出现乱码。以下是常见的enc参数的取值(该参数值不区分大小写):
- "UTF-8":国际通用字符编码标准,可支持各种语言
- "GB2312":中国国家语言标准编码,如果出现中文问题,可将EncodingCode参数设为此值。
- "GBK":国标扩展编码,含GB2312中的常见汉字编码及一些难检汉字,利用此编码同样可以解决汉字乱码问题。
- "ISO-8859-1":是Servlet默认的编码,此编码不支持中文
(4)Servlet输出的一般流程
-
设置服务器端HTTP响应的数据类型MIME值
- 需要注意,对于HTTP的一次响应,只能设置一种MIME值
- 输出数据的MIME类型多为TEXT/HTML文本
- 得到PrintWriter或ServletOuputStream响应流对象
-
利用响应流对象输出数据到客户端UA
- 对于浏览器UA,一般是通过PrintWriter响应流输出HTML标记代码
-
关闭输出流对象
- 一般应采用try…finally语句块管理输出流对象,以保证其正确关闭
(5)Servlet回应示例代码片段
@Override
protected void doGet(HttpServletRequest req,HttpServletResponse resp) throws java.io.Exception,javax.servlet.ServletException{ resp.setContentType("text/html;charset=utf-8");
java.io.PrintWriter out=resp.getWriter();
try{
out.print("<html><head><title>输出示例</title></head>");
out.print("<body><h1>Hi!这是一个Servlet输出!</h1></body></html>
}finally{
out.close(); //最好在PrintWriter对象的输出结束后,在finally语句块中将其关闭 }
}
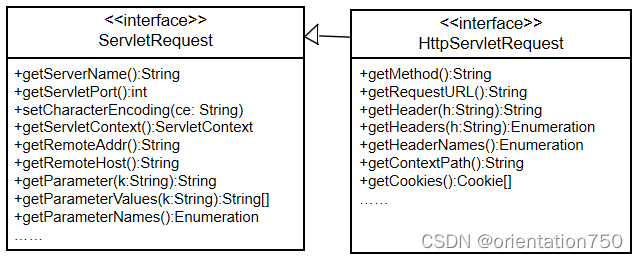
2.HttpServletRequest接口
- HttpServletRequest接口继承了通用的ServletRequest接口,用于封装HTTP协议的客户端请求相关的内容,利用此接口可取得用户的输入,也可取得客户的配置。
(1)HTTP请求行的读取
- 请求行中的信息主要通过下列方法来获得:
- HttpServletRequest接口
- String getMethod():返回"get"、"post"等请求的方式
- String getServletPath():获得对请求的Servlet的路径名
- String getRequestURL():获取整个请求的URL
- ServletRequest接口
- String getProtocol():返回URL中采用的通信协议
- String getServerName():获取服务器名称
- int getServerPort():获取服务器端口号
- String getContextPath():获取Web应用的上下文路径
(2)HTTP请求头信息的读取
- 请求头信息可由HttpServletRequest接口中的如下方法获取:
- Enumeration getHeadNames()
- 取得http协议请求头中相关的项目的名称,并将这些名称存放在类型为Enumeration类型的变量中。之后可通过调用此变量的hasMoreElements()方法取得相应的项目名称
- String getHeader(String name)
- 取得http协议请求头中name参数所指定的项目的值。可与getHeadNames搭配使用。
getHeader方法中name参数的取值
- 当UA为浏览器时,getHeader方法中的name参数常见的取值如下所示:
- "accept":此值可让方法返回浏览器收数据的MIME类型,如image/gif, application/msword等。
- "accept-language":此值将使方法返回浏览器采用的语言类型名称,如zh-cn。
- "user-agent":该值将使方法返回浏览器具体的版本标识。
- "host":此值将使方法返回服务器所在的主机名称。
getHeaderNames/getHeader示例
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException,
ServletException {
response.setContentType("text/html");
try(PrintWriter out = response.getWriter()){
Enumeration e = request.getHeaderNames();
while (e.hasMoreElements()) {
String name = (String)e.nextElement();
String value = request.getHeader(name);
out.println(name + " = " + value);
}
}
}
(3)客户机信息的读取
- 客户机相关信息的读取可由ServletRequese接口中的以下方法进行获取:
- String getRemoteAddr(): 取得客户机的IP地址
- String getRemoteHost(): 取得客户机的主机名称
二、表单/超链中的数据获取
- HTML表单中的控件和超链是Web程序的用户界面中人机互动的重要界面组件,表单控件和超链都可用于将客户端特定的数据传输给Servlet。
- 表单传输的是其中用户界面组件中存储的输入信息。例如文本框、单选/多选按钮,是Web程序中数据输入的主要方式。
- 超链传输的数据主要以查询字符串的方式传递给Servlet。
1.表单/超链的数据定义
- 表单的action属性所指向的Servlet一般应为相对URI,其中需要传递数据的控件都定义其name属性值,例:
<form action="login">
<input type="text" name="uid">
<!--提交按钮没有name属性,其值"确定"不会被提交-->
<input type="submit" value="确定">
</form>
- 超链的href属性取值类似于表单的action属性,后面通过查询字符串传递给Servlet数据,例:
<a href="login?uid=admin">管理员操作</a>
2.表单/超链中数据的获取
- ServletRequest接口中以下方法用于读取表单/查询字串中的数据:
- Enumeration getParameterNames():该方法返回表单/查询字串中的name属性的集合。对于Enumeration集合中数据的取出,可以参考前面的getHeaderNames示例。
- String getParameter(String key):该方法取得表单/查询字串中和key对应的值。注意,该方法返回的数据均为String类型,可使用Java中的类型转换转化为其他类型。
- String[] getParameterValues(String key):该方法取得表单/查询字串中同名key对应的所有数据,返回类型为String型数组。
(1)设置数据编码解决中文乱码
- ServletRequest接口提供了如下方法,进行数据编码的设定:
- void setCharacterEncoding(String enc)
- 该方法和ServletResponse接口中的同名方法类似, 其中enc参数取值也和前述同名方法一致,用于设置接收参数的编码类型。
- 该方法主要用于解决中表单数据中的中文问题,但要注意和传入参数之间的一致性,以及和其他方法之间的调用次序。
setCharacterEncoding调用规则
- 该方法中的enc参数取值必须要和HTTP协议中传入的参数编码要一致,否则还会引起参数乱码。
- setCharacterEncoding调用必须要早于调用getParameter或者getParameterValues方法,否则不能解决获取参数的乱码问题。
- 对于不同的Servlet容器,该方法一般只对采用post方式提交的表单数据起作用;对于采用get方式提交的查询字符串/表单数据有可能不起作用。(对Tomcat5.x及以后的版本,需要在server.xml中设定Connector标记的URIEncoding属性为特定编码,例如utf-8,才能避免get方式提交的参数的乱码问题。)
(2)获取表单/超链数据的代码示例
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setContentType("text/html;charset=utf-8"); request.setCharacterEncoding("utf-8");
try(PrintWriter out = response.getWriter()){
out.println("<html><head><title>Servlet</title></head><body>"); out.println("<h3>你好 , ");
out.println(request.getParameter("uid"));
out.println("</h3></body></html>);
}
}
(3)表单传输数据的注意事项
- 当表单中具有相同的name属性控件,或具有多选性质的下拉列表控件时,可以使用getParameterValues方法获取这些提交的同名控件的value值或下拉列表的选择值。
- 当表单中包含多个同名提交按钮,用户点击其中某个按钮提交表单数据时,此时在getParameter方法中传入提交按钮名称,可以获取到用户点击的提交按钮的value值。
- 表单中类型为多选或者单选的控件,只有被选中且具有name属性设定的多选/单选按钮的value才会被提交。
- 当表单中包含由文件上传组件时,不能使用getParameter等方法获取表单中提交的数据。
3.表单中的文件上传
- 用于上传文件的表单应保证将enctype和method属性设为下值:
enctype:必须设定该属性值为multipart/form-data
method:必须设定该属性值为post
例:
<form enctype="multipart/form-data" method="post" action="upload">
<input type="file" name="fname"/>
<!—其他表单组件定义省略-->
<input type="submit" value="上传"/>
</form>
(1)Common Fileupload类库
- 如前所述,HttpServletRequest接口并未提供读出此类表单数据的方法,开发者可借助Servlet3.0规范提供的API或第三方类库读取上传的文件和其他表单数据。
- Common Fileupload是应用较多的文件上传库,适用于运行在各种Servlet规范的容器中的Web应用程序。
- 该类库属于Apache的Commons项目中的子项目,它依赖于该项目中另一个子项目Common IO,使用时需要包含这两个项目中的所有类库。
- 可在http://commons.apache.org找到对应的项目及需要下载的压缩文件。
处理上传文件的两种方法
- Common Fileupload处理上传文件的方式有两种:
- 文件或内存模式:通过指定内存的上限大小,超过该上限,则Common Fileupload将上传的文件写入一个临时文件,供Web程序读入;否则将上传的数据直接放到内存中,供Web程序读取。
- 流式模式(Streaming model):直接把文件上传形成的数据流交给Web程序处理,这种模式由于不用生成临时文件,因此效率高,占用服务器内存少
- 流式模式要求必须要及时读入数据流,否则Fileupload组件会丢弃掉已处理完的数据流,并将流数据置为null值。
- 推荐使用流式模式处理上传数据。
流式处理的过程
- 检查数据是否合乎W3C组织规定的文件上传格式:
- ServletFileupload.isMultipartContent(request) 检查请求对象中数据的格式,为真返回true。
- 解析上传的数据,将每个数据项按照流式数据取出:
- ServletFileupload up=new ServletFileupload();
- FileItemIterator iter=up.getItemIterator(request);
- 对iter中包含的数据流进行处理
处理文本字段的数据项
while(iter.hasNext()){
FileItemStream item=iter.next();
String name=item.getFieldName(); //表单控件名称
InputStream is=item.openStream(); //打开数据流
if(item.isFormField()){ //处理普通的表单字段
String value=Streams.asString(item);
//其他代码
}else{
//按照输入流来处理流式数据。
}
}
处理上传文件的数据流
//假设输入流对象名称为is,输出流对象名为os
int SIZE=1024; //缓存大小,此处为1K
byte[] buf=new byte[SIZE]; //缓存数组
for(int b=is.read(buf);b>=;b=is.read(buf)){
//处理读到的缓存数组中的数据
//比如写入到输出流对象中
os.write(buf,0,b);
}
os.close(); //关闭输出流,保存写入的数据
(2)使用@MultipartConfig
- Servlet 3.0及以上规范在javax.servlet.annotation包中提供了@MultipartConfig类级注解,使用该注解标注的Servlet可通过doPost中请求参数的getPart/getParts方法接受上传的文件流。
- @MultipartConfig注解包含以下可选参数:
- fileSizeThreshold int型,用于指定文件的最小尺寸,默认为0
- location String型,指定存放生成文件的目录,默认为""
- maxFileSize long型,文件最大值,默认为-1,没有限制
- maxRequestSize long型,请求最大值,默认为-1,没有限制
@MultipartConfig示例
@javax.servlet.annotation.MultipartConfig
@javax.servlet.annotation.WebServlet("/upload")
public class UploadServlet extends HttpServlet {
protected void doPost(javax.servlet.http.HttpServletRequest request, javax.servlet.http.HttpServletResponse response) throws ServletException, IOException {
//利用request参数处理上传请求
}
@MultipartConfig中的请求处理
- 使用@MultiipartConfig标注的Servlet的doPost方法中,请求参数中的如下方法可以用于读取表单中的数据:
- getParameter/getParameterValues方法依旧可以用于取出非文件上传组件提交的文本数据。
- getParts方法可以按照文件上传设置的multipart方式取出所有的表单中数据,包括文件上传组件。
- 使用getPart方法,可以取出上传表单中对应名称的组件中的数据,对于文件上传组件,可以使用得到的Part对象的getInputStream方法获取上传的文件流对象。
getParts和getPart方法
- 在javax.servlet.http.HttpServletRequest接口中,getParts和getPart方法声明如下:
- java.util.Collection<javax.servlet.http.Part> getParts(); 获取表单中的所有的控件元素信息,可以通过遍历结果集合,得到Part接口对象
- javax.servlet.http.Part getPart(String fileCtrlName); 通过给出上传表单中指定名称的控件元素名称,获取Part接口对象
Part接口中的常用方法
- 在javax.servlet.http.Part接口中,可以使用如下方法处理上传数据:
- void delete() 删除所有上传数据
- String getContentType() 返回上传数据的MIME类型
- InputStream getInputStream() 获取文件上传流
- String getName() 获取控件名称
- long getSize() 获取文件的上传尺寸
- String getSubmittedFileName() 获取上传的文件名
- void write(String fileName) 按fileName直接写入上传的文件
三、页面重定向导航
- Servlet在处理UA的请求之后,使用文本响应流输出处理结果页面的HTML标记代码相对比较麻烦。
- Servlet提供了用于简化Servlet在处理请求后生成结果页面的HTTP重定向功能的实现,其工作流程如下:
- Servlet不再直接生成响应数据流,而是发送给UA一个以3开头的响应码,并在响应头中加入特定页面的URL
- UA接到该响应码后,将自动转到响应头中指定页面的URL
- HTTP重定向需要UA的识别和支持,目前,大部分浏览器都支持该功能。
- 通过HTTP重定向,就可以实现UA端自动的页面跳转,即页面导航(Page Navigation) 。
1.利用sendRedirect重定向
- HttpServletResponse接口中的sendRedirect()方法实现了UA的重定向,具体的声明如下:
- void sendRedirect(String redirectURL) redirectURL参数指明要转入的URL,可以使相对URL,也可以是绝对URL
- sendRedirect方法一经调用,将向浏览器发出一个重新连接服务器URL的指令,而重新连接的URL就是redirectURL
- 使用sendRedirect方法时,一定要保证该方法在向客户端进行输出之前调用,否则不能起到重定向作用
- 在sendRedirect调用之后,容器一般会结束Servlet的代码的执行,所以,应保证sendRedirect是处理请求的最后一行代码。
避免重定向时的相对URI错误
- 重定向时,采用相对于上下文路径的页面URI有时会导致UA进入到错误的URL。此时可使用相对于主机的URI避免这个问题,即构造如下形式的URI:
- Web程序部署的上下文路径可由HttpServletRequest接口中的getContextPath方法获取,该方法的声明如下:
- String getContextPath()
- 该方法返回以"/"开头的当前Web程序部署的上下路径。注意,当Web程序被部署为根应用时,该返回返回一个空的字符串。
sendRedirect示例代码片段
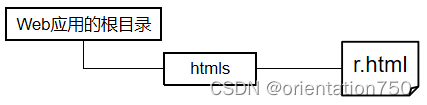
- 以下代码片段演示了Servlet将用户请求处理完成后,自动让浏览器将用户导航到下图的r.html页面:
String uri=request.getContextPath()+"/htmls/r.html";
response.sendRedirect(uri); //上述代码也可以采用相对上下文路径的uri,即: //response.sendRedirect("htmls/r.html");
//但有时会出现错误,取决于当前Servlet的url-pattern映射。
2.通过HTML头标记重定向
- sendRedirect无法在重定向之前向UA传输一些提示文本。如果需要此功能,可以先重定向到一个中间HTML页面,该页面的head元素中加入如下标记的定义:
<meta http-equiv="Refresh"
content="refreshSeconds;URL=url">
- 该标记可让浏览器在加载该页面refreshSeconds时间之后,自动转向url所指向的网页,实现在重定向之前显示提示信息。
- 注意,此标记代码中的refreshSeconds代表时间,单位为秒,url代表需要转向的地址,此处可以使相对或绝对url。
- 当省略refreshSeconds后的分号部分时,将重新加载该页面。
3.利用响应头进行重定向
- 也可以通过当前Servlet生成一个提示信息页面,并使用HttpServletResponse中的setHeader方法设置此页面的响应头信息,实现类似于meta元素的重定向功能,见下代码片段:
//设置请求头,5秒后自动重定向到r.html页面 resp.setHeader("Refresh","5;URL=htmls/r.html"); resp.setContentType("text/html;charset=utf-8");
try(java.io.PrintWriter out=resp.getWriter()){
out.print("<html><body><h3>处理完毕!请稍候…</h3>");
out.print("<a href=htmls/r.html>点此</a>直接转入</body>");
}
第五章 会话管理和应用程序对象
一、Cookie技术
- 为了提高http协议的服务效率,http被设计成无状态性协议
- 无状态性是指服务器不记录与之相连接的客户端的相关信息,如客户的连接持续时间、客户上一次的登录时间等信息
- 无状态特性提高了Web服务器的服务能力,使得Web服务器可以对更多的客户进行服务
- 无状态特性使得维护在线用户信息变得非常困难
- 解决无状态特性带来的问题可以使用Cookie技术。
客户端持有技术
- 为了达到能够利用http协议传输数据,同时又能记录客户端的状态,可在客户端记录相应的状态,然后将相应的状态信息放在http协议的请求头中传送给Web服务器,这种技术称之为客户端持有技术(cookie)
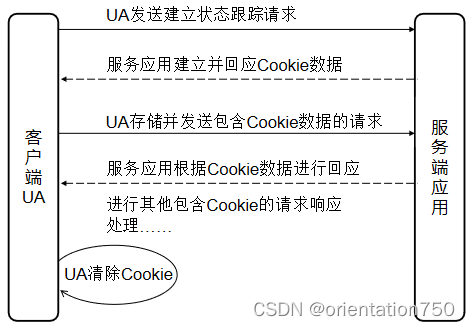
1.Cookie技术原理
- Cookie是一种文本数据,由服务器端产生,发送到客户端之后,由UA存储在客户机当中。
- Cookie的内容具有一定的格式规定,这种规定被称为Cookie规范,最早由网景公司(NetScape)制定。
- 当UA存储了来自于服务端的Cookie数据后,每次请求时都会自动将相应的Cookie信息传递给服务器,从而维护用户信息。
- Cookie技术需要UA的支持,当使用浏览器作为UA时,可以通过相关的设置开启/关闭对Cookie的支持。
Cookie技术原理图
2.在服务器端创建Cookie
- Servlet提供了Cookie类来封装服务器端Cookie数据的产生。
- Cookie类的主要成员及方法:
- public Cookie(String cookieName, String value)
- Cookie类的构造方法,其中cookieName指定了在客户端生成的cookie名称,value参数指定了该cookie存储的数据。
setVersion和getVersion方法
- public void setVersion(int ver)
- 设置cookie的版本号,其中ver可取:
- 0 cookie的最初版本,是目前被浏览器普遍实现的一个cookie版本,建议采用此版本
- 1 cookie的较高版本,符合RFC 2109规范,但并不是所有的浏览器都支持该版本。如果网站面向Internet而非内部网,不推荐采用该规范
- public int getVersion()
Cookie的名/值对
- 按Cookie的规范,一个cookie只能存储一个值,这样,一个cookie只有一个名字,且只有一个值与之对应,这样就构成了cookie的名/值对
setValue和getValue方法
- public void setValue(String val)
- public String getValue()
- 获取cookie中通过setValue方法存储的值
setPath和getPath方法
- public void setPath(String path)
- 默认情况下,cookie文件在服务器端只能被当前路径和网页及以下路径和网页读取,而setPath方法可改变这种设置
- 例:setPath(“/”),将cookie设置成根路径,则此cookie对当前主机下所有的Servlet都可见
- public String getPath()
setMaxAge和getMaxAge方法
- public void setMaxAge(int expiry)
- 设置cookie的过期时间,其中expiry单位为秒。
- 当expiry值为正值时,指明该cookie存活的秒数
- 当expiry值为0时,指明将在浏览器端删除该cookie
- 当expiry值为负值时,指明该cookie将在浏览器关闭时删除
- public int getMaxAge()
3.将Cookie传递给客户
- addCookie方法在HttpServletResponse接口中定义:
- public void addCookie(Cookie cookie)
- addCookie方法向客户端UA添加cookie,当调用此方法时,将在如果UA为客户端计算机上的浏览器,则会在相应的目录中生成cookie文件。
4.从客户端的请求中读取Cookie
- getCookies方法在HttpServletRequest接口中定义,其声明形式如下:
- public Cookie[] getCookies() 从客户端取出所有的cookie,将这些cookie放在一个数组中返回给调用者。
5.删除Cookie
- 删除Cookie意味着消除客户端存储的服务器信息,服务器端可以为客户端生成同名的Cookie,同时将其最大存活时间设置为0,然后向客户端UA发送该Cookie。一但客户端收到这个Cookie,将自动删除其存储的Cookie数据。
cookie应用实例
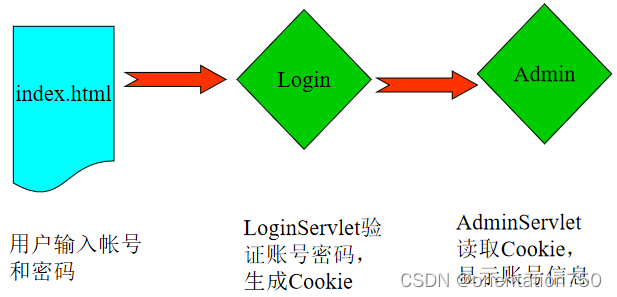
- 本示例利用一个HTML表单,提示用户输入帐号和密码,如果输入的帐号和密码正确,则在浏览器端生成一个cookie,该cookie中记录了用户此次登录的帐号,随后将用户转到另一个名为AdminServlet的Servlet,该Servlet检索浏览器端所有的cookie,并在这些cookie中找出相应的记录着用户帐号的cookie,显示该用户的登录成功信息。
二、会话对象
- Servlet提供了HttpSession接口,利用HttpSession接口的实例,即会话对象,可代替Cookie类实例实现会话跟踪。容器会为每一个客户端UA自动生成对应会话对象,可用于存储对应UA的专有数据,并且数据类型不像Cookie那样仅限于文本数据。
- 当UA支持Cookie时,容器将通过一个名为"JSESSIONID"的Cookie存储客户端UA的唯一标识,建立对应UA的会话对象;当客户端UA不提供Cookie支持时,容器还可以通过URL重写的机制,在回应的URL中加入UA标识,建立会话对象。
1.会话对象的建立
- HttpServletRequest接口中定义了getSession方法:
- public HttpSession getSession(boolean bCreateNewSession)
- 该方法可获得当前用户的正在使用的会话,如果当前用户没有对应的HttpSession对象,当bCreateNewSession参数为true时,该方法会自动创建一个新的HttpSesion对象;取false时,该方法会在用户会话不存在时,返回null值。
- public HttpSession getSession() 该方法是上述方法的重载版本,相当于bCreateNewSession参数取值为true
2.新建会话对象及会话Id的判定
- public boolean isNew() 测定当前的HttpSession是否是一个新创建的
- Session public String getId() 此方法返回当前会话的标识,每个会话都有一个唯一的标识
3.得到会话对象创建及访问时间
- public long getCreationTime()
- 此方法返回会话的创建时间,该时间表示从1970年1月1日午夜(格林威治时间)到会话创建时逝去的毫秒数。如果要得到以年月日形式所表示的时间,可将此时间传递给Date类的构造方法。
- public long getLastAccessedTime()
- 此方法返回最后一次从客户机发送此会话的时间,其返回数值的含义与getCreationTime方法的返回值含义相同。
4.利用会话对象处理UA专有数据
- public void setAttribute(String key, Object value) 将相应的数据存入HttpSession对象中,其中:
- key参数指定了存入对象的标识,以后可利用此标识检索存入的数据。
- value参数指定了存入对象的实际内容
获得和删除会话对象中的存储数据
- public Object getAttribute(String key) 检索会话中key参数指定的数据。此数据由setAttribute方法存入到HttpSession对象中。如果与key相应的数据不存在,则该方法返回null值。
- public void removeAttribute(String key) 该方法删除存放到HttpSession对象中的数据,其中key参数指定了要删除数据的标识
5.设置会话对象的存活时间
- public setMaxInactiveInterval(int second) 该方法设置如果用户没有相应的活动,当前会话的失效时间。如果second如负值,则此会话将永不超时
- public int getMaxInactiveInterval() 该方法返回通过setMaxInactiveInterval设置的会话超时的秒数
- public void invalidate() 该方法使得会话无效,并解除所有与当前会话相关联的数据
三、应用程序对象
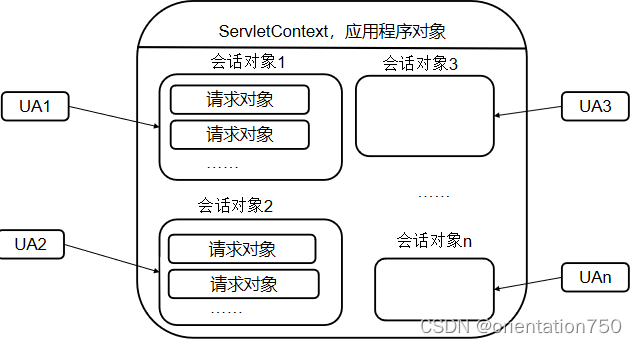
- 不同的客户可能会在同一时间对Web应用程序进行请求,这要求在处理用户请求时,要处理多线程并发访问问题。
- Servlet API提供了两个对象提供了避免多线程并发访问:
- HttpServletRequest,即请求对象,该对象仅存在于一次请求之间,可用于存储客户端需要传递的一些数据。
- HttpSession,即会话对象,该对象的生存时间长于请求对象,可用于对应客户端在会话期间的数据存储。
- 请求和会话对象只能存储特定的用户数据,如果需要针对所有的用户存储全局性数据,同时避免多线程问题,可以采用Servlet API提供的应用程序对象。
请求、会话和应用程序对象示意
1.应用程序对象的获取
- 应用程序对象代表部署到容器中的Web应用程序,它的类型为javax.servlet.ServletContext接口,其实例由容器建立。
- 可以在doGet等Servlet方法中调用继承自父类GenericServlet的getServletContext方法得到应用程序对象,也可以通过请求参数或会话对象得到其实例。例如,设doGet方法中的请求参数名为request,获取应用程序对象的代码示例如下:
- ServletContext application=getServletContext(); application=request.getSession().getServletContext();
- 通常情况下,一个Web应用程序仅对应于一个应用程序对象,所以应用程序对象中可以存储程序中的全局性数据。
2.应用程序对象中数据的存取
- 应用程序对象、会话对象、请求对象都提供了相同调用格式的setAttribute和getAttribute方法,用于其中数据的存储和取出:
- public void setAttribute(String key,Object value);
- public Object getAttribute(String key);
- 应用程序对象还提供了getAttributeNames方法,该方法返回所有存入数据的key名称的枚举集合,用于搜索对象中所有的数据存储数据:
- public Enumeration getAttributeNames();
3.通过应用程序对象传递请求数据
- Servlet有时需要启动另一Servlet并向其传递当前请求中的数据,此时可以使用javax.servlet.RequestDispatcher接口的实例,启动目标Servlet并向其传递当前请求以及请求中的数据。
- 例如,LoginServlet验证完用户的登录信息后,在当前的请求对象中存入用户信息,并通过RequestDispatcherd对象将请求传递给AdminServlet进行进一步处理,如下图所示:
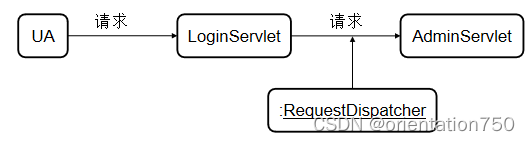
获取RequestDispatcher对象
- 应用程序对象提供了获取RequestDispatcher对象两个方法:
public RequestDispatcher getNamedDispatcher(
String servletName );
该方法通过web.xml中的servlet-name元素或Servlet注解中定义的Servlet名称,获取请求转发RequestDispatcher对象。
public RequestDispatcher getRequestDispatcher(
String path);
该方法通过指定服务器中path路径代表的页面名称或Servlet的URI,获取请求转发RequestDispatcher对象。
通过请求转发对象启动目标Servlet
- RequestDispatcher接口中的forward和include方法的参数完全一致,都可用于启动目标Servlet或页面并传递请求对象,其中forward方法的声明格式如下:
public void forward (ServletRequest request,
ServletResponse response)
throws ServletException,IOException;
- forward方法执行后,目标Servlet或页面的输出将替代当前的Servlet输出,而include方法执行后,目标Servlet或页面的输出将嵌入到当前Servlet的输出当中。
Servlet之间转发请求数据的示例:
@Override
public void doGet(HttpSevletRequest request,HttpServletResponse response) throws IOException,ServletException{
//其他代码省略
request.setAttribute("user","admin");
//getServletContext方法继承自父类GenericServlet
ServletContext application=getServletContext();
/*将当前的请求转发给AdminServlet,并将请求中的"user"数据传递给该Servlet。*/ application.getNamedDispatcher("AdminServlet").forward(request,response);
}
4.获取Web程序实际部署目录
- 应用程序对象提供的getRealPath方法可用于获取当前Web应用程序部署在容器之后,指定其中的资源所处的实际文件夹:
- public String getRealPath (String uri);
- 该方法的uri参数表示相对于Web应用程序根目录的资源URI,应以"/"作为开始字符,返回该资源实际所处的目录。例如以下方法调用返回整个Web程序所处的目录:
- getServletContext().getRealPath("/");
- 需要注意的是,如果Web程序采用非解压的WAR文件方式部署,则该方法将返回null值。
5.获取Web程序资源所在URL
- 应用程序对象提供的getResource方法可用于获取当前Web应用程序部署在容器之后,其中的资源文件所处的位置:
- public java.net.URL getResource(String uri);
- 该方法类似于getRealPath方法,但返回的是uri对应资源的URL格式描述。另外,即便Web程序采用非解压的WAR文件方式部署,则该方法也将返回一个确定的URL值而非null值。
- 例:以下方法调用表达式,同样也可以返回Web应用程序部署的实际目录位置,而不受Web程序部署方式的影响:
- getServletContext().getResource("/").getPath();
6.获取Web程序中资源输入流
- 应用程序对象提供的getResourceAsStream方法可用于获取当前Web应用程序中资源的数据输入流:
- public InputStream getResourceAsStream(String uri);
- 该方法类似于getResource方法,但返回的是uri对应资源的数据输入流。同样,即便Web程序采用非解压的WAR文件方式部署,则该方法也将返回正确的数据流。
- 在得到资源的数据流之后,可以根据需要读取流中的数据进行处理。
7.获取Servlet容器的版本信息
- 应用程序对象中的getServletInfo方法可用于获取当前Web应用程序部署所在容器的版本信息:
- public String getServletInfo();
- 该方法返回类似于"服务器名称/版本号"格式的信息,例如,在Tomcat中,该方法返回的值可能是"Apache Tomcat/9.0.36"。
第六章 JSP基础
- JSP技术是将特定的将Java代码嵌入到HTML网页代码中,再由JSP引擎将这些代码转换成Servlet代码,从而解决了Servlet输出网页需要大量的println代码的不足。
一、JSP的特点
- JSP源文件由html代码和java代码混合组成,其扩展名为.jsp
- JSP源文件一般应位于Web应用程序中相应的html页面的目录中(在NetBeans项目中,jsp源文件所在的目录应是web子文件夹)
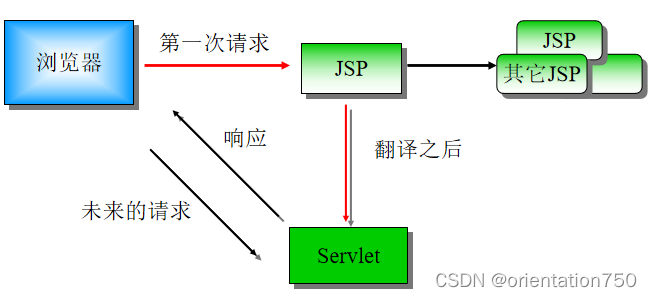
- JSP源文件在用户对其进行第一次访问时,JSP/Servlet容器将对其进行自动编译,生成相应的Servlet代码,这一过程较为费时
- JSP源文件一经编译,以后用户对于该JSP页面的访问都将转至编译后的Servlet来处理,所以页面的响应速度会大大加快
- 利用相关技术(JavaBean、自定义标签库),结合Servlet,JSP可以将Java代码同html代码相分离,从而适合于做Web应用程序的表示层
- JSP技术是Servlet技术的简化,同时又增加了许多新的特性。JSP技术拥有自己的规范,目前的被广发使用的标准是JSP1.2和JSP2.0,目前,JSP2.1及其修订版JSP2.2和JSP2.3也已经发布。
JSP页面编译过程

JSP页面的请求过程
二、JSP的组成元素

1.模板文本
- 模板文本又称为静态html代码,此类代码可以通过任何html编辑器生成,如Frontpage,Dreamweaver等工具,模板文本就是标准的HTML代码
- 模板文本会由编译生成的Servlet通过out.println语句向客户端原样输出
JSP注释与模板文本
- JSP文件中可以插入相应注释,这些注释不会影响到JSP文件的编译与执行。JSP注释有两种:
- 发送给客户端浏览器的html代码中的注释,即在模板文本中加入的注释,其格式与标准的HTML代码中注释的格式相同 格式:<!—注释内容-->
- 用于注释JSP代码本身的功用,不会发送至客户端浏览器 格式:<%--注释内容-- % >
2.JSP编译指令
- JSP编译指令在编译时执行,是为了告诉引擎如何处理当前的JSP页面。这类指令的格式为:
- 主要包括:
- include指令
- page指令
- taglib指令
(1)include指令
- < %@include file=“url”%>
- 该指令指示JSP/Servlet引擎在编译该JSP文件时,将include指令中指定文件插入到该JSP文件中一起进行编译。所以被包含文件中的模板文本最好不要有HTML中<html></html>
include指令的file参数
- file参数指定的url标明了所要包含的文件的路径。它可以是绝对url,也可以是相对url 。
- 以“/”开头的url属于绝对url,即表明此包含文件的路径相对于web应用程序根目录。(在NetBeans项目中对应于web目录)
- 以文件名或目录开头的url属于相对url,即表明此url相对于当前的JSP文件所在的目录
- 可以把JSP文件以内容为分类标准,存放于不同的目录下。然后在需要的时候将相应的页面(如公司的标志页面、版权声明等页面)用include指令进行包含,可降低页面的维护的工作量
(2)page指令
- 该指令用于定义JSP文件的全局属性。该语法为:<%@page attribute=“value”%>
- 其中的attribute可以为:
- language=“语言名称”
- 指定JSP文件中能够采用的语言的种类,目前只能用“java”.
- extends=“父类名称”
- 指明生成的Servlet的父类。但是使用它可能会限制JSP的编译能力,一般无需设定该属性;其缺省值为HttpJspBase。
attibute的取值
- 以下的属性除import外都只能用一次。
- import=“java包名称”
- session=“true|false”
- 设定在JSP中是否使用HttpSession,默认值为true。
- isThreadSafe=“true|false”。
- 取true时,该JSP页面将使用Servlet的多线程模式,否则使用Servlet的单线程模式。默认为true
- info=“文本信息”
- 一旦设定文本。该文本能够使用Servlet.getServletInfo()取回。
- errorPage、isErrorPage设置出错页和是否作为其他JSP页面的出错页。
- buffer=“none|sizekb”
- 指定JSP页面是否使用缓存区存储向浏览器输出的网页内容,默认为8kb
- autoFlush=“true|false”
- 指定当页面缓存区存储的内容溢出时,是否自动将缓存区内容发送到客户端浏览器,默认为true.
- contentType=“mimeType[;charset=字符集]”
- 指定JSP文件的mime类型及所属的字符集,默认的类型是text/html,字符集为iso-8859-1
- pageEncoding=“字符集”
- 指定JSP文件的存储格式字符集,默认为iso-8859-1
(3)taglib指令
- taglib指令用于定义JSP文件中的自定义标签,此指令将在“JSTL”一节中进行介绍
3.JSP声明指令
- 格式:<%!Java声明语句%>
- 注意事项
- 该语句可用于定义变量、方法、或类。在JSP编译成Servlet后,会被相应地编译成该Servlet类中的属性(即字段)、方法或内部类,因此这些变量、方法或类可以被该JSP页面的其它Java语句所使用。
- Java声明语句如果是定义字段,则必须以“;”结尾,且可以有多个字段声明语句,每个声明语句以“;”隔开
- Java声明语句定义的变量、方法或类仅在当前的JSP页面中有效。
4.JSP表达式
- 格式:<%=表达式%>
- 注意事项:
- 表达式末尾无需分号
- 表达式可以是任何合法的Java表达式,但该表达式一定要有返回值。
5.脚本片段
- 格式为:<%scriptlet%>
- 注意事项:
- 利用脚本片段可在JSP网页中插入较多的Java代码
- JSP/Servlet引擎将脚本片段中的Java代码转换到一个名为_jspService的方法中,并且在Servlet的service方法中对_jspService方法进行调用
- 脚本片段中的Java代码中不能出现方法的定义,但可以定义类。
三、JSP隐含对象
- JSP为了方便编程人员,内置了request、response、out、session、application、config、page 、 pageContext、exception 9个对象。这些对象可不经定义直接在JSP表达式或脚本片段中使用。
1.隐含对象的作用范围
- 隐含对象只能在JSP页面的表达式和脚本代码片断中使用。有时候,我们要跨越页面传递数据,为了方便,这些隐含对象中,有一部分对象提供了类似于前面介绍的会话对象的setAttribute/getAttribute方法用于数据的存储和取出。
- 不同的隐含对象在存储了数据之后,这些数据可以使用的范围是不相同的,有的仅能在本页面中取出使用;而有的则可以在同一个用户的会话中使用,这种隐含对象中存储的数据的使用的范围称之为“作用范围”
(1)页面作用域(Page)
- 具有此作用域的对象可在创建该对象的页面范围内使用,直到该JSP页面完成响应或请求被转移到其他网页
- Page作用域的隐含对象中存储的数据仅在当前JSP页面中有效,不能传递到其他JSP页面。
(2)请求作用域(request)
- 具有此作用域的对象可在处理该请求的网页中使用。一旦该请求被处理,则该对象被释放。
- request作用域相当于JSP页面转换成Servlet类中的service方法中request参数的作用域。所以具有request作用域的对象中存储的数据可以在同一次请求中经过的JSP页面和Servlet中共享(同一次请求,经过多个JSP页面或Servlet将在后续章节中介绍)
(3)session作用域
- 具有此作用域的对象中存储的数据可以用于所有处理该会话的请求的JSP网页。
- Session作用域相当于JSP转换为Servlet后的会话对象(HttpSession)的作用域。即处于此作用域的对象可应用于该Web应用程序中所有JSP页面和Servlet类。但该对象只对当前会话有效
(4)application作用域
- 具有此作用域的对象作用于该web应用程序中所有的JSP网页。
- application作用域相当于ServletContext对象的作用范围。具有application作用域的对象与session作用域对象的不同之处在于session作用域对象仅作用于当前会话,而application作用域对象对Web应用程序中所有的会话都是有效的
2.隐含对象
-
(1)request对象:
- 它实际上就是HttpServletRequest的实例。该对象中可以存储数据,而这些数据的作用域为request.
-
(2)response对象:
- 它实际上就是javax.servlet.HttpServlet Response的实例。在JSP中只是用它来设置相应的状态码和相应头。
-
(3)out对象:
- 是javax.servlet.jsp.JspWriter的实例。该类是java.io.printWriter的子类。并具有输出缓冲特性。JSP中用来输出真正的相应数据。
-
(4)session对象:
- 是javax.servlet.HttpSession的实例,因此只用于Http协议。要使用该对象,必须使用JSP page指令将session打开。作用域为session.
-
(5)application对象:
- 它是javax.servlet.servletContext的实例。在Servlet中可以通过getServletConfig().getContext()得到。其作用域为application.
-
(6)config对象:
- 它是javax.servlet.servletConfig的实例。在Servlet中可以通过getServletConfig() 得到。该对象中存储了由web.xml中指定一些配置信息。
-
(7)pageContext对象:
- 是java.servlet.jsp.PageContext的实例,用于存取所有与JSP程序执行时期所需要用到的属性。其作用域为Page.
-
(8)page对象:
- 是java.lang.Object的实例。当脚本片段使用JAVA时,该对象就是“this”的同义词。.
-
(9)exception对象:
- 是java.lang.Throwable的实例。该对象只能在出错页中使用。
四、JSP操作指令
- 该指令使用xml语法结构相同的action来控制Servlet引擎的行为。
- 与编译指令(<%@指令名称%>)不同的是,操作指令是在响应请求的时候动态执行的。
1.jsp:include指令
格式一:
<jsp:include page=“url|<%=expression%>”
flush=“true”/>(指令结束)
格式二:
< jsp:include page=“url|<%=expression%>”
flush=“true”>
<jsp:param name=“ ” value=“”/>
……(可以定义若干个参数名-值传递给包含文件)
</jsp:include>(指令结束)
jsp:include指令说明
- 该指令用于在响应请求时动态的包含一个文件。Page指定该文件的url。
- 一个该指令用于包含一个改动频繁的文件。而<@include file=“”>用于包含一个改动很少的文件,因为<@include file=“”>包含方式只有重新编译以后才能生效。
2.jsp:forward
格式一:
<jsp:forward page=“url|<%=expression%>”
flush=“true”/>(指令结束)
格式二:
< jsp: forward page=“url|<%=expression%>”
flush=“true”>
<jsp:param name=“ ” value=“”/>
……
(可定义若干个参数名-值对传递给重定向后的文件
</jsp: forward >(指令结束)
jsp:forward指令说明
- 该指令用于将请求重定向到一个html、JSP或者是一个能处理request对象的如ASP、CGI、PHP等程序。重定向后原JSP页中剩下的程序段将不被执行。
- 在重定向前不能有输出,否则会有异常。重定向时如果缓冲区中有数据,缓冲区中的数据将被清除。
3.jsp:plugin指令
- Applet是Java重要的客户端活动网页技术。但Applet的正常执行依赖于浏览器内置的Java虚拟及的版本号。
- 为了解决客户端Applet正常执行所需的Java虚拟机问题,Sun公司提供了一个Java的插件,该插件能够自动侦测Applet所需的Java虚拟机,如果客户端浏览器的Java虚拟机不能满足要求,可提示用户到指定的URL下载相应的虚拟机
- jsp:plugin指令可以在客户端自动生成所有这些与Applet相关的指令
jsp:plugin语法
<jsp:plugin Arributename=“Arributevalue”>
Arributname可取:
- Type=“bean|applet”必须指定是bean还是applet。
- Code=“”指定被Java插件使用的Java类名。
- Codebase=“”指明Code指定的文件的路径。
- Name=“”指明这个Bean|Applet实例的名字,以供JSP的其他地方的调用。
- Nspluginurl和iepluginurl分别指明Natscape Navigator和IE用户下载JRE的地址。
- <jsp:param>和<jsp:fallback>分别用于向Bean|Applet传递参数和JAVA插件不能启动时显示给用户的。
jsp:useBean指令
- 该指令指示JSP页面使用指定的JavaBean,有关JavaBean的概念和相关使用方法将在JavaBean一节详细说明
五、JSP指令的xml语法
- xml语言源于html,而JSP页面也是html形式的页面。为了便用以统一的方式处理jsp和html文件,所有的JSP指令都有相对应的xml语法格式
- JSP的xml语法格式在JSP1.2的规范中引入,早期的JSP规范不支持xml
- 在同一JSP文件中,xml语法格式不能和相应的传统的语法格式混合使用
- xml语言是大小写敏感语言,JSP指令的xml语法都是以小写的英文字母构成,大小写混用会导致编译错误
1.声明指令的xml语法
<jsp:declaration>
Java的变量、方法及类的声明语句
</jsp:declaration>
例:
<jsp:declaration>
int i=0;
int max(int a,int b){ return a>b?a:b;}
class A{ int attrib1;}
</jsp:declaration>
2.编译指令的xml语法
<jsp:directive.<指令名称>
attribName=attribVal
/>
- 上述<指令名称>可以是:
- 注意:taglib没有对应的xml指令形式
(1)page指令xml语法举例
例1:
<jsp:directive.page
import= “java.io.*,java.util.*”
/>
例2:
<jsp:directive.page
language=“java” pageEncoding=“GBK”
/>
(2)include指令xml语法举例
例1:
<jsp:directive.include
file= “relativePage.jsp”
/>
例2:
<jsp:directive.include
file=“/absoultePage.jsp”
/>
3.JSP表达式的xml语法
<jsp:expression>
Java表达式;
</jsp:expression>
例:
<jsp:expression>
out.println(“Hello,world”);
</jsp:expression>
4.脚本片段的xml语法
<jsp:scriptlet>
Java代码片段
</jsp:scriptlet>
例:
<jsp:scriptlet>
String str=“XML Format”;
out.println(str);
</jsp:scriptlet>
第七章 JavaBean的应用
一、JavaBean概述
- JavaBeans是Java语言引入的组件模型,这个模型通过JavaBean组件大大扩充了用Java语言开发软件的可复用性。开发者可以通过集成已经开发完成的JavaBean组件来建立自己的应用程序。省去了大量的重复劳动。
开发语言的演进
面对组件的程序设计
- 面向组件的程序设计是一种软件构件模型,本身不限于某种特定的语言。
- 特点:用组件组成应用程序,各个组件可组合成各种应用程序,从而大大提高的软件的复用性
- 主要组件模型:
- JavaBean(Sun提出,仅能由Java实现)
- COM(Component Object Model,微软提出,不限于语言,VB、VC、Pascal、Java均可实现COM模型)
- DCOM,分布式COM,将COM组件模型推广到网络应用上
- EJB,分布式Java组件模型,将JavaBean模型进一步演化,形成可满足大型应用的Java组件
二、JavaBean模型
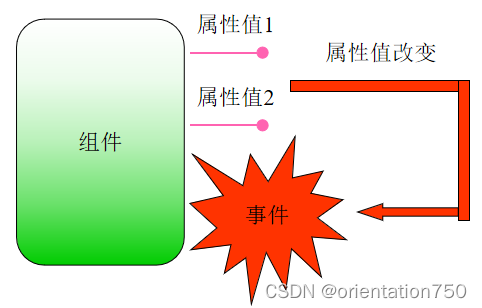
- 基于组件模型的编程模式最为主要的两个概念包括:
- 属性
- 用于程序对组件特性的访问。对属性的改变会直接影响到组件的外观或行为的改变。如:设定一个按钮组件的caption属性时,按钮的标题文本将自动反映caption改变后的值
- 事件
- 当组件的属性发生改变时,有可能引发组件内部其它属性或其它组件的相关属性随之发生改变。这种改变将自动的发送给指定的接收者,这种由属性的改变而引发的通知被称为事件
1.JavaBean的属性
- JavaBean就是一个特殊的Java类,实例化该Java类后,可以按访问实例中相应的属性的形式访问相应的JavaBean中的属性。但这些属性在类中对应着一系列的getXxx和setXxx方法,当设置这些属性值时,相应的getXxx或setXxx方法就会被调用,从而实现了组件模型中的属性的概念。
(1)Simple属性
- Simple属性定义了一对get和set方法,用于获取和设置该属性的值。get和set方法对应着Bean类中定义一个私有变量,该变量名与getXxx或setXxx中Xxx相对应。请注意在getXxx或setXxx中,Xxx中第一个字母要大写,而私有变量的名字第一个字母要小写。
Simple属性举例
public class Demo extends Component{
public Demo(){}
private String title =“Hello”;
public void setTitle(String title){
this.title=title;
}
public string getTitle(){return this.title;}
}
(2)Indexed属性
- 一个Indexed属性表示一个数组值。同样使用set/get方法用于设置。不过可以设置两对方法用来处理整个数组的值和数组元素的值。
Indexed属性举例
public class Demo extends Canvas{
private String title[];
public Demo(){}
public void setTitle(String title[]){this.title=title; }
public void setTitle(String value,int index){
this.title[index]=value;
}
public string getTitle(){return this.title;}
public String getTitle(int index){
return this.title[index];}
}
(3)Bound属性
- 一个Bound属性是指当该属性的值发生改变时,就激活一个PropertyChange事件,在该事件中封装了被改变的属性名、属性的原值、属性变化后的值。
(4)Constrained属性
- 当这个属性的值发生变化时,与这个属性已建立了某种连接的其他Java对象可否决属性值的改变。
2.可视化Bean与不可视化Bean
- 可视化Bean可以表示为一个简单的GUI。可以是按钮组件、游标、菜单等。本章主要讨论非可视化Bean的用法。非可视化Bean可以用于封装数据库连接、进行简单的逻辑运算等功能。它体现了java语言的封装特性和可移植性。非可视化Bean的属性主要是前两种,而第三、四主要用于让可视化Bean与开发环境交互
3.JavaBean的类定义
- JavaBean的类定义中必须要有一个不带参数的公有构造方法,否则不能利用<jsp:useBean>进行正常初始化。
- 在非可视化的JavaBean,最为常用的是simple属性,即由setter/getter组成的方法对。
4.jsp:useBean指令
- 在网页中使用JavaBean类之前,要使用import引入类的命名空间。该指令用于在JSP网页中加载JavaBean类以供使用。该指令有两种格式:
格式一:
<jsp:useBean
id=“variantname”
scope=“page|request|session|application”
class=“classname”
type=“typename”
beanName=“beanName”/>
格式二:
<jsp:useBean
id=“variantname”
scope=“page|request|session|application”
class=“classname”
type=“typename”
beanname=“beanName”>
body
</jsp:useBean>
- 如果对应的JavaBean的实例没有被建立,则body中的代码在Bean实例被建立的时候执行,否则body中的代码不会得到执行
- 该指令在JSP页面加载JavaBean的加载过程如下:
- 1.通过classname和scope查找一个Bean.
- 2.定义id指定的变量,其类型为typename.
- 3.如果发现Bean,则将这个Bean的一个引用存储在id中。如果没发现,则从classname中实例化一个Bean的对象,并把它保存在id中。并通过BeanName指定了Bean名,同时该Bean被java.beans.Beans.instantiate方法实例化,最后实例化得到的实例将赋给id指定的变量。
- 注意:
- 1、body体是在Bean实例化的时候执行的,而不是在赋值的时候。
- 2、在加载模式中,classname用来指定查找Bean时使用的类名,beanname用来指定实例化Bean时使用的类名。
- 使用useBean指令后就可以通过id指定的变量名在scope指定的范围内来使用这个Bean类中的公共方法和属性.如id.getXXX()等。
- scope各个值的意义为:
- Page:能在当前网页以及当前网页中的所有静态包含文件中(即<%@include file=url%>的方式)使用该Bean.直到当前网页被关闭为止。
- request:能在执行相同请求的JSP文件中使用该Bean,直到向客户端发回请求为止。在这之中,可以使用request.getArribute(“id指定的变量名”)来使用该Bean.
- session:能在使用相同session的JSP文件中使用该Bean.必须在创建该Bean的JSP文件中的<%@page%>中指定session=“true”.
- application:从创建Bean开始就可以在同一web应用程序内的JSP文件中使用该Bean.
5.jsp:setProperty指令
<jsp:setProperty name="beanId" property="属性名" value="值"|param="值"/>
- 该指令用于向指定ID的bean实例中的属性赋值,其中name参数为<jsp:useBean>中的定义的bean组件的id;property参数指定bean中要设置的属性名,而value或param参数提供要设置的值。 value可以用表达式来指定属性值,而param则是用request中的值来进行指定;两个参数不能同时使用。
- 当property取值为“*”时,则将request的所有参数与Bean的各个属性名进行匹配,如果某一个匹配不上,则该属性值将不被改变,但这不影响其他属性值的匹配和改变
6.jsp:getProperty
<jsp:getProperty name="beanID" property="值" />
- 该指令的作用与在scriptlet中使用get方法一样。同样,该指令实现了封装性。
- 指令用于获取指定Bean中指定属性名的值,并将之自动转化为字符串型,并将其插入到out对象中。使用前也必须将name值用useBean指令定义过。
7.在脚本片段中使用JavaBean
- 除了在HTML标记中使用<jsp:getProperty/>和<jsp:setProperty/>标记调用JavaBean之外,还可以直接在脚本片段中直接使用JavaBean。可以直接在脚本片段中使用由<jsp:useBean id="bean标识" class="bean类名"/>标记中id参数规定的bean标识作为脚本片段中类型为bean类的变量名。
在脚本片段中使用JavaBean示例
<jsp:useBean id=“myBean” class=“demo.Bean”>
<%
//此处的myBean变量名无需预先定义
myBean.setI(5);
%>
<jsp:setProperty>中的中文问题
- 使用<jsp:setProperty name="beanId" property="*"/> 或<jsp:setProperty name="beanId" property="属性名" param="参数名"/>标记从表单中获取数据时,要注意中文问题。在Tomcat中,解决的方案推荐为:
- 页面编码设置为utf-8
- 将表单的提交方式设置为post
- 在使用<jsp:setProperty>标记前,使用 <%request.setCharacterEncoding("utf-8")%>
第八章 MVC设计架构
一、Java Web编程原则
- 在Java的Web编程中,应该把Web相关的类看成是完成系统功能的用户接口,而实现具体功能时,代码要和Web类无关。按此要求,应遵守以下原则:
- 在JSP中Java代码和HTM尽量分离
- 在JSP不处理具体操作,JSP只负责结果的显示
- Servlet负责用户流程转换
- JavaBean用来处理具体业务处理
1.JSP中Java代码和HTML代码尽量分离
- 在JSP网页中,如果嵌入了大量的Java代码,会使得HTML代码和Java代码混合在一起,JSP网页难以直接通过网页编辑工具直接编辑和察看,维护工作难以进行。
2.JSP只负责结果显示
- 由于JSP本身和HTML代码十分接近,所以非常适合做Web程序的显示层,而实践证明,JSP最好的用法就是用以显示用户界面和处理结果。如果在JSP中加入了大量的用户处理逻辑或数据库访问代码,会使得Web应用程序整体混乱,架构不清,难以重用和维护
3.Servlet负责用户流程转换
- 在Web程序中,Servlet多用来进行针对不同级别的用户进行其数据检验和登录JSP页面转发,这样Servlet就可以和JSP相互合作,有利于JSP中的代码简化。
4.JavaBean负责业务处理
- JavaBean非常适合与网站的具体业务逻辑操作,所以,在JavaBean中处理诸如数据库访问、邮件的发送、文件的上传等任务非常合适,可以有效地减少在JSP和Servlet中的代码,有利于整个网站系统的模块化设计
二、Web中的Model 1模型
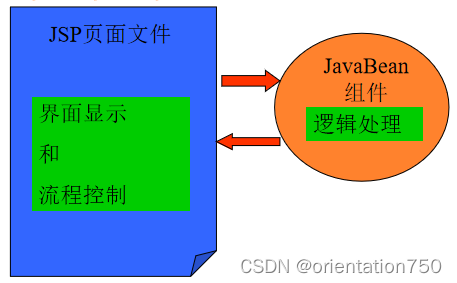
- 为了尽量的简化JSP网页中的Java代码,SUN公司提出了Model 1模型,该模型中使用了JavaBean来简化JSP的复杂程度。
1.JSP和JavaBean的分工
- 在Model 1中,JSP主要负责:
- JavaBean主要负责
- 底层信息访问,如数据库访问、邮件发送等
- 网站的商业流程处理
Model 1模型示意图
2.Model 1的优缺点
- 优点:
- 减少了JSP网页中的Java代码,将一些底层的代码和业务逻辑移到了Bean代码中
- 便于开发时的错误查找和调试
- 系统小巧简洁
- 缺点:
- JSP负责流程控制,有些代码书写不便
- 系统分层不是非常彻底,不便于大型网站的开发
三、Web中的Model 2模型
- 为了克服在Model 1中的缺点,SUN公司在MVC模型的基础上提出了Model2模型,在这种模型中加入了Servlet,用于流程控制,进一步分离了JSP页面中的Java代码和HTML代码。
1.Model2和MVC模型
- MVC模型代表模型-视图-控制,是应用在一些大型工程中的数据建模方式
- M代表Model,指的是负责处理数据的模型,在Model2中,JavaBean即为Model,负责处理网站的底层数据访问(如数据库、电子邮件等等)和业务逻辑
- V代表View,即显示在用户面前的界面,Model2中的JSP网页即负责用户界面的显示
- C代表Controller,负责控制用户操作流程,Model2中的Servlet即为控制用户的操作在页面之间的流转
2.Model2组成部分间的配合
- Servlet是控制器,用户登录网站首先与它进行交互。Servlet检查用户登录是否合法以及用户的身份等信息,然后调用相应的JavaBean处理用户的具体请求,之后将包含有处理结果的JavaBean实例转发给指定JSP网页,通过将用户转入到相应的JSP网页完成任务
Model 2模型示意图

3.Servlet向JSP页面的转发
- Servlet一般通过HttpRequest接口中定义的getRequestDispatcher(String destPage)方法进行流程控制。该方法返回一个RequestDispatcher类型的对象,通过调用该对象的forwad方法,即可将用户转发到destPage参数所指定的JSP页面中
- 一般在转发前,Servlet均会依据用户的请求建立对应的JavaBean对象,然后再将用户发转到指定的JSP网页
Servlet代码中页面转发示例
//需要转入的目标JSP页面
destPage=“success.jsp”;
//处理数据,并将产生的结果变量存入到request中,以供jsp显示用
SomeBean bean=new SomeBean();
//bean方法的调用
request.setAttribute(“key”,bean);
//获取转发对象
RequestDispatcher dispatcher= request.getRequestDispatcher(destPage);
//进行转发
dispatcher.forward(request,response);
forward方法和sendRedirect区别
- RequestDispathcer的forward和HttpServletResponse的sendRedirect都可用于用户的流程控制,但两者有着很大的区别:
- sendRedirect是客户端的转发,而forward是服务器端的转发
- sendRedirect转发的URL对于客户端浏览器来说是可见的,而forward转发的URL不可见
- forward在转发的同时保留了用户提交的请求,而sendRedirect只是将用户重新定向到了一个新的URl,不保留用户在转发前提交的请求数据
4.Servlet和JSP共享数据
- Servlet和JSP共享数据主要通过JavaBean的实例进行,在Servlet代码中可以动态建立相应的JavaBean的实例,然后将其放入不同作用域的Web变量中,即可让JSP在不同的范围内共享JavaBean实例中的数据
(1)request范围内共享数据
SomeBean bean=new SomeBean();
request.setAttribute("key",bean);
- 然后,Servlet将用户发送到具有如下代码的JSP中:
<jsp:useBean id="key" class="SomeBean"
scope="request"/>
(2)session范围内共享数据
SomeBean bean=new SomeBean();
HttpSession session=request.getSession(true);
session.setAttribute(“key”,bean);
- 然后,Servlet将用户发送到具有如下代码的JSP中:
<jsp:useBean id="key" class="SomeBean"
scope="session"/>
(3)application范围内共享数据
Servlet中的代码片断如下:
SomeBean bean=new SomeBean();
getServletContext().setAttribute("key", bean);
然后,Servlet将用户发送到具有如下代码的JSP中:
<jsp:useBean id="key" class="SomeBean"
scope="application"/>
第九章 JSP2.0表达式
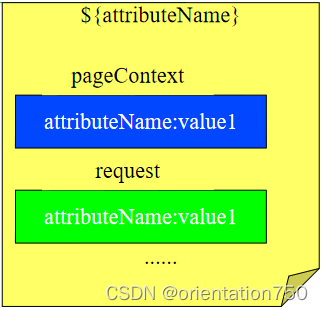
JSP2.0表达式概述:
- 在JSP2.0规范中,JSP页面可以使用一种以"${属性名}"表达式,可以方便地输出在pageContext、request、session、application等隐含对象中以名/值对形式存储的数据
一、表达式的语法
- 语法:${表达式}
- 表达式可以是合法的Java变量名,也可以是 “变量名.属性名”(不含引号)的形式
- 只能在JSP页面中的模板中使用
- 不要在JSP的代码标记<%%>中使用
- 输出值:
- 按照pageContext->request->session-> application的次序寻找对应的属性名的属性值,找到则输出该值,找不到,则没有输出
1.使用方法
- 调用pageContext、request、session、application等对象的setAttribute("key",value)方法存入数据
- 在JSP页面的HTML标记中,使用:
- ${key}输出普通数据
- ${key.attribute}输出JavaBean的某个属性值
表达式示例
<%
pageContext.setAttribute("msg","Welcome!-page");
session.setAttribute("msg","Welcome!-session");
%>
<html>
<body>
${msg}
</body>
</html>
2.指定取值范围
- 默认情况下,Web容器按照页面->请求->会话->应用程序对象的次序寻找表达式中的属性值,如果希望在指定的对象中寻找属性,可以使用如下语法:
- ${ xxxScope["属性名"] }
- xxx可以为page、request、session或application
- 方括号中的属性名必须用单引号或双引号括起来
3.特殊名称的表达式
- 如果属性名中包含有小数点,此时必须使用范围限制的方式,否则将不会得到正确的输出,因为这时属性的名称会和JavaBean的属性相混淆。
指定表达式求值范围的示例
<%
pageContext.setAttribute("p.msg","Welcome-page"); session.setAttribute("s.msg","Welcome-session");
%>
<html>
<body>
${sessionScope['s.msg']}
</body>
</html>
4.数组表达式
- 如果表达式中的属性名对应的数据是数组,则可以用类似于Java的语法表示数组中的某个元素,例如:
<% String[] users=new String[2]{"wa","jv"};
request.setAttribute("users",users);%>
<html><body>
请求对象中存储的第一用户是${users[0]}
</body></html>
二、2.0表达式和JavaBean
<jsp:getProperty name="bean名称"
property="属性名"/>
${bean名称.属性名}
- 对比可见,2.0的表达式大大地简化了JavaBean中属性值的输出
1. 2.0表达式中JavaBean使用
<jsp:useBean id="bean名" class="类名"/>
也可利用其他方式生成JavaBean实例,参见前面的JavaBean一章
${bean名.属性名} 或
${bean名['属性名']}-其中的单引号也可以换成双引号
2.JavaBean表达式动态属性
- 采用${bean名称['属性名'] }的语法可以使用另一个表达式代替中括号中的属性:
<% session.setAttribute("prop","name");
//beans.User为一个符合JavaBean规范的类
session.setAttribute("user",
new beans.User());
%>
${user[prop]}等价于 ${user['name']}
3.用Map代替JavaBean
- 可以使用Map接口的实现类代替JavaBean,这样可以避免使用JavaBean时都要预先在Web程序中定义对应的类文件,同时还具有动态添加属性的优点。
- 常用java.util包中的以下类代替JavaBean:
- HashMap
- Properties
- TreeMap
使用Map代替JavaBean示例
<%
java.util.HashMap user=new java.util.HashMap();
//为user添加一个名为name的属性,值为wang
user.put("name","wang");
request.setAttribute("user",user);
%>
<html><body>
${user['name']}或${user.name}
</body></html>
三、2.0表达式中的内置对象
- JSP2.0表达式中还可以使用一些内置的对象简化JSP1.2中的一些功能,这些内置对象的使用语法和JavaBean表达式相同,形式为:
- 主要包括:
- header和headerValues,param和paramValues
- cookie
- initParam和范围对象,如pageScope等
1.header和headerValues
- 用于取出请求头中各个数据项:
- header取出的值是一个字符串
- headerValues取出的是一个数组
<html><body>
示例: 浏览器类型:${ header['user-agent'] }<br>
可处理的文件类型:${ headerValues['accept'][0] }
</body></html>
2.param和paramValues
- 用于提取用户通过get方式提交的url中的查询参数值或post方式提交的表单中的控件值。
- 示例:
<html><body>
你传入的数据是:username=${ param['username'] }
<br>
选择的第一项课程是:${ paramValues['course'][0] }
</body></html>
3.cookie
- 用于取出浏览器传递给服务器的某个指定名称的cookie,可以通过该cookie的value、maxAge、path等属性取出其中存储的数据。
- 示例:
<html><body>
浏览器传递的会话cookie中的数据是: ${ cookie['JSESSIONID'].value }<br>
过期时间是:${ cookie['JSESSIONID'].maxAge}
</body></html>
4.initParam
- 通过initParam可以读取在web.xml文件通过<context-param>标记存储的上下文参数值,此标记在web.xml中的格式如下:
<context-param>
<param-name>p1</param-name>
<param-value>v1</param-value>
</context-param>
initParam示例
- 假设某个Web应用程序的web.xml中定义的上下文参数代码片断如下:
<context-param>
<param-name>db</param-name>
<param-value>/WEB-INF/db.prop</param-value>
</context-param>
${initParam['db']}
5.范围对象
- 范围对象的用法在前面已经论述,值得注意的是,如果某个JavaBean或Map对象存储在某个作用域中时,可以使用这样的语法在给定范围内取出其个属性中存储的值(假设给对象存储的范围是session,对象存储名为user,该对象含有一个名为name的属性):
${sessionScope['user'].name}
第十章 Web应用中的错误处理
一、页面不能正常显示的原因
- 引起Web程序中的页面不能正常显示的原因分成两大类:
- 用户请求的资源由于安全或其它原因不能被访问,HTTP协议为此定义了相应错误代码。
- 由于在Servlet或JSP网页执行时产生的异常而使得相应的页面不能显示。
- 对于上述的页面错误,Web服务器会使用特定的页面显示错误的原因。
常见的HTTP错误代码
- HTTP错误代码为4xx或5xx,其中:
- 4xx代表由客户端产生的错误
- 5xx代表服务器端产生的错误
- 500 内部错误 — 因为意外情况,服务器不能完成请求。
- 503 无法获得服务 — 由于临时过载或维护,服务器无法处理请求。
二、HTTP错误定制处理
- Web应用程序也可使用web.xml自定义出现错误时的处理页面。对于HTTP错误,可在web.xml文件中指定<error-page>标记,如下所示:
<error-page>
<error-code>Error Code</error-code>
<location>ErrorPage URI</location>
</error-page>
1.利用静态HTML网页处理错误代码
- 利用静态的HTML网页显示错误非常简单,只要根据其响应的HTTP错误编码,预先做好响应的内容即可
- 利用静态网页响应错误的不便之处在于对应每个HTTP错误代码,都要预先做好相应的网页。另外,由于不能得到具体的错误原因,其内容也只能根据错误代码的含义显示一些一般性错误信息
2.利用Servlet/JSP处理错误代码
- 可以利用一个Servlet或者JSP页面来响应多个HTTP错误代码,这样可以减少静态页面的制作数量。
- 使用这种方法时,Servlet或JSP均可使用存储在请求对象中的特定的属性获取错误的原因
请求对象中的存储错误的属性
- javax.servlet.error.status_code
- 该属性包含了产生错误的HTTP协议代码,其类型为java.lang.Integer
- javax.sevlet.error.message
- 该属性包含了出错的具体原因,类型为java.lang.String
- Servlet或JSP页面可以通过调用HttpServletRequest接口对象的getAttribute(“属性名”)方法获取这两个属性的值
三、Web程序异常处理
- 在Web程序中,如果没有用try...catch异常处理语句捕捉异常实例,Web容器将负责处理异常:
- 如果是检查异常,将根据异常的性质产生对应的HTTP错误代码,通常为500或503
- 如果是运行时刻异常,将产生404错误,以后对于该应用程序其他的动态页面或Servlet请求都将被标记为“不可用”
定制异常处理页面
- 由于Web容器自动将应用程序中的异常转换为对应的HTTP错误代码,所以,也将用内置的页面显示这些错误信息
- 可以在JSP或Servlet中定制这些错误信息的显示
1.JSP网页的错误处理
- JSP网页可以指定其Error Page,这种Error Page在该JSP页面抛出异常时会被JSP引擎自动调用,并传递给该错误处理页面一个exception对象。通过检索该对象,出错页面就可以向用户显示错误的原因。
JSP错误页面的指定
- 指定某个JSP页面的错误处理页面,可以用如下JSP指令:
<%@page errorPage=“出错处理页面URL”%>
- 在错误处理页面中,用如下指令声明自身为错误处理页面:
<%@page isErrorPage=“true”%>
2.Servlet中的异常处理
- 在Servlet中出现异常时,可在web.xml中指定<error-page>进行处理
- 在web.xml中指定异常处理方式有如下好处:
- 在web.xml指定的异常处理方式属于整个web程序的错误处理,并不局限于某个特定的Servlet。
- 利用这种异常处理方式可以使得Web程序以一种统一的方式在不同的服务器中显示出错信息
<error-page>中的<exception-type>属性
- <exception-type>用于标识响应异常的类型。其格式如下:
<error-page>
<exception-type>
异常类的全名
</exception-type>
<location>
异常响应页面或Servlet的URI
</location>
<error-page>
- 指定了该元素后,在Servlet运行时如果发生了对应的异常,则<location>中规定的异常响应页或Servlet将被JSP引擎自动调用,同时通过HttpServletRequest接口传递给该Servlet或JSP相应记录着异常具体情况的一些属性
JSP引擎传递的错误属性
- javax.servlet.error.status_code:
- javax.servlet.error.exception:
- 该属性包含servlet抛出异常类的实例,通过检索该属性的相应getMessage()方法,可以得到引发异常的原因
- javax.servlet.error.request_uri:
- 该属性为String类型,包含了出现异常时的servlet正在处理的请求的URI
- javax.servlet.error.servlet_name:
- 该属性为String类型,包含了抛出异常的Servlet名字
- 通过在HttpServletRequest接口检索这些属性,错误处理Servlet或JSP就可以显示具体的出错原因
3.Servlet中常用的异常
- Servlet的doGet和doPost方法中的声明中,抛出了两个异常:
- ServletException
- IOException
- 如果doGet或doPost方法需要抛出其他检查异常,就必须将这些异常转换为这两个异常其中的一个。
- 通常,由于IOException表示输入输出错误,大部分其他异常都要转换为ServletException
- UnavailableException是ServletException的子类,所以,如果需要,其他异常也可以转化为该异常
(1)ServletException
- ServletException,该类为Checked Exception,必须在程序出进行显示的处理,主要的方法有:
- ServletException():
- ServletException(String message):
- 用指定的信息构造ServletException的实例
- ServletException(Throwable rootCause):
- 用一个指定的异常构造ServletException的实例,该构造方法经常用于将应用程序自身产生的异常包装为ServletException。之后,可以通过调用getRootCause()方法返回应用程序自身的异常
- ServletException(String message,Throwable rootCause):
- 用指定的信息和异常类的实例构造一个ServletException实例
(2)UnavailableException
- UnavailableException是ServletException类的子类,该异常意味着Servlet暂时不可用或永久不可用,此时服务器将向用户返回SC_SERVICE_UNAVAILABLE(503)的HTTP状态代码。此异常一般在Servlet的init方法中被抛出,容器将销毁该Servlet,然后过一段时间后重新尝试加载该Servlet实例。主要方法:
- UnavailableException(String msg):
- 用于构造一个描述Servlet永久不可用的原因的UnavailableException类实例,此时该Servlet会被容器销毁。
- UnavailableException(String msg,int seconds):
- 用于构造一个描述Servlet暂时不可用的原因的异常实例,seconds参数指示容器再次构建该Servlet的秒数。在达到seconds秒数之后,容器将重新构建该Servlet的实例。如果难以估计时间,可以直接传递一个负数.
- int getUnavailableSeconds():
- boolean isPermanent():
第十一章 WEB应用程序的数据库访问技术
一、Web程序的数据库连接方式
- Web应用程序主要通过JDBC技术进行数据库访问。建立JDBC连结是访问数据库的第一步,JDBC连结建立的方式有两种:
- 由JDBC驱动管理程序(Driver Manager)直接建立数据库连结
- 通过数据源建立数据库的连接
- 通过Driver Manager连结数据库是普通Java程序常用的建立数据库连结方法,而Web应用程序多通过数据源建立数据库的连结
1.通过Driver Manager直接连接数据库
- Driver Manager加载JDBC驱动程序,建立和数据库之间的连接。连结建立后,通过SQL语句或JDBC的API对数据库中的表进行查询、修改和插入
2.数据库库连结池
- 建立数据库的连接非常耗时。为了减少连接创建时间,可预先建好一定数量的JDBC连接,当应用程序需要访问数据库时,只要获取预先建立的一个连接实例对象就可连结数据库。这种预先建立好的JDBC连接的集合就称为数据库连接池
3.JNDI资源和JDBC数据源
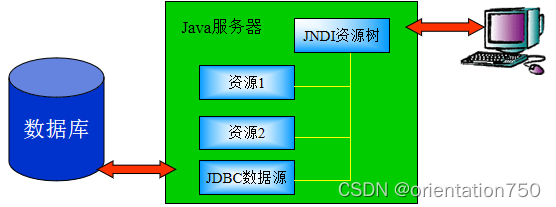
- 连结池程序代码可以自己实现,也可以由Java服务器实现。当利用Java服务器的连结池时,需要利用JNDI服务得到JDBC连结池对象,这种连结池对象就称为JDBC数据源
- JNDI (Java Name Directory Inteface)是SUN为了统一在不同的Java服务器对各种资源的访问而提出的规范。在JNDI中,资源的查找方式非常类似在Windows的目录中查找某个文件。
4.JDBC驱动程序的共享
把JDBC驱动程序的jar文件拷贝到Web程序的WEB-INF/lib目录中可让当前的Web程序通过Driver Manager加载对应的JDBC驱动,但如果其它Web程序需要加载相同的JDBC驱动,都需要在各自的WEB-INF/lib中拷贝相同驱动的jar文件 Java服务器一般都提供让所有的Web程序能够共享相同JDBC驱动程序的设定,但方法并不统一,需要参考特定Java服务器的使用手册。本课程介绍在Tomcat中让所有的Web程序共享JDBC驱动程序和设定JDBC数据源的方法
二、Tomcat中数据库的访问
- 在Tomcat中可以直接通过Driver Manager建立数据库的连结。为了使得数据库的JDBC驱动程序能够被所有Web应用程序共享,Tomcat提供了一个特殊的文件夹,拷贝到这个文件夹下面的JDBC驱动的JAR文件可被所有的Web程序以及Tomcat自身加载。
- Tomcat也提供了利用JNDI服务建立JDBC数据源的功能,该功能可以通过修改其安装目录中的conf文件夹的server.xml文件完成。比较方便的办法是利用Tomcat自身提供的admin实用程序完成
1.Tomcat中JDBC驱动的共享
- 处于Tomcat6.x安装目录的lib目录中的JDBC驱动的jar文件可以被Tomcat和所有的Web应用程序共享
- 如果要使用Tomcat的数据源功能,则必须将JDBC驱动的jar文件拷贝到这个目录
- 如果使用的是JDBC-ODBC桥,则由于该驱动JDK已经自带,所以无需拷贝对应的jar文件
Tomcat6.x中的lib目录
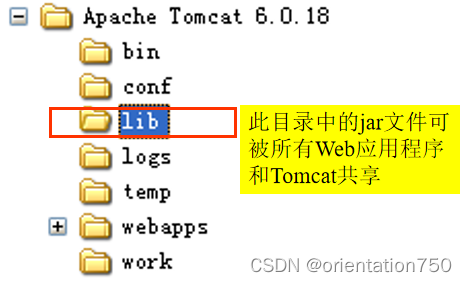
2.通过Driver Manager访问数据库示例
- 为了便于测试,本示例是包含一个index.jsp文件的NetBeans项目,使用JavaDB数据库存储数据。
- JavaDB数据库又称Derby,是Apache组织负责开发和维护的一个纯Java实现的数据库系统软件。JDK自身包括了JavaDB数据库,在NetBeans中也集成有对JavaDB数据库的支持,所以访问JavaDB数据库对于Java程序而言非常方便。
(1)建立JavaDB数据库
(2)建立学生基本信息表
(3)创建Web应用程序项目
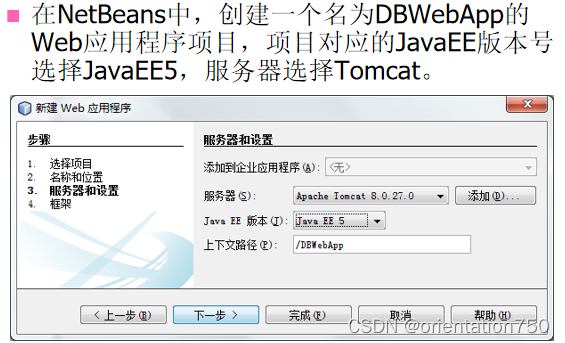
(4)添加JavaDB JDBC驱动
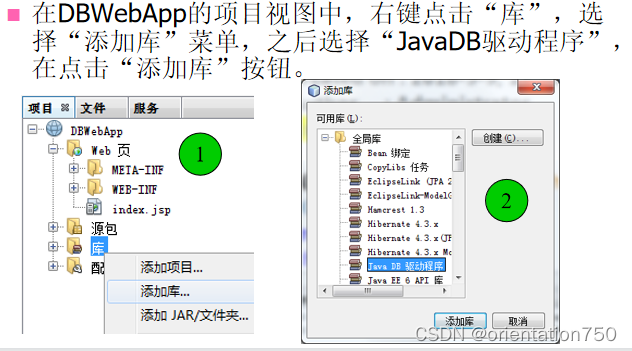
(5)修改JSP页面文件
- 修改项目中的index.jsp文件,修改后的内容如下:
<%--设置页面的编码,以免出现中文乱码--%>
<%@page pageEncoding="utf-8"%>
<%--引入java.sql包,这是JDBC中大多数类型所在的java包--%>
<%@page import="java.sql.*"%>
<html><body>
<%
//数据库访问代码将在此编写…
%>
</body></html>
- 准备在上述脚本片段的注释的下方编写数据访问代码,具体代码见后续页中的内容。
脚本片段中的代码
//数据库连接对象,java.sql.Connection是封装连接数据库功能的接口。
Connection conn=null;
//预编译语句对象,java.sql.PreparedStatement是封装执行SQL的接口, PreparedStatement ps=null;
//结果集对象,java.sql.ResultSet是封装查询SQL的执行结果的接口
ResultSet rs=null;
//用于存储结果集中当前记录指针是否指向有效位置的布尔类型的变量
boolean result=false;
String url="jdbc:derby://localhost:1527/ecdemo" //数据库连接字符串
try{ //用try…catch…finally主要是为了能够正确关闭打开的数据库连结等对象
Class.forName("org.apache.derby.jdbc.ClientDriver"); //加载JDBC驱动程序
conn =DriverManager.getConnection(url,"sa","123456"); //获取数据库连结 ps=conn.prepareStatement("select * from students"); //得到一个在数据库中预编译对象
rs=ps.executeQuery(); //通过预编译对象执行SQL语句,得到数据集对象
result=rs.next(); //首次调用数据集对象的next方法将使数据集中当前指针定位在首记录
if(!result) out.println(“<h3>对不起,目前数据库中尚无数据!”;
else{ //next方法向后移动数据指针,当它的返回值为假时,代表数据集中移到记录尾部
while(true){
out.println("<h3>学号为:"+rs.getInt("id")+"</h3>"
out.println("<h3>学生名称为:"+rs.getString("name")+"</h3>"); //ResultSet的getXxx方法,其中Xxx代表具体的数据类型,它的参数类型为String,代表表中的对应的字段名,返回值和Xxx代表的类型相同,用于取出当前记录的字段值 if(!rs.next()) break;
}
}
}catch(Exception e){
throw new RuntimeException(e.getMessage()); //出现数据库连结不上等错误时抛出运行时刻异常,给出出错原因
}finally{ //finally语句块负责无论在何种情况下均可正确关闭ResultSet、PreparedStatement和Connection对象
try{
rs.close();
System.out.println ("result set is closed");
ps.close();
System.out.println ("prepare statement is closed");
conn.close(); //关闭连结的close方法会抛出异常,所以必须要用try…catch进行处理
System.out.println ("connection is closed");
}catch(Exception ie){System.out.println ("some err is occured:" +ie.getMessage());}
}
finally代码段的作用
- finally代码段时数据库连结代码中必不可少的一部分,它负责在任何条件下程序均可关闭建立好的数据库连结和PreparedStatement对象。如果缺少了该段代码,一旦应用程序遇到了异常,就有可能不能正确关闭数据库连结和PreparedStatement对象,造成内存的泄漏
第十二章 JSTL的应用
JSTL的功能概述
- JSTL是指标准的自定义标记库,它可以完成以下任务:
- 对JSP2.0表达式中的数据进行操作
- 控制页面中的数据流程
- 格式化输出数据
- 处理XML文件
- 访问数据库
一、JSTL的组成
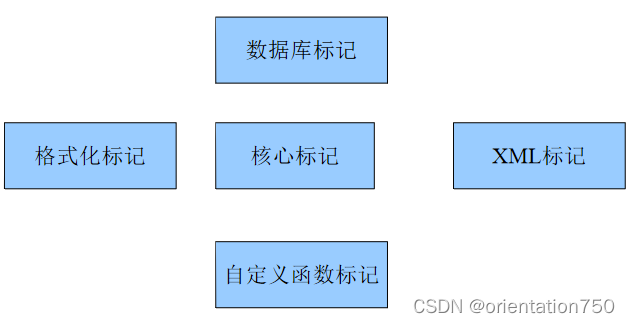
1.核心标记
- 核心标记负责以下功能:
- 数据输出
- 流程控制
- 操作URL
- 数据定义
- 引入文件
2.数据库标记
- 数据库标记负责以下功能:
- 定义数据源
- 执行查询,输出数据
- 插入数据
- 删除数据
- 更新数据
3.其他标记
- 自定义函数标记负责调用自定义函数功能:
- XML标记负责处理XML格式的数据
- 格式化标记负责以给定的格式在页面中输出数据
二、JSTL的下载和配置
- 要使用JSTL,首先必须在Web项目中引入JSTL的类库,JSTL类库可以从如下网址下载: http://java.sun.com/jstl/
- JSTL共有3种版本:
- 1.0版本:适用于JSP1.2规范和J2EE1.3
- 1.1版本:适用于JSP2.0规范和J2EE1.4及以上
- 1.2版本:适用于JSP2.0规范和JavaEE5.0
JSTL类库和TLD文件
- JSTL类库由两个JAR文件组成:
- standard.jar:包含TLD文件和基础功能实现类文件
- jstl.jar:包含扩展功能的类文件
- 将JSTL这两个类库拷贝到Web应用程序的WEB-INF/lib目录中即完成配置。
- 使用NetBeans6.1开发时无需下载JSTL,它自带了JSTL1.1相关的类库文件
在NetBeans中引入JSTL类库
- 在NetBeans的项目的“库”结点上,点击右键,通过图示的3个步骤就可以引入JSTL类库

引入JSTL库后的NetBeans项目
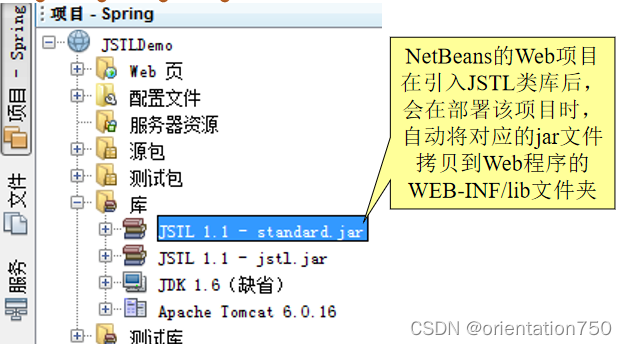
三、核心标记的使用
- 核心标记
- 前缀:本课程以后均用"c”作为核心标记的前缀
- uri:http://java.sun.com/jsp/jstl/core 或 http://java.sun.com/jstl/core_rt
- 引入语法:
<%@taglib
uri=”http://java.sun.com/jsp/jstl/core”
prefix=”c”
%>
1.赋值标记-set
<c:set var="属性名" value="值|表达式"
scope="page|request|session|application"/>
- 作用:将value值按照var指定的属性名存入scope标明的隐含对象中。省略scope时,将存入到pageContext对象中。value的值可以采用JSP1.2(<%=%>)或2.0的表达式
set标记使用示例:
<c:set var="password" value="123456"
scope="request"/>
- 将字符串"123456”以属性名为password存入到request对象中
<c:set var="uname" value=${param['uname']}/>
<c:set var="username" value="${uname}"/>
- 将用户提交给当前页面的uname参数值取出,存入uname属性;然后再将该值以username为属性名存入到页面对象中
2.去除标记-remove
<c:remove var="属性名"
scope="page|request|session|application"/>
- 功能: 在pageContext、request、session或application对象中,去除利用var指定的属性。
3.输出标记-out
<c:out value="值|表达式" escapeXML="true|false"
default="缺省值"/>
- 功能:
- 将value值输出到页面
- 如果excapeXML取true,则对value值中的大于号(<)、引号(")、连字符(&)等字符进行转换,以便在浏览器中能够正常显示这些符号。省略escapeXML属性时,等价于将该属性设置为true
- value值可以是一个JSP1.2或2.0表达式
- default属性用于在value值为null时,指定替代的输出值,该属性为可选
out标记示例:
<c:out value="${cookie['JSESSIONID']}"/>
<% String name="<h3>3号标题</h3>"; %> <c:out value="<%=name%>" />
<c:out value="${user}" default="未定义的值"/>
- 输出JSP2.0表达式的值,如果该值为null,则输出"未定义的值"
4.条件判定标记-if
<c:if test="${逻辑判定表达式}" >
输出内容
</c:if>
- 功能:当逻辑判定表达式的值返回true、或不为null、不等于0时,则显示标记间的输出内容。否则不显示没有输出内容
test属性取值中的关系运算符
- 在if标记中的可用的关系运算符包括:
- 大于(>)或gt
- 小于(<)或lt
- 大于等于(>=)或ge
- 小于等于(<=)或le
- 等于(==)或eq
- 不等(!=)或ne
if标记中数据的比较
- JSP2.0表达式中的数据只有三种类型:
- 字符串类型
- 常量字符串用单引号或双引号包围其中的字符
- 字符串顺次按照其中字符的Unicode编码比较
- 数值类型
- 逻辑类型
- 常量用true和false表示,true>false
if标记中不同数据类型之间比较
- 字符串和数值比较时,全部转换为数值类型;字符串不能转换为数值类型时将出现错误。
- 字符串和逻辑类类型比较时,全部转换为字符串类型数据后比较
- 数值类型和逻辑类型之间不能比较
if标记中关系运算符示例
<%
request.setAttribute("a","3");
%>
<c:if test="${a > 13}">a<13</c:if>
<c:if test="${a gt '13'}"> a>'13'</c:if>
<c:if test="${false gt true}"> false!</c:if>
<c:if test=‘${''a" > true}’>a!</c:if>
test属性取值中的逻辑运算符
- 在if标记中的逻辑判定表达式中,还可以通过逻辑运算符将关系运算式连接起来,构成逻辑判定式。这些逻辑运算符按照优先级排列如下:
- 逻辑否(not)或!
- 逻辑与(and)或&&
- 逻辑或(or)或||
- 使用这些运算符时,利用圆括号可以改变逻辑运算符的组合和优先级
if标记中逻辑运算符示例
<%
request.setAttribute("a","3");
pageContext.setAttribute("b","5");
%>
<c:if test="${a > 13 or b eq '5'}">OK!</c:if>
<c:if test="${a>'13' and (b !=5)}">Wrong!</c:if>
if标记中的empty运算符
- empty用于探测表达式是否为null或空字符串。
- 例:
<%session.setAttribute("b",param[“b”]);%>
<c:if test="${empty a}">a is null</c:if>
<c:if test="${not empty b}">b is not null</c:if>
相当于:
<% String b=request.getParameter(“b”);
if(b==null||b.length()==0){%>
b is null
<%}%>
if标记和算术运算符
- JSP2.0表达式中,对数值型表达式可以使用算术运算符进行运算,这些运算符包括:
- 乘(*)、除(/或div)、加(+)、减(-)、求余(%或mod)
- 可以转换为数值类型的字符串和数值之间也可以进行上述运算。
- if标记中,算数运算符可以和关系、逻辑等运算符联合使用。
if中算术运算符示例
<c:set var="add1" value='<%= request.getParameter("add1") %>'/>
<c:set var="add2" value="${param.add2}"/>
<c:if test="${add1+add2==5}">
The answer is 5
</c:if>
- 该页面取出传递给它的add1和add2参数值,然后用if标记检查两个参数之和是否为5.
if标记中的独立表达式
- if标记的test属性的表达式可以是一个逻辑值或字符串,但不能是数值。
- 逻辑值表达式:
- 字符串:
- 包含"true"字符串(不区分大小写)将被转换为逻辑真值true,其他的字符串转换为逻辑假false
- 如果表达式的值为null,则该表达式被视为false
if标记独立表达式示例:
<%pageContext.setAttribute("a",true);
request.setAttribute("b",null);
session.setAttribute("c","other");
%>
<c:if test="${'True'}"> 'True' </c:if>
<c:if test="${a}"> a=true </c:if>
<c:if test="${b}"> b=null </c:if>
<c:if test="${c}"> c='other'</c:if>
存储if标记的表达式运算结果
<c:if test="${判定表达式}" var="属性名"
scope="page|request|session|application">
输出内容
</c:if>
- 利用var指定存储的属性名,通过scope指定要存储的范围;省略scope时,运算结果将存储在pageContext对象中
存储if标记运算结果示例
<%request.setAttribute("a",10);
request.setAttribute("b",2);
%>
<c:if test="${(a+b) mod 2 eq 0}" var="result">
${a+b}为偶数
</c:if>
<c:if test="${result}">
已存储运算结果${result}
</c:if>
5.条件判定标记choose-when
<c:choose>
<c:when test="${逻辑判定表达式1}">
输出内容1
</c:when>
<c:otherwise>
其他输出
</c:otherwise>
</c:choose>
choose-when标记说明:
- choose、when和otherwise标记之间不能有其他文本或标记出现
- When标记和otherwise标记必须位于choose标记之间
- when标记可以出现多次,且必须位于otherwise标记之前,用于多个条件判定,其语法和if标记基本相同
- otherwise标记必须位于所有的when标记之后,最多只能出现一次,它是个可选标记,用于所有when标记都不满足的情况下的输出。
6.迭代标签-forEach
<c:forEach var="变量名" items="集合表达式">
需要循环输出内容
</c:forEach>
- 功能:
- 将集合或数组类型表达式(JSP1.2/2.0格式均可)中每个元素取出,将其存放在var属性指定的变量中,并根据集合的元素数目,输出标记体中的内容。
- 在标记体中,可以使用表达式${变量名}输出集合或数组中的元素。
forEach标记中的集合类型
- items的取值可以是返回以下类型的表达式:
- 实现了java.util.Collection接口的类
- 实现了java.util.Map接口的类
- 实现了java.util.Enumeration接口的类
- 实现了java.util.Iterator接口的类 一切数组类型
- 字符串类,即java.lang.String
forEach标记示例
<% int[] a={1,2,3,4,5};
java.util.Collection b=new java.util.ArrayList(); b.add(1);b.add(2);b.add(3);b.add(4);b.add(5);
pageContext.setAttribute("b",b);
%>
<c:forEach var="a" items="<%=a%>">${a}</c:forEach>
<c:forEach var="s" items="<br>">${s}</c:forEach>
<c:forEach var="bb" items="${b}">${bb}</c:forEach>
- 上述JSP页面将输出两行123456,注意,第二个循环标记实际上输出的是HTML的换行符<br>
指定循环次数
<c:forEach begin="开始值" end="结束值"
var="循环变量" step="步长">
需要循环输出的内容
</c:forEach>
- 功能:按照begin和end属性指定的开始值和结束值进行循环;如果省略step,则默认增长值为1。可利用var属性存储循环计数器中的当前值。
给定循环次数示例
<c:forEach begin="1" end="6">-</c:forEach>
<c:forEach begin="1" end="6" var="i">
<H${i}>Hi!</H${i}>
</c:forEach>
<c:forEach begin="1" end="12" step="2">-</c:forEach>
- 该JSP页面输出:
- ------
- 6个H1-H6标题大小的文本Hi!
- ------
在集合中输出指定范围的元素
<c:forEach var="变量名" items="集合表达式"
begin="起始值" end="终止值" step="步长"/>
循环输出内容
</c:forEach>
- 功能:按照begin和end属性指定的范围,在集合中循环。注意,对于集合或数组,第1个元素的开始编号为0
输出指定集合元素示例
<%int[] a={1,2,3,4,5,6};%>
<c:forEach var="a" items="<%=a%>"
begin="2" end="6">
${a}
</c:forEach>
- 由于集合的第一个元素编号为0,所以上面的代码可在JSP页面中输出的数字是3456
- 注意,虽然end指定的值超过了数组中最大元素下标(5),但不会发生数组越界错误。
监控循环状态
<c:forEach 其他属性 varStatus="监控变量">
需要循环输出内容
</c:forEach>
- varStatus参数可用于监控循环的状态,该参数可包含若干属性,可以读取这些属性,控制循环中的输出内容。
varStatus监控变量中的属性
- varStatus包含如下属性:
- begin:循环计数的开始值,整型
- end:循环计数的结束值,整型
- step:循环的步长,整型
- count:当前循环的计数值,(1为基数),整型
- index:当前循环的计数值,(0为基数),整型
- first:是否为第一次循环,布尔型
- last:是否为最后一次循环,布尔型
- current:集合中对应于当前循环的元素
varStatus示例
<c:forEach var="v"
items="<%=request.getHeaderNames()%>"
varStatus="s">
<c:if test="${s.first}"><p>-----请求头信息-----</p></c:if>
(${s.count})${v}=${header[s.current]}<br>
<c:if test="${s.last}"><p>------输出结束------</p></c:if>
</c:forEach>
- 这段JSP代码可在页面输出对该页面请求的请求头中所有信息,并利用监控变量的相关属性对输出进行了一些格式化工作。
- 这段代码中,s.current和v的值是相同的。
7.字符串分割-forTokens标记
<c:forTokens items="字符串" var="变量名"
delims="分割字符">
循环输出内容
</c:forTokens>
- 功能:将items属性给定的字符串按照delims属性给出的字符进行分割,按照分割后的子字符串个数进行循环,其中var属性存储了每次分割的字符串。
forTokens示例
<c:forTokens items="user=wang&course=web"
delims="&" var="pv">
<c:out value="${pv}"/><br>
</c:forTokens>
- 上述代码将分两行输出user=wang和course=web
forTokens标记的其他属性
- 和forEach标记类似,forTokens标记也可以使用以下可选属性:
- 这些属性的用法和forEach标记中的对应语法相同,此处不再赘述。
8.重定向标记-redirect
<c:redirect url="url" context="上下文路径">
<c:param name="参数名" value="参数值"/>
</c:redirect>
- 将访问该JSP页面的用户从定向到指定的url,如果指定了context参数的值,则url参数取值必须用“/”开头。
redirect标记示例
<c:redirect url="other.jsp"/>
<c:redirect url="/o.jsp"
context= ‘<%=request.getContextPath()%>’/>
- 重定向到相对于当前Web程序上下文路径下的o.jsp
<c:redirect url="i.jsp">
<c:param name="p" value="&"/>
<c:param name="q" value="="/>
</c:redirect>
- 形成的重定向url将是i.jsp?p=%26&q=%3d,参数值自动被编码成特定的字符。
9.url标记
<c:url value="url" context="上下文路径">
<c:param name="参数名" value="参数值"/>
</c:url>
- 功能:在当前页面生成指定的url字符串,如果用户关闭了浏览器的cookie,则该标记可自动生成url重写字符串。如果添加了context属性,则value的取值规则和redirect标记中的value取值是相同的。
url标记示例
<a href="<c:url value='index.jsp'>
<c:param name='action' value='?2'/>
</c:url>">
返回首页
</a>
- 该段代码可在JSP页面生成一个如下的超级链接: <a href="index.jsp?action=%3f2">返回首页</a>
url标记和url重写
- 如果用户禁用了cookie,则session对象在JSP页面中将不能正常使用。
- 大部分服务器在此情况下,自动在请求的页面后添加一个会话id的参数,以保持session的可用性
- 这种自动生成带有会话id的url的功能称为url重写
-
url标记可自动生成重写url,比如上例中,如果用户禁用cookie,则生成的href将自动变为如下形式:
- index.jsp;jsessionid=E4A0EB8280B7817CF3D465FEBC6A3007?c=%3f2
url标记的var和scope参数
<c:url value="url" context="上下文路径"
var="存储url变量名" scope="范围">
<c:param name="参数名" value="参数值"/>
</c:url>
- 添加了var属性后,url标记将不在当前页面中产生输出,而是将生成的url存储在var指定的变量中。如果省略scope,则该变量将存储在页面上下文中。
url标记var和scope示例
<c:url value='index.jsp' var="url">
<param name='action' value='?2'/>
</c:url>
<a href="${url}"返回首页</a>
-
该段代码可在JSP页面生成一个如下的超级链接: <a href="index.jsp?action=%3f2">返回首页</a>
10.捕捉异常标记-catch
<c:catch var="存储异常实例的属性名">
可能发生异常的JSP代码
</c:catch>
- catch标记用于将JSP页面中抛出的异常实例存储到页面对象中,从而避免JSP页面出现错误的信息。
catch标记示例
<c:catch var="ex">
<% int a=Integer.parseInt("3.0+");%>
</c:catch>
<c:if test="${not empty ex}">
错误:${ex}
</c:if>
- 该JSP页面会捕捉在类型转换时发生的异常,从而显示该异常信息。
11.引入资源标记-import
<c:import url="文件url" charEncoding="编码">
<c:param name="参数名" value="参数值"/>
</c:import>
- 功能:功能和<jsp:include>类似。如果url指定文件的编码同当前页面的编码不一致,可以使用charEncoding属性指定其编码。另外,url可指定其他资源,比如可以是一个来源于某个ftp资源的文件。
三、数据库操作标记
-
数据库操作标记主要由以下标记组成:
- setDataSource-设置数据源
- query-查询
- update-更新
- transaction-事务控制
数据库标记的url和前缀
uri:http://java.sun.com/jsp/jstl/sql或
http://java.sun.com/jstl/sql_rt
引入语法:
<%@taglib
uri=”http://java.sun.com/jsp/jstl/sql”
prefix=”sql”
%>
数据库标记的使用
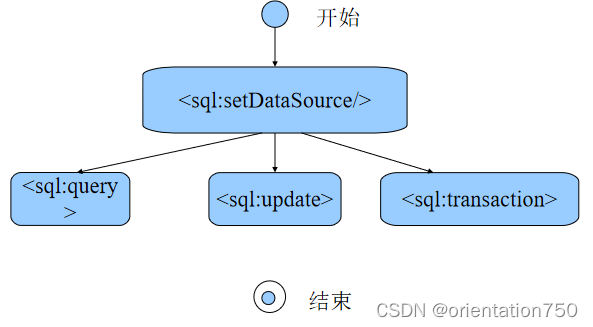
1.设置数据源标记
<sql:setDataSource driver="数据库驱动类名"
url="数据库连接url"
user="用户名"
password="口令"
var="数据源变量名"
scope="page|request|session|application"/>
- 功能:建立数据库连接的连接池,如果没有给出var和scope属性,连接池变量将存储在当前的页面中。
2.数据库查询标记
<sql:query var="查询结果变量名" scope="范围"
dataSource="${数据源变量名}">
select 语句
</sql:query>
<sql:query var="查询结果变量名" scope="范围"
sql="select语句" dataSource="${数据源变量名}"/>
(1)dataSource和var参数
- dataSource:
- 指定由setDataSource标记设置的数据源。
- 如果setDataSource标记没有利用var属性指定数据源变量,此时该属性可以省略;否则必须利用该属性指定数据源变量。
- var和scope:
- var属性指定查询的结果存储的变量名,以后可以利用<c:forEach>标记取出其中的查询结果
- scope可以省略,此时查询结果将存在页面中。
(2)限制查询的记录数
- 为query标记添加以下参数可以限制查询到的记录数,从而实现查询结果的分页功能:
- startRow:指定查询结果中包含的开始记录数,省略时该参数时,将以“0”为开始值
- maxRows:指定查询结果中最多包含的记录数,该值为-1或省略时,将包含所有的记录。
(3)var参数中可用的属性
- 可以利用var参数以下属性取出查询的结果:
- columnNames:查询结果中的字段名的集合
- rows:查到的记录集合,可利用循环标记取出这些记录,而每条记录均可使用如下形式取出其中的对应的每个字段值:
- rowsByIndex:以数组方式存储的查询记录集合
- rowCount:记录总数
- limitedByMaxRows:是否限制了最大查询的行数
var参数中的rows和rowsByIndex属性
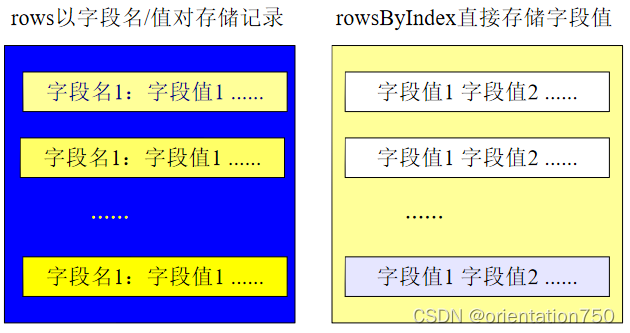
query示例:建立JavaDB数据源
<!--建立到JavaDB数据库的连接池-->
<sql:setDataSource
driver="org.apache.derby.jdbc.ClientDriver"
url="jdbc:derby://localhost:1527/DBDemo"
user="sa" password="sa"/>
<!--使用query标记,将查询结果存入名为r的属性-->
<sql:query var="r">
SELECT id as 用户标识,name as 用户账号 FROM users
</sql:query>
query示例:使用columnNames和rows
<table><!--使用结果集的columnNames属性打印列名-->
<c:forEach var="colName" items="${r.columnNames}">
<th>${colName}</th>
</c:forEach>
<tr><td>使用rows属性取出结果集中的记录</td></tr>
<c:forEach var="row" items=${r.rows}><tr>
<c:forEach var="columnName" items=${r.columnNames}> <td>${row[columnName]}</td>
</c:forEach></tr>
</c:forEach>
query示例:使用rowsByIndex
<tr><td>使用rowsByIndex取出结果集中记录</td></tr>
<c:forEach var="row" items=${r.rowsByIndex}>
<tr>
<c:forEach var="field" items=${row}>
<td>${field}</td>
</c:forEach>
</tr>
</c:forEach>
</table>
(4)为参数化查询中指定数据
- 查询的where子句中可以包含问号(?)以便实现参数化查询,此时可以在标记中嵌入param标记提供参数数据:
<sql:query>
<sql:param value="参数值表达式1"/>
<sql:param value="参数值表达式2"/>
select * from 表名 where 字段1=? and 字段2=?
</sql:query>
- 注意param标记的数目应和where子句中问号数目相同,参数值表达式既可以是1.x也可以是2.0形式的表达式。
sql中的Date参数
- <sql:dateParam>标记允许开发者使用java.util.Date类型的数据为日期型参数提供精确的日期数据:
<sql:query>
<sql:dateParam value="日期型表达式"
type="date | time | timestamp" />
select * from 表名 where 日期型字段=?
</sql:query>
- type指定该参数是只包括年月日的日期(date)、只包括小时分钟秒的时间(time)还是精确的时间(timestamp)。
param和dateParam示例中的表结构
- 假设在JavaDB的DBDemo数据库中有一个名为users的表,该表结构如下:
- id:用户标识,整型,主关键字
- name:用户名,字符串型
- regdate:注册日期,日期型
- 以下示例将使用hiredate字段作为查询的参数,分别使用param标记和dateParam标记查询指定注册日期的用户。
param和dateParam示例代码
<sql:setDataSource
driver="org.apache.derby.jdbc.ClientDriver" url="jdbc:derby://localhost:1527/DBDemo"
user="sa" password="sa"/>
<% java.util.Date d;
java.text.SimpleDateFormat sdf=new java.text.SimpleDateFormat("yyyy/MM/dd");
d=sdf.parse("2008/11/30");
java.sql.Date sd=new java.sql.Date(d.getTime());
%>
<sql:query var="rp">
<sql:param value="<%=sd%>" />
SELECT * FROM users where regdate=?
</sql:query>
<sql:query var="rd">
<sql:dateParam value="<%=d%>" type="date"/>
SELECT * FROM users where regdate=?
</sql:query>
3.更新标记-update
<sql:update var="存储更新行数的变量名"
scope="存储范围"
dataSource=${数据源变量名}
sql="更新sql语句"/>
<sql:update var="存储更新行数的变量名"
scope="存储范围" dataSource=${数据源变量名}> 更新sql语句
</sql:update>
update标记说明
- update标记的使用方法和query标记基本相同
- 和query标记不同的是,update的var属性中存储的是修改、插入或删除的记录数
- update标记同样可以和<sql:param>、<sql:dateParam>等SQL参数标记连用,实现对于更新sql中参数化数据的赋值
4.事务标记-transaction
<sql:transaction dataSource="${数据源名称}" isolation="事务隔离级别">
需要事务处理的查询和更新标记
</sql:transaction>
- 功能:对于标记中的嵌入的数据库操作标记比如update、query等操作进行数据库事务管理。其中的数据源和事务隔离级别属性都是可选的。
事务标记的使用
- 对于嵌套在事务标记中的更新或查询标记,均使用事务标记中的dataSource指定的数据源,不得再自行指定数据源。
- 通常使用catch标记对事务产生的异常进行捕捉:
<c:catch var="tx">
<sql:transaction>....</sql:transaction>
</c:catch>
<c:if test="${not empty tx}">
事务处理提示:${tx}
</c:if>
更新和事务标记示例
<!--此处数据源的设定通过var属性为数据源指定了名称-->
<sql:setDataSource
driver="org.apache.derby.jdbc.ClientDriver" url="jdbc:derby://localhost:1527/DBDemo"
user="sa" password="sa"
var="javadbDS"
/>
<!--catch标记用于捕捉可能发生的异常错误信息-->
<c:catch var="tx">
<!--以下插入SQL没有使用事务,可以指定自己的数据源-->
<sql:update dataSource="${javadbDS}">
delete from users where id=1
</sql:update>
<!--利用事务控制两组插入SQL,数据源由事务标记指定-->
<sql:transaction dataSource="${javadbDS}">
<!--注意,此处的update标记不可指定数据源-->
<sql:update>
insert into users(id,name) values(1,'小赵')
</sql:update>
<!--以下更新标记使用param标记为SQL中的?提供参数-->
<sql:update>
<sql:param value="1"/> <sql:param value="小赵"/>
insert into users(id,name) values(?,?)
</sql:update>
</sql:transaction>
</c:catch>
<c:if test="${not empty tx}">
插入数据失败:${tx}事务已回滚。
</c:if>
更新和事务标记示例说明
- 在上述的示例中,首先,通过delete语句删除了数据库中的id为1的记录。随后两组insert语句均使用事务标记控制。
- 第一个insert语句成功插入一条id为1的记录。
- 第二个insert语句插入了又一条id为1的记录,这违反了数据库主键唯一的约束,所以它是失败的。
- 由于两个insert语句均由事务控制,由于第二条插入语句失败,事务回滚,第一条插入的记录也随之无效。表users此时不再包含id值为1的记录。
四、自定义函数标记
- 自定义函数可以在JSP2.0表达式中加入JSTL中定义的处理字符串函数,增强表达式的数据处理能力。
- 自定义函数标记的引入语法:
<%@taglib prefix="fn"
uri="http://java.sun.com/jsp/jstl/functions"%>
${fn:函数名(参数列表)}
fn:后可用的函数
- toLowerCase(字符串表达式)
- toUpperCase(字符串表达式)
- trim(字符串表达式)
- substring(字符串表达式,起始位置,终止位置)
- 按照起始位置和终止位置,返回截取后的字符串。
- 注意,字符串中字符的位置从0开始计数,而该函数返回的子串为起始位置到终止位置-1处的子串。
- substringBefore(字符串表达式1,字符串表达式2)
- substringAfter(字符串表达式1,字符串表达式2)
- startsWith(字符串表达式1,字符串表达式2)
- 如果串1以串2开头,返回true,否则返回false
- endsWith(字符串表达式1,字符串表达式2)
- 如果串1以串2结尾,返回true,否则返回false
- split(字符串表达式1,字符串2表达式)
- 以字符串2为标界,对字符串1进行分割,返回分割之后的字符串数组
- replace(字符串表达式1,字符串2,字符串3)
- 将字符串1中包含的字符串2用字符串3替换,返回替换之后的字符串
- join(字符串数组表达式,字符串表达式)
- 将字符串数组中的元素用字符串表达式进行连接,返回连接之后的形成的字符串
- contrains(字符串表达式1,字符串表达式2)
- 如果字符串1包含字符串2,返回true,否则返回false
- contrainsIgnoreCase(字符串表达式1,字符串表达式2)
- 功能和contrains类似,只是不区分字符串的大小写
- indexOf(字符串表达式1,字符串表达式2)
- 返回串2在串1中的位置,位置的计数从0开始;如串2不在串1中,返回-1
- length(表达式)
- escapeXml(字符串表达式)
- 对字符串中包含的大于号(>)、小于号(<)、单引号(')、双引号(“)、连字符(&)等符号用其实体引用的方式进行替换(比如大于号转换为">"),返回替换后的字符串。
自定义函数标记示例
${fn:substring('wyi@ncepu.edu.cn',0,3)}
- 上述JSP代码利用2.0表达式中的param隐含对象测验用户输入的电子邮件参数是否合法
<c:if test="{ !fn:contrains(param.email,'@'))}"/>
电子邮件不合法!
</c:if>
${ fn:join(fn:split('wyi_ncepu.edu.cn', '_'), '@' ) }
${fn:replace('wyi_ncepu.edu.cn','_',@')}
第十三章 过滤器和监听器
一、过滤器
- 在Java的Web应用中,有时候需要对用户的访问集中进行控制,比如监控用户对程序的某些页面的访问,如果这些页面要求用户登录后才能访问,那么当用户还未登录时就应该禁止其访问这些页面。通过在每个页面中加入session检查可以解决这个问题,但这时采用过滤器就更为简单。
1.过滤器的作用
- 过滤器是一种特殊的Servlet,当在Web程序中加入过滤器后,该过滤器就可以监控用户对Web程序中的某些URL的访问,从而提供一种集中控制用户的一种手段
2.过滤器的构成
- 使用过滤器需要进行以下步骤:
- 编写过滤器的Java类文件
- 在web.xml文件中加入过滤器的说明,这些声明类似于Servlet的说明,用来规定过滤器的名字和匹配的URL
- 如果用户访问在web.xml被过滤器声明过的URL,该过滤器将会被自动调用
(1)过滤器Java类的构成
- 过滤器类必须要实现javax.servlet.Filter,Filter接口定义了doFilter方法,该方法用于对用户的请求进行处理
public class MyFilter implements Filter{
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws ServletException,IOException{
/*对请求进行处理后,可以调用chain对象的doFilter方法,继续传递处理过程*/ chain.doFilter(request,response);
}
}
doFilter方法
public void doFilter(ServletRequest request,
ServletResponse reponse,
FilterChain chain)
throws ServletException,IOException;
- 当用户请求某个被过滤器监控的URL时,在请求的资源返回给用户之前,过滤器Servlet中的doFilter方法会首先被调用。
- 在该方法中,如果没有调用chain对象的doFilter方法,则用户的请求会被阻止;相反,如果调用了doFilter方法,则会将请求传递给下一个过滤器Servlet的doFilter,如果下一个过滤器中的doFilter方法也调用了chain对象的doFilter方法,此请求将一直延续,直到最终到达用户请求的资源
过滤器执行的示意图
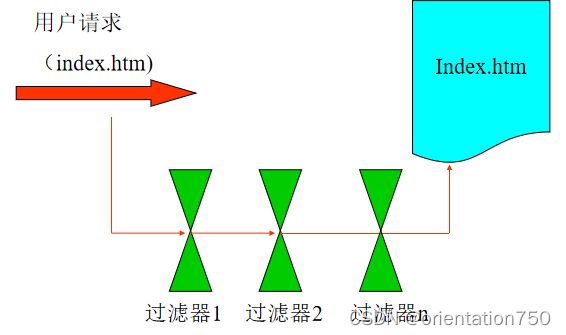
(2)在web.xml中加入过滤器的定义
- 过滤器类要起到监控作用,需要在web.xml文件中加入其类名的说明和监控的url,如下所示一个示例,该示例为edu.ec.web.NewFilter过滤器类规定了NewFilter名称,并将该过滤器监控的url设为对Web程序的所有的请求:
<filter>
<filter-name>NewFilter</filter-name>
<filter-class>edu.ec.web.NewFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>NewFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
- 注意,<filter>和<filter-mapping>的次序不能颠倒,而且这两个标记必须紧接着web.xml文件中的<listener>标记之前出现。
3.过滤器的应用示例
- 该示例演示了如何防止Web站点被其他站点盗链的方法。
- 在该示例中,用一个过滤器监控所有的对jsp页面的请求,察看这些请求是否来源于合法的请求,如果是,则让用户的请求继续,否则,阻止用户的请求。
二、监听器
- 监听器用于监控Web应用程序中的由自身引发的一系列事件,如在Web容器装入Web应用程序、用户的session被创建、销毁、session中被存入数据、删除数据等事件。当这些事件发生时,监听器将会被自动调用
- 利用监听器,Web程序可以更好地控制程序的执行。比如,数据库的连接是一项耗费时间的操作,但数据库的连接如果不被关闭,则会造成数据库资源无法释放。但如果Web程序每次用完连接后都进行关闭,再打开连接时由需要耗费时间。利用监听器可以解决这个问题:在Web程序由容器装入时,打开数据库连接;在Web程序被容器销毁时,断开数据库连接。
监听器执行示意图
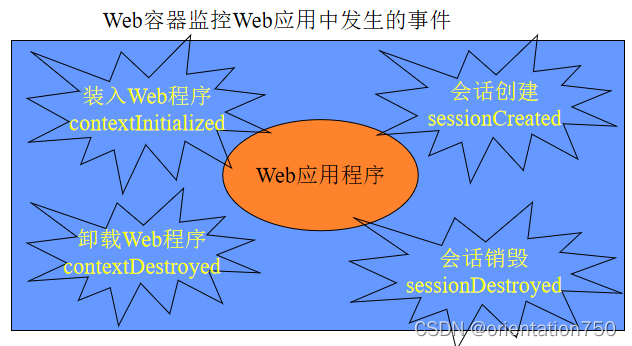
1.监听器的构成
- 监听器无需继承特定的父类,但需要实现特定的接口,以下列出这些接口:
- javax.servlet.ServletContextListener:
- javax.servlet.ServletContextAttributeListener:
- 用于监控Web应用在ServletContext中存取数据
- javax.servlet.http.HttpSessionListener:
- 用于监控Web应用程序中session的创建和删除
- javax.servlet.http.HttpSessionAttributeListener:
(1)ServletContextListener接口
- ServletContextListener接口中定义两个方法:
- public void contextInitialized(ServletContextEvent evt)
- 该方法将在 Web 应用程序启动以及添加或重新装入上下文时由容器自动调用,可以利用该方法分配一些资源,比如打开数据库的连接等工作
- public void contextDestroyed(ServletContextEvent evt)
- 该方法将在Web 应用程序关闭或者删除时由容器自动调用 ,可以利用该方法进行一些资源清理工作,比如关闭数据库连接等工作
(2)ServletContextAttributeListener接口
- ServletContextAttributeListener接口中定义了三个方法:
- public void attributeAdded( ServletContextAttributeEvent evt)
- 该方法在向ServletContext中添加属性时自动被容器自动调用
- public void attributeRemoved( ServletContextAttributeEvent evt)
- 该方法在ServletContext中删除属性时自动被容器调用
- public void attributeReplaced( ServletContextAttributeEvent evt)
- 该方法在ServletContext中替换属性时自动被容器调用
(3)HttpSessionListener接口
- HttpSessionListener接口中定义了两个方法:
- public void sessionCreated(HttpSessionEvent evt)
- 该方法在建立用户session对象时自动被容器调用
- public void sessionDestroyed(HttpSessionEvent evt)
- 该方法在销毁用户session对象时自动被容器调用
(4)HttpSessionAttributeListener接口
- HttpSessionAttributeListener接口中定义了三个方法:
- public void attributeAdded(HttpSessionBindingEvent evt)
- public void attributeRemoved(HttpSessionBindingEvent evt)
- public void attributeReplaced(HttpSessionBindingEvent evt)
监听器类定义示例
- 以下示例的监听器类可以监控Web应用程序在容器中的装入和删除删除事件,在Web应用程序启动时连接数据库,并将连接存入ServletContext中,以便其他类访问,在Web应用关闭时,取出该连接并关闭该连接:
public class UserListener implements ServletContextListener{
public void contextInitialized(ServletContextEvent evt) {
try{
Class.forName(“sun.jdbc.odbc.JdbcOdbcDriver”);
Connection con=DriverManager.getConnection(“jdbc:odbc:demo”);
evt.getServletContext().setAttribute("con", con);
}catch(Exception e){ throws new RuntimeException(e);}
}
public void contextDestroyed(ServletContextEvent evt){
Connection con = (Connection) evt.getServletContext().getAttribute("con");
try {
con.close();
} catch (SQLException ignored) {}
}}//类定义结束
2.监听器的使用
- 使用监听器只需要将写好的监听器类加入到web.xml文件中即可,假如上述的监听器类UserListener所在的包为edu.ec.demo,则将其加入到web.xml中的代码如下所示:
<listener>
<listener-class>edu.ec.demo.UserListener</listener-class>
</listener>
- 注意,<listener>标记必须要加到<filter-mapping>标记之后,<servlet>标记之前。
3.监听器的应用示例
- 该示例可以监控访问Web应用程序的在线用户数量。当用户访问Web应用程序时,利用会话监听记录用户的数量,而当用户的会话超时或用户注销登录时,该监听器将自动减少在线用户的计数器。